






 本文详细解读了UKBiobank,英国最大的生物样本数据库,包括数据采集流程、基因组与生化样本信息,以及如何通过官网获取和搜索数据。介绍了志愿者招募、问卷调查、身体测量和生物样本收集等内容,展示了数据库结构和数据分类系统。
本文详细解读了UKBiobank,英国最大的生物样本数据库,包括数据采集流程、基因组与生化样本信息,以及如何通过官网获取和搜索数据。介绍了志愿者招募、问卷调查、身体测量和生物样本收集等内容,展示了数据库结构和数据分类系统。
UK Biobank(英国生物样本数据库),简称为UKB,UKB生物数据库是由维康信托基金和英国政府(医学研究委员会、卫生部和苏格兰行政院)资助,并注册成为一家慈善公司。该生物数据库是一个试点项目,目的是将英国电子医疗记录中的数据与遗传数据联系起来,从而建立一个更全的英国国民健康保险制度(National Health Service)生物库。它是目前世界上已建成人类遗传队列生物样本库中规模最大的。其收集了来自英国各地,年龄在40岁至69岁之间,大约50万志愿者的疾病和生活方式信息及基因型数据。
UKB 数据采集介绍
UKB队列数据中所有志愿者都是通过分布在英国各地的22个评估中心负责招募的(见图1),
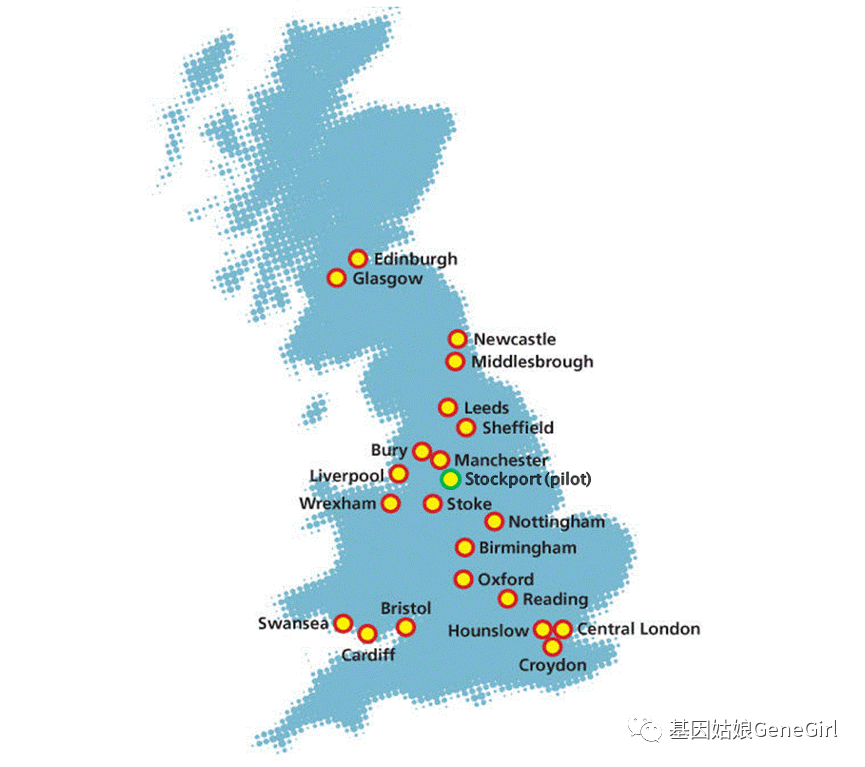
图一,UKB评估中心地图
UKB招募方式主要是通过邮件询问及电话邀请途径。当参与者同意参与英国生物样本数据库时,他们将被邀请访问最靠近他们的评估中心,以收集基线信息和生物样本。志愿者参与UKB访问中心的具体步骤看图2。
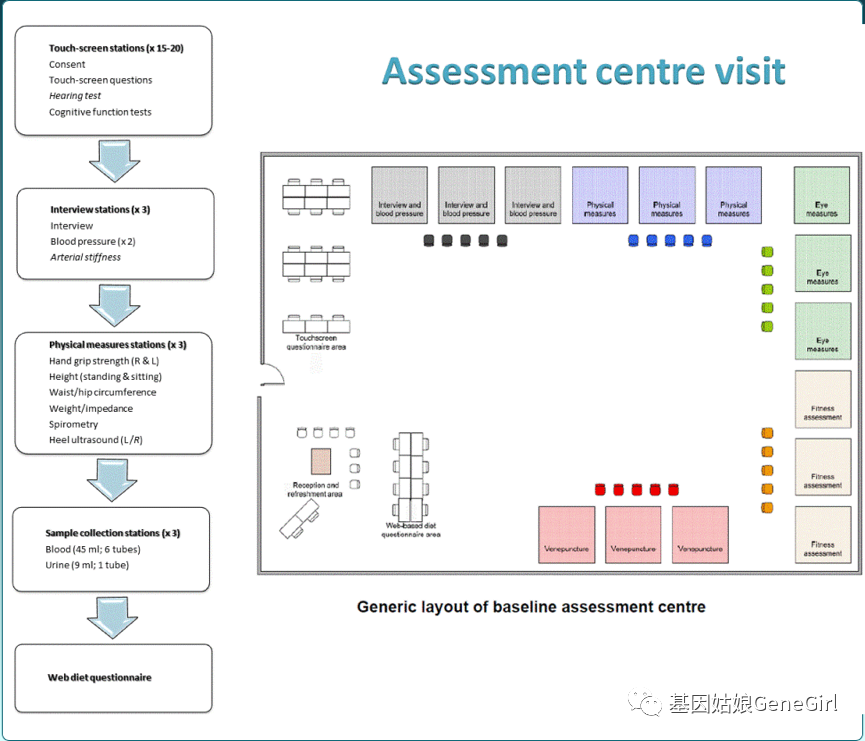
图二,评估诊所的布局及志愿者参与的具体步骤
具体的参与过程是:
第一步,利用触摸屏进行问卷调查。在志愿者完成知情同意程序后,即可使用触摸屏自行填写问卷来收集大部分个人信息,调查问卷内容非常广泛,包括很多方面,主要是集中在:
1)社会人口因素方面。这些问题大多来源和改编自人口普查(如2001年人口普查和英格兰健康调查),主要包括社会经济地位和人口统计指标。问题包括住房所有权、是否拥有汽车、家庭收入、家庭成员、就业状况和当前职业、种族和出生国家、学历和离校年龄。
2)吸烟和饮酒方面。
3)家族史和个体早期的一些暴露因素。家族病史是常见癌症、心血管疾病和许多其他疾病的已知预测因素,这些问题包括了患有常见严重疾病的一级亲属的家族史,以及双胞胎顺序出生的问题,个体早期暴露因素主要是关于出生体重、母乳喂养、母亲吸烟、儿童体型和出生时居住的问题,因为这些问题被认为是成年健康的潜在预测因素。
4)环境因素。调查问卷考虑了大量潜在的环境暴露,选择被认为是常见疾病(如呼吸系统疾病和肌肉骨骼状况)影响的指标,这些问题包括当前住址、出生时的居住地、职业和其他工作场所因素、被动吸烟暴露、室内空气污染和使用手机频率。
5)饮食习惯。主要是包括食物频度问卷、24小时饮食回忆和多天饮食回忆问卷。
6)参与体育活动情况。主要是体力活动强度(剧烈、适度),体育活动频率,关于常见久坐活动的问题也被纳入。
7)心理和认知状态。在心理状态方面,调查问卷的方法是在标准化问卷的基础上评估心理特质(神经质)和情绪,并记录影响心理症状的严重事件及其医学表现。具体的问卷内容可以看表一。
第二步,身体测量指标。当志愿者完成问卷后,接下来会进行一系列的身体测量过程,包括血压(和脉搏)、身高、体重、腰围、臀围、握力、肺活量、骨密度数据。第三步是生物样本收集过程,主要收集的血液数据和尿液数据,用于进行基因组,蛋白质组,代谢组学的检测。所收集到的基础表型数据可以见表一。
| Touchscreen questionnaire | http://biobank.ctsu.ox.ac.uk/crystal/label.cgi?id=100025 |
| Verbal interview | http://biobank.ctsu.ox.ac.uk/crystal/label.cgi?id=100071 |
| Physical measures | http://biobank.ctsu.ox.ac.uk/crystal/label.cgi?id=100006. |
| Web-based questionnaires | http://biobank.ctsu.ox.ac.uk/crystal/label.cgi?id=100089 |
| Physical activity monitor | http://biobank.ctsu.ox.ac.uk/crystal/label.cgi?id=1008 |
| Biochemistry markers | http://www.ukbiobank.ac.uk/wpcontent/uploads/2013/11/BCM023_ukb_biomarker_panel_website_v1.0-Aug-2015.pdf |
| Urinary biomarkers | http://biobank.ctsu.ox.ac.uk/crystal/label.cgi?id=100083 |
| Imaging study | http://biobank.ctsu.ox.ac.uk/crystal/label.cgi?id=100003 |
表一,UK Biobank 数据库中收集到的基础表型数据的网址链接。
除此之外,UKB还覆盖了英国电子医疗记录中的数据,包括,
1)死亡和癌症登记数据,
2)入院诊断数据,
3)全科医生数据,
4)其他医疗(如处方、病理报告、影像报告、筛查)与健康有关的数据。
UKB除了含有从2006年到2010年在全英国招募的50万名年龄在40-69岁的参与者(男女人数大致相等)的上述基线数据外,2012年8月至2013年6月,在英国斯托克波特的评估中心对2万名参与者进行了随访调查,主要随访对象是在评估中心35公里半径范围内的志愿者,总体的参与率是21%,采集的数据跟基线数据大致一样,但同时也增加了比如大脑核磁扫描数据及唾液样本等样本数据。截止到目前,已经进行了四次随访,包括2006-2010,2012-2013,2014+,2019+。
UKB基因型数据介绍
UKB目前公开了488,000多名志愿者的基因组数据,为此UKB专门针对英国人群设计了两款芯片。其中对49,950名志愿者使用UK BiLEVE Axiom芯片进行基因型分型,这款芯片包含807,411个标记。另外的438,427名参与者使用了UK Biobank Axiom芯片进行基因型分型,这款芯片包含825,927个标记,这些标记不仅包括常见(5%)和低频(1-5%)的较小等位基因频率(MAF),并且还包括一部分的稀有变异(<1%),更多的设计芯片细节可以看图三。
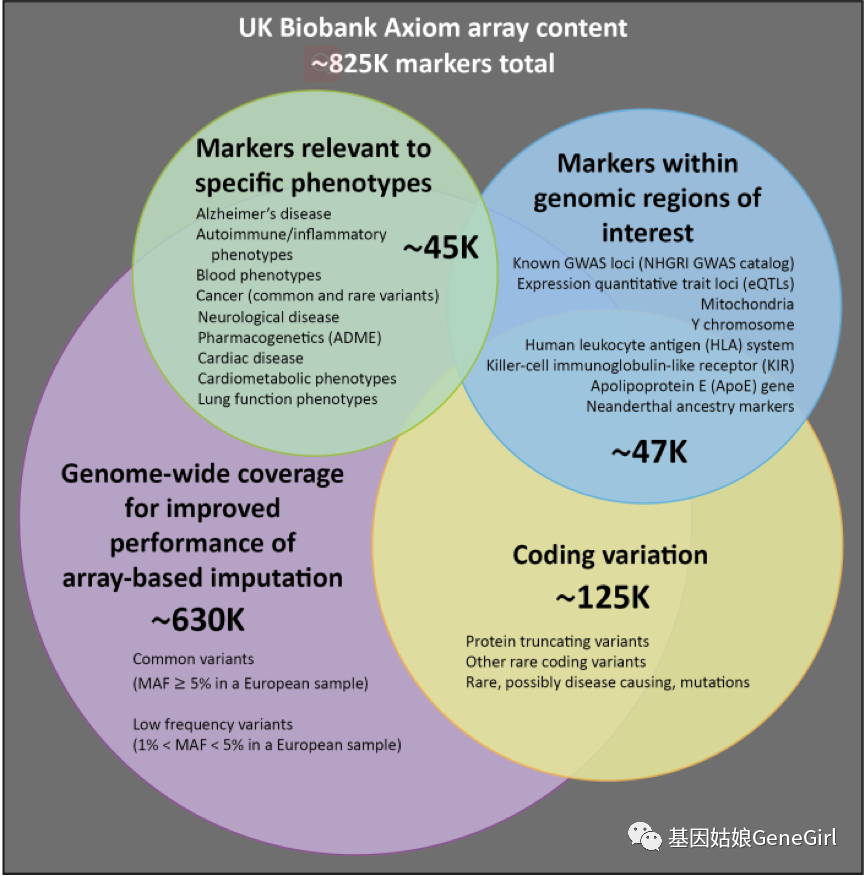
图三,芯片数据设计策略
除了芯片数据外,UKB同样对芯片数据进行了填充。利用的参考面板是合并的UK10K和千人基因组Phase3参考面板的数据,同时也利用HRC参考面板进行填充。但是如果在两个参考面板中都出现的SNP,选取HRC参考面板的结果,其余不一样的,则选取合并的(UK 10K 和千人基因组Phase3参考面板)参考面板填充的数据结果。最终得到92,693,895常染色体的SNPs。目前,全测序数据(Whole genome sequence)还在测序阶段,全基因组序列数据的第一部分预计将在2021年底向研究人员开放。除此之外,UKB还包括一部分的全外显子测序数据。目前UKB全外显子组测序(WES)的第一部分已经开放了50,000人的数据。
UK Biobank Showcase用户指南
UKB虽然含有上述介绍的丰富的数据,但是该如何寻找我们感兴趣的数据集呢?在这里主要介绍两种方法解决这个问题。
第一种方法是通过UKB官方网站进入Data Showcase,点击Browse,根据数据项的层次类别和子类别中来查找感兴趣的数据项。这种方法是系统性的寻找一类数据的方法。按原始类别进行搜索,数据以树形结构呈现,可通过点击浏览获得,根据收集数据的来源分为七种类别见图四。
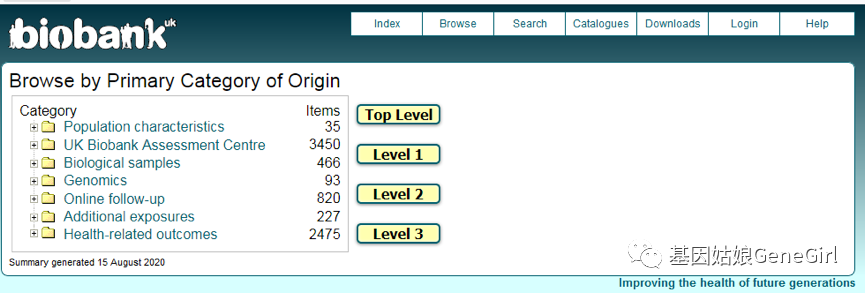
图四,原始类别浏览的网页内容
这些类别包括:
1)Population characteristics,人口特征,这个类别包含参与者的一般特征数据。
2)UK Biobank Assessment CentreUKB评估中心,这一类别包含了评估中心收集的信息,并根据评估的类型(如触屏、语言面试、身体测量、生物采样)被分为子类别。
3)Biological samples,生化样本,该类别包含UKB在评估中心采集后收到的生物样本的类型和数量信息(样本清单),以及进行的测定及其结果。
4)Genomics,基因组信息,UKB目前包含以下基因组数据,488,000名参与者的基因型及其填充数据,5万参与者的外显子组序列,50名参与者的全基因组序列。
5)Online follow-up,在线的随访数据,此类别包含基于UKB使用在线问卷进行的额外评估的信息。
6)Additional exposures,额外的暴露因素,这一类别包含基于在评估中心以外进行的其他评估的信息。
7)Health-related outcomes,健康相关的结局,该类别包含通过与一系列健康相关记录的链接提供的参与者健康结果有关的信息。这些数据集还在不断累积,数据库也在定期更新,
这七个大的类别下面还有小的类别,小的类别还可以分更小的类别,有三个level的数据。
但是如何寻找我们感兴趣的数据呢,使用Category前提是需要我们知道感兴趣的数据的类别,比如我们想知道UKB数据中是否含有Vitamin D的数据,我们需要知道Vitamin D是生化指标,一般是从血液中检测,血液又属于生物样品类别,因此我们直接找到Browse里面的Biological samples数据集,这个数据集又包括了Blood assays、Saliva assays和Urine assays数据,在这里我们就知道应该从Blood assays数据集寻找数据Blood biochemistry,在这个数据集中,我们最终找到了Vitamin D aliquot(Field ID 30890),Vitamin D assay date(30891),Vitamin D correction level (30893),Vitamin D correction reason(30894),Vitamin D missing reason(30895)和Vitamin D reportability(30896)。最后我们根据Field ID号(后面会再次介绍)在自己数据中就能定位到数据了。
第二种方法是直接进行搜索,通过UKB官方网站进入Data Showcase,点击Search,进入Search 界面,如图五所示,
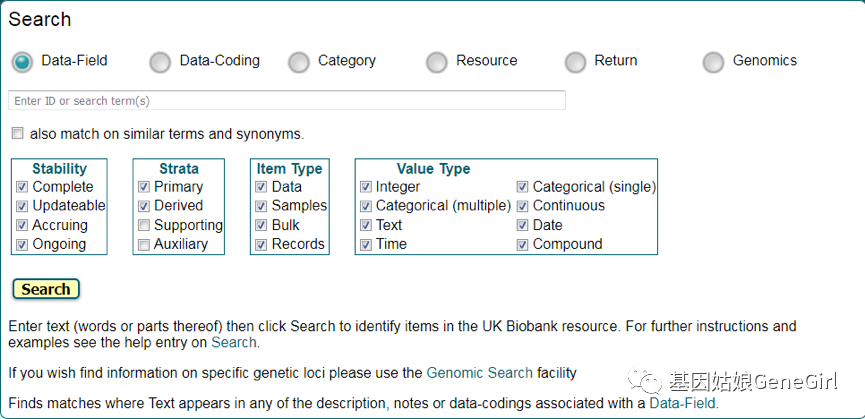
图五,UKB网站中Search界面
上面有六个搜索条件,包括Data-Field,Data-coding,Category,Resource,Return, Genomics。通过选择相关的搜索类型按钮,可以进行数据编码、类别资源和基因型数据的搜索,例如我们想要找到vitamin D 的数据,我们就在Data-Field中搜索,最终在搜索完的界面,能找到许多包括vitamin D的数据,同时也能找到vitamin D的数据,例如进入Field ID 30890 Vitamin D 数据中,我们会看到图六的数据。
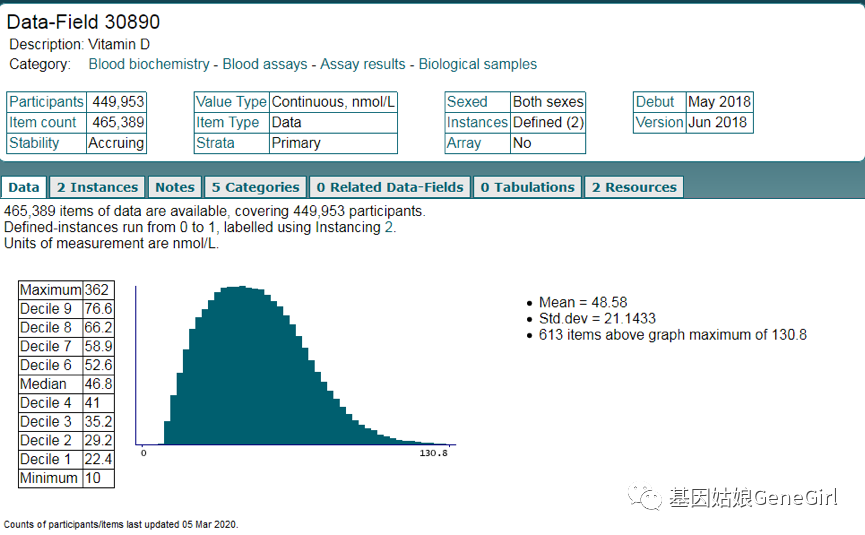
图六,Field-ID 30890在UKB网站中的描述
我们可以获得的信息是30890这个数据来源于血液生化指标,有449,953个参与者(Participants),共收集到469,389个数据(Item count),数据类型(Value Type)是连续型变量,除了基线数据外,并且是含有一次随访的数据(Defined (2),2006-2010,2012-2013年),同时还对这部分数据有一个初步的统计量的描述,例如均值为48.58nmol/L,标准差为21.433。关于这个数据的详细介绍可以参阅Resources里的两个PDF文件(Biochemistry assay quality procedures.pdf,Companion document for serum biomarker data.pdf)。另外从Categories选项卡中可以看到数据所属的类别和子类别。它还在页面顶部的类别树中水平显示。Data-Field是非常重要的编号,在确定选取的数据后,它的编号,是后面要提取数据的唯一编号。除了搜索Data-Field外,UKB网站还能搜索大类的搜索条件,例如选中Category后,在搜索窗口中搜索lifestyle,可以看到两个大类Lifestyle和Lifestyle and environment,点进去又有很多小类的关于lifestyle的数据,这个功能对我们搜索成系统一类的数据还是很有帮助的。除了搜索基本的表型信息外,Search功能还能提供genomics的搜索条件,在这个窗口下,你可以搜索SNP的rs号,通过在染色体上的位置信息寻找是否包含在UKB基因组数据中。
UKB数据使用介绍
UKB数据如何申请,这里就不详细叙述了,可以参照《如何利用UK Biobank申请研究数据和生物样本》。本节主要介绍如何从UKB数据中获得我们想要研究的数据。
当我们通过UKB的申请后,会收到一封包含32字符MD5校验和64字符的电子邮件,UKB中的数据都是保存在一个安全的在线存储库中,所有标准数据下载后必须解密并转换成合适的格式才能使用。
第一步,需要下载三个帮助程序来解密和转换数据,“ukbmd5”,“ukbunpack”,和 “ukbconv”。这些程序可以从UKB主网站的Data Showcase中的download下载,帮助程序可以选择Windows系统跟Linux系统下版本。但是使用Windows系统的研究者来说,需要使用命令提示符窗口下运行(可以使用Windows+R进入,但是路径需要跟三个帮助程序下载的位置保持一致),Linux系统需要在终端运行命令。除了上述的三个帮助程序外,在ukbconv转换数据过程中,还需要一个“encoding.ukb”的文件用于将编码定义分配给数据集中的变量,这个文件是兼容Windows跟Linux系统的,这个文件也需要跟上面的帮助程序在一个文件中。
第二步是要下载数据集,首先须登录到访问管理系统(Access Management System),导航到Downloads界面,进入Datasets,根据ID号,点击进入下载数据。在这里,需要进行身份验证,通过输入32字符的MD5校验(MD5 Checksum)进行验证(一长串字母和数字),并选择generate,将打开一个包含数据集链接的新页面。选择Fetch按钮下载加密数据集,尽量将数据集保存在与帮助程序相同的文件目录中。
第三步,数据解密和转换过程,如果是选用的Windows系统的,需要进入命令提示符窗口,然后进入到帮助程序及加密数据集所在的目录下(cd +位置信息),接下来需要验证加密数据集的完整性,输入命令ukbmd5 filename(加密数据集名字),运行此命令时产生的MD5的值应该与通过电子邮件提供的MD5值相同。如果值不同,则应删除文件并重新下载数据。当加密数据集通过验证后,接下来需要ukbunpack程序进行加密数据集的解密和解压为一个自定义的UKB格式,所用到的命令是1, ukbunpack inputfile keyvalue, 其中keyvalue表示来自通知电子邮件的64个字符的密码。命令2,ukbunpack inputfile keyfile,keyfile是包含密码的纯文本文件的名称。默认情况下,下载的文件命名为“ukbN”。,其中N是整数(申请号)。将解压缩此名称的文件以生成“ukbN.enc_ukb”。
到这一步,我们已经有了基本的数据,利用ukbconv程序(ukbconv inputfile format)可以将此数据集“ukbN.enc_ukb”转换为各种标准格式,例如csv,docs,sas,stata,r等数据格式,便于利用相应的软件进行后续处理分析,另外如果申请的数据量非常大的话,而分析只是用到一部分数据的话,我们还可以从ukbN.enc_ukb数据中提取用到的一部分数据,所用到的命令是ukbconv inputfile format flagfile-ID, Flag,主要是包括:
1)-i 后面跟一个txt文件,这个文件是一个每行都有一个字段Field-ID号的txt文件(例如Vitamin D 30890),需要提取的数据的Field-ID号都放进这个txt文件中,最终提取的数据就是含有这个txt的Field-ID的数据集。
2)–x,但是-x是原始文件中去除掉所在txt文件标注的Field-ID号,提取剩余的数据。
3)–o, 为输出文件指定一个替代名称。
4)–e,指定要从其它文件中提取编码信息的,默认是“encoding.ukb”。由于原始文件一般很大,提取数据非常耗时,因此我们一般是从Linux系统中进行提取数据,用到的命令如图七,

图七,Linux系统下进行数据的提取
提取的数据格式是r语言可以运行的tab文件。Field-ID.txt,是所用到的数据的Field-ID号(一行一个号),最终得到的数据名字是final_data。注意,大型数据集可能需要较长的时间(可能几个小时)转换,完成后,数据集将在指定的文件目录中输出。当获得所需数据后,就可以开始进行各式分析。
来源:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









