










Task04 基于相似度的方法
文章目录
在本系列的第一篇博客中,我们提到了有基于相似度的异常检测算法,这一个博客中我将对这类算法做具体的阐述。
基于相似度的方法一般分类两类:一是基于距离的方法,二是基于密度的方法。
1 基于距离的方法
基于距离的方法是一种常见的适用于各种数据域的异常检测算法,它基于最近邻距离来定义异常值。基于距离的检测算法的基本原理集中于观测值之间的距离计算。一个点被视为离其附近的邻居较远的离群值。 此类方法不仅适用于多维数值数据,在其他许多领域,例如分类数据,文本数据,时间序列数据和序列数据等方面也有广泛的应用。
假设
基于距离的异常检测有这样一个前提假设,即异常点的 k k k 近邻距离(KNN)要远大于正常点。解决问题的最简单方法是使用嵌套循环。 第一层循环遍历每个数据,第二层循环进行异常判断,需要计算当前点与其他点的距离,一旦已识别出多于 k k k 个数据点与当前点的距离在 D D D 之内,则将该点自动标记为非异常值。 这样计算的时间复杂度为 O ( N 2 ) O(N^{2}) O(N2),当数据量比较大时,这样计算是及不划算的。 因此,需要修剪方法以加快距离计算。
注:下文中会讲到用KNN算法做异常检测
在基于距离的算法中,又有两类,一是基于单元格的方法,二是基于索引的方法。
1.1 基于索引的方法
对于一个给定数据集,基于索引的方法利用多维索引结构(如
R
\mathrm{R}
R 树、
k
−
d
k-d
k−d 树)来搜索每个数据对象
A
A
A 在半径
D
D
D 范围 内的相邻点。设
M
M
M 是一个异常值在其
D
D
D -邻域内允许含有对象的最多个数,若发现某个数据对象
A
A
A 的
D
D
D -邻域内出现
M
+
1
M+1
M+1 甚至更多个相邻点, 则判定对象
A
A
A 不是异常值。该算法时间复杂度在最坏情况下为
O
(
k
N
2
)
,
O\left(k N^{2}\right),
O(kN2), 其中
k
k
k 是数据集维数,
N
N
N 是数据集包含对象的个数。该算法在数据集的维数增加时具有较好的扩展性,但是时间复杂度的估算仅考虑了搜索时间,而构造索引的任务本身就需要密集复杂的计算量。
1.2 基于单元格的方法
在基于单元格的技术中,数据空间被划分为单元格,单元格的宽度是阈值D和数据维数的函数。具体地说,每个维度被划分成宽度最多为 D 2 ⋅ d \frac{D}{{2 \cdot \sqrt d }} 2⋅dD 单元格。在给定的单元以及相邻的单元中存在的数据点满足某些特性,这些特性可以让数据被更有效的处理。
其中:①阈值距离 D ,点与点之间距离超过D ,则不再认为这两个点为“近邻”。②d 为dimensionality,维度.

以二维情况为例,此时网格间的距离为 D 2 ⋅ d \frac{D}{{2 \cdot \sqrt d }} 2⋅dD ,需要记住的一点是,网格单元的数量基于数据空间的分区,并且与数据点的数量无关。
网格距离是以下目标而设定的:
L1邻居中的所有点与当前网格所有点的距离均小于等于阈值距离D,即均为"近邻"。
L2以外的邻居与当前网格所有点的距离均大于阈值距离D,即均为"远邻"
只有L2中的邻居节点,无法判断与当前网格中点到距离与阈值距离的关系,需要进行显式距离计算。
判定规则:
- 如果一个单元格中包含超过 k k k 个数据点及其 L 1 L_{1} L1 邻居,那么这些数据点都不是异常值。
- 如果单元 A A A 及其相邻 L 1 L_{1} L1 和 L 2 L_{2} L2 中包含少于 k k k 个数据点,则单元A中的所有点都是异常值。
1.3 KNN算法及其实现
KNN算法:(K Near Neighbor),k个最近的邻居,即每个样本都可以用它最接近的k个邻居来代表。
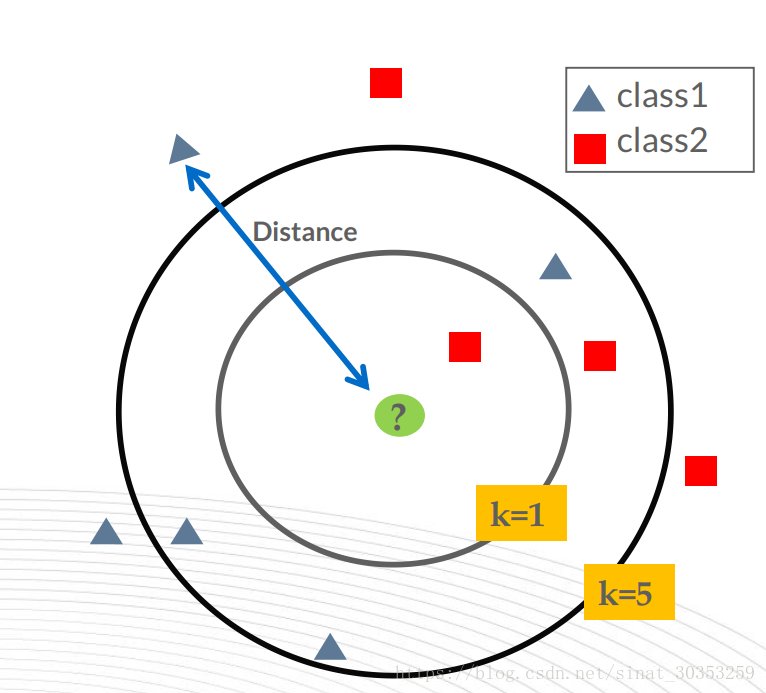
关键因素主要有两个,K值的选取和点距离的计算。
k的选取:需要先验知识做支撑
距离计算:有很多距离的度量方式,这里可以参考一下这篇文章:https://zhuanlan.zhihu.com/p/23272822
KNN做异常检测:
代码及效果:
# -*- coding: utf-8 -*-
"""Example of using kNN for outlier detection
"""
# Author: Yue Zhao <zhaoy@cmu.edu>
# License: BSD 2 clause
from __future__ import division
from __future__ import print_function
import os
import sys
# temporary solution for relative imports in case pyod is not installed
# if pyod is installed, no need to use the following line
sys.path.append(
os.path.abspath(os.path.join(os.path.dirname("__file__"), '..')))
from pyod.models.knn import KNN
from pyod.utils.data import generate_data
from pyod.utils.data import evaluate_print
from pyod.utils.example import visualize
if __name__ == "__main__":
contamination = 0.1 # percentage of outliers
n_train = 200 # number of training points
n_test = 100 # number of testing points
# Generate sample data
X_train, y_train, X_test, y_test = \
generate_data(n_train=n_train,
n_test=n_test,
n_features=2,
contamination=contamination,
random_state=42)
# train kNN detector
clf_name = 'KNN'
clf = KNN()
clf.fit(X_train)
# get the prediction labels and outlier scores of the training data
y_train_pred = clf.labels_ # binary labels (0: inliers, 1: outliers)
y_train_scores = clf.decision_scores_ # raw outlier scores
# get the prediction on the test data
y_test_pred = clf.predict(X_test) # outlier labels (0 or 1)
y_test_scores = clf.decision_function(X_test) # outlier scores
# evaluate and print the results
print("\nOn Training Data:")
evaluate_print(clf_name, y_train, y_train_scores)
print("\nOn Test Data:")
evaluate_print(clf_name, y_test, y_test_scores)
# visualize the results
visualize(clf_name, X_train, y_train, X_test, y_test, y_train_pred,
y_test_pred, show_figure=True, save_figure=True)
On Training Data:
KNN ROC:0.9992, precision @ rank n:0.95
On Test Data:
KNN ROC:1.0, precision @ rank n:1.0

2 基于密度的方法
这些方法的核心原理是可以在低密度区域中找到离群值,而正常值则位于密集区域中。
常见的算法:Local Outlier Factor (LOF)局部因子。
基于距离的检测适用于各个集群的密度较为均匀的情况。在下图中,离群点B容易被检出,而若要检测出较为接近集群的离群点A,则可能会将一些集群边缘的点当作离群点丢弃。而LOF等基于密度的算法则可以较好地适应密度不同的集群情况。
2.1 基于密度的度量
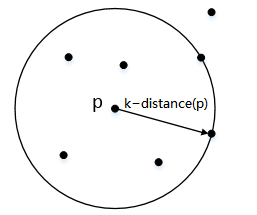
k-距离(k-distance§):
对于数据集 D D D中的给定对象 p p p,对象 p p p与数据集 D D D中任意点 o o o的距离为 d ( p , o ) d(p,o) d(p,o)。我们把数据集 D D D中与对象 p p p距离最近的 k k k个相邻点的最远距离表示为 k − d i s t a n c e ( p ) k-distance(p) k−distance(p),把距离对象 p p p距离第 k k k近的点表示为 o k o_k ok,那么给定对象 p p p和点 o k o_k ok之间的距离 d ( p , o k ) = k − d i s t a n c e ( p ) d(p,o_k)=k − d i s t a n c e ( p ) d(p,ok)=k−distance(p),满足:
- 在集合 D D D中至少有不包括 p p p在内的 k k k个点 o ′ o' o′,其中 o ′ ∈ D { p } o'∈D\{p\} o′∈D{p},满足 d ( p , o ′ ) ≤ d ( p , o k ) d(p,o')≤d(p,o_k) d(p,o′)≤d(p,ok)
- 在集合 D D D中最多有不包括 p p p在内的 k − 1 k-1 k−1个点 o ′ o' o′,其中 o ′ ∈ D { p } o'∈D\{p\} o′∈D{p},满足 d ( p , o ′ ) < d ( p , o k ) d(p,o')<d(p,o_k) d(p,o′)<d(p,ok)
直观一些理解,就是以对象 p p p为中心,对数据集 D D D中的所有点到 p p p的距离进行排序,距离对象 p p p第 k k k近的点 o k o_k ok与 p p p之间的距离就是k-距离。
k-邻域(k-distance neighborhood):
由k-距离,我们扩展到一个点的集合——到对象
p
p
p的距离小于等于k-距离的所有点的集合,我们称之为k-邻域:$N_{k − d i s t a n c e ( p )}( p ) = { q ∈ D \backslash{ p } ∣ d ( p , q ) ≤ k − d i s t a n c e ( p )}
$。
-
k-邻域包含对象 p p p的第 k k k距离以内的所有点,包括第 k k k距离点。
-
对象 p p p的第 k k k邻域点的个数$ ∣ N_k§∣ ≥ k$。
在二维平面上展示出来的话,对象 p p p的k-邻域实际上就是以对象 p p p为圆心、k-距离为半径围成的圆形区域。就是说,k-邻域已经从“距离”这个概念延伸到“空间”了。
可达距离(reachability distance):
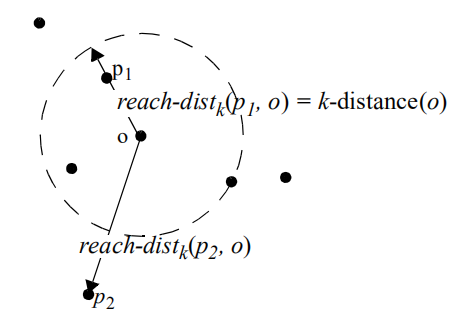
-
p 1 p_1 p1在对象 o o o的k-邻域内, d ( p 1 , o ) < k − d i s t a n c e ( o ) d ( p_1 , o )<k−distance( o ) d(p1,o)<k−distance(o),
可达距离 r e a c h − d i s t k ( p 1 , o ) = k − d i s t a n c e ( o ) r e a c h−d i s t_ k ( p_1 , o ) = k−distance( o ) reach−distk(p1,o)=k−distance(o) ;
-
p 2 p_2 p2在对象 o o o的k-邻域外, d ( p 2 , o ) > k − d i s t a n c e ( o ) d ( p_2 , o )>k−distance( o ) d(p2,o)>k−distance(o),
可达距离 r e a c h − d i s t k ( p 2 , o ) = d ( p 2 , o ) r e a c h−d i s t_ k ( p_2 , o ) = d ( p_2 , o ) reach−distk(p2,o)=d(p2,o) ;
局部可达密度(local reachability density):
我们可以将“密度”直观地理解为点的聚集程度,就是说,点与点之间距离越短,则密度越大。在这里,我们使用数据集 D D D中对象 p p p与对象 o o o的k-邻域内所有点的可达距离平均值的倒数(注意,不是导数)来定义局部可达密度。
2.2 LOF
局部异常因子LOF.
如何得到LOF值?
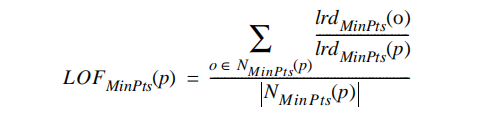
不难看出, p p p的局部可达密度越低,且它的 M i n P t s MinPts MinPts近邻的平均局部可达密度越高,则 p p p的LOF值越高。
emsp; 如果这个比值越接近1,说明o的邻域点密度差不多,o可能和邻域同属一簇;如果这个比值小于1,说明o的密度高于其邻域点密度,o为密集点;如果这个比值大于1,说明o的密度小于其邻域点密度,o可能是异常点。
由公式计算出的LOF数值,就是我们所需要的离群点分数。
LOF实战
1首先构造正常点和异常点
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.neighbors import LocalOutlierFactor
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus']=False
pd.set_option('display.max_columns', None)
pd.set_option('display.max_rows', None)
np.random.seed(61)
# 构造两个数据点集群
X_inliers1 = 0.2 * np.random.randn(100, 2)
X_inliers2 = 0.5 * np.random.randn(100, 2)
X_inliers = np.r_[X_inliers1 + 2, X_inliers2 - 2]
# 构造一些离群的点
X_outliers = np.random.uniform(low=-4, high=4, size=(20, 2))
# 拼成训练集
X = np.r_[X_inliers, X_outliers]
n_outliers = len(X_outliers)
ground_truth = np.ones(len(X), dtype=int)
# 打标签,群内点构造离群值为1,离群点构造离群值为-1
ground_truth[-n_outliers:] = -1
plt.title('构造数据集 (LOF)')
plt.scatter(X[:-n_outliers, 0], X[:-n_outliers, 1], color='b', s=5, label='集群点')
plt.scatter(X[-n_outliers:, 0], X[-n_outliers:, 1], color='orange', s=5, label='离群点')
plt.axis('tight')
plt.xlim((-5, 5))
plt.ylim((-5, 5))
legend = plt.legend(loc='upper left')
legend.legendHandles[0]._sizes = [10]
legend.legendHandles[1]._sizes = [20]
plt.show()
正常点和异常点的分布

2 使用LOF检测异常点
# 训练模型(找出每个数据的实际离群值)
clf = LocalOutlierFactor(n_neighbors=20, contamination=0.1)
# 对单个数据集进行无监督检测时,以1和-1分别表示非离群点与离群点
y_pred = clf.fit_predict(X)
# 找出构造离群值与实际离群值不同的点
n_errors = y_pred != ground_truth
X_pred = np.c_[X,n_errors]
X_scores = clf.negative_outlier_factor_
# 实际离群值有正有负,转化为正数并保留其差异性(不是直接取绝对值)
X_scores_nor = (X_scores.max() - X_scores) / (X_scores.max() - X_scores.min())
X_pred = np.c_[X_pred,X_scores_nor]
X_pred = pd.DataFrame(X_pred,columns=['x','y','pred','scores'])
X_pred_same = X_pred[X_pred['pred'] == False]
X_pred_different = X_pred[X_pred['pred'] == True]
# 直观地看一看数据
X_pred
plt.title('局部离群因子检测 (LOF)')
plt.scatter(X[:-n_outliers, 0], X[:-n_outliers, 1], color='b', s=5, label='集群点')
plt.scatter(X[-n_outliers:, 0], X[-n_outliers:, 1], color='orange', s=5, label='离群点')
# 以标准化之后的局部离群值为半径画圆,以圆的大小直观表示出每个数据点的离群程度
plt.scatter(X_pred_same.values[:,0], X_pred_same.values[:, 1],
s=1000 * X_pred_same.values[:, 3], edgecolors='c',
facecolors='none', label='标签一致')
plt.scatter(X_pred_different.values[:, 0], X_pred_different.values[:, 1],
s=1000 * X_pred_different.values[:, 3], edgecolors='violet',
facecolors='none', label='标签不同')
plt.axis('tight')
plt.xlim((-5, 5))
plt.ylim((-5, 5))
legend = plt.legend(loc='upper left')
legend.legendHandles[0]._sizes = [10]
legend.legendHandles[1]._sizes = [20]
plt.show()

3 总结
1.基于距离的方法:**优点**:它们简单易懂,因为它们大多不依赖于假设的分布来拟合数据。它们在多维空间中的伸缩性更好,因为它们有强大的理论基础,并且与统计方法相比,它们在计算上更高效。**缺点**:性能由于维数灾难而下降。数据中的对象通常具有离散的属性,这使得定义这些对象之间的距离具有挑战性。不适合大型数据集。
2.基于密度的方法:**优点**:在基于密度的方法中,使用的密度估计是非参数的;他们不依靠假设的分布来拟合数据。**缺点**:复杂,计算成本也更高。它们对参数设置很敏感,例如确定邻居的大小。
4 参考资料
[1]Datawhale开源课程.2021年.https://github.com/datawhalechina/team-learning-data-mining/tree/master/AnomalyDetection
[2]H. Wang, M. J. Bah and M. Hammad, “Progress in Outlier Detection Techniques: A Survey,” in IEEE Access, vol. 7, pp. 107964-108000, 2019, doi: 10.1109/ACCESS.2019.2932769.
[3]CSDN.https://blog.csdn.net/youyoufengyuhan/article/details/112968487
[4]GitHub.https://github.com/yzhao062/pyod















 3981
3981











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









