









详细介绍DALL·E 3的模型架构和训练过程,详细解读其论文《Improving Image Generation with Better Captions》。
🌺DALL·E系列文章列表🌺
建议阅读
背景与挑战
DALL·E 3 是 OpenAI 推出的最新文本生成图像模型,其显著提升主要得益于对训练数据中图像描述(caption)的改进。
挑战
文本到图像生成任务的核心是理解输入文本提示,并将其转换为高质量且语义一致的图像,目前很大的一个问题是模型的文本理解能力有限。传统的文本到图像模型在处理复杂提示时,常常无法准确捕捉提示中的所有细节,导致生成的图像与输入文本不完全匹配。传统方法存在以下问题:
- 细节缺失:许多描述仅关注图像的主要主题,忽略了背景、环境和对象之间的关系。
如COCO数据集,图像常规的文本描述往往过于简单,它们大部分只描述图像中的主体而忽略图像中其它的很多信息,比如背景,物体的位置和数量,图像中的文字等
- 不准确性:在互联网上收集的描述可能包含错误信息,甚至与图像内容无关。
另外一方面,目前训练文生图的图像文本对数据集(比如LAION数据集)都是从网页上爬取的,图像的文本描述其实就是alt-text,但是这种文本描述很多是一些不太相关的东西,比如广告。训练数据的caption不行,训练的模型也就自然而然无法充分学习到文本和图像的对应关系,那么prompt following能力必然存在问题
解决方案
为了提升模型的性能,OpenAI 提出了 “数据集重描述”(Recaptioning) 的创新方法。其核心思路是为训练数据中的每张图像生成更详细、准确的描述,从根本上提升数据质量。具体步骤如下:
- 构建图像描述生成器:训练一个模型,输入图像后生成详细的文本描述。
- 应用于数据集:将该生成器应用于整个训练数据集,为每张图像生成新的描述。
- 模型训练:使用包含改进描述的数据集训练文本到图像模型。
通过优化数据集进而提高模型能力的方案其实不是DALL·E 3 首次使用,在BLIP模型中使用Captioning and Filtering (CapFilt) 模块进行自引导学习,详情请参考:万字长文解读深度学习——多模态模型CLIP、BLIP、ViLT
Image Captioner实现细节
从上文的解决方案得知,OpenAI训练了一个强大的图像字幕生成器(image captioner),可以根据图像生成详细的文本描述,用这个模型处理已有的文本-图像配对数据集后,为各个图像生成更详细、准确的图像描述或字幕,再使用改进的数据集进行训练DALL·E模型,从而提高DALL·E的文本理解能力(prompt following能力)。
OpenAI最终选择基于谷歌的CoCa (Contrastive Captioners) 模型,微调一个image captioner,用来合成图像的caption。下面将详细的介绍这个Image Captioner的实现细节。先讲解CoCa,再讲解微调。
CoCa
OpenAI最终选择基于谷歌的CoCa (Contrastive Captioners) 模型,微调一个image captioner,用来合成图像的caption。
论文:CoCa: Contrastive Captioners are Image-Text Foundation Models
模型结构
下面我们先介绍CoCa的模型结构。它是构建在encoder-decoder的基础上的。它的结构如下:
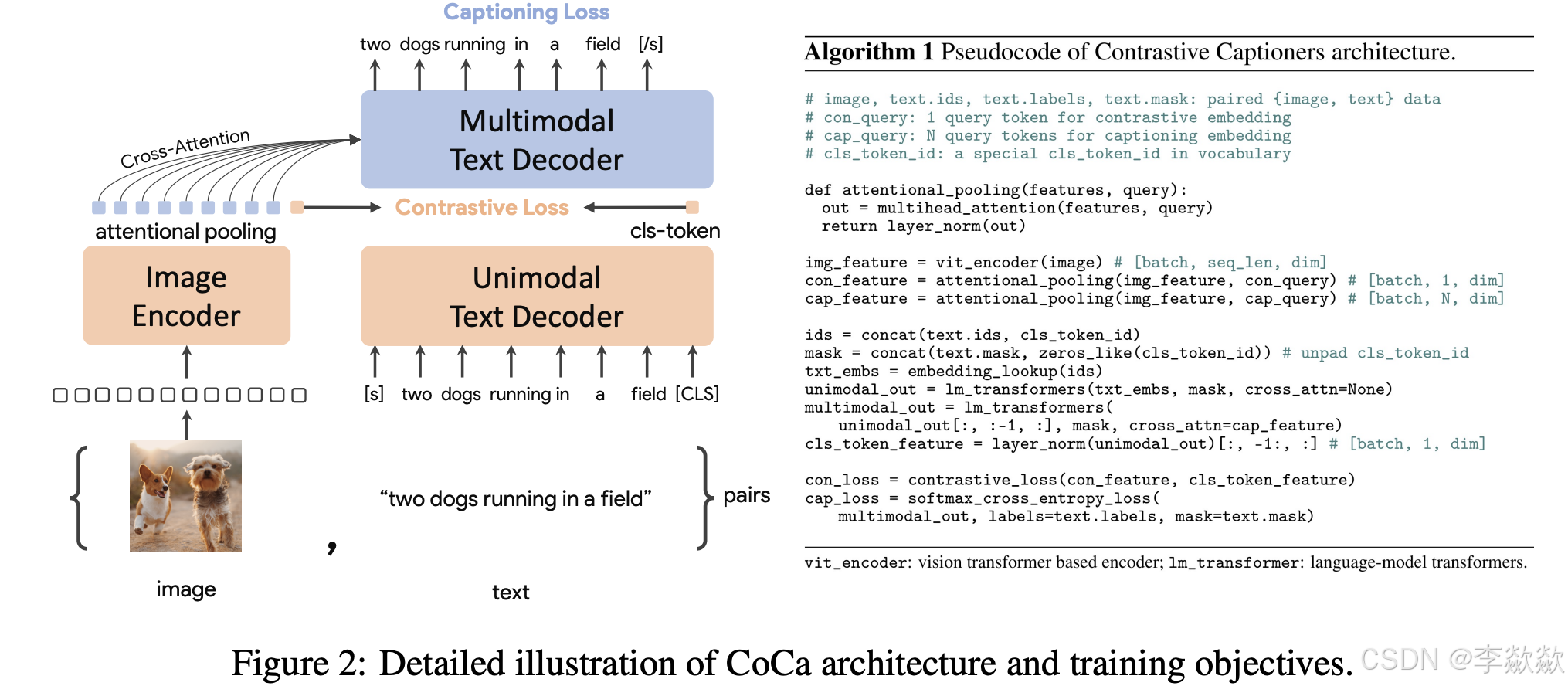
它由一个 Image Encoder 和两个 Text Decoder 组成,均采用Transformer模型。
- 图像编码器 (Image Encoder)
- 使用一个视觉变换器(例如 ViT)对输入图像进行编码,生成一系列特征表示。
- 这些特征表示通过注意力池化进一步提取,分别生成两个特征:
- 对比特征 (Contrastive Feature): 用于对比学习,通过与文本的
cls-token特征进行对比。 - 描述特征 (Captioning Feature): 用于文本生成任务,作为多模态解码器的输入。
- 对比特征 (Contrastive Feature): 用于对比学习,通过与文本的
采用attention pooling对image encoder进行图像的全局特征提取。(这里的attention pooling其实就是一个multi-head attention,只不过key和value是image encoder得到的特征,而query是预先定义的一个可训练的embedding,由于我们只需要提取一个全局特征【与单模态文本解码器的全局特征进行图像-文本的对比学习】,所以只需要定义一个query就好了)
- 单模态文本解码器 (Unimodal Text Decoder)
- 不参与对图像特征的cross-attention;
- 使用 Transformer 模型生成文本的上下文表示, cls-token 特征,得到整个句子的全局特征。
- 特别关注
cls-token,其特征用于计算与图像对比特征的对比损失 (Contrastive Loss)。
图像编码器和单模态文本解码器的两个全局特征就可以实现图像-文本的对比学习。image encoder和unimodal text decoder的两个[CLS]向量作为图片和文本的表示,进行对比学习。
- 多模态文本解码器 (Multimodal Text Decoder)
- 接收图像的描述特征和文本的输入,利用交叉注意力机制,生成文本表示。
- 输出文本序列,优化目标为描述生成损失 (Captioning Loss),通常是
交叉熵损失。
这里也通过一个attention pooling对image encoder得到的特征进行提取,不过这里query数量定义为256,这样attention pooling可以得到256个特征,它作为multimodal text decoder的cross-attention的输入,用于融合图片和文本信息,实现双模态,最后做文本生成。
为什么采用这种分层设计?
- 高效性: 先处理单模态文本输入,避免对所有层都施加跨模态交互,降低计算复杂度。
- 任务分离: 单模态和多模态表示的分离使模型能够同时支持对比学习(Contrastive Learning)和生成式任务(Captioning)。
损失函数
CoCa(Contrastive Captioners)解码器的设计在任务分工和结构上非常特别,采用了 分层解码器结构,以同时支持单模态(Unimodal)和多模态(Multimodal)目标。CoCa 的目标函数是单模态和多模态任务的联合优化:
L C o C a = λ Con ⋅ L Con + λ Cap ⋅ L Cap \mathcal{L}_{CoCa} = \lambda_{\text{Con}} \cdot \mathcal{L}_{\text{Con}} + \lambda_{\text{Cap}} \cdot \mathcal{L}_{\text{Cap}} LCoCa=λCon⋅LCon+λCap⋅LCap
-
Contrastive Loss ( L Con ) (\mathcal{L}_{\text{Con}}) (LCon)
- 用于优化图像编码器和单模态文本解码器在多模态嵌入空间中的对齐。
- 单模态表示(Unimodal Text Representations)通过
cls-token特征与图像特征进行对比。 - λ Con \lambda_{\text{Con}} λCon 是对比损失的权重超参数。
-
Captioning Loss ( L Cap ) (\mathcal{L}_{\text{Cap}}) (LCap)
- 用于优化图像编码器和多模态文本解码器对生成任务(文本生成)的质量。
- 多模态表示(Multimodal Image-Text Representations)通过交叉注意力生成文本描述,与目标文本计算交叉熵损失。
- λ Cap \lambda_{\text{Cap}} λCap 是描述生成损失的权重超参数。
微调
微调方案
为了提升模型生成caption的质量,OpenAI对预训练好的image captioner进行了进一步微调,这个微调包括两个不同的方案,两个方案构建的微调数据集不同:
- 短caption(short synthetic captions,简称SSC):生成的描述只描述图像主体的短caption(类似COCO风格的caption),简洁地描述了图像的主体内容。
- 长caption(descriptive synthetic captions,简称DSC):生成的描述详细描述图像内容的长caption,详细描述了图像的很多内容,细节比较丰富。

混合比例
为提高合成caption对文生图模型的性能,作者做了实验分析了两点:
- 合成caption对文生图模型性能的影响
- 训练过程中合成caption和原始caption的最佳混合比例
作者使用了 CLIP score来评估模型的prompt following能力(评估图像和文本之间语义对齐程度的一个指标)。
- 公式如下:
C ( z i , z t ) = z i ⋅ z t ∥ z i ∥ ∥ z t ∥ C(z_i, z_t) = \frac{z_i \cdot z_t}{\|z_i\| \|z_t\|} C(zi,zt)=∥zi∥∥zt∥zi⋅zt- 其中:
- 图像编码器生成图像嵌入 z i z_i zi
- 文本编码器生成文本嵌入 z t z_t zt
- 图像嵌入 z i z_i zi 和文本嵌入 z t z_t zt 的余弦相似度 C ( z i , z t ) C(z_i, z_t) C(zi,zt)
- z i ⋅ z t z_i \cdot z_t zi⋅zt 是两个嵌入的点积。
- ∥ z i ∥ \|z_i\| ∥zi∥ 和 ∥ z t ∥ \|z_t\| ∥zt∥ 是各自向量的 L 2 L_2 L2 范数(即向量长度)。
- 余弦相似度的值范围在
[
−
1
,
1
]
[-1, 1]
[−1,1] 之间,表示两者的方向相似程度:
- 接近 1:表示图像和文本语义高度匹配。
- 接近 -1:表示语义完全不匹配。
- 其中:
DALL·E3中最终决定采用95%的合成长Caption+5%的原始Caption作为最终的Caption标签。
论文中指出,DALL·E 3和之前的DALL·E 2一样,是基于latent的diffusion模型(DALL·E 是基于像素空间生成的)。下面是DALL·E 3的一些细节:
- 其VAE采用的是8倍下采样(和SD一样)。
- text encoder采用T5-XXL,之所以用T5-XXL,可能主要有两个原因,一方面T5-XXL可以编码更长的文本,另外一方面是T5-XXL的文本编码能力也更强。(SD3 的三个text encoder中也有T5-XXL,只是由于另外两个text encoder的限制,导致编码只能是77)。
- 这里训练的图像尺寸为256x256(这只是实验,所以低分辨率训练就足够了),采用batch size为2048共训练50W步,这相当于采样了1B样本。
- 论文中并没有说明UNet模型的具体架构,只是说它包含3个stages,应该和SDXL类似(SDXL包含3个stage,只下采样了2次,第一个stage是纯卷积,而后面两个stages包含attention)。
SD系列模型参考:小白也能读懂的AIGC扩散(Diffusion)模型系列讲解
upsample
像之前我们提到的,原始的caption时很短的,DALL·E3中使用95%的合成长Caption+5%的原始Caption作为最终的Caption标签,效果可能就会变差,得到的模型也会“过拟合”到长caption上。
为了解决这个问题,OpenAI采用GPT-4来“upsample”用户的caption,就是扩写。下面展示了如何用GPT-4来进行这个优化,不论用户输入什么样的caption,经过GPT-4优化后就得到了长caption:

其他优化
论文中提到,DALL-E 3也不应简单地归功于在合成caption的数据集上训练,还有其他的一些优化,但没有披露具体的优化策略,下面是论文中提到几种策略:
- 递进式的训练策略(256 -> 512 -> 1024),而且最后也是采用了多尺度训练策略来使模型能够输出各种长宽比的图像
- DALL-E 3额外训练了一个latent decoder来提升图像的细节,特别是文字和人脸方面,这个应该是为了解决VAE所产生的图像畸变。
这两个手段在SD 3中也用到了。
评估方式
对于DALL-E 3的评测,论文是选取了DALL-E 2和SDXL(加上refiner模块)来进行对比。模型评测包括自动评测和人工评测。
自动评测
自动评测主要有3个指标:
- 测评生成图像的CLIP score。
- 采用GPT-4V来进行评测,将生成的图像和对应的text输入到GPT-4V,然后让模型判断生成的图像是否和text一致,如果一致就输出正确,否则就输出不正确。
- T2l-Compbench:与Drawbench类似,只是换了不同的prompts体系和不同的评估模型
评测模型的prompt following能力,并不涉及到图像质量。
人工评测
人工评测主要包括三个方面
- prompt following,给出两张不同的模型生成的图像,让人来选择哪个图像和文本更一致。
- style,这里不给文本,只给两张图像,让人选择更喜欢的那个图像。
- coherence,这里也不给文本,让人从两张图像中选择包含更多真实物体的图像。
参考
AI绘画原理解析:从CLIP、BLIP到DALLE、DALLE 2、DALLE 3、Stable Diffusion(含ControlNet详解)
【论文精读】DALLE3:Improving Image Generation with Better Captions 通过更好的文本标注改进图像生成



















 2290
2290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









