







Dice系数与Dice Loss
Dice
Dice系数是一种集合相似度度量函数,通常用于计算两个样本的相似度,取值范围在[0,1]:
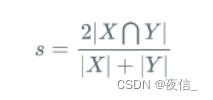
其中 |X∩Y| 是X和Y之间的交集,|X|和|Y|分表表示X和Y的元素的个数,其中,分子的系数为2,是因为分母存在重复计算X和Y之间的共同元素的原因。
Dice Loss:
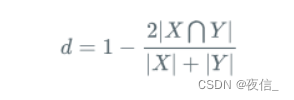
Laplace smoothing:
Laplace smoothing 是一个可选改动,即将分子分母全部加 1:
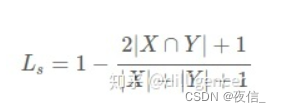
带来的好处:
(1)避免当|X|和|Y|都为0时,分子被0除的问题
(2)减少过拟合
Dice 代码
import torch.nn as nn
import torch.nn.functional as F
class SoftDiceLoss(nn.Module):
def __init__(self, weight=None, size_average=True):
super(SoftDiceLoss, self).__init__()
def forward(self, logits, targets):
bs = targets.size(0)
smooth = 1
probs = F.sigmoid(logits)
m1 = probs.view(bs, -1)
m2 = targets.view(bs, -1)
intersection = (m1 * m2)
score = 2. * (intersection.sum(1) + smooth) / (m1.sum(1) + m2.sum(1) + smooth)
score = 1 - score.sum() / bs
return score
dice loss 为何训练会很不稳定?
在使用dice loss时,一般正样本为小目标时会产生严重的震荡。因为在只有前景和背景的情况下,小目标一旦有部分像素预测错误,那么就会导致loss值大幅度的变动,从而导致梯度变化剧烈。可以假设极端情况,只有一个像素为正样本,如果该像素预测正确了,不管其他像素预测如何,loss 就接近0,预测错误了,loss 接近1。而对于ce loss,loss的值是总体求平均的,更多会依赖负样本的地方。
dice loss 特点
-
一般情况下,dice loss 正样本的梯度大于背景样本的; 尤其是刚开始网络预测接近0.5的时候,这点和单点输出的现象一致。说明 dice loss 更具有指向性,更加偏向于正样本,保证有较低的FN。
-
负样本(背景区域)也会产生梯度。
-
极端情况下,网络预测接近0或1时,对应点梯度值极小,dice loss 存在梯度饱和现象。此时预测失败(FN,FP)的情况很难扭转回来。不过该情况出现的概率较低,因为网络初始化输出接近0.5,此时具有较大的梯度值。而网络通过梯度下降的方式更新参数,只会逐渐削弱预测失败的像素点。
-
对于ce loss,当前的点的梯度仅和当前预测值与label的距离相关,预测越接近label,梯度越小。当网络预测接近0或1时,梯度依然保持该特性。
对比发现, 训练前中期,dice loss下正样本的梯度值相对于ce loss,颜色更亮,值更大。说明dice loss 对挖掘正样本更加有优势。
当然dice loss也是有缺点的 -
梯度形式更优,当x和y的为负样本值都非常小时,由于梯度计算中都需要进行平方,计算得到的梯度值可能会非常大。通常情况下,导致训练很不稳定。因此建议可以配合类ce为主loss进行训练,也可以通过设置class_weight对于样本更少的类别赋予给高的weight
-
类IoUloss中当前像素的loss不光和当前像素的预测值相关,和其他点的值也相关。可以理解为mask操作,固定大小的正样本的区域计算的loss是一样的,对网络起到的监督贡献也是一样的。训练更倾向于挖掘前景区域,所以当正样本为小目标时loss会产生严重的震荡。一旦有部分像素预测错误,那么就会导致loss值大幅度的变动。而对于ce loss,loss的值是总体求平均的,更多会依赖负样本的地方。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









