






GAN模型是啥?(李沐老师的视频)
机器学习的模型
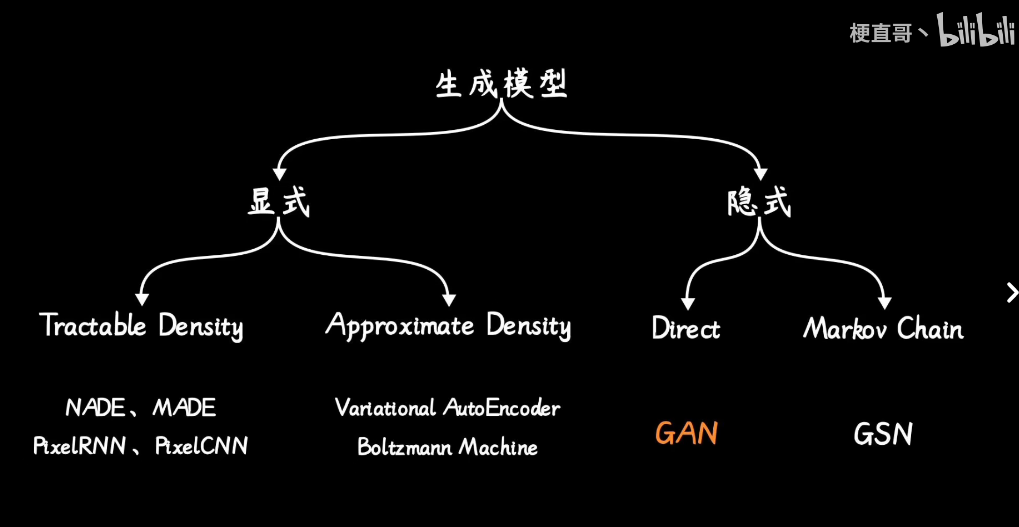
1 分辨模型
2 生成模型



minmax对抗游戏 纳什均衡
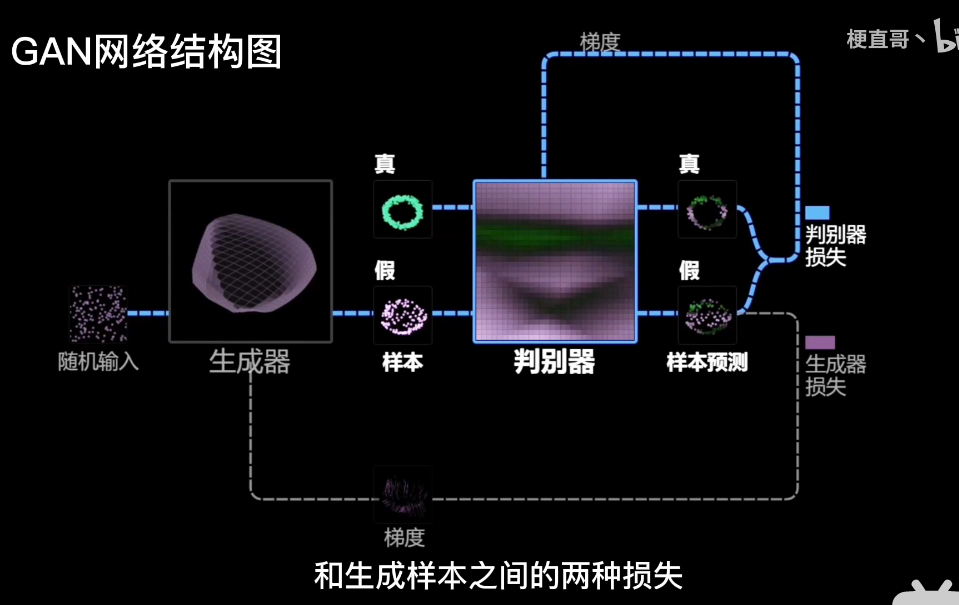
生成器跟判别器一样

最好使得生成器跟判别器更新的速度差不多
gan的收敛需要很多约束




好的我们现在知道了gan模型的全程是生成式对抗模型,其实就是一个生成器跟判别器的博弈的过程,生成器想要生成跟输入媲美的内容,判别器想要识别是真的图片还是生成器生成的内容,然后再这种竞争之中,双方的性能都越来越好,直到达到一种均衡
那么这种均衡是怎么体现出来的呢
也就是说判别器有%50的可能识别对,也有%50的可能识别错
好
我们接下来看cyclegan
Abstract

图像到图像的转换的目标是学习图像之间的映射
问题1:为什么配对训练数据不可用

问题2:什么叫没有成对示例

问题3:为什么映射是高度欠约束的

问题4:包括集合样式迁移、对象变形、季节迁移、照片增强等是啥

Introduction

本文提出的是捕获一个图像集合的特殊特征,弄清楚是怎么从这个特征转化为另一个的,然后这些都没有配对训练示例

说的是人话么


那我有点奇怪,就是这个判别器是怎么知道冬天图像的样子的呢
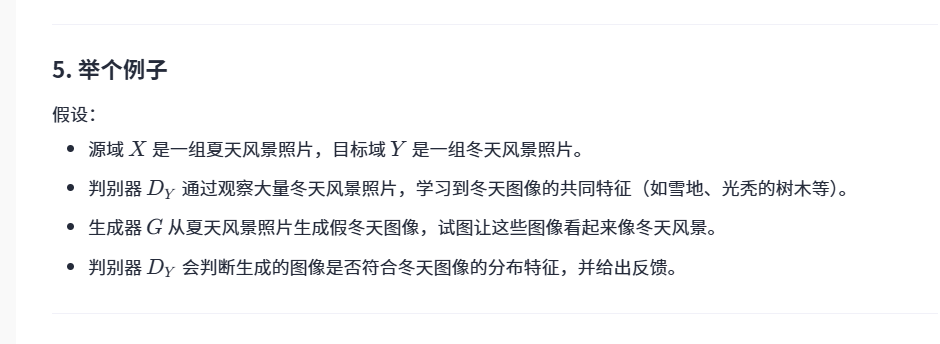
那我明白了,就是生成器也不知道冬天是啥样的,但是会根据判别器的反馈来调整,直到判别器也辨认不出来

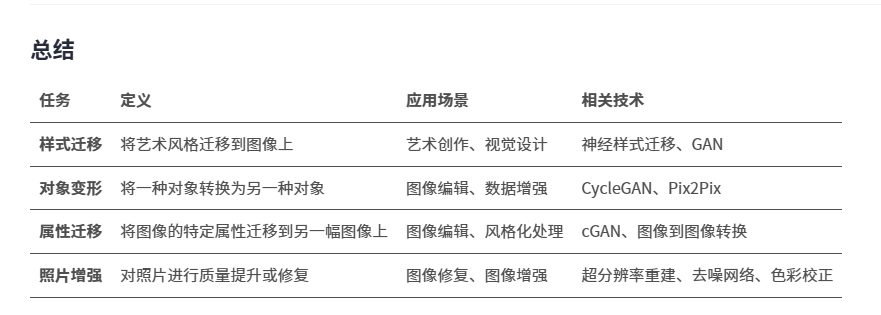
样式迁移就是模仿风格
对象变形就是把马变成斑马
属性迁移就就是调整图像参数
照片增强就是修复损坏照片或提高照片的清晰度
什么问题呢?就是很难独立地优化对抗目标,还有就是所有输入都对应相同的输出,我们就要加入更多的结构了,最好是一致的,就比如说英语翻译到了法语,然后再翻译回来,跟原文是一样的
Related work

对抗性损失的概念使得图像逼真,无法区分


讲的是coupledgan 基于源图像计算出值,用来符合目标域的元素
所以这段话讲的是有配对的翻译还是无配对的呢
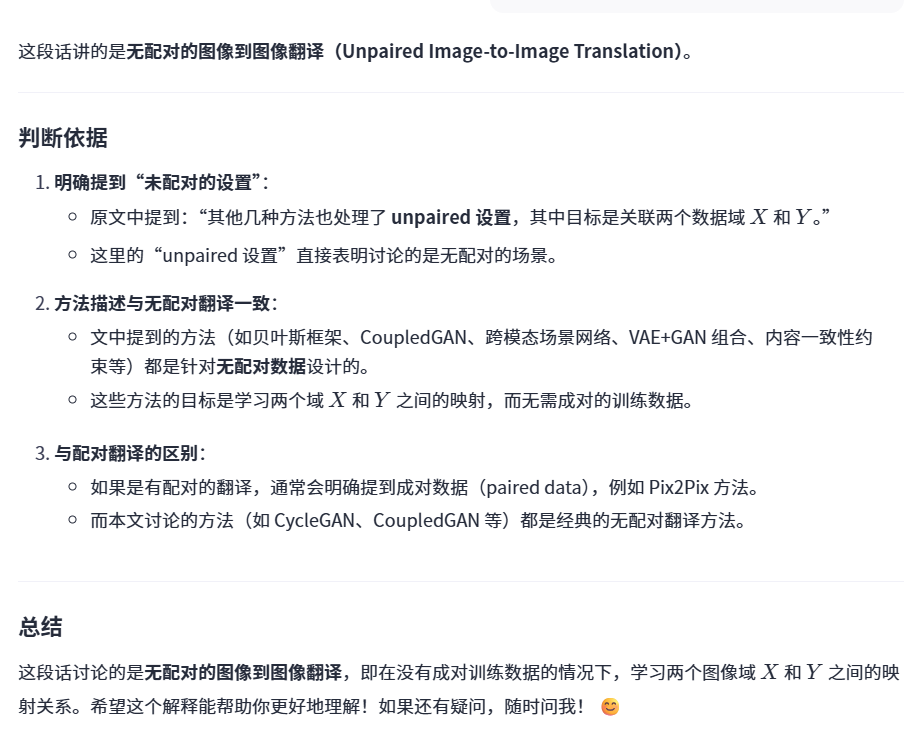

我们的公式好在哪里呢?
1 我们的公式不依赖预定义的相似函数,也没有假设低维的嵌入空间
2 方法更通用
什么是对偶学习



那其实cyclegan也是受到对偶学习的启发啊
循环一致性

就是上面说的,转换来转换去是一样的
神经风格迁移

感觉像是跟泛化性差不多的东西? 这种想法错了!!!
并不是一个模型对应不同的风格,而是在域中不仅仅是对特定的图像结合,可以对域内的多个元素进行操作

图像风格迁移是一种通过将一张图像的风格应用到另一张图像的内容上,从而生成一张新图像的技术。这种技术通常基于深度学习模型,特别是卷积神经网络(CNN)。
Formulation
我们的目标是学习到X域到Y域的映射函数
有两个术语
对抗性损失 周期一致性损失
3.1. Adversarial Loss

符号的含义



为什么判别器里面有着生成器的公式

梯度为什么会消失


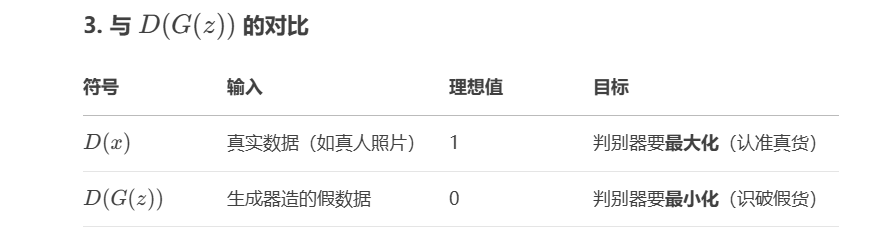

 为什么使用log函数,是因为防止梯度消失
为什么使用log函数,是因为防止梯度消失


sigmoid饱和区是啥


3.2. Cycle Consistency Loss
cyclegan的创新点是啥,是怎么实现的,有什么作用?


总期望
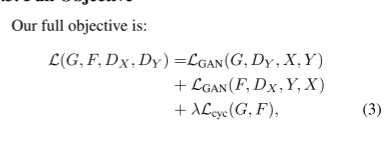



Implementation
作者把负对数似然估计法变成了最小二乘估计法



model oscillation 模型震荡

为什么要加入图像缓冲区



调参
Results

CycleGAN通过定量指标(AMT、FCN、分类精度)和定性对比(视觉结果、消融实验)综合评估,证明了其在非配对图像翻译中的优越性,尤其在保留语义和生成真实感方面
5.1.1 Evaluation Metrics
AMT perceptual studies
FCN score
Semantic segmentation metrics
基线使用的模型如下

Cyclegan代码解释
1.导入库
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import os
import itertools

2 定义生成器跟判别器
class Generator(nn.Module):
def __init__(self, input_channels, output_channels):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(input_channels, 64, kernel_size=7, stride=1, padding=3),
nn.InstanceNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 128, kernel_size=3, stride=2, padding=1),
nn.InstanceNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, 256, kernel_size=3, stride=2, padding=1),
nn.InstanceNorm2d(256),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(256, 128, kernel_size=3, stride=2, padding=1, output_padding=1),
nn.InstanceNorm2d(128),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2, padding=1, output_padding=1),
nn.InstanceNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, output_channels, kernel_size=7, stride=1, padding=3),
nn.Tanh()
)
def forward(self, x):
return self.model(x)
生成器完毕
class Discriminator(nn.Module):
def __init__(self, input_channels):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(input_channels, 64, kernel_size=4, stride=2, padding=1),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, 128, kernel_size=4, stride=2, padding=1),
nn.InstanceNorm2d(128),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(128, 256, kernel_size=4, stride=2, padding=1),
nn.InstanceNorm2d(256),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(256, 512, kernel_size=4, stride=1, padding=1),
nn.InstanceNorm2d(512),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(512, 1, kernel_size=4, stride=1, padding=1)
)
def forward(self, x):
return self.model(x)
判别器搞定
代码讲解


先经过一个卷积核大小为7*7的卷积操作,再经过一个InstanceNorm的操作,关于这个Norm操作,我发现它还是蛮有讲究的
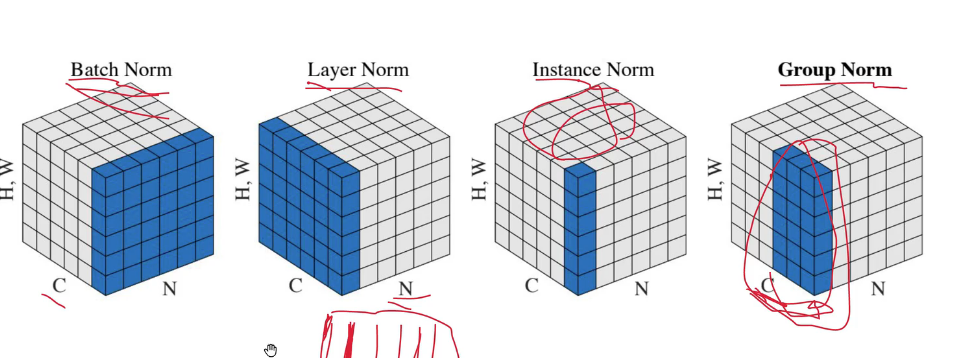
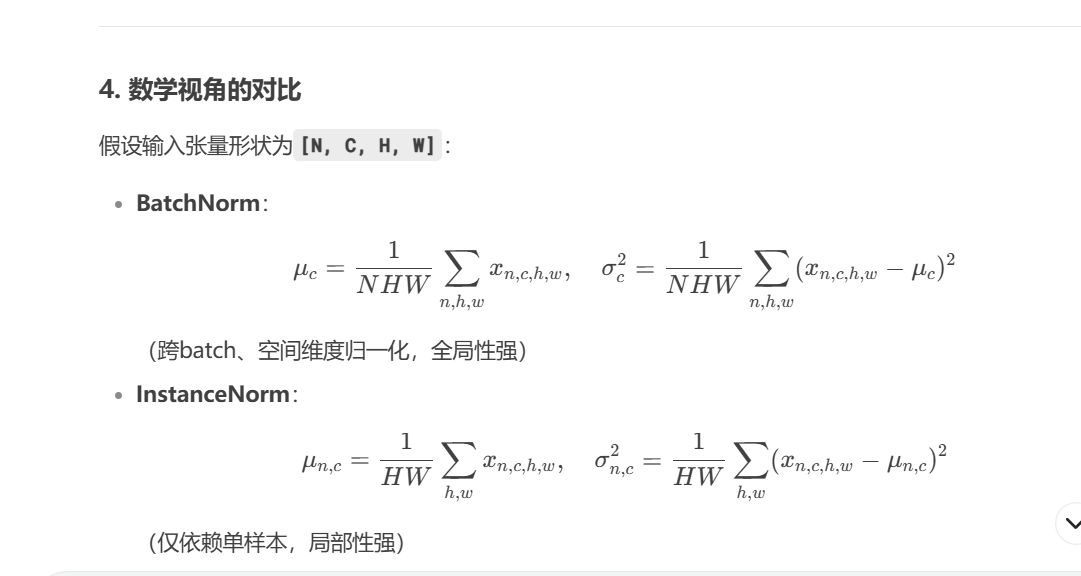
批次归一化,层归一化,实例归一化,组归一化
生成器
GAN中使用的是实例归一化InstanceNorm,它的好处就是对每个通道单独计算方差跟均值,这样的话虽然它忽略了与其他样本跟通道的关系,但是保留了样本间的独立性,
输入图像的风格保留下来了,因为输出图像的风格只受到输入图像的影响,而不是整体数据集的,因此针对单个通道进行归一化的InstanceNorm更好
接着就是对特征图反复的进行卷积操作,归一化,relu函数
总共有六层
最后使用tanh函数
判别器
代码跟生成器差不多,就是把relu换为了Leakyrelu(为了增强鲁棒性),然后没有tanh函数
3 定义CycleGAN 模型
class CycleGAN(nn.Module):
def __init__(self, input_channels, output_channels):
super(CycleGAN, self).__init__()
self.G_A2B = Generator(input_channels, output_channels)
self.G_B2A = Generator(input_channels, output_channels)
self.D_A = Discriminator(input_channels)
self.D_B = Discriminator(input_channels)
def forward(self, x):
fake_B = self.G_A2B(x)
fake_A = self.G_B2A(fake_B)
return fake_A, fake_B
输入x,生成的图片为fake_B 然后把fake_B再生成回去,作为循环一致性损失的样本
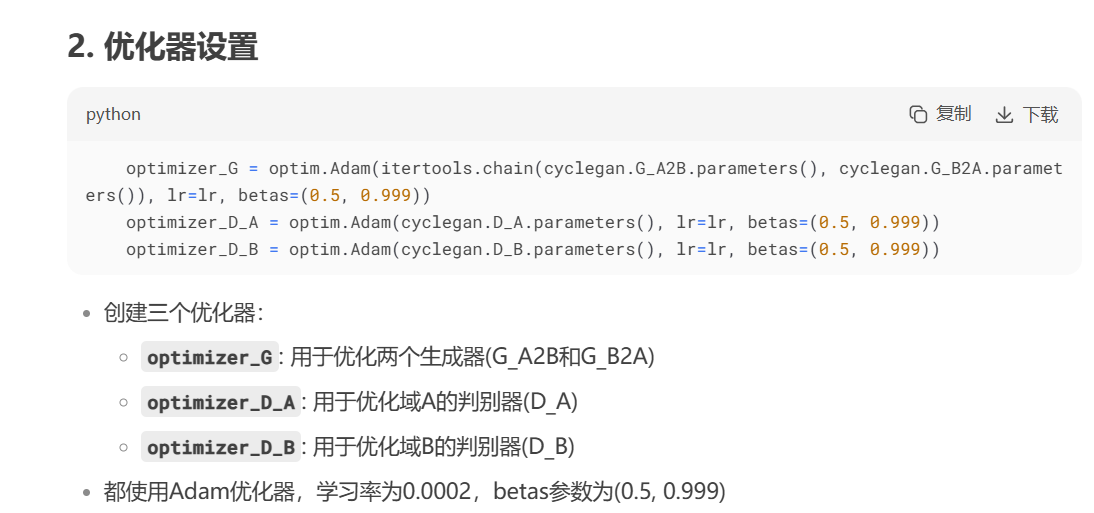
4 定义损失函数跟优化器
def train_cyclegan(cyclegan, dataloader_A, dataloader_B, num_epochs=200, lr=0.0002, device='cuda'):
cyclegan = cyclegan.to(device)
criterion_GAN = nn.MSELoss()
criterion_cycle = nn.L1Loss()
criterion_identity = nn.L1Loss()
optimizer_G = optim.Adam(itertools.chain(cyclegan.G_A2B.parameters(), cyclegan.G_B2A.parameters()), lr=lr, betas=(0.5, 0.999))
optimizer_D_A = optim.Adam(cyclegan.D_A.parameters(), lr=lr, betas=(0.5, 0.999))
optimizer_D_B = optim.Adam(cyclegan.D_B.parameters(), lr=lr, betas=(0.5, 0.999))
for epoch in range(num_epochs):
for i, (real_A, real_B) in enumerate(zip(dataloader_A, dataloader_B)):
real_A = real_A.to(device)
real_B = real_B.to(device)

训练生成器
# Train Generators
optimizer_G.zero_grad()
# Identity loss
same_B = cyclegan.G_A2B(real_B)
loss_identity_B = criterion_identity(same_B, real_B)
same_A = cyclegan.G_B2A(real_A)
loss_identity_A = criterion_identity(same_A, real_A)

# GAN loss
fake_B = cyclegan.G_A2B(real_A)
pred_fake_B = cyclegan.D_B(fake_B)
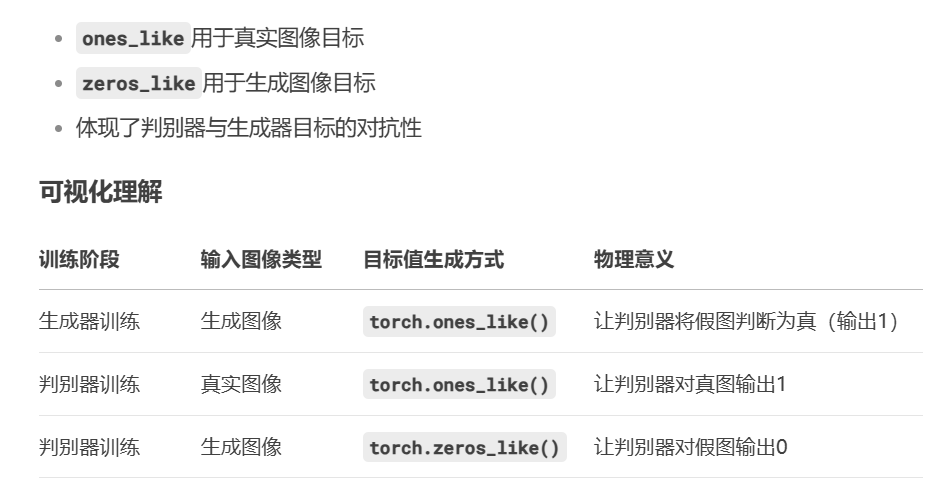
loss_GAN_A2B = criterion_GAN(pred_fake_B, torch.ones_like(pred_fake_B))
fake_A = cyclegan.G_B2A(real_B)
pred_fake_A = cyclegan.D_A(fake_A)
loss_GAN_B2A = criterion_GAN(pred_fake_A, torch.ones_like(pred_fake_A))
真实图像想让自己接近1

# Cycle loss
recovered_A = cyclegan.G_B2A(fake_B)
loss_cycle_A = criterion_cycle(recovered_A, real_A)
recovered_B = cyclegan.G_A2B(fake_A)
loss_cycle_B = criterion_cycle(recovered_B, real_B)

# Total loss
loss_G = loss_GAN_A2B + loss_GAN_B2A + loss_cycle_A + loss_cycle_B + loss_identity_A + loss_identity_B
loss_G.backward()
optimizer_G.step()

判别器的训练
# Train Discriminator A
optimizer_D_A.zero_grad()
pred_real_A = cyclegan.D_A(real_A)
loss_D_real_A = criterion_GAN(pred_real_A, torch.ones_like(pred_real_A))
pred_fake_A = cyclegan.D_A(fake_A.detach())
loss_D_fake_A = criterion_GAN(pred_fake_A, torch.zeros_like(pred_fake_A))
loss_D_A = (loss_D_real_A + loss_D_fake_A) * 0.5
loss_D_A.backward()
optimizer_D_A.step()
# Train Discriminator B
optimizer_D_B.zero_grad()
pred_real_B = cyclegan.D_B(real_B)
loss_D_real_B = criterion_GAN(pred_real_B, torch.ones_like(pred_real_B))
pred_fake_B = cyclegan.D_B(fake_B.detach())
loss_D_fake_B = criterion_GAN(pred_fake_B, torch.zeros_like(pred_fake_B))
loss_D_B = (loss_D_real_B + loss_D_fake_B) * 0.5
loss_D_B.backward()
optimizer_D_B.step()
虚假图像则偏向于0

if i % 100 == 0:
print(f"Epoch [{epoch}/{num_epochs}] Batch [{i}/{len(dataloader_A)}] "
f"Loss D_A: {loss_D_A.item()} Loss D_B: {loss_D_B.item()} "
f"Loss G: {loss_G.item()}")
torch.save(cyclegan.state_dict(), 'cyclegan.pth')

是怎做到最小化跟最大化的?

ones_like 和 zeros_like
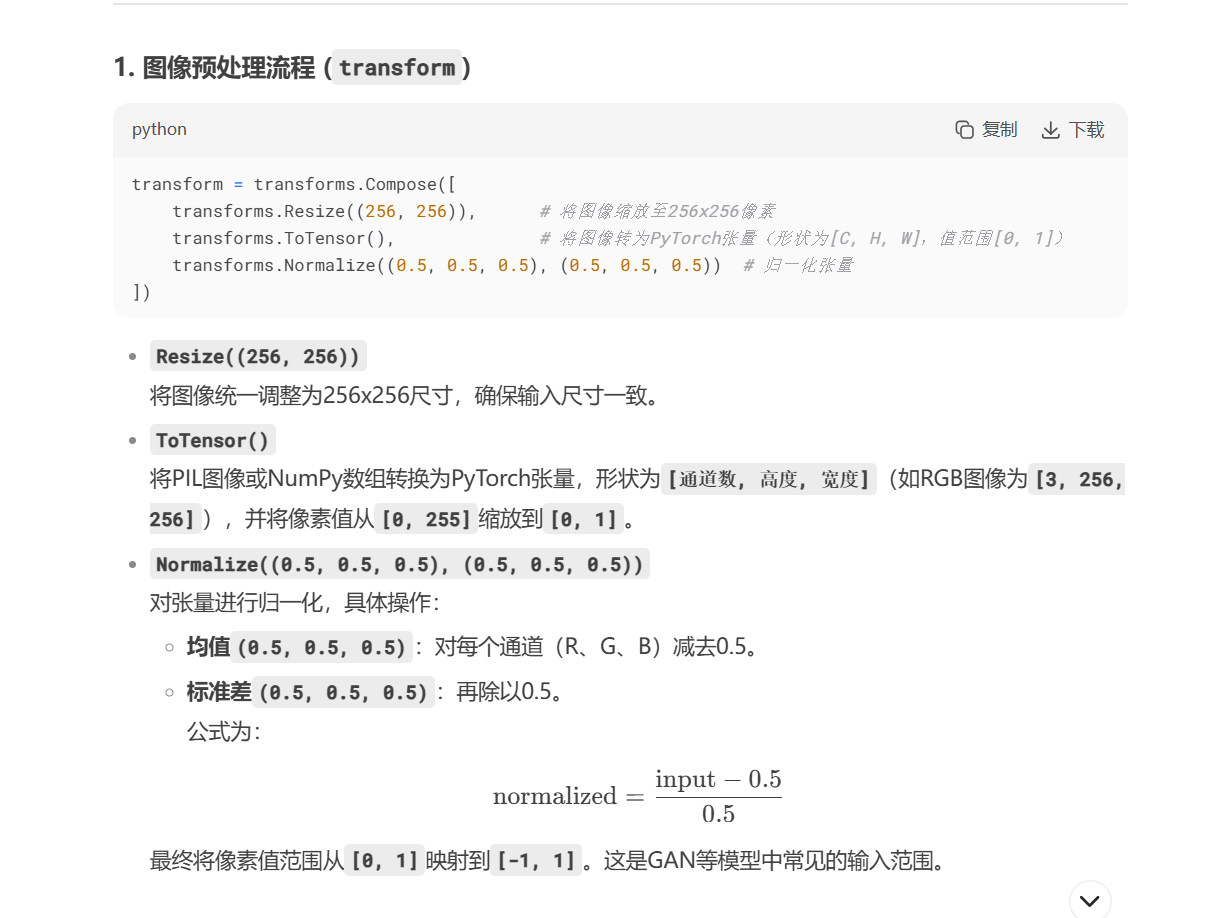
5 数据加载和预处理
transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
dataset_A = datasets.ImageFolder(root='path_to_dataset_A', transform=transform)
dataset_B = datasets.ImageFolder(root='path_to_dataset_B', transform=transform)
dataloader_A = DataLoader(dataset_A, batch_size=1, shuffle=True)
dataloader_B = DataLoader(dataset_B, batch_size=1, shuffle=True)

6 训练模型
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
cyclegan = CycleGAN(input_channels=3, output_channels=3)
train_cyclegan(cyclegan, dataloader_A, dataloader_B, num_epochs=200, device=device)
7 测试模型
def test_cyclegan(cyclegan, dataloader_A, device='cuda'):
cyclegan.load_state_dict(torch.load('cyclegan.pth'))
cyclegan = cyclegan.to(device)
cyclegan.eval()

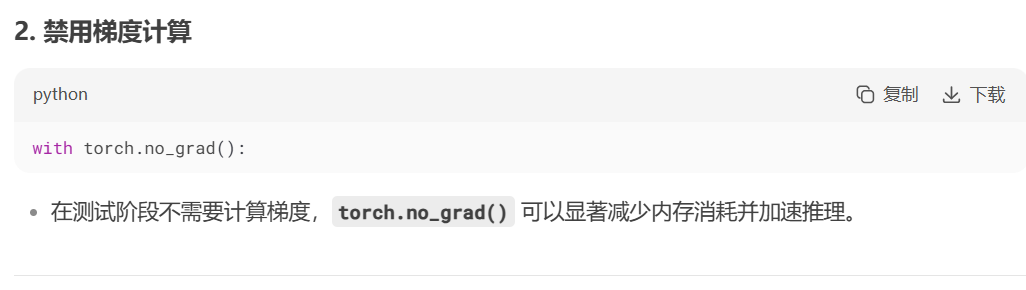
with torch.no_grad():
for i, real_A in enumerate(dataloader_A):
real_A = real_A.to(device)

fake_B = cyclegan.G_A2B(real_A)
fake_A = cyclegan.G_B2A(fake_B)
plt.figure(figsize=(10, 5))
plt.subplot(1, 3, 1)
plt.title("Real A")
plt.imshow(real_A.cpu().squeeze().permute(1, 2, 0) * 0.5 + 0.5)
plt.subplot(1, 3, 2)
plt.title("Fake B")
plt.imshow(fake_B.cpu().squeeze().permute(1, 2, 0) * 0.5 + 0.5)
plt.subplot(1, 3, 3)
plt.title("Recovered A")
plt.imshow(fake_A.cpu().squeeze().permute(1, 2, 0) * 0.5 + 0.5)
plt.show()
if i == 5:
break

test_cyclegan(cyclegan, dataloader_A, device=device)
8 运行代码+输出结果
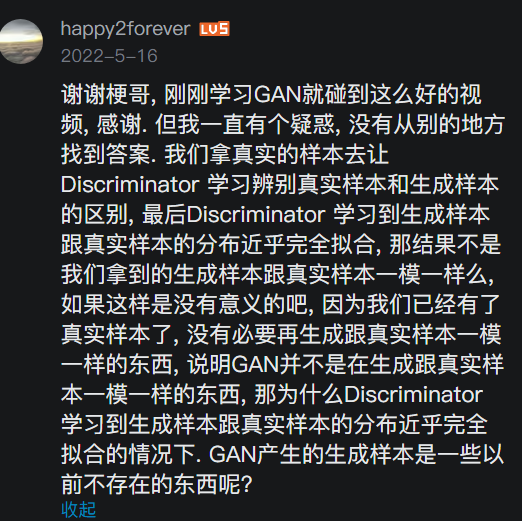
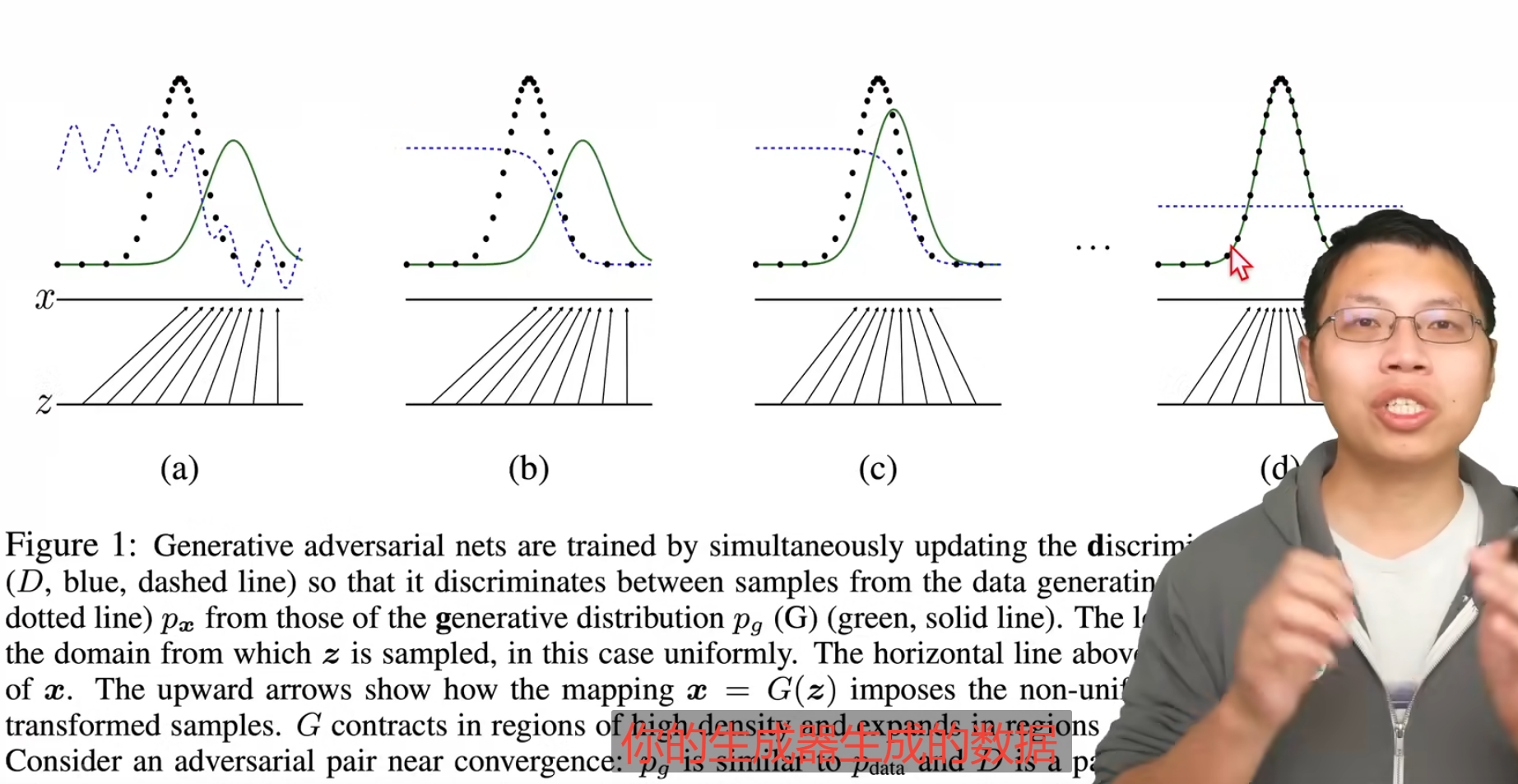
引申 为何GAN能够生成图像呢?



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









