






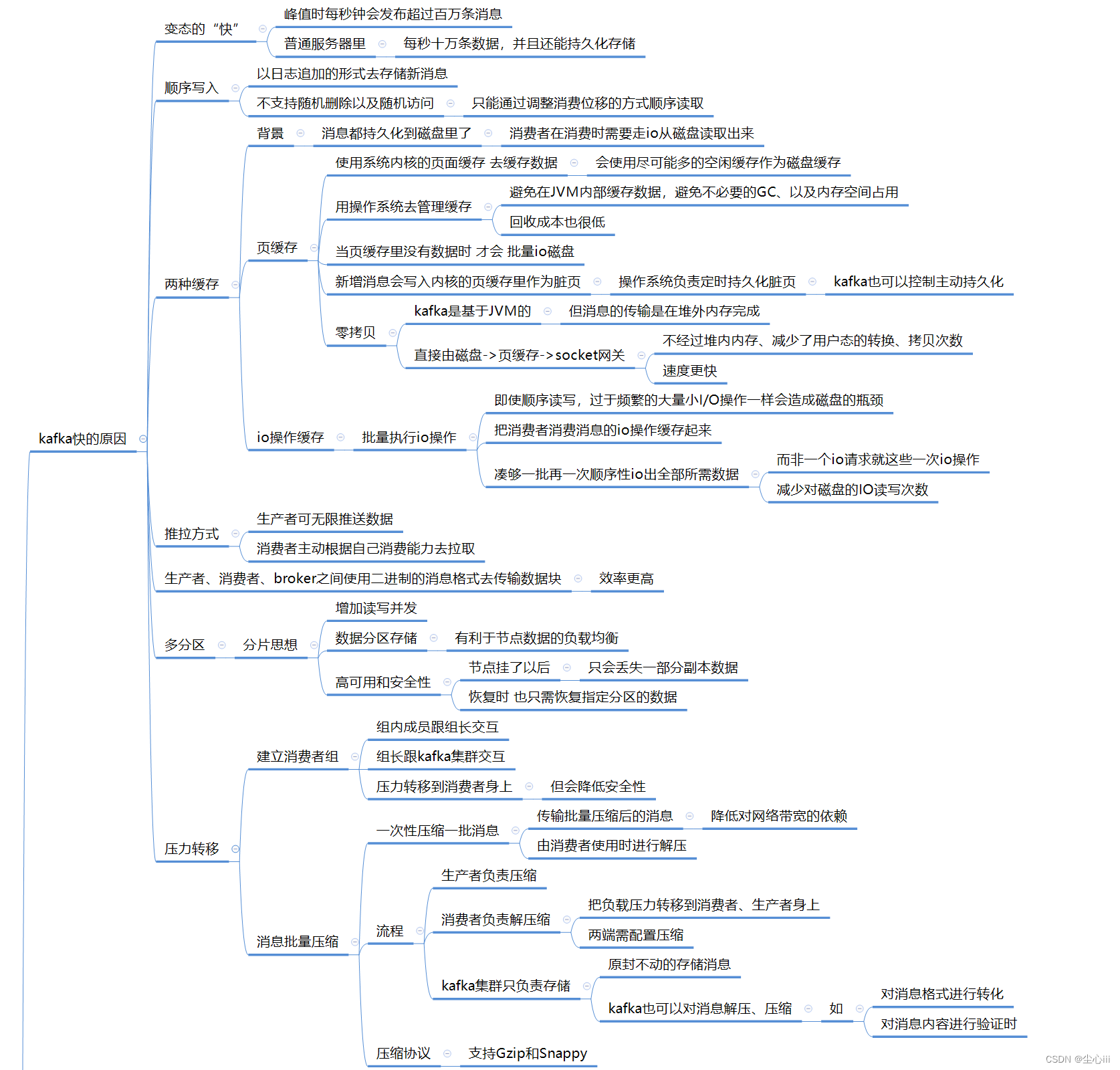
kafka是变态的“快”,峰值时每秒钟会发布超过百万条消息,即使是在普通服务器里,每秒十万条数据,并且还能持久化存储
快的原因
1、顺序写入
以日志追加的形式去存储新消息
不支持随机删除以及随机访问,只能通过调整消费位移的方式顺序读取
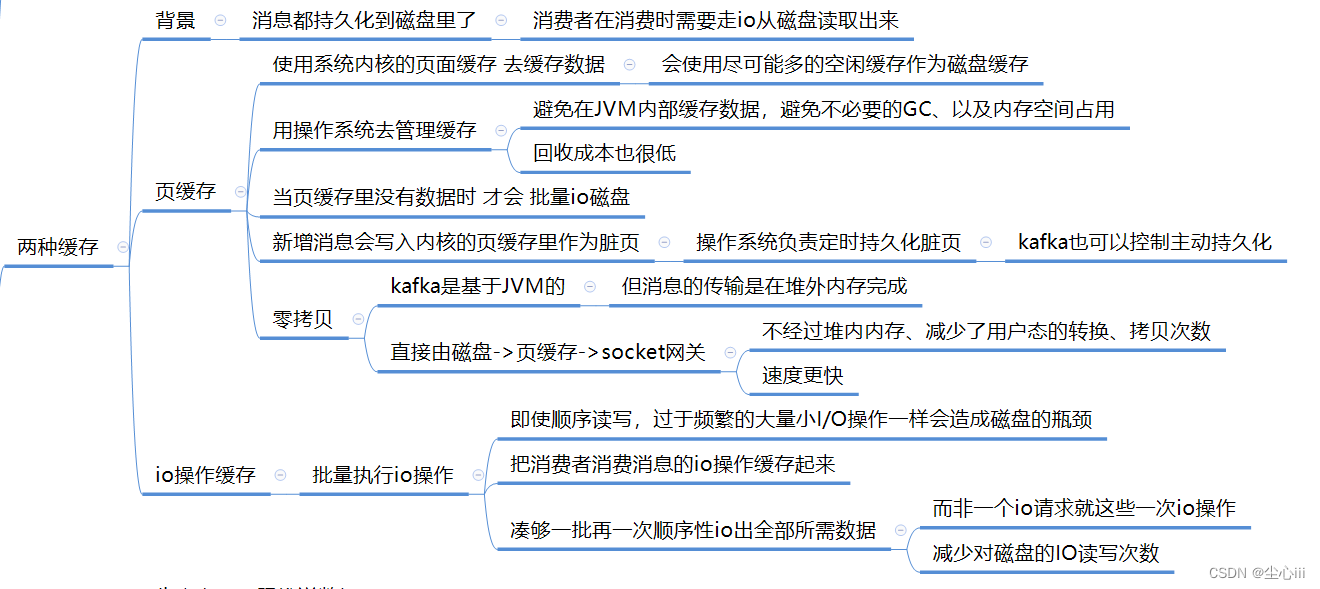
两种缓存的使用
消息都持久化到磁盘里了,消费者在消费时需要走io从磁盘读取出来
2、页缓存和零拷贝
使用页面缓存,消息直接 由磁盘->页缓存->socket网关,不经过堆内内存、减少了用户态的转换、拷贝次数,速度更快
3、io操作缓存
凑够一批再一次顺序性io出全部所需数据,而非一个io请求就这些一次io操作,减少对磁盘的IO读写次数
4、推拉方式
生产者可无限推送数据
消费者主动根据自己消费能力去拉取
5、二进制数据块
生产者、消费者、broker之间使用二进制的消息格式去传输数据块, 效率更高
6、多分区
分片思想
1 增加读写并发
2 数据分区存储,有利于节点数据的负载均衡
3 高可用和安全性,节点挂了以后,只会丢失一部分副本数据,恢复时 也只需恢复指定分区的数据
压力转移
7、建立消费者组
组内成员跟组长交互
组长跟kafka集群交互
把压力转移到消费者身上,但会降低安全性,容易消息丢失、消息重复
8、消息批量压缩
一次性压缩一批消息
传输批量压缩后的消息,降低对网络带宽的依赖,由消费者使用时进行解压
压缩流程
生产者负责压缩
消费者负责解压缩
把负载压力转移到消费者、生产者身上,两端需配置压缩
kafka集群只负责存储,原封不动的存储消息
kafka也可以对消息解压、压缩。
如,对消息格式进行转化,对消息内容进行验证时
支持Gzip和Snappy压缩协议

















 1021
1021

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









