






其中一组数据,只有少量的异常值(如图1),还手动标记个案编号,手动删除的。但当样本量很大的时候,手动标记异常值已经不现实了(如图2)。
于是,可以使用如下代码批量剔除异常值(快速找到解决办法途径,还是ChatGPT啊,虽然每次给的代码不一定完全准确,但按图索骥总是解决问题的)
% 【step1]导入数据,做回归,查看残差图
[data,txt,raw] = xlsread('mydata.xlsx','Sheet1');
x = data(:,1); n = size(x,1); X = [ones(n,1),x];
y = data(:,2);
[b,bint,r,rint,s] = regress(y,X,0.05); % b为beta0和beta1系数,bint为置信区间,r为残差向量,rint为残差置信区间;s包括决定系数r^2,F值,F检验的p值,剩余方差
rcoplot(r,rint) % 绘制残差图
% 【step2】根据残差剔除异常数据
stdr = std(r); meanr = mean(r);
outliers = find(abs(r-meanr)>2*stdr); %得到一组标记异常值的变量; 标记出与均值的距离大于2倍标准差的残差;数字2可以根据自己需求替换,如1-对异常值更严格,3-对异常值更放松
X(outliers,:) = [ ]; %剔除X中相应的异常值
y(outliers,:) = [ ];
[b,bint,r,rint,s] = regress(y, X,0.05); %剔除异常值后,回归效果会改善
rcoplot(r,rint) % 重新绘制残差图
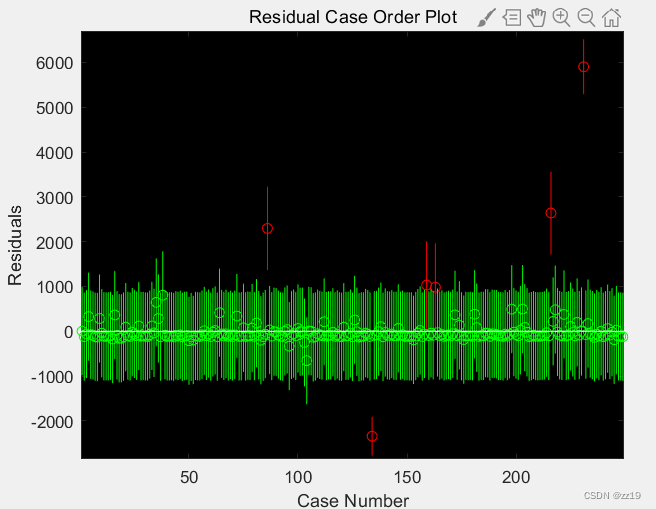
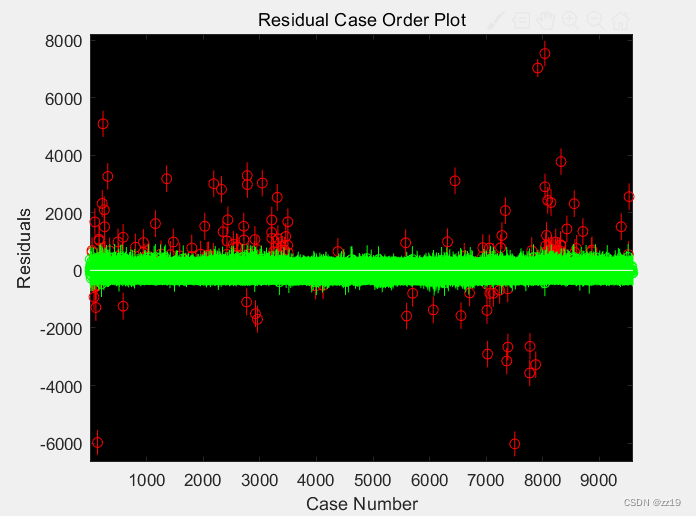
图1 图2
PS:
发现了另一个有意思的链接,使用 fitlm 函数 ,以便于在一元线性回归中去掉常数项。
链接:https://ww2.mathworks.cn/help/stats/fitlm.html















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









