







1、Parquet存储格式
1.1、Parquet介绍
Apache Parquet 是由 Twitter 和 Cloudera 最先发起并合作开发的列存储项目。Parquet 的设计与计算框架、数据模型以及编程语言无关,可以与任意项目集成,因此应用广泛。目前已经是 Hadoop 大数据生态圈列式存储的事实标准。
1.2、原理
有这么三行数据
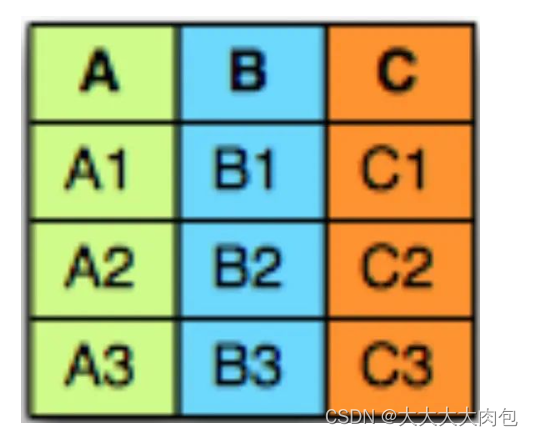
在面向行的存储中,每列的数据依次排成一行,如下所示:

而在面向列的存储中,相同列的数据存储在一起:

显而易见,行存适用于数据整行读取场景,而列存适用于只读取部分列数据(如统计分析等)场景。
1.3、优点
(1)列裁剪(offset of first data page -> 列的起始结束位置)
Parquet列式存储方式可以方便地在读取数据到内存之间找到真正需要的列,具体是并行的task对应一个Parquet的行组(row group),每一个task内部有多个列块,列快连续存储,同一列的数据存储在一起,任务中先去访问footer的File metadata,其中包括每个行组的metadata,里面的Column Metadata记录offset of first data page和offset of first index page,这个记录了每个不同列的起始位置,这样就找到了需要的列的开始和结束位置。其中data和index是对数值和字符串数据的处理方式,对于字符变量会存储为key/value对的字典转化为数值。
(2)谓词下推(Column Statistic -> 列的range和枚举值信息)
任何列都能作为索引
Parquet中File metadata记录了每一个Row group的Column statistic,包括数值列的max/min,字符串列的枚举值信息,比如如果SQL语句中对一个数字列过滤>21以上的,因此File 0的行组1和File 1的行组0不需要读取
(3)压缩效率高,占用空间少,存储成本低
Parquet这类列式存储有着更高的压缩比,相同类型的数据为一列存储在一起方便压缩,不同列可以采用不同的压缩方式,结合Parquet的嵌套数据类型,可以通过高效的编码和压缩方式降低存储空间提高IO效率
1.4、缺点
- 选择完成时,被选择的列要重新组装(列式存储行式展示)
- 列存储由于需要把一行记录拆分成单列保存,写入次数明显比行存储多,再加上磁头需要在盘片上移动和定位花费的时间,实际时间消耗会更大。所以,行存储在写入上占有很大的优势。
-
点查询不适合。
2、Snappy压缩方式
Snappy是谷歌开源的一个用来压缩和解压的开发包。相较其他压缩算法速率有明显的优势。
开源项目地址:GitHub - google/snappy: A fast compressor/decompressor

















 1818
1818

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









