






当图像特征中RGB图像和depth图像特征有鸿沟时,怎么进行融合呢?这里从RGBD SOD显著性检测的领域找了一些最新论文的方法,并附上代码,以供参考。
1、2022 Multi-modal interactive attention and dual progressive decoding network for RGB-D/T salient object detection


三、2021 CDNet: Complementary Depth Network for RGB-D Salient Object Detection

https://github.com/MathLee/HAINet

五、21 RGB-D Salient Object Detection via 3D Convolutional Neural
3D CNN聚合广泛信息的能力。将depth模态作为RGB的另一个“时间状态“,通过3D CNN聚合两种模态的信息,使得在解码器阶段显式融合,且不需要再设计复杂的跨模态融合模块。

六、2015 Siamese Network for RGB-D Salient Object Detection and Beyond

“⊕”利用了特征的互补性,而“⊗”更强调特征的共性 。可视为一种residual attention
七、2020 Learning Selective Mutual Attention and Contrast for RGB-D Saliency Detection
选择性互注意与对比(SMAC)模块(融合了两个模态的互注意力机制和对比机制(前后景对比),还用了选择性注意力自适应调整深度图融合所占的权重)

八、2020 Is Depth Really Necessary for Salient Object Detection?
信道感知融合模块(CAF),它可以自适应地选择鉴别特征来进行对象理解。

九、2020 Feature Reintegration over Differential Treatment: A Top-down and Adaptive Fusion Network for RGB-D Salient Object Detection
提出了两种模块分别针对高层级特征和低层特征的融合
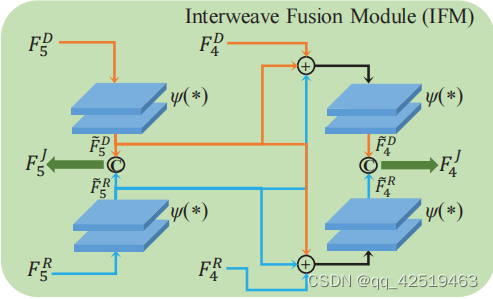
IFM专注于结合来自两种高水平模态的全局信息,而GSFM的目标是通过“在低水平中删除不必要的信息来融合有用的本地信息。
IFM如下图,因为高层特征细节不多,所以不用很复杂:
GSFM(门控选择融合模块)如下图,

并且每一层特征融合时都引入了监督:

十、2020 Depth Quality Aware Salient Object Detection
主要不是特征融合,是怎么得到有贡献的深度特征: 多加一流进行监督学习,学习到深度图中有、但RGB中没有的、对saliency map的贡献。
精髓在于用这样的pGT = {P + B}的损失函数进行监督

十一、2020 Data-Level Recombination and Lightweight Fusion Scheme for RGB-D Salient Object Detection
将原始的四维RGB-D循环转换为DGB、RDB和RGD。















 1791
1791











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









