 决策树算法原理与流程详解
决策树算法原理与流程详解





本笔记仅记录《统计学习方法》中各个章节算法|模型的简要概述,比较泛泛而谈,用于应对夏令营面试可能会问的一些问题,不记录证明过程和详细的算法流程。大佬可自行绕路。
更多章节内容请参阅:李航《统计学习方法》学习笔记-CSDN博客
目录
决策树概述:
一种基本的分类与回归方法,可以认为其是if-then规则的集合。决策树学习通常包括3个步骤:特征选择、决策树的生成、决策树的修剪。
决策树模型:
决策树是一种树形结构,内部结点表示一个特征或者属性,叶子结点表示一个类。
决策树学习的本质是从训练数据集中归纳出一组分类规则。
决策树学习的损失函数通常是正则化的极大似然函数。
因为从所有可能的决策树中选取最优决策树是NP完全问题,所以现实中决策树学习算法通常是启发式方法,近似求解,这样得到的决策树是次优的。
决策树学习的算法流程通常是一个递归地选择最优特征的过程,并根据该特征对训练数据进行分割,使得对各个子数据集有一个最好的分类的过程。该方法可能对训练集有很好的分类能力,但是对于未知的测试数据可能未必会有很好的分类能力,可能发生过拟合现象,因此需要对决策树进行自下向上的剪枝,简单来讲,就是去掉过于细分的叶结点,使其退回到父结点,或者更高的结点。
决策树的生成对应于模型的局部选择,决策树的生成考虑全局最优。
特征选择:
目标是选择对训练数据有足够分类能力的特征,如果存在使用某些特征作为分类的结果与随机分类的结果没有很大差别,则丢弃该特征。
通常特征选择的准则是信息增益或者信息增益比。通过计算按照某个特征进行分类后的信息增益比,我们进而可以判断该特征是否可以用于很好地分类。
信息增益:
熵的计算公式:
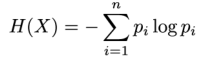
注意熵只依赖与X的分布,而与X的取值无关,因此也可以记为:
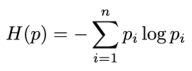
该公式表示计算随机变量的不确定性的程度,熵越大,随机变量的不确定性越大。
条件熵的计算公式:
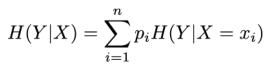
该公式表示在已知随机变量X的条件下随机变量Y的不确定性。
知道了上述公式,那么什么是信息增益(也可以称为互信息)呢?
信息增益表示得知特征X的信息进而使得类Y的信息的不确定性减少的程度。
![]()
不同的特征具备不同的信息增益,信息增益大的特征具备更强的分类能力。
根据信息增益准则的特征选择算法是:对训练数据集(或子集)D,计算其每个特征的信息增益,并比较它们的大小,选择信息增益最大的特征。
算法流程:

例子:
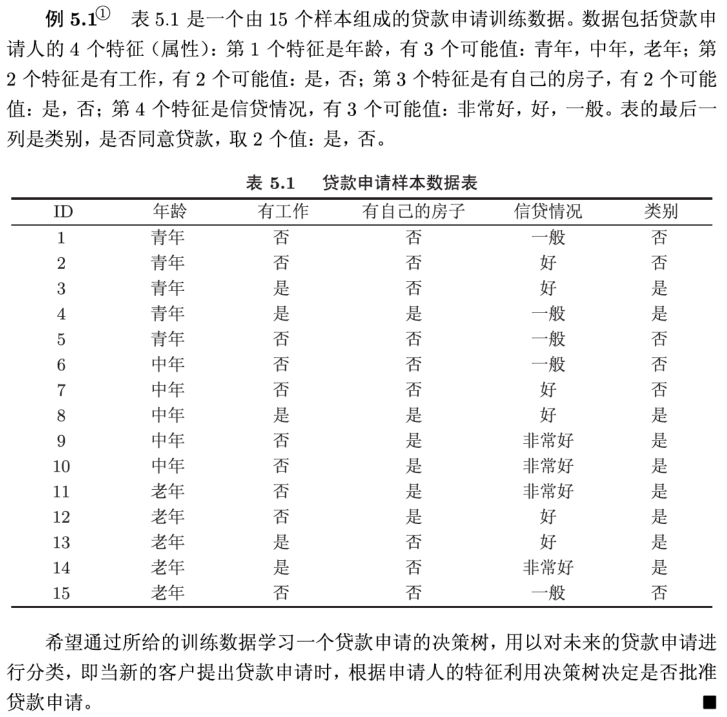


信息增益比:
以信息增益作为划分数据集的特征,存在偏向于选择取值较多的特征的问题。
为什么会出现这个问题?
举个例子,如果我们现在数据集共有8个样本,某个特征具备8个不同的取值,这样子按照这个特征划分每个子集熵都是0,导致按照信息增益计算公式来算该特征具备最好的分类能力,但实际上该特征可能并没有实际的预测能力。
这个例子说明了信息增益倾向于选择取值较多的属性,这种倾向可能会导致选择那些对分类没有实际贡献的属性,从而影响决策树的泛化能力。信息增益比通过归一化处理减轻了这一问题,使得对多值属性的偏好得到调整。

决策树的生成:
ID3算法:
ID3本质就是递归选择信息增益最大的特征作为结点的特征,相当于用极大似然法进行概率模型的选择。
算法流程:


例子:

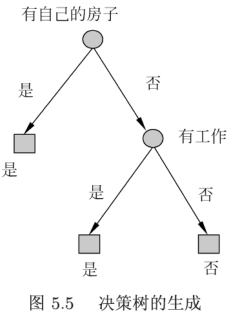
ID3算法只有树的生成,所以该算法生成的树容易过拟合。
C4.5的生成算法:
C4.5相比C3的改进就是选用信息增益比作为评价准则进行特征选择。
算法流程:

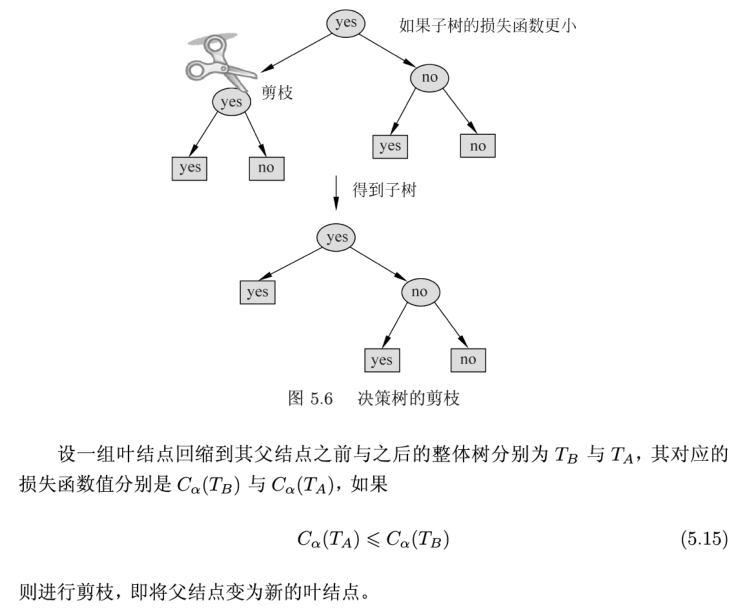
决策树的剪枝:
上述算法(C3、C4.5)由于只涉及树的生成,所以很容易过拟合,需要进行剪枝操作。
决策树的剪枝往往通过极小化决策树整体的代价函数来实现,代价函数中为了防止过拟合,加入了正则化。设树的叶结点个数为|T|,t是树的叶结点,该叶结点具有Nt个样本点,Ht(T)为叶结点t上的经验熵,那么决策树的代价函数可以定义为:
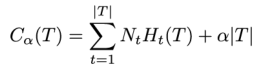
也就是在分类性能和模型复杂度之间寻求一种平衡。
算法流程:


CART算法:
CART算法是应用广泛的决策树学习方法,同样由特征选择、决策树生成、剪枝组成,既可以用于分类,也可以用于回归。
CART生成:
对回归树用平方误差最小化准则,对分类树用基尼系数最小化准则。
回归树:
对输入空间采用启发式划分方法,然后和相应的标签对比,得到预测误差。
算法流程:

分类树:
使用基尼指数最优特征,同时决定该特征的最优二值切分点。
基尼指数:

算法流程:

例子:


CART剪枝:
从叶结点从下向上进行剪枝操作,采用交叉验证得到最优子树。
算法流程:




















 1135
1135

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









