







 本文深入探讨了目标检测任务中的评估指标,包括TP、FN、FP的计算方式,以及在IOU阈值下的P-R曲线和平均精度(AP)的求解过程。文章指出,高阈值下的mAP提升并不一定意味着定位性能改善,同时强调了FP的影响取决于其与TP的关系。此外,还介绍了如何根据IOU和置信度判断预测框的正负,并用于计算精确度和召回率。
本文深入探讨了目标检测任务中的评估指标,包括TP、FN、FP的计算方式,以及在IOU阈值下的P-R曲线和平均精度(AP)的求解过程。文章指出,高阈值下的mAP提升并不一定意味着定位性能改善,同时强调了FP的影响取决于其与TP的关系。此外,还介绍了如何根据IOU和置信度判断预测框的正负,并用于计算精确度和召回率。
首先强调一些概念,这里假设目标检测任务是单类别:
【1】分类任务中,一个图片对应一个标签和一个预测。而目标检测任务,一个图片对应有m个标签(bbox)和n个预测(score+bbox)。一个图片可能就没有目标m=0,也可能模型啥都没有预测出来n=0。
【2】标签就一个bbox,因为是单类别。 bbox是一个四个数值(x1,y1,x2,y2)。
【3】预测的每个bbox还对应这一个score,表示这个框是否为目标的一个概率
【4】如下图,TP,FN,FP可计算,但TN不可计算。原因是标签的bbox和预测的bbox都只表示图像中哪个位置是目标物体,除此之外的都是非目标物体。这样的话TN就有无穷多个。
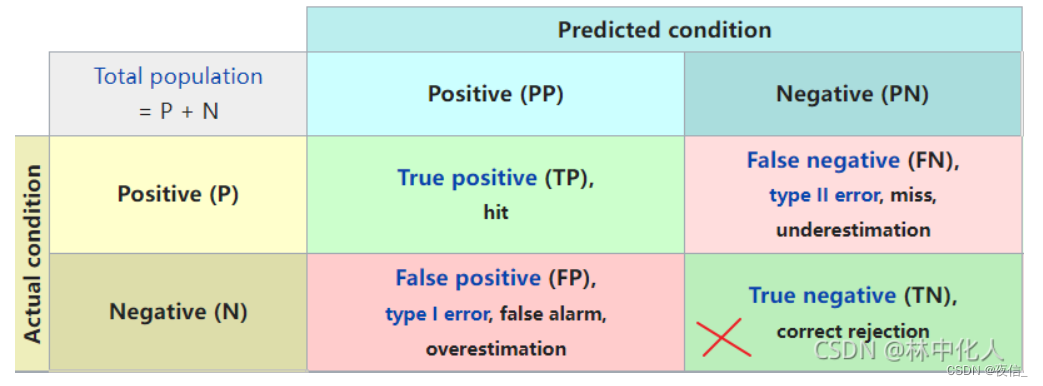
【5】TP,FN,FP如何计算?
若某个标签bbox与某个预测bbox的IOU大于IOU_T(一个阈值,比如70%),则TP+=1。
如果没有任何预测的bbox与某个标签bbox的IOU大于IOU_T,说明这个正例bbox未被预测出,则FN+=1
如果没有任何标签的bbox与某个预测bbox的IOU大于IOU_T,说明这个预测的正例是假的,则FP+=1
【6】再在上述基础上套上score,算P_R曲线,再算AP。这里就直接上例子吧。

image x 为图片,一张图片上可能有许多个gt,也有可能没有gt,detections是网络预测的多个预测框,一个图片上可能会存在多可预测框(用A-Z进行编码)。
首先确定每一个预测框(A-Z是 正 还是 负), 即大于IOU阈值的为正,小于的为负。并且一个gt只能算一次,也就是两个预测框对于同一个gt都满足了IOU大于阈值,但是只有IOU最大的一个算是正,剩下的算是负 (疑问,a,b 对于gt1的IOU都大于阈值, a的iou更高, b对于gt2的IOU也大于阈值, b是否会在处理gt1的时候直接被设置成负?)
然后,Confidence从高到低一, 大于的,正的变成TP,负的变成FP,然后剩下 #gt - TP 个 FN。

相关链接
- 从这几个结果的对比我们可以发现mmAP的几个特点:1.mAP@0.75这样的高阈值mAP提高时,未必是定位的性能变好导致的,也有可能是因为检测器留下了部分本来应该被过滤掉的FP,而碰巧这个FP的定位效果更好,在高阈值mAP上提供了正面价值;2.如果检测器的定位性能更强,那么mmAP一定会有所提高;3.有时FP未必会影响性能,FP是否影响性能,关键要看是否还存在比该FP分数更低的TP。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









