







Inner Join 的用法
SELECT *
FROM Orders
INNER JOIN Product
ON Orders.productId = Product.id优点:使用简单和离线数仓一样
缺点:因为历史数据默认不会被清理,因为资源问题一般只用做有界数据流的 Join,或者需要设置状态,设置过期时间。
Outer Join
outer join包括left join和right join、full join,效果和离线数仓一样。和 inner join还有不同一点在于ttl的状态更改,inner join只有数据被创建的时候会更改状态,但对于 outer join来说,用left join举例子,左表的数据会在被查询的时候也会被更改状态,所以会出现一个现象,如果你设置了过期时间为10秒,但如果右表一直会join左表的某一条数据,那么这条数据的状态会一直该变,生效时间会远远超过10秒。
SELECT *
FROM Orders
LEFT JOIN Product
ON Orders.productId = Product.id优点:使用简单和离线数仓一样
缺点:因为历史数据默认不会被清理,因为资源问题一般只用做有界数据流的 Join,或者需要设置状态,设置过期时间。
INTERVAL Join的用法
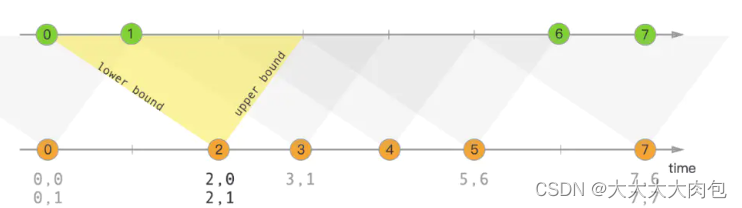
简单来说,Interval Join 可以让⼀条流去 Join 另⼀条流中前后⼀段时间内的数据。
SELECT
show_log.log_id as log_id,
show_log.timestamp as timestamp,
show_log.show_params as show_params,
click_log.click_params as click_params
FROM show_log
LEFT JOIN click_log
ON show_log.log_id = click_log.log_id
AND show_log.row_time
BETWEEN click_log.row_time - INTERVAL '10' MINUTE
AND click_log.row_time + INTERVAL '10' MINUTE;这里设置了 show_log.row_time BETWEEN click_log.row_time - INTERVAL '10' MINUTE AND click_log.row_time + INTERVAL '10' MINUTE代表 show_log 表中的数据会和 click_log 表中的 row_time 在前后 10 分钟之内的数据进行关联。
Lookup Join 的用法
在实时数仓中,同样也有维表与事实表的概念,其中事实表通常为实时流数据,维表通常存储在外部设备中(如 MySQL、HBase 等)。对于每条流式数据,可以关联外部数据源,查询并补充维度属性。由于维表是一张不断变化的表(静态表视为动态表的一种特例),因此在维表 JOIN 时,需指明这条记录关联维表快照的对应时刻。Flink SQL 的维表 JOIN 语法引入了 Temporal Table 的标准语法,用于声明流数据关联的是维表哪个时刻的快照。需要注意是,目前原生 Flink SQL 的维表 JOIN 仅支持事实表对当前时刻维表快照的关联(处理时间语义),而不支持事实表 rowtime 所对应的维表快照的关联(事件时间语义)。
--事实表
CREATE TABLE Orders (
order_id INT,
user_id INT,
price DOUBLE,
quantity INT,
proc_time AS PROCTIME(),
PRIMARY KEY(id) NOT ENFORCED
) WITH (
...
);
--维表
CREATE TABLE user (
user_id INT,
name STRING,
country STRING,
zip STRING,
PRIMARY KEY(id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://mysqlhost:3306/customerdb',
'table-name' = 'user',
--可定义参数优化 用于缓存
'lookup.cache.strategy' = 'LRU',
'lookup.cache.max-rows'='200000'
);
SELECT o.order_id
,o.user_id
,o.quantity
,c.country
,c.zip
FROM Orders AS o
JOIN user FOR SYSTEM_TIME AS OF o.proc_time AS c
ON o.user_id = c.user_id;优化:维表 Join 的默认策略是实时、同步查询维表,每条流数据到来时,在 Flink 算子中直接访问维表数据源来进行关联。这种方式可以保证维表数据是最新的,但是当数据流量过大时,频繁的维表实时查询会对外部系统带来巨大的压力。我们可以缓存维表中的数据,保存到 Flink 作业TaskManager 的内存中,流数据到来时,只需要查询本地缓存中的数据,无需与远程数据源进行交互,可以极大提升数据处理的吞吐量。
注意:如果缓存中找到数据,就不会再去业务数据库中找数据,所以如果频繁变化的维度数据,那么不能采用缓存的优化方式。















 3261
3261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









