







Hadoop
介绍hadoop之前,要简单介绍一下hadoop的应用领域——大数据
1.大数据(big data)
(1)概念
①大数据是IT行业的的术语,是指无法在一定时间内通过常规软件进行抓取,管理和处理的数据,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
(2)特性
- 数量大 Volume<:数据的大小决定所考虑的数据的价值和潜在的信息
- 增长块 Velocity:指获得数据的速度
- 种类多 Variety:数据类型的多样性
- 价密低 Value:合理运用大数据,以低成本创造高价值
- 可变性 Variability:妨碍了处理和有效地管理数据的过程。
- 真实性 Veracity:数据的质量。
- 复杂性 Complexity:数据量巨大,来源多渠道。
(3)分布式计算
①传统分布式:
- 多数据节点-copy data->单计算节点master
- 特点:数据量小,受限于单体计算节点CPU性能
- 提升放法:提升单体计算机的运算能力
②hadoop分布式:
- 多具有存储和运算功能节点-copy computed result from single node->汇总计算节点
- 特点:数据量大。受单体计算节点影响小
- 提升方法扩展低成本集群
说到分布式计算就可以开始正式介绍Hadoop了
2.Hadoop
(1)概念
- Hadoop是一个开源的分布式计算框架,它允许在整个集群使用简单编程模型计算机的分布式环境存储并处理大数据。它的目的是从单一的服务器到上千台机器的扩展,每一台计算机都可以提供本地计算和存储。
(2)Hadoop生态圈
这里就简单的用一张图概括一下,网上可以找到很多类似的图片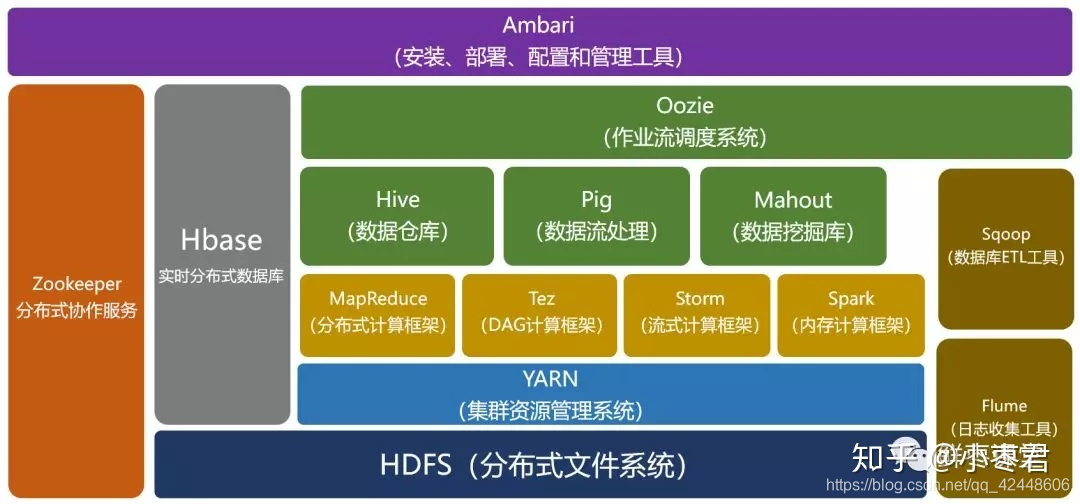
(3)Hadoop的优势
①高扩展性:添加数据节点
②高可靠性:多个数据备份
③高容错性:失败任务重新分配
④低成本:允许部署在低价机器上
⑤高灵活性:可以存储任何类型的数据
⑥开源:活跃社区
(4)RDBMS 和 HADOOP的比较

(4)Hadoop框架
1)hdfs =>hadoop file system Hadoop分布式文件系统
是指被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统(Distributed File
System)。它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS放宽了一部分POSIX约束,来实现流式读取文件系统数据的目的。HDFS在最开始是作为Apache
Nutch搜索引擎项目的基础架构而开发的。HDFS是Apache Hadoop Core项目的一部分。
- 将文件拆分存储:hadoop 2.x才有的
- 每个文件拆分为128m,每个文件片存储在不同的节点上
- 比如200m的文件会被拆为:128m 72m,再小的文件也会以128m为标准,分配给它128m的内存
- 缺点
- 不适合低延迟(毫秒以下)的操作
- 不适合大量小文件,会严重浪费资源
- 不支持并发写入、随机修改,只支持追加
2)MapReduce =>reduce 是一种编程模型
- 用于大规模数据集(大于1TB)的并行运算,
- 概念"Map(映射)“和"Reduce(归约)”,是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
- 一次读一行的方式来读取文件,并以(key,value)的方式传给下一步
3)yarn => yet another resource nigotiator 另一种资源协调者
- 是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。

a、DataNode 每1小时向NameNode汇报所有Block块信息
b、DataNode美3秒钟向NameNode发送一次心跳包, 心跳会带回NameNode给DataNode的命令:如把某数据块复制到哪个节点备份
c、如10分钟没有收到某DataNode的心跳包,则认为不可用并移除
d、集群在运行中可以安全添加或移除节点
4)common => common model 公共模式
是业务和分析应用程序使用的共享数据语言。它包含 Microsoft 和我们的合作伙伴发布的一组标准化、可扩展的数据架构,让应用程序和业务流程中的数据及其意义保持一致。















 2540
2540











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









