







反向自动微分的yacc和lex实现
0. 写在前面
为了完成编译原理的实验,本人在互联网上搜索yacc和lex相关的用法,但是解惑和细节的内容相对来说比较少,有的小部分也没有进行说明。于是在经历了很长时间的外文互联网搜索和阅读英语手册后,我完成了这个实验,并且决定写一写我对于yacc和lex工具的理解。当然源代码在GitHub上,如果觉得我的文章对你有帮助,还请不吝star和点赞和收藏。
1.反向自动微分
反向自动微分在互联网上可以找到很多相关资料,各位可以去看知乎上的文章,基本上大同小异。具体的原理就不介绍了,主要就是大一学过的多变量微积分中的链式求导法则,是很好理解的。
反向自动微分的好处在于,只要扫描两遍图就能输出f(x1,x2,x3…)对于每一个变量的偏导数,相比正向自动微分有n个变量就要扫描n遍,这简直是天大的好事。
这里给一个例子让大家亲自算一算如何进行反向自动微分。如果可以的话,请拿出纸和笔在纸上和我的步骤一起写,并且仔细体会我写的步骤,这样会有更好的理解。
首先要创建数据结构,包括内容为:名字,值,梯度值,节点类型,以及它的孩子指针reverse[0]和reverse[1]。由于我们在这里实现的微分最多是二目运算符(+,-,*,/,^等),或者是单目运算符(单个负号,sin,cos,exp等),所以一个节点最多只会有两个孩子,所以只需要两个孩子指针。每次建立节点都进行初始化操作:节点的名字为空,节点的孩子全部设置为null;
-
给出算式:f(x=3,y=5):x^2+2*sin(y)
-
为这个算式建立一个计算图,节点建立的顺序是按照从左到右扫描以及算符的优先程度建立,相当于编译原理最左规约。具体方法如下:
-
读入f(x=1,y=2):为x和y分别建立一个节点。节点的名字是“x“和”y“,节点的类型是“变量”,节点的值设置为变量的值,也就是3和5。节点的序列号是0和1,代表这两个节点是第一个和第二个创建的节点。
-
读入f(x=1,y=2):x:x已经创建了节点,所以不需要创建新节点。
-
读入f(x=3,y=5):x^2:为2创建一个单独的节点,节点类型是“数字”,节点值为2,节点序列号是2.
-
读入f(x=3,y=5):x2+:发现+优先级较低,于是为x2创建一个单独的节点,节点类型是““,节点的值是x2=9,节点的序列号是3,表明是我们第四个创建的节点。此时,将这个节点的两个孩子指针分别指向”x“和”2“的节点,也就是我们在1和3步骤中创建的节点,序号是0和2。这个操作表明:我们创建的3号节点对于x和2进行了乘方操作。
-
读入f(x=3,y=5):x^2+2:对新读入的2创建一个新的节点。可能你会问为什么不重新利用前一个已经为数字2创建的节点,当然你可以这么做,但是这么做并不是必要的,并且创建一个新节点可以为我们省去不少麻烦,所以何乐而不为呢?这一步剩下的操作和之前相同。此时节点的序列号应该是4。但是请注意:如果重复使用了x或者y这样的变量,你不能重复创建x或者y的新节点!原因是多元函数的微分应该把微分路径上的偏导数都相加。举个例子:f(x=2):3*x+ln(x)中,3*x节点的孩子是数字3和x,ln(x)的孩子是x,这两个x是同一个x,也就是说这两个x都是我们在第一步中创建的那个节点!原因是:反向计算时,指向x的指针会有两个,也就是3*x节点和ln(x)节点,相当于有两条路径会通向x节点,所以对于x来说,3*x和ln(x)就相当于两个不同的都和x相关的变量y(x)和z(x),那么对x的全微分就是dx=dy+dz,所以后续求x的偏导数时这两个节点的梯度值都应该用上,如果为x创建了两个不同的节点,那这两个节点的结果必须相加才是最终答案!这样既不省空间,也不省力气。
-
读入f(x=3,y=5):x^2+2*sin:发现sin的优先级比*乘法更高,于是我们继续向下读,这样可以找到sin的操作对象。
-
读入f(x=3,y=5):x^2+2*sin(y):我们发现sin已经读完了,并且我们知道为y创建的节点的序列号是1.现在我们创建一个节点,节点的第一个孩子指向y节点,节点的类型是sin,节点的值就是sin(5),序列号是5。
-
读入f(x=3,y=5):x^2+2*sin(y):我们的创建历程并没有结束!我们为2*sin(y)建立一个新的节点,节点的两个孩子指向新创立的2和y节点,节点的类型是*,节点的值就是2*sin(5),序列号是6。
-
读入f(x=3,y=5):x2+2*sin(y):我们的创建历程还是没有结束!x2+2*sin(y)创建一个新的节点,节点的两个孩子指向x^2和2*sin(y)节点,节点的类型+,节点的值就是算出来的值,序列号是7。
-
最后为了方便,我们创建一个root节点。这个节点的类型是root,孩子指向第9步中的节点,值和孩子相同,序列号是8,但是此时我们将root节点的梯度设置为1。此时我们的创建节点的过程已经结束了。这时候,我们将开始反向进行梯度的计算。你创建的图应该和下方的图是一样的。下图中的数字代表节点的序号。这样我们就从左到右得到了一个可以使用的计算图。
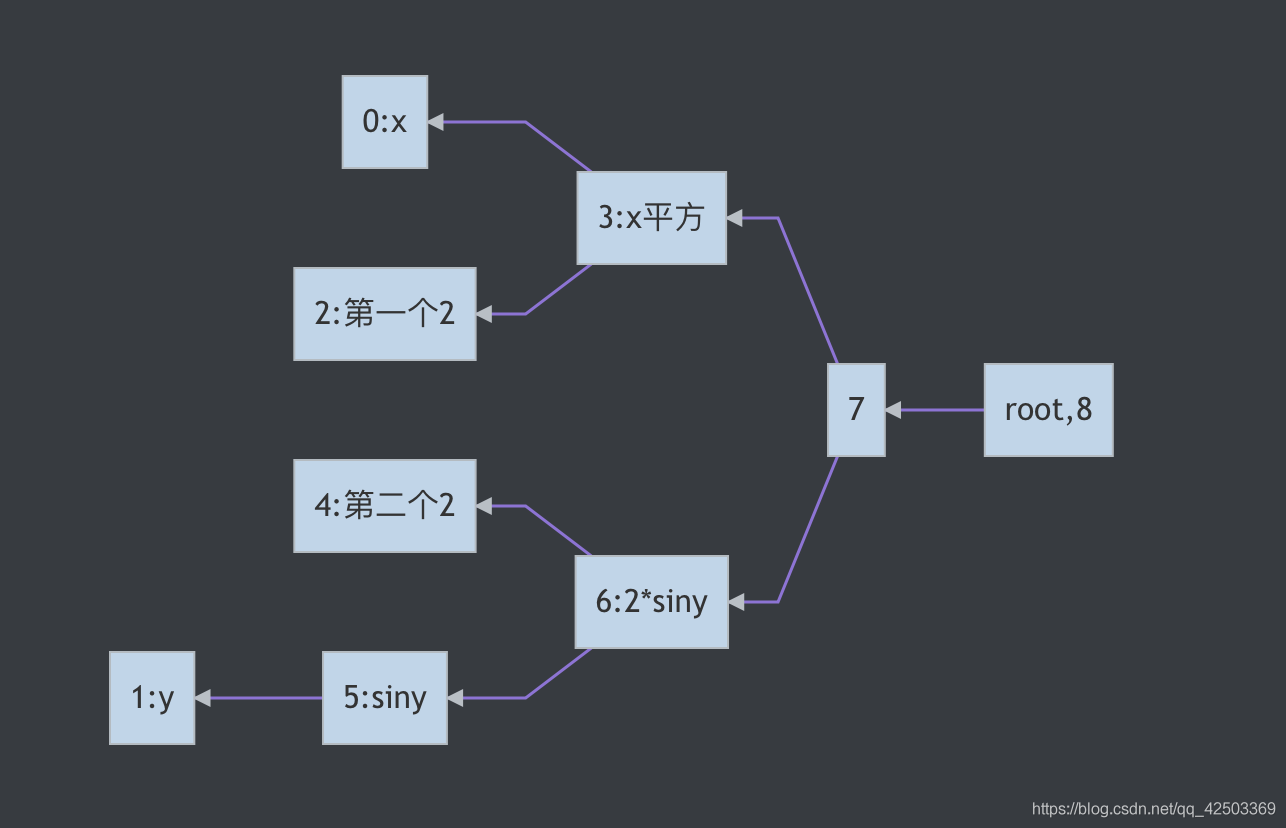
//下方是上图的mermaid代码,可以使用markdown查看 graph RL root,8-->7 7-->6:2*siny 7-->3:x平方 3:x平方-->0:x 3:x平方-->2:第一个2 4:第二个2 5:siny-->1:y 6:2*siny-->4:第二个2 6:2*siny-->5:siny我们将从节点8,也就是root节点开始反向计算。
-
-
处理完算式以后,我们的root里面应该已经算出了整个算式的值。现在我们反向求微分。我们下面都用grad代表节点的梯度值,用Vi代表节点的算式,方便阅读。我们写成Vi形式的时候,其实是把i节点所代表的算式当成一个变量处理,请记住这一点。
-
设置root的grad为1;
-
对于7节点:f(x) = x^2+2*sin(y) = V7。在这里,我们就把V7当成一个变量,并且求f(x)=V7对于变量V7的偏导数。这里由于f(x)只和V7相关,所以偏导数就是导数。由于y(x)=x的导数是1,我们很容易得到我们要求的偏导数是1。之后根据链式法则:
dx/dy = (dx/dz)(dz/dy),我们要把这一步算出来的1和前一步算出来的导数相乘,就得到了这个节点的梯度值。也就是1*1 = 1。我们把1填在节点7的grad中。后续所有节点都仿照这样进行计算即可。从8号节点按照递减的顺序向下求,最后到0和1节点,0和1节点里面的值就是我们想求的答案:分别是f对于x和y的偏导数。
-
比如2*siny,也就是6号节点。要求V6的grad,我们要看向V7。V7 = V3 + V6 也就是x^2+2*siny。显然V7对于V6的偏导数就是1,对于V3的偏导数也是1。之后我们令V3.grad += V7.grad * 1(为什么是+=在前面加粗的地方说过了。虽然那里说的是x,但是对于每一个有两个入边的节点都成立,所以我们都用+=运算符),V6.grad += V7.grad * 1;
-
同理我们最后就能求得结果。在x节点中存储的就是对x的偏导数,y节点中就是对y的偏导数。
-
-
现在你可以亲自动手算一算知乎上或者其他地方都用的这个例子:f(x1=2,x2=3):ln(x)+x1*x2-sin(x2)的偏导数值了。
2. lex词法分析器和yacc语法分析器
- yacc和lex简洁版手册 http://dinosaur.compilertools.net/
- 小型c语言编译器 https://github.com/rabishah/Mini-C-Compiler-using-Flex-And-Yacc
- lex和yacc小型计算器 https://developer.ibm.com/technologies/systems/tutorials/au-lexyacc/
我们在写yacc之前,需要一个能够向yacc传递词语的工具。这个工具就是lex。当然你可以在yacc中自己写,但是用lex生成词法分析器是更好的选择:自动,方便,快捷,有丰富的全局变量。lex的主要用法在很多教材上都有。上面推荐一些网站,可以去看一看。看完以后再回来看我的这篇文章,接下来主要是进行一些讲解,但是是建立在你已经知道lex、yacc是什么和基本用法上的基础上的。
接下来是细节部分的解惑。完整代码在Github上。
lex难点解答
下面是一段源代码,我已经给出了较为详细的注释。正规式的语法之类教材或者网上都可以找到,这里不过多讲解。lex文件也可以加上主程序单独生成lex.yy.c,网上也有详细的案例和教程。lex默认输入输出yyin和yyout是stdin和stdout,也就是打印到屏幕,从屏幕读取。你可以修改这两个指向你的文件,这样lex就可以读入或者输出文件。主程序借鉴了https://www.cnblogs.com/wp5719/p/5528896.html,但是只用于说明,不保证可以正常运行。读者应自己编写main函数。
%{//开头
//这个部分里面的所有内容都会被原封不动拷贝进生成的lex.yy.c文件,所以可以像C语言代码一样编写。
#include <stdio.h> //在调试打印过程中,我们需要调用printf,所以在这里包含头文件
#include <string.h>
//extern char* yytext
//yytext是lex自带的extern类型变量,它指向正在分析的单词的string的头部,可以直接printf或者传递给yacc
extern int yylval;
//yylval是lex自带的一个extern类型的变量,可以用于在yacc和lex之间传递变量的值。在这里是 //为了lex文件单独使用时声明的
// enum op{zs, NUMBER, IDENT ,FUNC ,LEFTPA,RIGHTPA ,COMMA ,COLON,EQUA,PLUS ,MINUS,MUL ,DIV,COS ,SIN, LN ,EXP, POW };
/*同样是为了lex单独使用,如果和yacc一起使用,你应该在yacc文件中定义这些变量。zs用于占位,这样就不会return 0,虽然可有可无*/
%}//结束
/*一些常规定义,使用了正规式*/
letter [A-Za-z] //代表任意一个字母
digit [0-9] //代表任意一位数字
%% //用两个百分号开头表示进入词法规则部分。下面的printf用于调试。此部分注释不能顶格写。
//越是排在前面的优先级越高,所以你不能把下方的用于识别标识符的规则放在cos、sin之前,这样lex会认为cos是一个标识符而不是代 表cos这个函数!
"\n" {
//大括号里的部分都会被拷贝进生成的C文件!正常使用即可
//注意:lex会分析所有输入的符号,包括回车在内!如果不识别回车,很可能会报错!!!
// printf("enter\n");
return EOL;
}
"cos" {
// printf("%s, cos\n",yytext);
return COS;
}
"=" {
// printf("%s, equal\n",yytext);
return EQUA;
}
/*
这里填写其他的规则,因为篇幅原因略去
*/
//下面正规式表示:一个字母开头,后面为空或者跟了一串字母和数字的组合,可以是x,x1,x12,xe2r4等
{letter}({letter}|{digit})* {
// printf("%s,ident\n",yytext);
return IDENT;
}
//下面表示最少有一位的数字组合,如0,12,08,184819657981465等
{digit}+ {
// printf("%s, number\n",yytext);
yylval = atoi(yytext);
//将yytex的字符串转换成数字传给yylval用于yacc使用
return NUMBER;
}
%% //如果下方没有函数,这个百分号是不必要的。下面这部分的代码也会被拷贝进生成的c文件,所以可以正常按照C语言的格式写
/*
可以用于编写测试用的main函数等等。你可以使用yylex()、yylval等返回上方的数字,IDENT,COS等并加以利用,可以上网搜索例子
注意:单独使用lex时,一定要记得定义IDENT等变量!因为这些本应该在yacc中定义!
int main (int argc, char ** argv){
int c,j=0;
if (argc>=2){
if ((yyin = fopen(argv[1], "r")) == NULL){
printf("Can't open file %s\n", argv[1]);
return 1;
}
if (argc>=3){
yyout=fopen(argv[2], "w");
}
}
* yyin和yyout是lex中定义的输入输出文件指针,它们指明了
* lex生成的词法分析器从哪里获得输入和输出到哪里。
* 默认:键盘输入,屏幕输出。
while (c = yylex()){
writeout(c);
j++;
if (j%5 == 0) writeout(NEWLINE);
}
if(argc>=2){
fclose(yyin);
if (argc>=3) fclose(yyout);
}
return 0;
}*/
yacc难点解惑
下面是一段yacc源代码,我已经给出了较为详细的注释。正规式的语法之类教材或者网上都可以找到,这里不过多讲解。lex文件也可以加上主程序单独生成y.tab.c,网上也有详细的案例和教程。根据使用的系统不同,yacc可能是bison等,但是使用上差别不大。也有可能会生成y.tab.h,这时候就请根据网上的其他进行修改。
众所周知,我们可以使用继承属性和综合属性。下面的代码没有使用继承属性,但是可以参考:https://github.com/aoxy/RevAutoDiff-with-Flex-and-Bison 使用union定义了终结符和非终结符的属性,用struct包含继承和综合属性,从而进行计算。
%{
//和lex一样,这个部分里面所有的内容都会被拷贝进生成的C文件。你可以自己写额外的文件并包含在这里
#include <ctype.h> //包含C代码片段的所需库
#include <stdio.h>
#include <string.h>
#include "lex.yy.c" //包含lex产生的C文件,里面包含我们所需的词法分析器和yylval等变量
#include <math.h>
#define YYSTYPE int //定义程序使用的栈的数据类型,也就是后面$$或者$3等的类型,这里是int
int yyparse(void); //定义yacc的一些函数用于使用,具体实现不需要我们自己写
int yyerror(char *s);
int count_id = 0; //定义一些我们所需的全局变量,分别是标识符节点计数,非标识符节点计数和所有节点数
int count_node = 0;
int all_node = 0;
enum OP {zs,ROOT,ID,NU,PL,MN,UMN,DI,MU,P,L,C,S,EX};
//定义一些我们需要进行计算的操作符号,也就是在反向自动微分中的节点类型
typedef struct Node{ //定义反向自动微分中的节点数据结构
double diff;
double val;
char name[10];
enum OP op;
struct Node *reverse[10];
}node;
node *chain[40]; //定义最多40个节点的“钥匙串”,可以按顺序存储生成的节点
node* CreateNode(); //声明一些函数,具体实现在最后,你也可以把它们放在其他文件里,但是记得要include
void calcVal(node *n);
int FindID(char name[]);
void ReverseAutoDiff(node *chain[]);
%}//结束
/*这里是定义lex和yacc中的终结符号。token就是普通的定义,left和right表示运算符左右结合,优先级是越下方的越高,这里MUL乘法的优先级就比PLUS加法高,比cos余弦运算要低。*/
//%start Start yacc会默认第一个产生式为开始符号,所以这里可以不写
/*
%union {
struct tnode* node;
char name;
char* str;
}
%type <name> func_def 你可以为非终结符也设置定义,但是注意:要先用union包含你想使用的定义!左边是一些例子!
%type <name> var_list 不代表可以正常使用,请读者根据需要编写!
%type <name> var_init
%type <node> expr
*/
%token EQUA
%left PLUS MINUS
%left MUL DIV
%token COS SIN
%left LN EXP POW
%token NUMBER IDENT FUNC LEFTPA RIGHTPA COMMA COLON EOL
%% //第一部分结束,进入第二部分。第二部分内容会删减,完整在github
Start : REV_AutoDiff //这一步是为了可以输入多个表达式进行求值
| REV_AutoDiff Start
;
REV_AutoDiff : func_def EOL //使用EOL表示已经结束了!这很重要!
{
printf("val = %lf\n",chain[all_node-1]->val); //打印表达式的值
ReverseAutoDiff(chain); //调用函数计算偏微分
}
;
func_def : FUNC LEFTPA var_list RIGHTPA COLON expr
{
node *x = CreateNode(); //创建节点
chain[all_node++] = x; //放进“钥匙串”,总节点数+1,除了标识符节点外的节点数+1
count_node++;
x->op = ROOT; //设置节点类型
x->reverse[0] = chain[$6]; //将孩子指向钥匙串中的点。
/*
这里为什么是$6呢?因为$$代表冒号左边的值,$1是FUNC,$2是LEFTPA,$3是var_list,以此类推,expr的值是$6
*/
// printf("x->reverse[0]: %d, val: %lf\n",$6, chain[$6]->val);
calcVal(x);
}
;
var_init : IDENT
{ //注意:这个大括号算$2!!!
node *x = CreateNode();
chain[all_node++] = x;
count_id++;
x->op = ID;
strcpy(x->name,yytext); //这里就使用了yytext变量!
// printf("yytext: %s, x->name: %s\n",yytext, x->name);
}
EQUA NUMBER
{
node *x = chain[all_node-1];
// printf("ident name:%s, ident val:%d\n",x->name,$4);
x->val = $4;
//重要!这里为什么是$4?因为IDENT是1,EQUA是3,NUMBER是4!中间的那一段大括号也算在里面,是$2!各位可以试试打印$2的值
}
;
var_list : var_init
| var_list COMMA var_init
;
expr : IDENT
{
int x = FindID(yytext);
// printf("x value: %d\n",x);
$$ = x;
}
| LEFTPA expr RIGHTPA
{
$$ = $2; //这里甚至可以不用写,因为yacc使用的是栈,这里默认就会把expr的值放在栈顶,不需要赋值
}
/*
其他产生式,这里省略
*/
;
%%
extern FILE *yyin; //可以不写,默认stdin
int main()
{
yyin = stdin;
return yyparse(); //表示一直进行下去
}
yyerror(s) //会自动产生错误放进stderr,所以直接打印即可
char *s;
{
fprintf(stderr, "%s\n", s );
}
int yywrap(){
return 1; //用于表示有没有分析完成的函数,默认返回1
}
node* CreateNode(){ //用于实现反向自动微分的函数,完整在GitHub,比如这里给出的创建节点函数
node* x = (node*)malloc(sizeof(node));
x->diff = x->val = 0;
for(int i = 0; i < 10; i++){
x->name[i] = '\0';
x->reverse[i] = NULL;
}
/* printf("Build node: %d\n",all_node); */
return x;
}
/*
其他必要函数
*/
3. 生成可执行文件
在macOS或者Linux的终端中依次输入:
cd 你的存放.l和.y文件的目录
lex 你的文件名.l
yacc 你的文件名.y
gcc y.tab.c -ly -ll
如果无法生成,请检查你是否安装了flex(lex),bison(yacc),并使用homebrew等方式安装
第一步会产生lex.yy.c
第二步会产生y.tab.c
第三步,编译y.tab,c,链接ly和ll库,这两个库中包含了许多我们没有定义或者使用,但是yacc和lex需要的函数,比如yyerror等就在其中。不包含这两个库会导致程序出错!这条指令会根据系统有所不同,非mac用户请搜索具体使用方法。
最后运行你的程序,双击打开a.out 或者:
./a.out
注意:如果你的lex没有处理空格和换行符,那么输入空格或换行符将导致出错!想处理这些,可以在lex中添加规则:
delim [\t\n]
/* 转义字符,\t表示制表符,\n表示换行符。*/
ws {delim}+
{ws} {;/* 此时词法分析器没有动作,也不返回,而是继续分析。 */}
/*
正规式部分用大括号扩住的表示正规定义名,例如{ws}。
*/
4. 写在最后
编译原理其实不是一门简单的课程,虽然这次试验比较艰难,但是确实能学到不少东西。本人水平有限,有错漏之处还请斧正。
我的GitHub名:isaacveg
此项目GitHub地址:https://github.com/isaacveg/Yacc-lex-for-reversed-automatic-differentiation
如果觉得有用,请点赞或者star,你的肯定对我很重要!欢迎通过各种方式和我联系关于文章内容的错误或者不当之处,但是我不会给你源代码或者帮你编译!自己学习也是很重要的!















 320
320











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









