







图卷积网络(GCN)的计算可以分为基于频域(Spectural)和基于空域(Spatial)两种方式。
频域方法:
图的频域卷积是在傅里叶空间完成的,我们对图的拉普拉斯矩阵进行特征值分解,特征分解更有助于我们理解图的底层特征,能够更好的找到图中的簇或者子图,典型的频域方法有ChebNet,GCN等。但是图的特征值分解是一个特别耗时的操作,具有 [公式] 的复杂度,很难扩展到海量节点的场景中。
空域方法:
空间方法作用于节点的邻居节点,使用 K \ K K 个邻居节点来计算当前节点的属性。基于空域的方法的计算量要比频域方法小很多,时间复杂度约为 O ( ∣ E ∣ d ) \ O(|E|d) O(∣E∣d),本文要介绍的GraphSAGE就是经典的基于空域的图模型。
这里要介绍的GraphSAGE[1]是一个经典的基于空域的算法,它从两个方面对传统的GCN做了改进:
一是在训练时的,采样方式将GCN的全图采样优化到部分以节点为中心的邻居抽样,这使得大规模图数据的分布式训练成为可能,并且使得网络可以学习没有见过的节点,这也使得GraphSAGE可以做归纳学习(Inductive Learning)。
二是GraphSAGE研究了若干种邻居聚合的方式,并通过实验和理论分析对比了不同聚合方式的优缺点。
算法详解
GraphSAGE的算法核心是将整张图的采样优化到当前邻居节点的采样,因此我们从邻居采样和邻居聚合两个方面来对GraphSAGE进行解释。
在GraphSAGE之前的GCN模型中,都是采用的全图的训练方式,也就是说每一轮的迭代都要对全图的节点进行更新,当图的规模很大时,这种训练方式无疑是很耗时甚至无法更新的。mini-batch的训练时深度学习一个非常重要的特点,那么能否将mini-batch的思想用到GraphSAGE中呢,GraphSAGE提出了一个解决方案。它的流程大致分为3步:
- 对邻居进行随机采样,每一跳抽样的邻居数不多于 S k \ S_k Sk 个,如图1.2第一跳采集了3个邻居,第二跳采集了5个邻居;
- 生成目标节点的embedding:先聚合二跳邻居的特征,生成一跳邻居的embedding,再聚合一跳的embedding,生成目标节点的embedding;
- 将目标节点的embedding输入全连接网络得到目标节点的预测值。

从上面的介绍中我们可以看出,GraphSAGE的思想就是不断的聚合邻居信息,然后进行迭代更新。随着迭代次数的增加,每个节点的聚合的信息几乎都是全局的.
邻居的定义:
这里作者的做法是设置一个定值,每次选择邻居的时候就是从周围的直接邻居(一阶邻居)中均匀地采样固定个数个邻居。
随着迭代,可以聚合越来越远距离的信息

作者发现,K不必取很大的值,当K=2时,效果就很好了,也就是只用扩展到2阶邻居即可。例如在现实生活中,对你影响最大就是亲朋好友,这些属于一阶邻居,然后可能你偶尔从他们口中听说一些他们的同事、朋友的一些故事,这些会对你产生一定的影响,这些人就属于二阶邻居。但是到了三阶,可能基本对你不会产生什么影响了。你所接触到的、听到的、看到的,基本都在“二阶”的范围之内。
思考 & GCN
GCN公式:
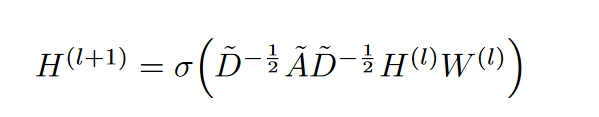
美化版:
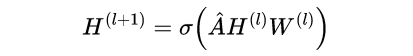
中间这个A帽子,就是上面丑公式中的那一大串东西。对A帽子的理解,其实它就是邻接矩阵A做的一个归一化。下面为了表达的方便,我直接当做邻接矩阵来分析吧!H是节点的每一层的特征矩阵。
这个公式的内部,画成矩阵相乘的形式是这样的:

其中,A是n×n维,H是n×m维,W则是m×u维。n就是节点个数,m则是节点特征的维度,u就是神经网络层的单元数。
先看看A乘以H是个啥意思:

A帽子矩阵的第i行和H矩阵的第j列对应元素相乘在求和就得到Q矩阵的(i,j)个元素。 这都是最基本的线性代数了,但我们不妨再仔细看看我图中高亮的那几个向量的内部:

这个图说的明明白白,所以我们发现,GCN的这一步,跟GraphSAGE是一样的思想,都是把邻居的特征做一个聚合(aggregation)。

所以,都是一个词——Aggregate!Aggregate就完事儿了。
这也是为什么GraphSAGE的作者说,他们的mean-aggregator跟GCN十分类似。
在GCN中,是直接把邻居的特征进行求和,而实际不是A跟H相乘,而是A帽子,A帽子是归一化的A,所以实际上我画的图中的邻居关系向量不应该是0,1构成的序列,而是归一化之后的结果,所以跟H的向量相乘之后,相当于是“求平均”。
GraphSAGE进一步拓展了“聚合”的方法,提出了LSTM、Pooling等聚合方式,不是简单地求平均,而是更加复杂的组合方式,所以有一些效果的提升也是在情理之内的。
其实,通过GraphSAGE得到的节点的embedding,在增加了新的节点之后,旧的节点也需要更新,这个是无法避免的,因为,新增加点意味着环境变了,那之前的节点的表示自然也应该有所调整。只不过,对于老节点,可能新增一个节点对其影响微乎其微,所以可以暂且使用原来的embedding,但如果新增了很多,极大地改变的原有的graph结构,那么就只能全部更新一次了。从这个角度去想的话,似乎GraphSAGE也不是什么“神仙”方法,只不过生成新节点embedding的过程,实施起来相比于GCN更加灵活方便了。
参考1:https://zhuanlan.zhihu.com/p/74242097
参考2:https://zhuanlan.zhihu.com/p/336195862
















 597
597











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











