









决策树
思想
- 对特征进行节点划分,难点在于先选哪个特征,就引出信息熵的概念,也就是类似于权重,用于划分数据集
信息熵、信息增益
熵
- 描述系统的无序程度,系统越有序,熵越低
信息熵
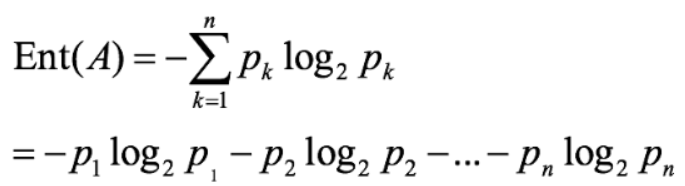
- 这个式子的优点:
- 当概率平均的时候熵最大,以两种情况即n=2为例,
p
1
=
p
2
=
0.5
p_1=p_2=0.5
p1=p2=0.5,熵最大,图像如下,这也是以2为底的原因

- 当概率平均的时候熵最大,以两种情况即n=2为例,
p
1
=
p
2
=
0.5
p_1=p_2=0.5
p1=p2=0.5,熵最大,图像如下,这也是以2为底的原因
信息增益-ID3
- 信息增益=信息熵(特征划分前)-信息熵(特征划分后)

- 切记:再往下的计算都基于上一次,选择信息增益最大的那个特征划分,第一步最大,后面越来越小。即使选的特征再烂,也不可能出现信息增益为负(信息熵函数的特性)
信息增益率-C4.5
- 相当于信息增益的加权,平衡每个特征样本量的差距
基尼值与基尼系数-常用
基尼值Gini(D)

- 基尼值越小,纯度越高
基尼系数-CART
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sNQ9PIVM-1569803799695)(en-resource://database/518:1)]](https://img-blog.csdnimg.cn/20190930084634466.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQyMzcwNDcx,size_16,color_FFFFFF,t_70)
- 总结:选择节点特征时,选择基尼系数最小的,即纯度最高的,即系数增益最大的,和信息熵差不多
剪枝
- 决策树的剪枝分为先剪枝和后剪枝,后剪枝在sklearn中并未实现,前剪枝容易理解,就是在生成树的时候直接进行评判并剪枝;
- 后剪枝则是在树完全生成后,即每个叶节点都是纯净的之后再进行剪枝。此时会遍历每个叶节点计算损失函数,比前剪枝要更加准确。
API和参数
sklearn.tree.DecisionTreeClassifier(criterion='gini', max_depth=None, random_state=None)
- criterion:选择树的类型
- 'gini’默认值:即CART算法
- ‘entropy’:表示信息增益,即ID3树
- min_samples_split:内部节点在划分的最小样本数,默认为2,10万左右的样本一般设为10
- min_samples_leaf:叶子节点最小样本数,默认1,10万左右的样本一般设为5
- max_depth:最大深度,适用于样本量和特征都多的时候















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









