







本文的视频教程可访问下面链接:
https://www.bilibili.com/video/BV1iB4y1E75V
动态Batch/动态分辨率基本概念介绍
若模型推理时包含动态Batch/动态分辨率特性,在模型推理时,需调用pyACL提供的接口设置模型推理时需使用的Batch数/分辨率。
关键原理说明如下:
- 加载模型。模型加载成功后,返回标识模型的ID。
对于动态Batch/动态分辨率,模型支持的Batch数已提前在构建模型时配置(构建模型的说明请参见《ATC工具使用指南》中的“ATC工具使用指南”章节),构建模型成功后,在生成的om模型中,会新增一个输入(下文简称动态Batch输入/动态分辨率输入),在模型推理时通过该新增的输入提供具体的Batch值/分辨率。
例如,a输入的Batch数/分辨率是动态的,在om模型中,会有与a对应的b输入来描述a的Batch数/分辨率。在模型执行时,准备a输入的数据结构请参见准备模型推理的输入/输出数据,准备b输入的数据结构、设置b输入的数据请依次参见2、3。
加载模型数据分为以下4种方式:
acl.mdl.load_from_file:从文件加载离线模型数据,由系统内部管理内存。
acl.mdl.load_from_mem:从内存加载离线模型数据,由系统内部管理内存。
acl.mdl.load_from_file_with_mem:从文件加载离线模型数据,由用户自行管理模型运行的内存(包括工作内存和权值内存)。
acl.mdl.load_from_mem_with_mem:从内存加载离线模型数据,由用户自行管理模型运行的内存(包括工作内存和权值内存)。
- 创建aclmdlDataset类型的数据,用于描述模型的输入数据、输出数据。
- 申请动态Batch/动态分辨率输入对应的内存前,需要先调用acl.mdl.get_input_index_by_name接口根据输入名称(固定为"ascend_mbatch_shape_data")获取模型中标识动态Batch/动态分辨率输入的index。
- 调用acl.mdl.get_input_size_by_index、acl.mdl.get_output_size_by_index接口根据index获取输入、输出内存大小。
- 调用acl.rt.malloc接口根据2.b中的大小申请内存。申请动态Batch/动态分辨率输入对应的内存后,无需用户设置内存中的数据(否则可能会导致业务异常),用户调用3.b中的接口后,系统会自动向内存中填入数据。
- 调用acl.create_data_buffer接口创建aclDataBuffer类型的数据,用于存放输入/输出数据的内存地址、内存大小。
- 调用acl.mdl.create_dataset接口创建aclmdlDataset类型的数据,并调用acl.mdl.add_dataset_buffer接口向aclmdlDataset类型的数据中增加aclDataBuffer类型的数据。
- 在成功加载模型之后,执行模型之前,设置动态Batch数/动态分辨率(模型的输入图片的宽和高)。
- 调用acl.mdl.get_input_index_by_name接口根据输入名称(固定为"ascend_mbatch_shape_data")获取模型中标识动态Batch/动态分辨率输入的index。
- 调用acl.mdl.set_dynamic_batch_size / acl.mdl.set_dynamic_hw_size接口设置动态Batch数/动态分辨率。
此处设置的Batch数/分辨率只能是模型转换时通过dynamic_batch_size/dynamic_image_size参数设置的Batch/分辨率档位中的某一个,模型转换的详细说明请参见《ATC工具使用指南》。
也可以调用acl.mdl.get_dynamic_batch/acl.mdl.get_dynamic_hw接口获取指定模型支持的Batch/分辨率档位数以及每一档中的Batch数/宽、高。
详情请见官网开发文档合集(华为 CANN 配置手册、产品文档、PDF - https://support.huawei.com/enterprise/zh/ascend-computing/cann-pid-251168373)
- 执行模型。
调用acl.mdl.execute接口执行模型。
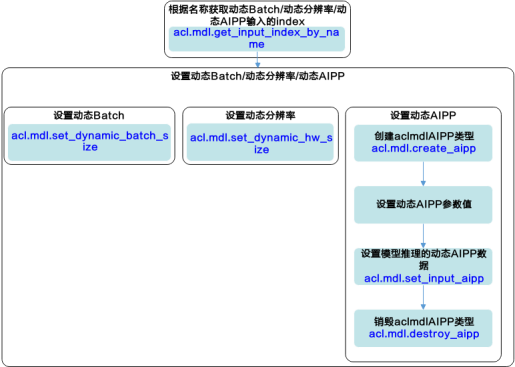
图1 动态Batch/动态分辨率流程图
Ascend昇腾开发环境极速搭建
开发环境搭建可选择A.Ubuntu环境下或者B.Windows环境下远程连接已经配置完毕的服务器
Ubuntu环境
注意分为昇腾设备和非升腾设备。非昇腾AI设备无需安装固件与驱动,仅能用于代码开发、编译等不依赖于昇腾设备的开发活动。在昇腾AI设备上安装开发环境,支持代码开发和编译,同时可以运行应用程序或进行训练脚本的迁移、开发&调试。
- 安装Ubuntu依赖
开发框架CANN开发环境支持多种操作系统,如这里的Ubuntu 18.04。请在root用户下执行如下命令检查源是否可用:

安装一些OS依赖库,具体可执行如下命令:
·apt-get install -y gcc g++ make cmake zlib1g zlib1g-dev openssl libsqlite3-dev libssl-dev libffi-dev
·sudo apt-get install -y unzip pciutils net-tools libblas-dev gfortran libblas3 libopenblas-dev libncursesw5-dev
因为此处我们已经安装过了,因此显示都已经是最新版


CANN 还依赖于Python3.7 ,因此首先确认一下本地的Python版本,执行命令python3 --version,如果python版本在3.7.0~ 3.7.11之间则可以跳过Python安装过程,默认情况下,Ubuntu 18.04安装的Python是3.6.9 。因此需要重新安装python3.7.5。在目录/home/jack/mysoft下,执行如下命令:

稍等片刻后,会在mysoft目录中下载完成此安装包Python-3.7.5.tgz。解压源码包:

进入解压后的文件夹,执行配置、编译和安装命令:

其中“--prefix”参数用于指定python安装路径,用户根据实际情况进行修改。“--enable-shared”参数用于编译出libpython3.7m.so.1.0动态库。“--enable-loadable-sqlite-extensions”参数用于加载libsqlite3-dev依赖。安装完成后,如果输入python3还是未生效,需要配置环境变量。可以执行如下命令设置python3.7.5环境变量,执行如下命令:

具体可以参考官网 https://www.hiascend.com/software/mindstudio
- Ubuntu依赖安装
之前的配置Python环境变量,只能在当前的Shell窗口有效,当开启新的命令窗口,则环境变量失效,示意如下所示:
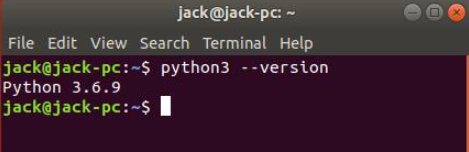
下面设置永久的环境变量,命令如下:

增加的内容如下:
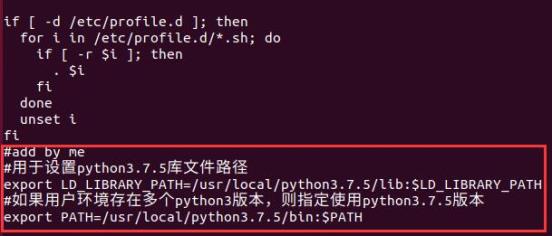
执行如下命令生效:

为后续安装CANN软件包、运行CANN软件环境变量设置脚本时能够自动配置python3.7.5环境变量,用户需提前创建好文件“use_private_python.info”,执行如下命令(root用户):

内容如下:

- 安装CANN开发工具
在基础Linux环境搭建完成后,需要登录华为相关网站(下载软件有权限要求,否则可能无法下载),并获取相关权限后,首先可以在Windows操作系统上下载两种架构(x86和aarch64)的CANN toolkit开发套件包Ascend-cann-toolkit_xxx.run 。
请根据CPU架构(x86_64、aarch64)获取对应的软件包。
例如本次安装的版本为CANN 5.1.RC1:
Ascend-cann-toolkit_5.1.RC1_linux-aarch64.run
Ascend-cann-toolkit_5.1.RC1_linux-x86_64.run
对于x86_64则: ./Ascend-cann-toolkit_{version}_linux-x86_64.run
对于运行环境为aarch64而开发环境为x86_64的场景,需同时获取两种架构的开发套件包。

({version}表示软件版本号,{arch}表示CPU架构。)
其主要用于用户开发应用、自定义算子和模型转换。开发套件包包含开发应用程序所需的库文件、开发辅助工具如ATC模型转换工具。
- 验证完整性
然后打开终端命令行,执行如下命令进行CANN toolkit安装:
./Ascend-cann-toolkit_{version}_linux-x86_64.run --check
./Ascend-cann-toolkit_{version}_linux-aarch64.run --check
./Ascend-cann-toolkit_{version}_linux-x86_64.run --install
./Ascend-cann-toolkit_{version}_linux-aarch64.run --install
输入如下命令设置可执行权限:
chmod +x Ascend-cann-toolkit_5.1.RC1_linux-aarch64.run
chmod +x Ascend-cann-toolkit_5.1.RC1_linux-x86_64.run

输入如下命令进行安装
./Ascend-cann-toolkit_5.1.RC1_linux-x86_64.run --install
安装过程如下
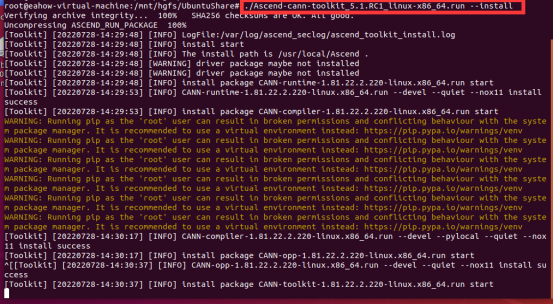
安装完成显示如下:
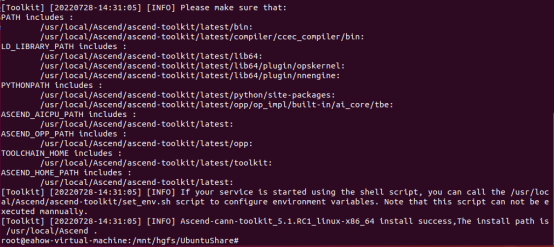
输入如下命令进行安装
./Ascend-cann-toolkit_5.1.RC1_linux-aarch64 --install
安装过程同上
- 配置交叉编译环境
最后,对于Atlas 200 AI加速模块 (RC场景)和Atlas 500 小站(运行环境aarch64架构)来说,当开发环境是一台X86 PC进行环境搭建时,需要在开发环境中安装交叉编译工具,具体命令如下:
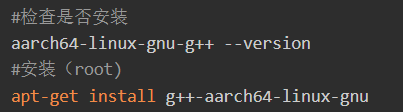
安装成功后,再次验证,执行如下命令:
此处已经配置完成

- 安装MindStudio
去昇腾社区官网,选择对应版本,下载安装包。
网址:https://www.hiascend.com/software/mindstudio/download
将MindStudio_{software version}_ubuntu18.04-x86_64.tar.gz软件包上传至MindStudio安装服务器。并解压
使用MindStudio的安装用户进入软件包解压后的MindStudio/bin目录,执行如下命令启动:

第一次运行时会检查环境,MindStudio依赖JDK和Python3等环境,检查过程示意如下:

首先根据提示安装相关库,执行如下命令:
·apt-get -y install xterm fonts-wqy-zenhei fonts-wqy-microhei fonts-arphic-ukai fonts-arphic-uming
·pip3.7 install --user grpcio coverage gnureadline pylint matplotlib pandas xlrd==1.2.0 absl-py

- MindStudio配置
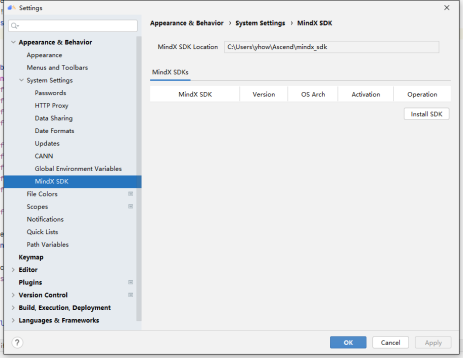
打开软件后,到setting配置CANN的路径

在里面配置MindX sdk
- 安装必要的pip包
python3 -m pip install numpy decorator sympy cffi pyyaml pathlib2 psutil protobuf scipy requests grpcio pylint absl-py --user -i https://pypi.tuna.tsinghua.edu.cn/simple
B.Windows环境
在官网选择MindStudio Windows版本进行下载

这里选择软件包下载,点击软件包下载,跳出安装界面进行安装
用户根据需要勾选安装选项

- Create Desktop Shortcut:创建桌面快捷方式,用户可根据系统配置选择“32-bit launcher”或者“64-bit launcher”。
- Update PATH variable(restart needed):将MindStudio的启动文件路径加入环境变量PATH中,可从系统命令行直接启动MindStudio。如果勾选此项,MindStudio安装配置完成后会重启操作系统。
- Update context menu:勾选“Add "Open Folder as Project"”后,右键单击文件夹,可以作为MindStudio工程打开。
- Create Associations:默认不勾选。
- 点next进入下一步
Windows SSH连接配置:
- 在菜单栏依次选择File > Settings... > Tools > SSH Configurations进入SSH连接配置。
- 在欢迎界面依次选择Customize> All Settings... > Tools > SSH Configurations进入SSH连接配置。
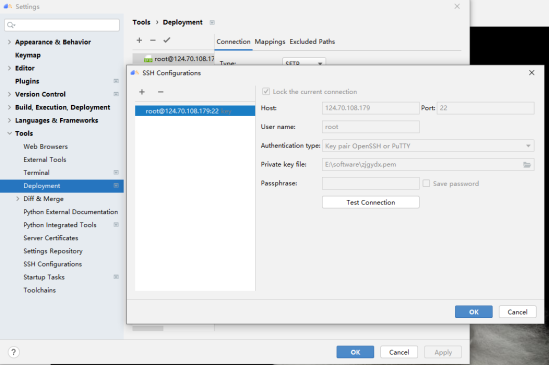
点击Test Connection
显示连接成功
动态Batch/动态分辨率设置总体流程
- 模型选择:在某些场景下,模型每次输入的BatchSize或分辨率是不固定的,如检测出目标后再执行目标识别网络,由于目标个数不固定导致目标识别网络输入BatchSize不固定。需要选择支持动态Batch/动态分辨率调整的模型,即输入BatchSize数值/分辨率数值可以动态调整的模型。
动态Batch:用户执行推理时,其Batch数是动态可变的。
动态分辨率H*W: 用户执行推理时,每张图片的分辨率H*W是动态可变的。
- 工程创建:通过MindStudio工具创建MyApp工程,根据模板创建后会自动生成模型、数据集和加载模型的运行文件的存储路径。
- 转换模型:
- 下载caffe或者pb等格式模型到指定的路径下。
- 使用MindStudio工具提供的模型转换功能将模型封装为om格式。
- 点击模型转换,成功将模型转换为om格式。
- 加载模型:模型加载的详细流程,请参见模型推理,模型加载成功后,返回标识模型的ID。模型转换完成后,在生成的om模型中,会新增一个输入,在模型推理时通过该新增的输入提供具体的Batch值/分辨率值。例如,a输入的Batch数/分辨率是,在om模型中,会有与a对应的b输入来描述a的Batch数/分辨率取值。
- 创建aclmdlDataset类型的数据:用于描述模型执行的输入数据、输出数据。
- 设置动态Batch/动态分辨率:成功加载模型之后,执行模型之前,设置动态Batch/动态分辨率的参数值。
注意:
对同一模型不能同时调用接口设置动态Batch、动态分辨率和动态维度。
对同一模型,AIPP(包括静态AIPP和动态AIPP)与动态维度(ND格式)不能同时使用。
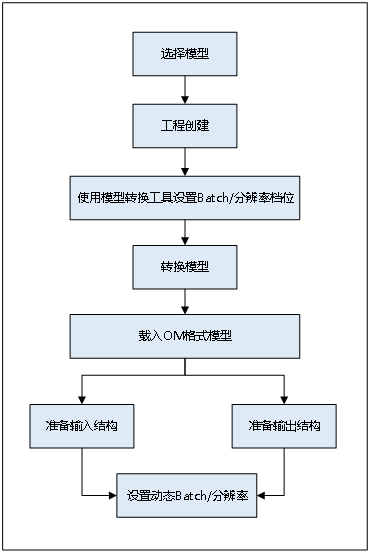
图2 动态Batch/动态分辨率设置总体流程图
动态Batch/动态分辨率设置例子详解
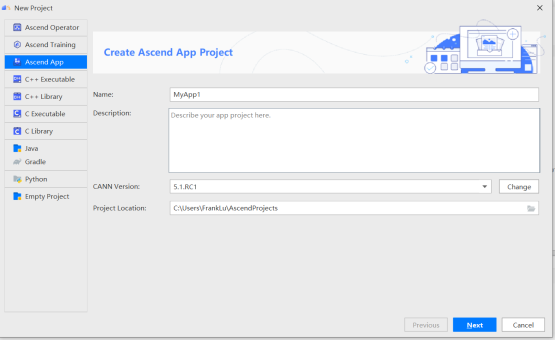
- MindStudio,选择AscendApp创建工程项目
- 点击next之后我们可以选择MindStudio提供的模板进行工程创建
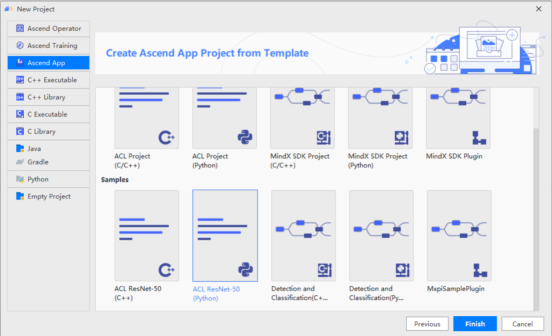
- 这里我们选择官网提供的图像分类的Resnet50模型的模板
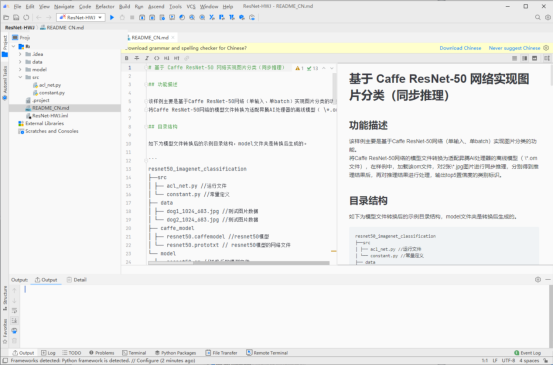
- 我们先到Pytorch官网下载Resnet50的pth文件,再到码云官网中找到Ascend 开源仓库,并找到Resnet50_Pytorch_Infer项目,然后根据里面的教程进行模型转换
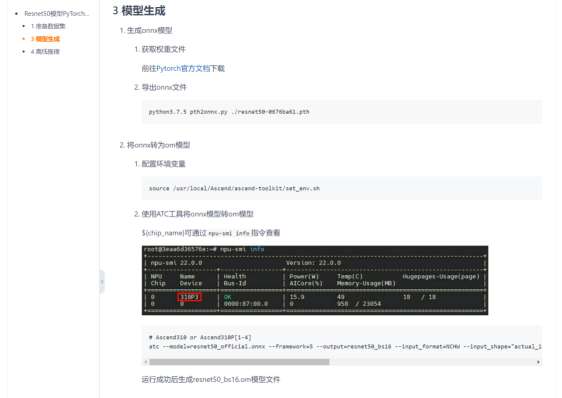
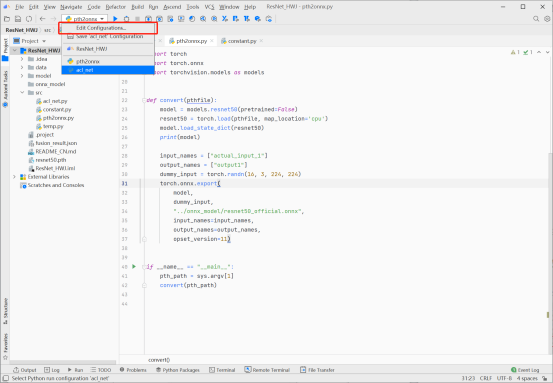
- 我们需要先将pth格式文件转换成onnx格式文件,为此我们需要使用Resnet50_Pytorch_Infer项目下的pth2onnx.py脚本文件。首先使用MindStudio建立如下图所示的运行配置,并点击运行(注意这里我们使用本地环境,须保证电脑有完整的Pytorch环境)

- 运行脚本文件可以得到转换后的文件,并把它放在项目文件夹中
- 为了进行onnx模型到om模型的转换,需要使用MindStudio转换工具以及华为的远程CANN环境(这里我们已经连接上了)。点击MindStudio中的Ascend选项,并选择Model Converter
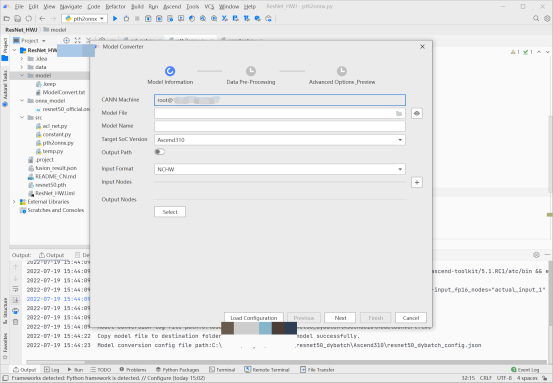
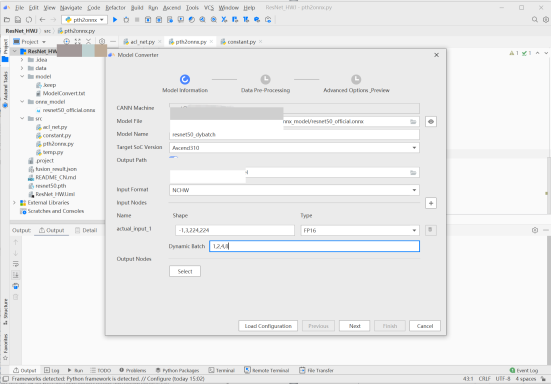
- 由于动态Batch和动态分辨率不能同时使用,故而我们分别使用MindStudio转换成支持动态batch和动态分辨率的离线模型。首先转换成支持动态Batch的离线模型,我们在Model Converter中选择部署在服务器中的onnx格式文件,选择输出路径(我们选择在本项目下的model文件夹),在输出形状中将Batch大小改为-1,并在Dynamic Batch中进行档位的输入(我们的档位为1,2,4,8),完成后一直点击next直到最后点击finsh ,直到控制台打印转换成功则模型转换完成,此时我们可以发现在modelzoo文件下出现了我们转换成功的离线模型文件

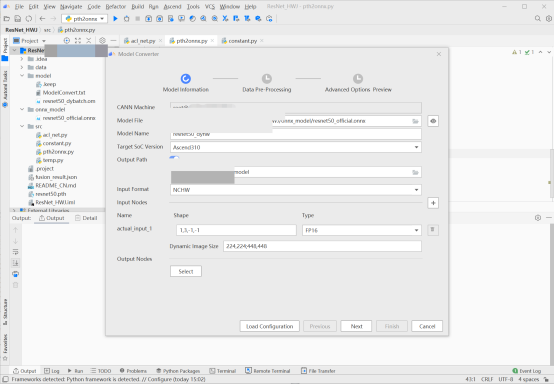
- 同理,将onnx文件转换成支持动态分辨率的离线模型,操作步骤和步骤8中是相似的,只需将长度和宽度两个维度设置为-1,并在Dynamic Image Size中进行档位的输入(我们的档位为224,224;448,448),并等待转换的完成

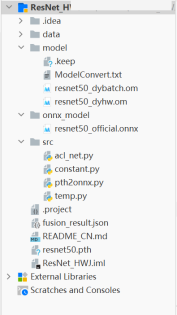
- 上述操作完成后我们便得到了支持动态Batch/动态分辨率的离线模型
- 打开模型的结构图,我们可以看到om模型对比原始模型,从原来的一个输入变为了两个输入,新增的输入就是用于调节可变Batch/分辨率设置的输入
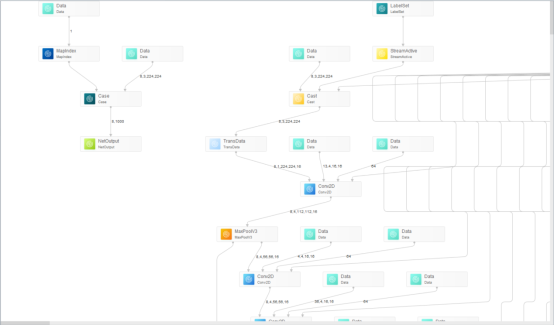
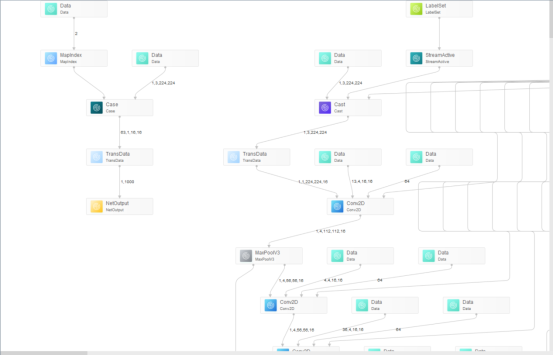
- 点击模型的输入,我们可以看到模型此时的最大输入为动态Batch/动态分辨率最大档位的输入;而在项目代码中数据预处理的函数处理后的单张图片分辨率为224x224。我们利用这个函数实现动态Batch/动态分辨率(选择档位224x224)的输入数据预处理。须知,对同一个模型,不能同时调用acl.mdl.set_dynamic_batch_size接口和acl.mdl.set_dynamic_hw_size接口。
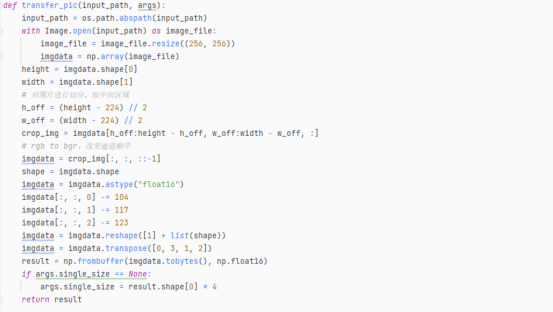
- 对于动态Batch设置,我们使用的档位是8,故而我们需要先加载支持动态Batch的离线模型resnet50_dybatch.om。该离线模型有两个输入,我们需要为两个输入分配内存,但是支持动态Batch的输入内存不需要向其中放入数据;对于动态分辨率设置,我们使用的档位是224x224,同理先加载支持动态Batch的离线模型resnet50_dyhw.om。该离线模型有两个输入,需要为两个输入分配内存,但是支持动态分辨率的输入内存不需要向其中放入数据。动态Batch/动态分辨率的输入名为ascend_mbatch_shape_data,为此我们可以通过接口方法acl.mdl.get_input_index_by_name(输入固定名称ascend_mbatch_shape_data)获得该输入的index,从而避免往其中放入数据
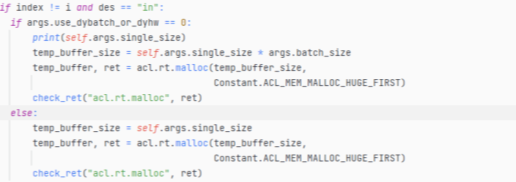
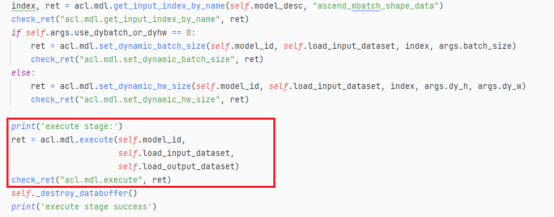
- 之后调用acl.mdl.create_dataset接口创建aclmdlDataset类型的数据,并调用acl.mdl.add_dataset_buffer接口向aclmdlDataset类型的数据中增加aclDataBuffer类型的数据

- 在准备好输入和输出的数据结构之后,我们就可以对动态Batch/动态分辨率进行设置了,须知我们输入的档位必须是符合转换模型时设置的档位。对于动态Batch,我们调用acl.mdl.set_dynamic_batch_size接口设置动态Batch数;对于动态分辨率,我们调用acl.mdl.set_dynamic_hw_size接口设置动态分辨率。
这里我们需要注意设置动态batch和动态分辨率的操作必须在模型执行前进行,否则程序会报错。
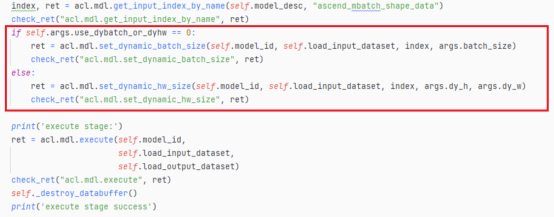
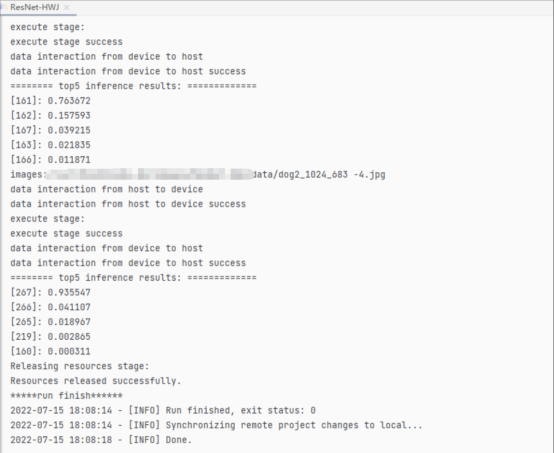
- 在设置完动态Batch/动态分辨率之后,我们调用模型的函数对模型进行测试。输入两张动物的图片,并对图片进行分类,最后的分类结果如图所示;到此动态Batch/动态分辨率的设置就结束了。

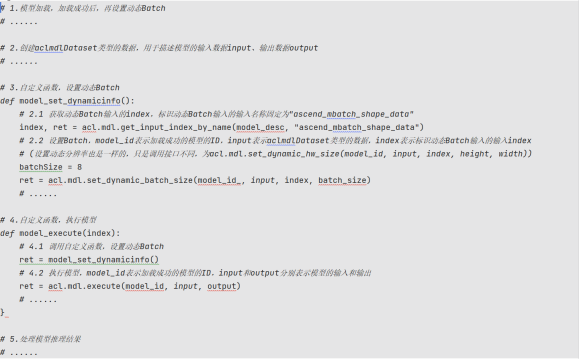
- 最后总结,对于使用离线模型使用动态Batch/动态分辨率的整体流程如下图所示
详情请见昇腾社区https://www.hiascend.com/















 373
373











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









