







目录
一 、 YOLOV5环境
1.1 gpu版本
实现GPU硬件加速,需要电脑带有英伟达的显卡。如何查看自己电脑的显卡请自行百度。
如果电脑满足了显卡的要求,需要安装cuda和cudnn,由于本文主要是配置yoloV5故安装cuda和cudnn不再阐述。注意cuda的版本要根据自己电脑的显卡驱动版本确定,不一定是越高越好;cuda版本和cudnn版本是对应的;cuda版本和pytorch版本是对应的。笔者显卡是3060 因为显卡驱动是11.3.X故cuda安装版本为11.3刚好和官网pytorch 中有cuda11.3版本的pytorch。进入pytorch可以查看对应版本。
由于pytorch还需要c++环境,在配置环境时候需要安装Visual Studio (2017或别的版本)。

1.2 cup版本
相较于GPU版本CPU版本更容易些。如果你使用的是pip则直接运行框中的代码即可。

二 、 YOLOv5项目下载及配置
将代码下载到本地,安装requirements.txt中的包依赖,Base和框中的python包我们必须下载,不然无法运行程序。wandb是保存运行日志的python包,可以选择性安装。如果使用wandb,需要进行注册,注册需要外网。如果不适用wandb需要在代码中进行配置,在本文的最后安装问题总结中会进行介绍处理方式。

三 、 测试环境
3.1 yoloV5的目录

data:存放训练数据集、测试数据集、数据集的配置文件。我们在训练和使用训练后的模型进行检测时,通过配置相应的参数,调用该文件下的数据和配置文件。
models:模型相关的配置文件,但并不是模型存放地方。
run:程序运行结果存放的位置,可能你刚刚下载的yoloV5源码没有此文件夹,当运行程序时,系统会自动创建。包括两个子文件夹一个(train)存放检测结果、一个(detect)存放训练结果。
wandb:程序运行的日志文件。
detect.py:检测文件
rain.py:训练文件
3.2 用pycharm打开YOLOV5项目,运行detect.py文件
第一次运行会下载相关的模型文件,如果运行成功 run/detct 会保存第一次的运行结果,则yolo环境配置完毕
四 、 数据准备 labelImg进行标注数据
4.1 配置环境
#主要python 包
pip install PyQt5
pip install lxml
4.2 使用labelImage标注数据
根据实际情况更改labelImg-master\data\predefined_classes.txt
运行 python labelImg.py
五 、 训练
5.1 训练数据的文件路径形式

train : 训练数据
val : 测试数据
images保存的都是图片(包括训练数据图片train 测试图片val),labels保存的都是label ,yolo会根据图片去labels中找相应图片的label
5.2 训练数据的配置文件

复制coco.ymal 重新命名为xxxx.ymal 并更改内容根据自己路径更改
下图为更改后的coco.yaml,读者需要根据自己需求更改

train:训练集图片地址
val:测试集图片地址
nc:一共有多少类
names:每一类的名称,必须和标注时候对应,否则训练后检测很乱。
train 和val一定是图片地址!!!!
5.3 train.py
**train.py需要修改的部分和部分参数注释。红色框中是我们常修改的内容可以对应下面的图进行修改自己的内容。(有点模糊)


5.4训练结果

六 、 检测
6.1 使用自己模型进行检测
weights :我们训练好的模型路径
source :我们要检测的数据路径。yolo支持输入是文件夹和单个图片的检测

七、可能遇到的问题
7.1 CUDA Error: out of memory
一般这个错误会在训练的时候遇到,显存不足,我们可以调低bach-size的大小即可。
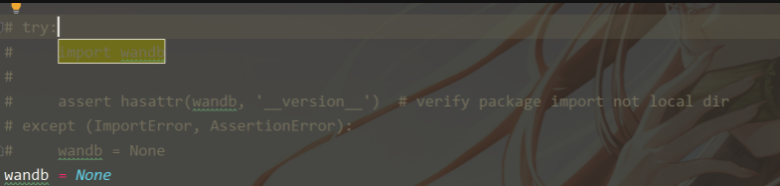
7.2wandb
wandb可能遇到很多问题,如果不使用wandb需要修改文件wandb_utils.py
















 1495
1495











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









