










目录
1. 超级详细的YOLOv8安装与测试指南:让计算机视觉任务变得简单
2. 超详细的YOLOv8项目组成解析:一站式指南了解其架构与组件
3. 超详细深入理解YOLOv8配置参数:了解多种任务计算机视觉模型训练
4. 超详细YOLOv8图像分类全程概述:环境、训练、验证与预测详解
5. 超详细YOLOv8目标检测全程概述:环境、训练、验证与预测详解
6. 超详细YOLOv8实例分割全程概述:环境、训练、验证与预测详解
7. 超详细YOLOv8姿态检测全程概述:环境、训练、验证与预测详解
12. 深入理解 YOLOv8:解析.yaml 配置文件目标检测、实例分割、图像分类、姿态检测
附1:目标检测实例分割数据集转换:从XML和JSON到YOLOv8(txt)
引言与目录导航
 https://docs.ultralytics.com/zh/
https://docs.ultralytics.com/zh/欢迎来到我们的技术博客,这里是探索深度学习奥秘的乐园!今天,我们要聊的是——YOLOv8,这不仅仅是一个目标检测算法,它简直就是目标检测界的“瑞士军刀”!想象一下,你走在街上,一眼就能识别出每一辆路过的车型、每个路人的服饰,甚至是天空中飞过的每只鸟。听起来像是超能力?不,这正是YOLOv8的日常!从YOLOv1的“初出茅庐”到YOLOv8的“身经百战”,我们见证了一个算法的成长历程。现在,它不仅速度飞快,还变得精准无比。
但我是个初学者啊!”别担心,虽然我们的博客内容详尽,但我们绝不是那种只讲大道理不谈实操的“高冷”类型。我们会用浅显易懂,甚至是带点幽默的方式,带你领略YOLOv8的魅力。当然,如果你对“1+1=2”还有疑问,那可能就需要先补补课了。
在这个系列里,我们不会过多讨论YOLOv8的核心原理,只会一步步教你如何训练模型、如何将其应用到实际场景中,甚至还会教你如何将它部署到不同的平台上。以及量化、推理部署等。但是相关的理论以及参考文献我会专门单独的列出一章给大伙分享。我们的目标是:不论你是刚入门的新手,还是想要提升技能的老手,都能从这个系列中获得所需。(另外如果还是会遇到问题的可以喊我,不过是有偿技术支持服务,毕竟小编也得赚钱养家。)
1. 超级详细的YOLOv8安装与测试指南:让计算机视觉任务变得简单
2. 超详细的YOLOv8项目组成解析:一站式指南了解其架构与组件
3. 超详细深入理解YOLOv8配置参数:了解多种任务计算机视觉模型训练
4. 超详细YOLOv8图像分类全程概述:环境、训练、验证与预测详解
5. 超详细YOLOv8目标检测全程概述:环境、训练、验证与预测详解
6. 超详细YOLOv8实例分割全程概述:环境、训练、验证与预测详解
7. 超详细YOLOv8姿态检测全程概述:环境、训练、验证与预测详解
8. 超详细YOLOv8训练参数、说明详解
9. 超详细YOLOv8验证参数、说明详解
10. 超详细YOLOv8预测参数、说明详解
11. 超详细概述YOLOV8实现目标追踪任务全解析
12. 深入理解 YOLOv8:解析.yaml 配置文件目标检测、实例分割、图像分类、姿态检测
附1:目标检测实例分割数据集转换:从XML和JSON到YOLOv8(txt)
提示
大家好,本专栏后续尽可能的给大家简单的对YOLOV8相关技术进行摘要,小编会尽可能的把文档整理清晰方便大家浏览,同时函数、安装、使用等等相关的概述都是基于官方文档直接进行摘要。当前本文概述基本都是基于windows环境下进行演示(linux部署流程基本都一样,就是系统环境有所区别)。希望能得到大家的认可。
前言
在快速发展的计算机视觉领域,目标检测技术一直是研究和应用的热点。它在许多实际场景中扮演着至关重要的角色,从智能监控系统到自动驾驶汽车,再到医疗影像分析。在众多目标检测模型中,YOLO(You Only Look Once)系列因其出色的速度和准确率而备受关注。
而最新的YOLOv8,不仅在性能上超越了其前代版本,还引入了一系列创新技术,为整个领域带来了新的突破。 YOLOv8继承了YOLO系列的快速、准确的特点,同时引入了更高效的架构和算法优化。这些改进不仅提高了检测速度,还进一步提升了模型在各种复杂环境下的准确性和鲁棒性。对于从事计算机视觉研究和开发的专业人士来说,YOLOv8的出现无疑是一个值得关注的里程碑。
YOLO简史
YOLO (You Only Look Once),由华盛顿大学的Joseph Redmon和Ali Farhadi开发的流行目标检测和图像分割模型,于2015年推出,由于其高速和准确性而迅速流行。
- YOLOv2 在2016年发布,通过引入批量归一化、锚框和维度聚类来改进了原始模型。
- YOLOv3 在2018年推出,进一步增强了模型的性能,使用了更高效的主干网络、多个锚点和空间金字塔池化。
- YOLOv4 在2020年发布,引入了Mosaic数据增强、新的无锚检测头和新的损失函数等创新功能。
- YOLOv5 进一步改进了模型的性能,并增加了新功能,如超参数优化、集成实验跟踪和自动导出到常用的导出格式。
- YOLOv6 在2022年由美团开源,现在正在该公司的许多自动送货机器人中使用。
- YOLOv7 在COCO关键点数据集上添加了额外的任务,如姿态估计。
- YOLOv8 是Ultralytics的YOLO的最新版本。作为一种前沿、最先进(SOTA)的模型,YOLOv8在之前版本的成功基础上引入了新功能和改进,以提高性能、灵活性和效率。YOLOv8支持全范围的视觉AI任务,包括检测, 分割, 姿态估计, 跟踪, 和分类。这种多功能性使用户能够利用YOLOv8的功能应对多种应用和领域的需求。
YOLO不同版本性能对比
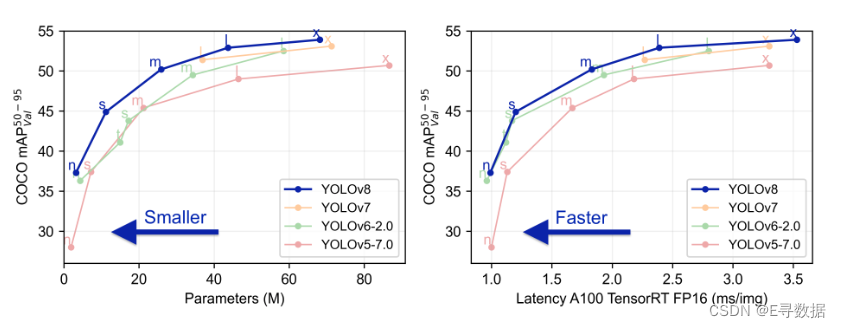
左图:模型大小与性能
- 横轴(Parameters (M)):表示模型的参数数量,以百万(M)为单位。参数数量越多,通常表示模型结构越复杂,计算需求越高。
- 纵轴(COCO mAP@.5:.95):表示在COCO数据集上使用mAP(从IoU=0.5到IoU=0.95的平均值)评价指标所得的结果。这是一个衡量模型准确度的标准,值越高表示准确度越好。
- 图中曲线:展示了不同大小的模型(s、m、x分别代表小、中、大版本)在准确度上的表现。
- YOLOv8:在不同大小的版本中均显示出较高的mAP值,说明它在准确性方面表现优秀。
- YOLOv7、YOLOv6.2.0、YOLOv5-7.0:其他版本的YOLO也展示了性能,可以看到随着模型大小的增加,它们的mAP也提高了。
- 观察:总体来看,随着模型参数的增加,mAP得分也趋于提高。YOLOv8的表现在所有大小的模型中都是最好的。
右图:速度(延迟)与性能
- 横轴(Latency A100 TensorRT FP16 (ms/img)):表示在NVIDIA A100 GPU上使用TensorRT并以半精度(FP16)计算时,模型处理单张图片所需的时间(以毫秒为单位)。延迟越低表示模型处理速度越快。
- 纵轴:与左图相同,也是COCO mAP@.5:.95。
- 图中曲线:展示了不同版本的YOLO模型在处理速度和准确度上的表现。
- 观察:可以看到,随着延迟的减少(模型速度的提升),mAP得分略有下降。这表明存在速度与准确性之间的权衡。同样,YOLOv8在各个延迟级别上显示出很好的性能,特别是在速度较快时。
模型结构解释

这张图是 YOLOv8(You Only Look Once version 8)目标检测模型的结构图。它展示了模型的三个主要部分:Backbone(主干网络)、Neck(颈部网络)和 Head(头部网络),以及它们的子模块和连接方式。
Backbone(主干网络)
主干网络是模型的基础,负责从输入图像中提取特征。这些特征是后续网络层进行目标检测的基础。在YOLOv8中,主干网络可能采用了类似于CSPDarknet的结构,该结构的特点是:
- 高效的特征提取:通过深度卷积网络提取图像的深层次特征。
- Cross Stage Partial networks:通过在网络中的某些阶段应用部分连接来减少参数和计算量,增强模型的学习能力和泛化性。
- 多尺度特征提取:通过多个阶段(Stage Layer)逐渐缩小特征图的尺寸,使网络能够捕捉到不同层次的抽象特征。
- CSPDarknet:图中使用的是YOLOv8的主干网络,采用CSP(Cross Stage Partial networks)结构,这有助于减少计算量和提高训练速度。
- Stem Layer:最初的层,用于提取初步特征。
- Stage Layer 1 - 4:不同的阶段包含若干ConvModule和CSP层,用于不断提取和合成特征。
Neck(颈部网络)
颈部网络位于主干网络和头部网络之间,它的作用是进行特征融合和增强。YOLOv8中的颈部网络可能包含以下特点:
- Spatial Pyramid Pooling-Fast (SPPF):通过在多个尺度上聚合特征来保留不同尺度的上下文信息,这有助于检测不同大小的物体。
- Path Aggregation Network (PAN):用于增强特征的信息流动,通过自底向上和自顶向下的路径融合不同层级的特征,这样可以提高小物体的检测性能。
- SPPF (Spatial Pyramid Pooling-Fast):它在不同尺度上池化特征,使网络能够捕捉到不同大小的上下文信息。
- PAN (Path Aggregation Network):用于特征金字塔,合并不同层次的特征图。
Head(头部网络)
头部网络是目标检测模型的决策部分,负责产生最终的检测结果。YOLOv8的头部网络可能具有以下特性:
- Decoupled Head:将边界框的预测和类别的预测分离,这样可以独立优化每个任务,提高模型的整体性能。
- 专门的检测层:针对不同的任务(如边界框定位和类别分类)使用特定的层,这样每个任务都可以使用最适合其特点的网络结构和参数。
- YOLOv8HeadModule:最后的检测头,负责预测边界框、目标类别和对象分数。
- Decoupled Head:将边界框预测(Bbox)和类别预测(Cls)分开处理,有助于提高模型的性能。
好处和作用
- 模块化设计:将模型分成不同的部分允许针对每个部分进行优化,并简化了模型的调试和改进过程。
- 特征融合:通过颈部网络融合不同层级的特征,模型能够同时理解图像的细节和大局,增强了对复杂场景的理解。
- 专业化:头部网络的分离让模型能够更加精确地处理不同的任务,例如精确的边界框定位和准确的类别预测。
- 性能和效率:CSP结构和SPPF等技术的应用旨在提高模型的运行速度和准确度,使其适用于需要实时检测的应用场景。
其他细节
- ConvModule:包含卷积层、BN(批量归一化)和激活函数(如SiLU),用于提取特征。
- DarknetBottleneck:通过residual connections增加网络深度,同时保持效率。
- CSP Layer:CSP结构的变体,通过部分连接来提高模型的训练效率。
- Concat:特征图拼接,用于合并不同层的特征。
- Upsample:上采样操作,增加特征图的空间分辨率。
IoU (交并比):
IoU是评估目标检测模型性能中一个非常重要的指标。它衡量的是预测边界框和真实边界框之间的重叠程度。IoU的计算方式如下:
其中,Area of Overlap是预测边界框和真实边界框重叠的区域面积,Area of Union是两个边界框覆盖的总面积。
- 优点:IoU提供了一个明确的指标来衡量位置预测的准确性。
- 作用:它被广泛用于训练阶段来优化模型(作为损失函数的一部分),以及评估阶段来比较不同模型或同一模型在不同参数下的性能。
Bbox Loss:
Bbox Loss用于计算预测边界框和真实边界框之间的差异。均方误差(MSE)是一个常用的损失函数,其计算公式如下:
其中, 是真实边界框的坐标,而
是预测边界框的坐标。该损失计算预测与实际坐标之间的差异的平方和。
- 优点:MSE是一个很好的损失函数,因为它在较大误差时赋予更高的惩罚,这有助于模型快速修正大的预测错误。
- 作用:作为优化目标,引导模型在训练过程中减少预测框和真实框之间的差距。
Cls Loss(分类损失)
Cls Loss用于衡量模型预测的类别分布与真实标签之间的差异。交叉熵损失函数是分类任务中常用的一种损失函数,其公式为:
这里, 是一个指示器,如果样本o属于类别c,则为1,反之为0。而
是模型预测样本o属于类别c的概率。
- 优点:交叉熵损失对于错误预测给出了很大的惩罚,尤其是在预测的概率和实际标签相差很大时。
- 作用:帮助模型在多分类问题中优化其预测,使预测概率分布尽可能接近真实的标签分布。
每一个损失函数都专注于模型的一个特定方面,确保模型能够从多个维度进行学习和优化。在训练时,这些损失通常被组合起来形成一个综合的优化目标,以便模型能够同时提高其在定位和分类任务上的性能。
YOLOv8模型在COCO数据集上的性能
在计算机视觉领域,COCO(Common Objects in Context,即上下文中的常见对象)数据集被视为评估目标检测模型性能的基准。YOLOv8架构在各种配置下展示了其性能,如下所总结:
模型配置和结果
| Backbone | Arch | size | Mask Refine | SyncBN | AMP | Mem (GB) | box AP | TTA box AP | Config | Download |
|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv8-n | P5 | 640 | No | Yes | Yes | 2.8 | 37.2 | config | model | log | |
| YOLOv8-n | P5 | 640 | Yes | Yes | Yes | 2.5 | 37.4 (+0.2) | 39.9 | config | model | log |
| YOLOv8-s | P5 | 640 | No | Yes | Yes | 4.0 | 44.2 | config | model | log | |
| YOLOv8-s | P5 | 640 | Yes | Yes | Yes | 4.0 | 45.1 (+0.9) | 46.8 | config | model | log |
| YOLOv8-m | P5 | 640 | No | Yes | Yes | 7.2 | 49.8 | config | model | log | |
| YOLOv8-m | P5 | 640 | Yes | Yes | Yes | 7.0 | 50.6 (+0.8) | 52.3 | config | model | log |
| YOLOv8-l | P5 | 640 | No | Yes | Yes | 9.8 | 52.1 | config | model | log | |
| YOLOv8-l | P5 | 640 | Yes | Yes | Yes | 9.1 | 53.0 (+0.9) | 54.4 | config | model | log |
| YOLOv8-x | P5 | 640 | No | Yes | Yes | 12.2 | 52.7 | config | model | log | |
| YOLOv8-x | P5 | 640 | Yes | Yes | Yes | 12.4 | 54.0 (+1.3) | 55.0 | config | model | log |
训练设置
官方使用了8张A100 GPU进行YOLOv8模型的训练,每个GPU处理的批量大小为16。这一设置与官方代码中的配置不同,但我们发现它并不影响模型的性能。
性能波动
模型性能存在不稳定性,平均精度(mAP)可能会有大约0.3的波动。在COCO数据集上进行训练的YOLOv8模型中,最高性能权重可能不会出现在最后一个训练周期(epoch)。这里展示的性能是我们所观察到的最佳模型性能。
权重转换支持
官方提供了脚本将官方的权重文件转换为MMYOLO格式,以便于使用和集成。
技术细节
- 同步BN(SyncBN):表示在训练中官方使用了同步批量归一化技术,这在多GPU训练中特别重要,以确保每个GPU上的BN层可以同步更新。
- 混合精度训练(AMP):表明我们采用了混合精度训练,这可以加速训练过程并减少内存消耗。
- 掩码细化(Mask Refine):这是一种训练技术,指的是在加载标注数据和进行YOLOv5RandomAffine变换之后,通过掩码来细化边界框(bbox)。在大(L)和超大(X)模型中,我们还使用了复制粘贴(Copy Paste)技术。
测试时增强(TTA)
测试时增强(TTA)是在测试阶段应用的一种技术,旨在通过图像变换来提高模型的性能。具体来说,我们对图像进行了3次多尺度变换,然后是2次翻转变换(一次翻转和一次不翻转)。在测试时,只需指定--tta参数即可启用这一功能。更多细节可以查看TTA相关文档。
总结
这两个图表明,YOLOv8在不同尺寸和速度设定下,都能提供出色的准确度,即使在更快的设置下也能保持较高的mAP值。这反映了YOLOv8在设计时的优化,使其在速度和准确度之间取得了良好的平衡。如果有哪里写的不够清晰,小伙伴本可以给评论或者留言,我这边会尽快的优化博文内容,另外如有需要,我这边可支持技术答疑与支持。


















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











