







目录
在Redis缓存应用中,常常会遇到缓存穿透、缓存击穿和缓存雪崩这些问题。这些问题如果不能得到有效的解决,会严重影响Redis缓存的性能和可用性。
一、缓存穿透
描述:
缓存穿透:是指查询一个一定不存在的数据,由于缓存是不命中时需要从数据库查询,查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,进而给数据库带来压力,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
解决方案:
数据预热:将热门数据提前加载到缓存中,避免缓存击穿。
布隆过滤器:在查询缓存之前,先判断查询的key是否在布隆过滤器中存在,如果不存在,直接返回;如果存在,再查询缓存或数据库。
布隆过滤器(Bloom Filter,简称BF)由Burton Howard Bloom在1970年提出,是一种空间效率高的概率型数据结构。
布隆过滤器专门用来检测集合中是否存在特定的元素。
如果在平时我们要判断一个元素是否在一个集合中,通常会采用查找比较的方法,下面分析不同的数据结构查找效率:
采用线性表存储,查找时间复杂度为O(N)采用平衡二叉排序树(AVL、红黑树)存储,查找时间复杂度为O(logN)采用哈希表存储,考虑到哈希碰撞,整体时间复杂度也要O[log(n/m)]当需要判断一个元素是否存在于海量数据集合中,不仅查找时间慢,还会占用大量存储空间。接下来看一下布隆过滤器如何解决这个问题。
布隆过滤器设计思想
布隆过滤器由一个长度为m比特的位数组(bit array)与k个哈希函数(hash function)组成的数据结构。位数组初始化均为0,所有的哈希函数都可以分别把输入数据尽量均匀地散列。
当要向布隆过滤器中插入一个元素时,该元素经过k个哈希函数计算产生k个哈希值,以哈希值作为位数组中的下标,将所有k个对应的比特值由0置为1。
当要查询一个元素时,同样将其经过哈希函数计算产生哈希值,然后检查对应的k个比特值:如果有任意一个比特为0,表明该元素一定不在集合中;如果所有比特均为1,表明该集合有可能性在集合中。为什么不是一定在集合中呢?因为不同的元素计算的哈希值有可能一样,会出现哈希碰撞,导致一个不存在的元素有可能对应的比特位为1,这就是所谓“假阳性”(false positive)。相对地,“假阴性”(false negative)在BF中是绝不会出现的。
总结一下:布隆过滤器认为不在的,一定不会在集合中;布隆过滤器认为在的,可能在也可能不在集合中。
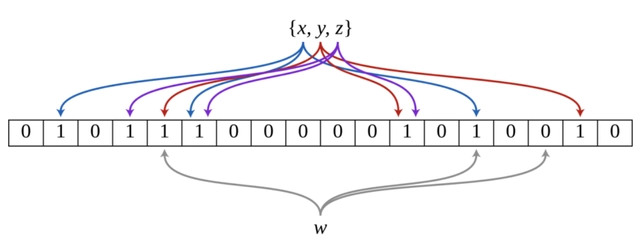
举个例子:下图是一个布隆过滤器,共有18个比特位,3个哈希函数。集合中三个元素x,y,z通过三个哈希函数散列到不同的比特位,并将比特位置为1。当查询元素w时,通过三个哈希函数计算,发现有一个比特位的值为0,可以肯定认为该元素不在集合中。
布隆过滤器优缺点
优点:
节省空间:不需要存储数据本身,只需要存储数据对应hash比特位时间复杂度低:插入和查找的时间复杂度都为O(k),k为哈希函数的个数缺点:
存在假阳性:布隆过滤器判断存在,可能出现元素不在集合中;判断准确率取决于哈希函数的个数不能删除元素:如果一个元素被删除,但是却不能从布隆过滤器中删除,这也是造成假阳性的原因了布隆过滤器适用场景
爬虫系统url去重垃圾邮件过滤黑名单(2)返回空对象
当缓存未命中,查询持久层也为空,可以将返回的空对象写到缓存中,这样下次请求该key时直接从缓存中查询返回空对象,请求不会落到持久层数据库。为了避免存储过多空对象,通常会给空对象设置一个过期时间。
这种方法会存在两个问题:
如果有大量的key穿透,缓存空对象会占用宝贵的内存空间。空对象的key设置了过期时间,在这段时间可能会存在缓存和持久层数据不一致的场景。
二、缓存击穿
描述:
缓存击穿:是指热点key在某个时间点过期的时候,而恰好在这个时间点对这个Key有大量的并发请求过来,简单的说就是缓存中没有但数据库中有的数据(缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力
解决方案:
- 设置热点数据不过期:热点数据不过期,避免在热点数据失效的瞬间,大量的请求进来,形成缓存击穿。
- 加互斥锁:在缓存失效后,加互斥锁,避免同时有多个线程请求数据库,保证只有一个线程请求数据库,其他线程等待。
static Lock reenLock = new ReentrantLock();
public List<String> getData04() throws InterruptedException {
List<String> result = new ArrayList<String>();
// 从缓存读取数据
result = getDataFromCache();
if (result.isEmpty()) {
if (reenLock.tryLock()) {
try {
System.out.println("我拿到锁了,从DB获取数据库后写入缓存");
// 从数据库查询数据
result = getDataFromDB();
// 将查询到的数据写入缓存
setDataToCache(result);
} finally {
reenLock.unlock();// 释放锁
}
} else {
result = getDataFromCache();// 先查一下缓存
if (result.isEmpty()) {
System.out.println("我没拿到锁,缓存也没数据,先小憩一下");
Thread.sleep(100);// 小憩一会儿
return getData04();// 重试
}
}
}
return result;
}
说明:
1)缓存中有数据,直接走上述代码13行后就返回结果了
2)缓存中没有数据,第1个进入的线程,获取锁并从数据库去取数据,没释放锁之前,其他并行进入的线程会等待100ms,再重新去缓存取数据。这样就防止都去数据库重复取数据,重复往缓存中更新数据情况出现。
3)当然这是简化处理,理论上如果能根据key值加锁就更好了,就是线程A从数据库取key1的数据并不妨碍线程B取key2的数据,上面代码明显做不到这点。
三、缓存雪崩
描述:
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决方案:
- 分布式锁:在缓存失效的时候,加分布式锁,避免大量请求同时落到数据库上。
- 数据分布:如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中。
- 设置热点数据永远不过期。
















 2239
2239











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











