










个性化联邦学习,通过分组在noniid数据上元学习
个性化联邦学习(PFL)提供了一种能够适应每个客户端的本地数据分布的个性化模型。现有的基于元学习的方法隐含地假设不同客户端之间的数据分布是相似的,由于联邦学习中数据异构的特性,这可能不适用。
提出了一种基于组的联邦元学习框架,称为G-FML,该框架根据客户数据分布的相似性自适应地将客户分组,并在每个分组内进行元学习获得个性化模型。特别地,我们开发了一种简单而有效的分组机制来自适应地将客户端划分为多个组。每个组都是由具有相似数据分布的客户端组成的,可以推广到一个高度异构的环境。
在三个异构基准数据集上评估了我们提出的G-FML框架的有效性。实验结果表明,相对于最先进的联邦元学习,我们的框架将模型精度提高了13.15%。
intro
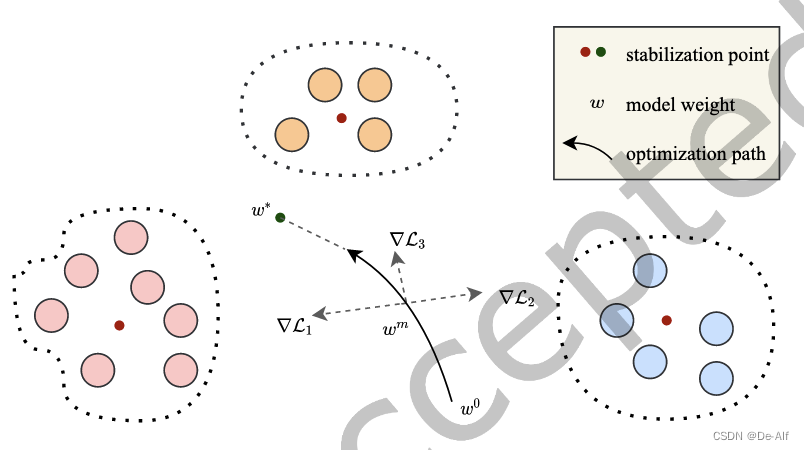
G-FML,它学习多个组智能元模型以同时拟合不同的数据分布。G-FML的目标是学习准确和个性化的模型,尽管数据分布在不同的客户端之间非常分散。特别是,为了学习多个组智能元模型,首先开发了一个高效的分组算法,并且在每个组中学习一个组智能元模型。
问题的主要挑战是如何量化客户机的数据分布。为此,使用深度自编码器来学习每个客户端本地数据的低维特征表示,将它们聚合为一个整体来表示每个客户端的数据分布。在每一轮通信中,任务表示是不同的,这可能会影响分组结果。因此每一轮通信重新分组客户端。
主要贡献如下:
-
确定并证明了依赖于单个模型的方法的局限性
-
提出了一个框架和一个有效的分组算法来解决这一限制。具体来说,该框架生成一组全局元模型,并将其准确地分配给客户端。
-
在合成数据集和真实数据集上的实验结果表明,G-FML比在模型精度和收敛速度方面最先进。
相关工作
本工作分类为基于模型的个性化学习。介绍了一些多模型的措施,比如基于聚类的学习,因此常常产生大量消耗,本方法传输自动编码器的编码因此比较简单而且只需要余弦相似度进行分组;单模型,包括了个性化层和元学习。作者认为找一个共同的分布不太现实。
问题定义
FL中,N客户端训练一个共享模型theta,各有各的数据集D,损失函数l,即最小化所有客户端上的经验损失函数。问题是前提要求iid数据分布,若为non iid则不好。
iid: independent identical distribution,独立同分布。理解成所有客户端上的样本服从统一的分布。
non iid导致global model无法在所有客户端上进行最小化经验损失。因此采用分组元学习的方法。问题定义后的全局目标如下。分了K组,共N客户端。
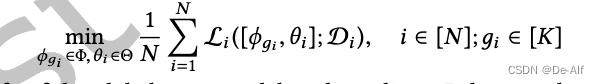
overview
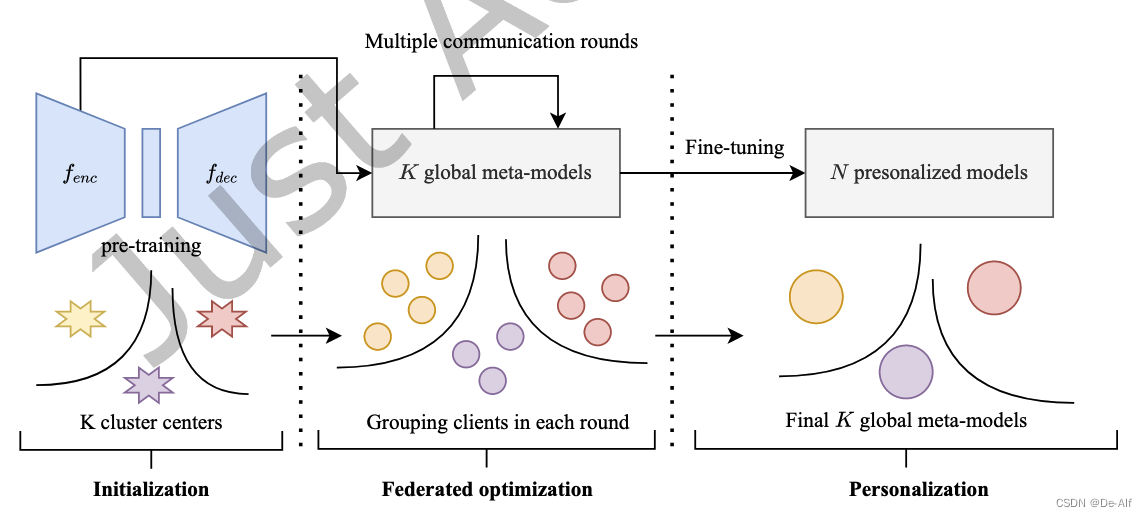
关键点在于进行分组。全训练过程分三部分:初始化,联邦优化和个性化。
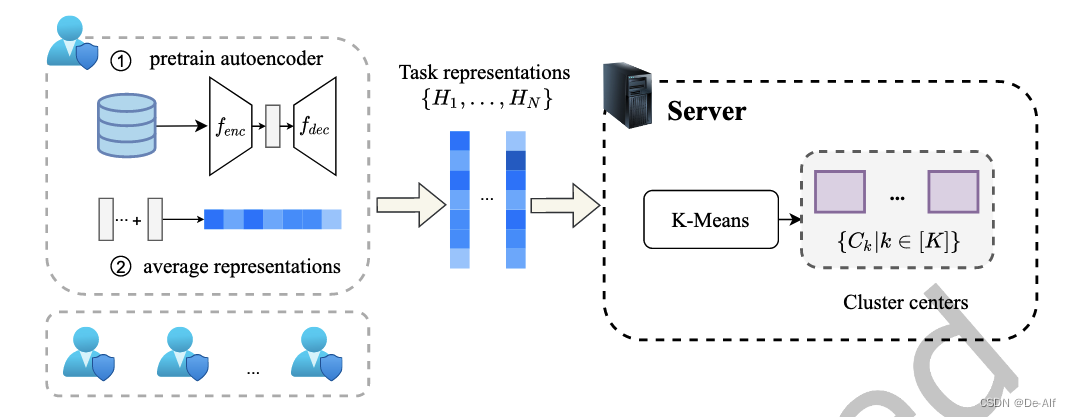
初始化:自动编码器学习客户端的任务表示,之后分组。每个客户机从服务器下载自动编码器架构。自动编码器从局部数据中提取低维向量,然后将任务表示传输到服务器,使用这些表示的输入来执行K-Means聚类算法。可以得到K个簇中心。这些集群中心用于识别联邦优化阶段中的组。此外,每个组的元模型具有相同的模型初始化。
联邦优化:在这个阶段,G-FML的目标是优化分组元模型。这个阶段遵循联邦学习的标准过程。客户端首先从服务器下载相应的组智能元模型,训练,同时使用预训练的编码器来获得训练数据的任务表示。最后将更新后的模型和任务表示传输给服务器。服务器通过测量和比较任务表示与K个聚类中心的相似性来完成分组过程。之后,服务器对每个组中的元模型执行模型聚合,以获得下一轮通信所需的新的全局元模型。重复此过程,直到满足某些终止标准,即有限的通信轮数。
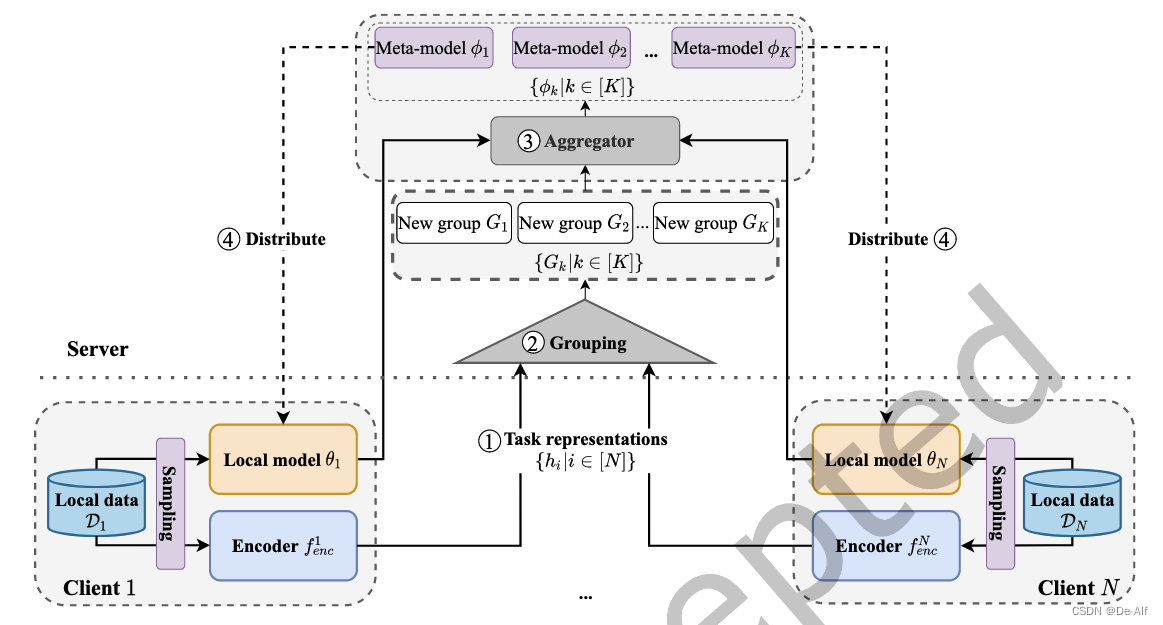
个性化阶段:在这个阶段,遵循使用元学习进行个性化的传统设计,对每个客户端对应的组智能元模型执行一步梯度下降。
自动编解码器各为两层ReLU全连接层,通过直接平均得到所有样本的低纬度表示H。在服务器上K means聚类后用于起始点
联邦优化阶段的具体算法用了MAML,优化目标如下,即进行一步优化后效果好的模型。更新方法:模型g0,梯度下降一次得到中间模型g1,之后用中间模型g1的梯度去更新原本的模型g0。重复上述操作。作者使用数据生成中间表示。
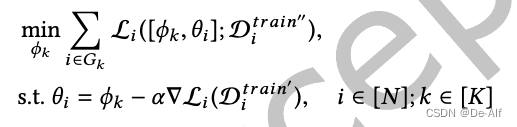
分组算法用了聚类中心和客户端表示的kmeans。聚合算法就是普通的按数据量组内加权平均。
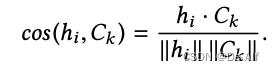

个性化阶段,在D test上学习表示,然后上传到服务器,返回分组对应的模型,之后用一次梯度下降获取模型。(真的就一次?)
分析:分组带来的复杂度O(KSd),d很小,S是一小部分,K也通常比S小很多。空间复杂度是K倍模型大小。K也不大。自动编解码器不需要计算到收敛。同时本方法可以不停止,也可以训练到指定轮数。
实验
数据集:
-
3个特征为60维的合成数据集,100个客户端,集群数量为超参数M,每个客户端的数据呈现出聚类结构,聚类数量由超参数
M确定,M的取值分别为1、4、8,每个聚类中心µj从高斯分布N(Bj, I)中生成,其中Bj也从高斯分布N(0, I)中生成。每个客户端在t时刻,根据概率分布(p1, ..., pM)(这些概率相等且总和为1)选择一个聚类中心µj。每个客户端在t时刻的数据样本数nt由公式nt = min(mt + 50, 5000)确定,其中mt从对数正态分布(均值为3,标准差为2的对数正态分布)中抽取。每个数据样本的特征xti从正态分布N(vt, σ)中生成,其中vt从正态分布N(Ct, I)生成,Ct同样从N(0, I)中生成。方差σ的对角元素根据σi,i = i^-1.2设定。每个样本的标签yti由argmax(sigmoid(wt xti + N(0, 0.1 * I)))决定,其中wt由wt = Qut计算得出,ut从N(µt, I)中生成,Q是维度为Rd+1×s的矩阵。所有合成数据集随机划分为60%的训练集和40%的测试集。使用多项式逻辑回归模型进行分类,输入为展平的60维向量,输出为0至9之间的类别标签。 -
FEMNIST:62个class的手写数字和字母识别,200客户端,从EMNIST数据集派生出来,专为联邦学习场景设计。EMNIST本身是扩展自MNIST的手写数字和字母数据集。在这个特定的设置中,只选用了从‘a’到‘j’的10个类别。每个客户端只持有这10个类别中的5个。90%的训练集和10%的测试集,模型是一个含有一个隐藏层(100个神经元)的两层深度神经网络(DNN)。输入是展平的784维向量,28x28像素的图像。输出是一个类标签,范围从0到9,对应上述10个类别。
-
Shakespeare数据集源自《莎士比亚全集》,每个戏剧中的不同角色被视为一个独立的客户端,模拟现实生活中用户的数据隐私和分布。选择了103个不同的说话角色作为客户端进行训练,70%的训练集和30%的测试集。使用的是一个含有100个隐藏单元的两层长短期记忆网络(LSTM),模型包括一个8维的嵌入层,用于将字符转换为数值表示。输入是一个长度为80个字符的序列。输出是每个训练样本后的一个字符,典型的下一个字符预测任务。
baselines:
-
FedAvg
-
FedAvg+Update,在FedAvg的基础上微调一下。
-
FedProx,知名优化器,使用近似项来防止本地和全局偏离太远。这里设置为0.001
-
IFCA:聚类联邦学习,客户端会被分配到不同组进行优化
-
PerFedAvg:SOTA FML算法
对比:每个epoch用一个batch的数据训练本地模型。全部用SGD,在本地测试集上进行测试,汇报全部客户端的平均准确率。每次选择10客户端,合成数据集lr=0.01,FEMNIST 0.003,Shakespeare 0.8。初始阶段训练encoder 50个iterations。作者没说iteration的定义,先理解成训练50轮,因为没有提供batch size。优化阶段,在test set上做一步梯度下降。问题:在test set上下降?这样公平吗
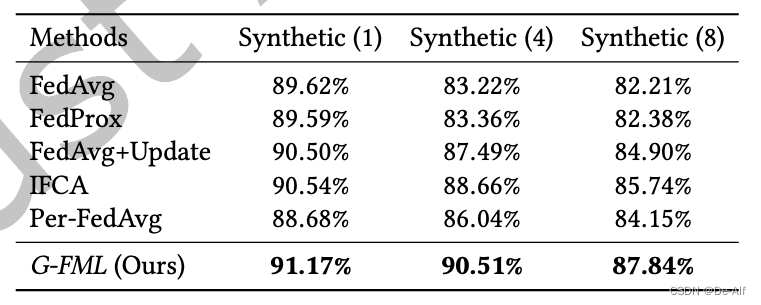
Noniid的影响:合成数据集上local epochs=5,batchsize=10,beta=0.005,K=4(集群)600轮客户端的平均测试精度和训练损失。收敛时,所有方法在合成(1)数据集上的测试精度是相似的。但是随着统计异质性的增加,K = 4时G-FML的检验精度变差。G-FML虽然性能较差,但测试精度较高。在Synthetic(4)数据集和Synthetic(8)数据集上,G-FML在120轮通信之前的收敛速度比IFCA慢。此后,G-FML不断提高,达到了更高的精度,而IFCA在较低的精度上收敛。出乎意料的是,FedAvg+Update比Per-FedAvg实现了更高的精度,这可能是因为使用了Per-FedAvg的一阶近似版本来更新,忽略了二阶项。总体而言,实证结果表明G-FML可以处理不同层次的非iid数据,并且训练过程更加高效。
K集群数量的影响:在Synthetic(8)、FEMNIST和Shakespeare数据集上进行实验。K来自有限候选集(2,4,8,10)。观察到对于各种数据集都存在一个最优K值。具体来说,对于Synthetic(8)数据集,由于创建了具有8个集群中心的数据集,因此使用k8时它的性能最好。对于FEMNIST数据集,虽然K = 4时G-FML的性能与K = 8相似,但K = 4在训练过程中表现更为稳定。对于Shakespeare数据集,K = 4达到了最好的性能,而当K = 8和K = 10时,G-FML在特定的精度范围内波动。因此,应该根据异构数据集的级别仔细调整K。在实践中,可以在少量的通信轮中运行不同K值的G-FML,然后选择性能最好的K值。
分组策略的有效性:比较策略有RCA(随机客户端分配)和FCA(固定客户端分配)。更具体地说,RCA在每一轮通信中将客户端随机分配到组中,FCA使用初始化阶段得出的分组结果。动态分组策略在模型精度和收敛速度上都优于RCA和FCA。特别是在莎士比亚数据集上,由于数据的高度异质性,RCA和FCA很难收敛到目标精度。尽管如此,我们的集团战略仍然保持着更快的收敛速度。
用了t-SNE展示了CIFAR100分成超类后的结果
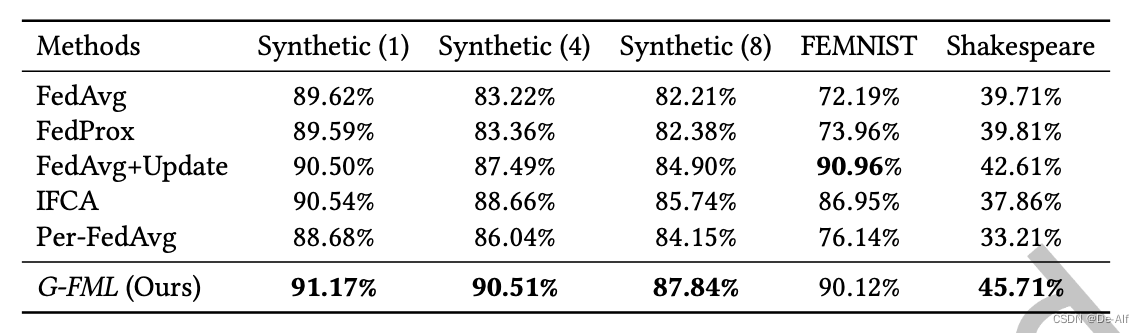
性能比较:为了突出G-FML的经验性能,在三个异构数据集上对G-FML和其他基线进行了比较。所有实验的组数K = 4,相同随机选择客户端、初始模型参数和所有个性化学习率。在所有数据集上,由于非iid数据高度倾斜,per fedag的收敛性比G-FML差。特别是在莎士比亚数据集中,它的收敛速度和模型精度甚至比fedag还要差。G-FML不仅比其他基线性能更稳定,而且在较少的通信轮数下达到了期望的精度。由于非iid数据对模型精度的波动较大,将最大测试精度作为最终模型精度。与per - fedag相比,G-FML在Synthetic中平均准确率提高了3.55%,在FEMNIST中提高了13.98%,在Shakespeare中提高了12.50%。
总结
这篇文章也是一个比较常规的工作。优点是讲解清晰,采用了很多trick展示优点。问题在于:
-
提前预处理阶段,虽然消耗资源不多
-
聚类带来的问题,需要Fine Tune超参数
-
“we use one batch of data at each epoch to train the local model.” (Yang 等, 2023, p. 13)这里问题很大。什么叫每个epoch只用一个batch?元学习算法根本就不只要一个batch的数据,作者淡化了比较过程。并且可以看见没有完成时间的对比,只有rounds

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









