







一、正则re模块
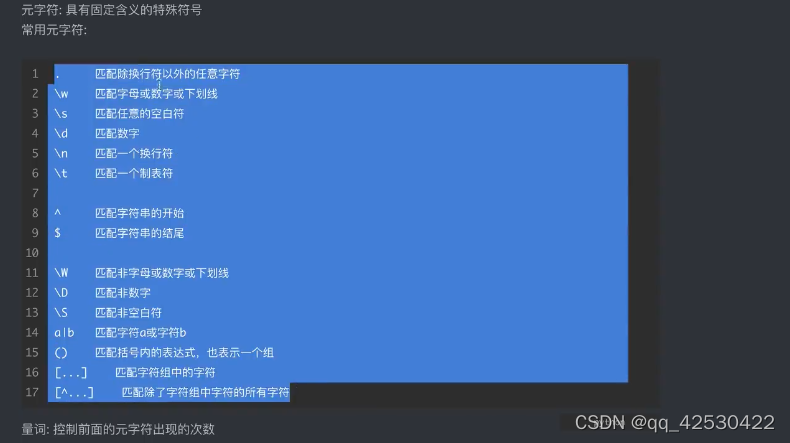
量词
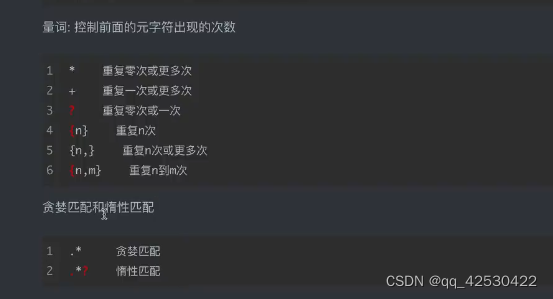
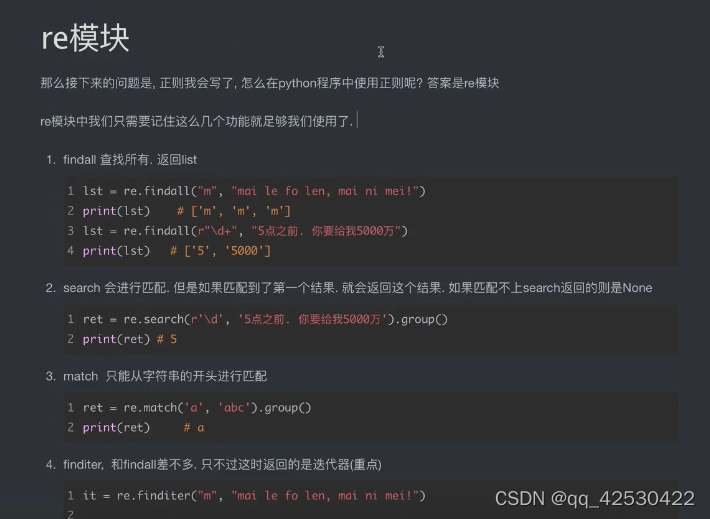
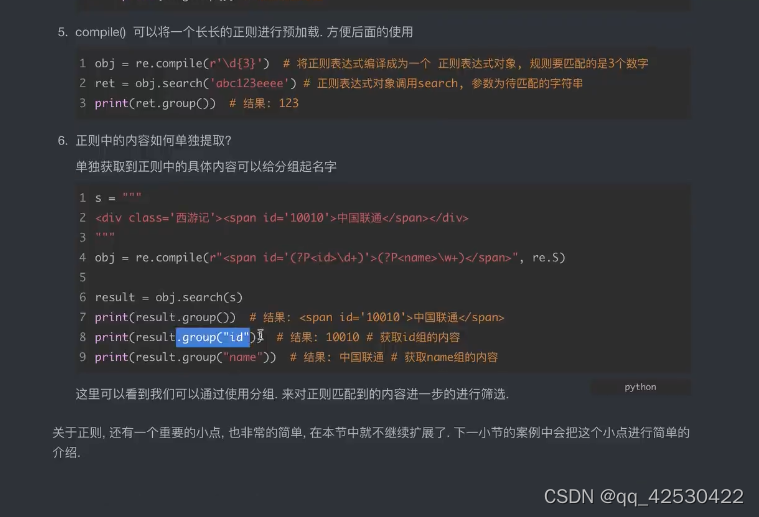
1、使用正则re爬取豆瓣排行榜
数据在源代码中
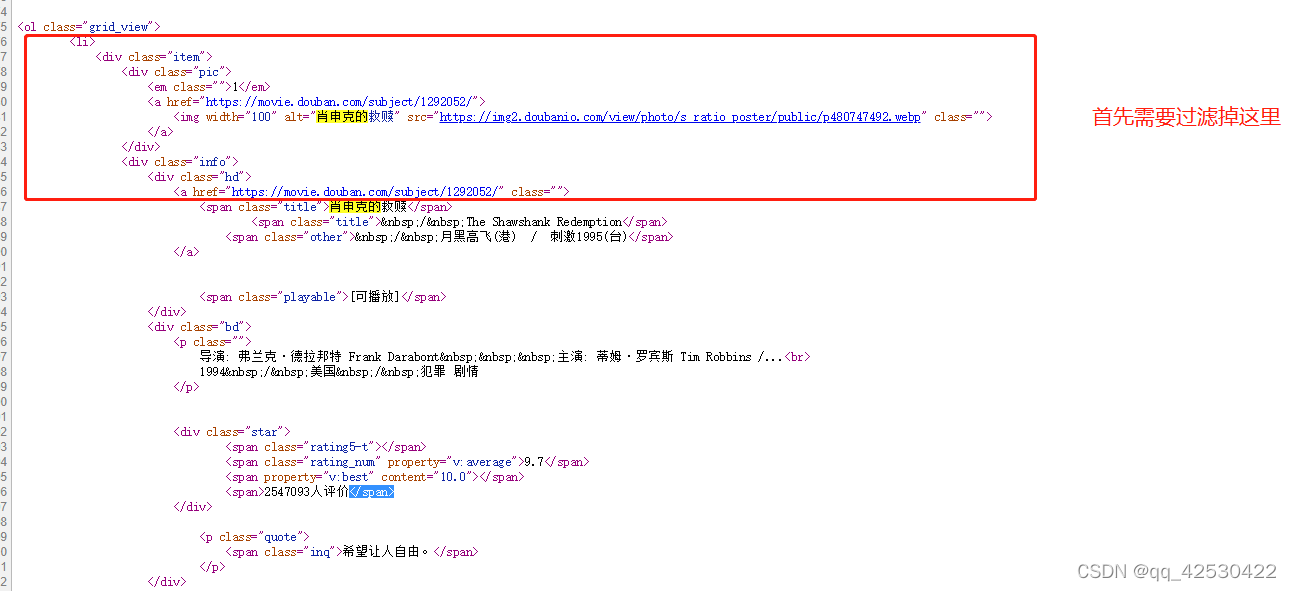
r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>' #获取电影名
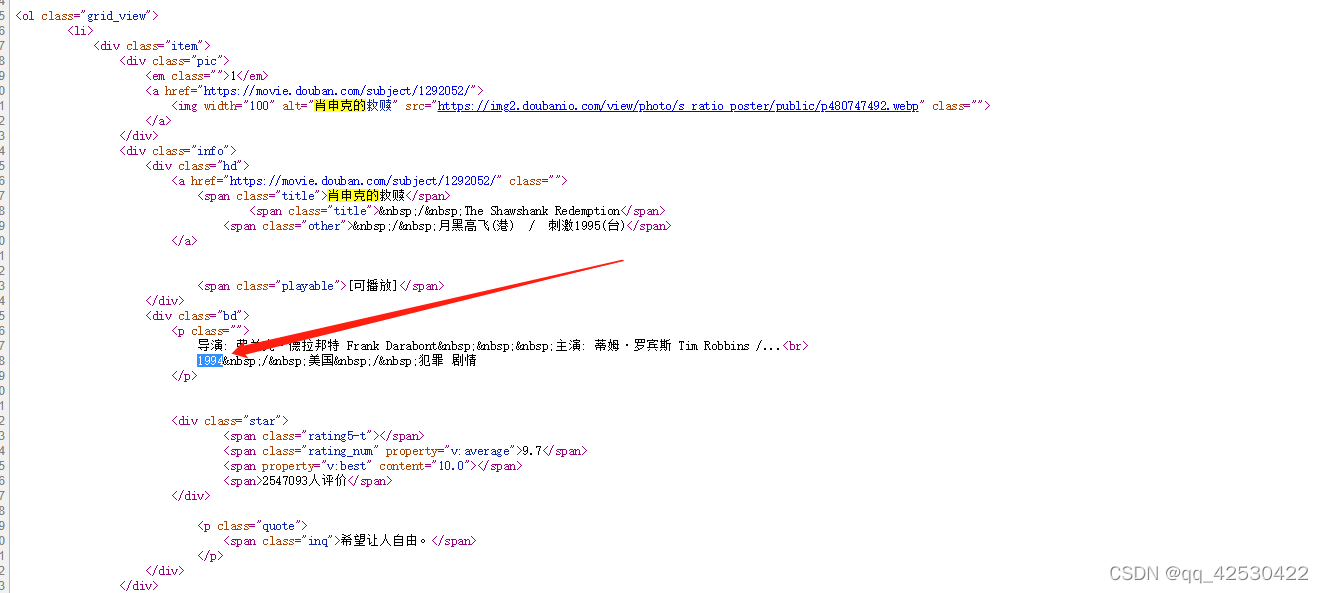
r'.*?<p class="">.*?<br>(?P<year>.*?) ' #获取电影上映年份
代码:
import requests
import re
#存如csv格式
import csv
url = "https://movie.douban.com/top250"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3878.400 QQBrowser/10.8.4518.400"
}
resp = requests.get(url, headers=headers)
page_content = resp.text
#解析数据
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>' #获取电影名
r'.*?<p class="">.*?<br>(?P<year>.*?) ' #获取电影上映年份
r'.*?<span class="rating_num" property="v:average">(?P<score>.*?)</span>' #获取电影评分
r'.*?<span>(?P<num>.*?)人评价</span>', re.S)
#开始匹配
result = obj.finditer(page_content)
f = open("data.csv", mode="w", encoding="utf-8")
csvwriter = csv.writer(f)
#下面这个循环不注释掉,最后面的循环会出错
# for it in result:
# print(it.group("name"))
# print(it.group("year").strip()) #去掉name和year之间的间隔
# print(it.group("score"))
# print(it.group("num"))
for i in result:
dic = i.groupdict()
dic['year'] = dic['year'].strip()
csvwriter.writerow(dic.values())
f.close()
resp.close()
print("Over!")
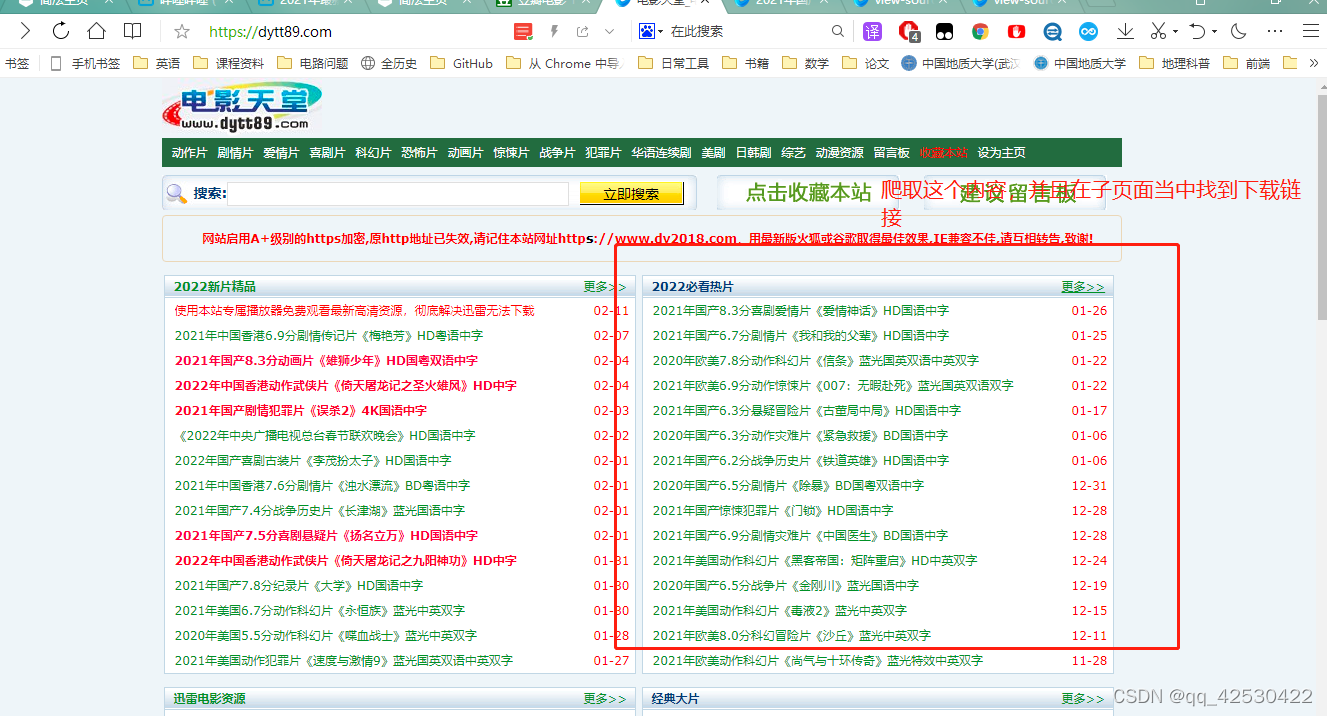
2、屠戮盗版天堂
数据在源代码中
- 定位到2020必看片
- 从2020必看片中提取到子页面的链接地址
- 请求子页面的链接地址,拿到我们想要的下载地址。。。
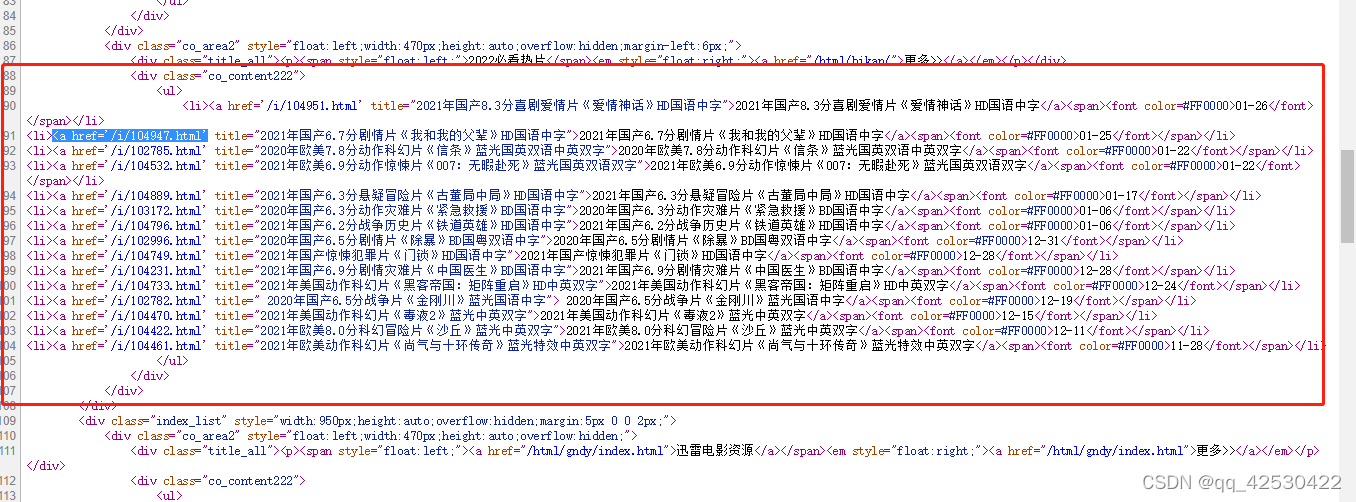
domain = "https://dytt89.com/"
resp = requests.get(domain, verify=False) #verify=False:不做访问页面时的校验
resp.encoding = 'gb2312' #指定字符集
#拿到ul里面的li
obj1 = re.compile(r'2022必看热片.*?<ul>(?P<ul>.*?)</ul>', re.S)
result1 = obj1.finditer(resp.text)
2、找到子页面的地址

obj2 = re.compile(r"<a href='(?P<href>.*?)'", re.S)
child_href_list = [] #创建一个列表
for it in result1:
ul = it.group('ul')
# print(ul)
# 提取子页面链接
result2 = obj2.finditer(ul)
for itt in result2:
# print(itt.group('href'))
#本句是将https://dytt89.com/ + /i/104951.html 将这个链接拼接起来
child_href = domain + itt.group('href').strip("/") #.strip("/")是将链接中多余的一个/去掉
child_href_list.append(child_href) #把子页面保存起来
3、定位到子页面中的下载地址
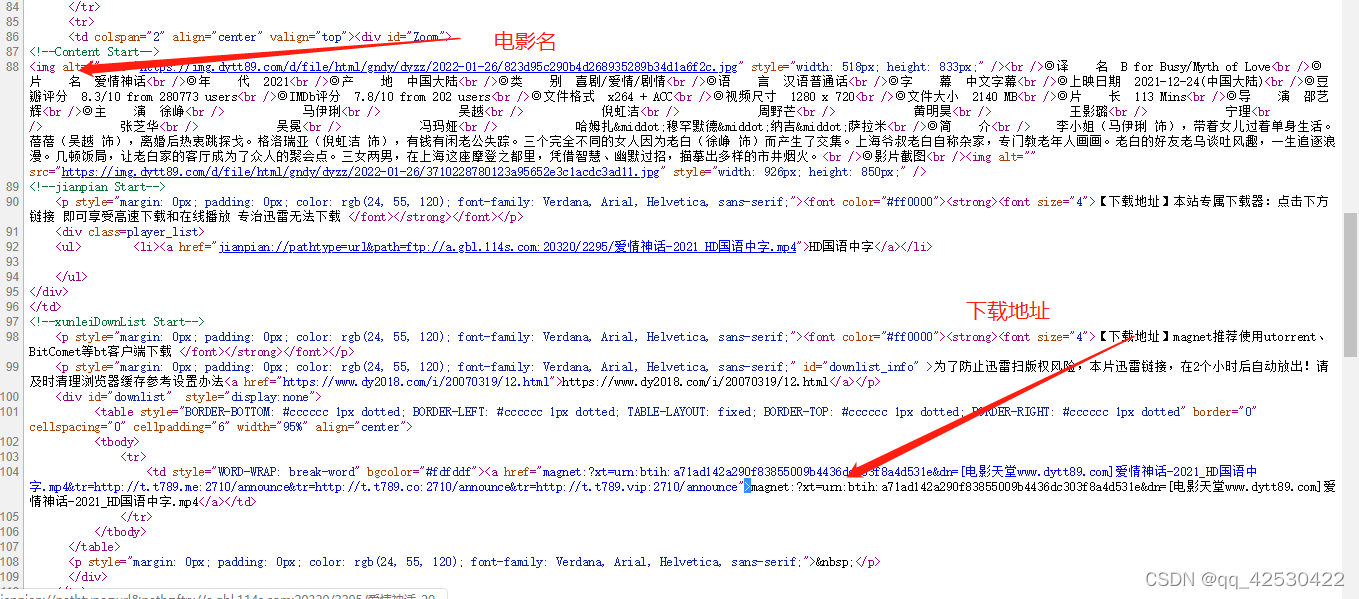
obj3 = re.compile(r'◎片 名(?P<movie>.*?)<br />'
r'.*?<td style="WORD-WRAP: break-word" bgcolor="#fdfddf"><a href="(?P<download>.*?)">', re.S)
for href in child_href_list:
child_resp = requests.get(href, verify=False)
child_resp.encoding = 'gbk'
result3 = obj3.search(child_resp.text)
print(result3.group("movie"))
print(result3.group("download"))
break
代码:
import requests
import re
import time
domain = "https://dytt89.com/"
resp = requests.get(domain, verify=False) #verify=False:不做访问页面时的校验
resp.encoding = 'gb2312' #指定字符集
# print(resp.text)
#拿到ul里面的li
obj1 = re.compile(r'2022必看热片.*?<ul>(?P<ul>.*?)</ul>', re.S)
obj2 = re.compile(r"<a href='(?P<href>.*?)'", re.S)
obj3 = re.compile(r'◎片 名(?P<movie>.*?)<br />'
r'.*?<td style="WORD-WRAP: break-word" bgcolor="#fdfddf"><a href="(?P<download>.*?)">', re.S)
result1 = obj1.finditer(resp.text)
child_href_list = [] #创建一个列表
for it in result1:
ul = it.group('ul')
# print(ul)
# 提取子页面链接
result2 = obj2.finditer(ul)
for itt in result2:
# print(itt.group('href'))
#本句是将https://dytt89.com/ + /i/104951.html 将这个链接拼接起来
child_href = domain + itt.group('href').strip("/") #.strip("/")是将链接中多余的一个/去掉
child_href_list.append(child_href) #把子页面保存起来
#提取子页面内容
for href in child_href_list:
child_resp = requests.get(href, verify=False)
child_resp.encoding = 'gbk'
result3 = obj3.search(child_resp.text)
print(result3.group("movie"))
print(result3.group("download"))
time.sleep(1)
# break
二、bs4模块
1、菜价的整理
数据在源代码中
爬取网站 https://www.construdip.com/marketanalysis/0/list/1.shtml
import requests
from bs4 import BeautifulSoup
import csv
url = "https://www.construdip.com/marketanalysis/0/list/1.shtml"
resp = requests.get(url)
# print(resp.text)
#解析数据
#1、把页面源代码交给BeautifulSoup进行处理,生成bs对象
page = BeautifulSoup(resp.text, "html.parser") #指定html解析器
#2、从bs对象中查找数据
# find(标签,属性=值)
# find_all(标签,属性=值)
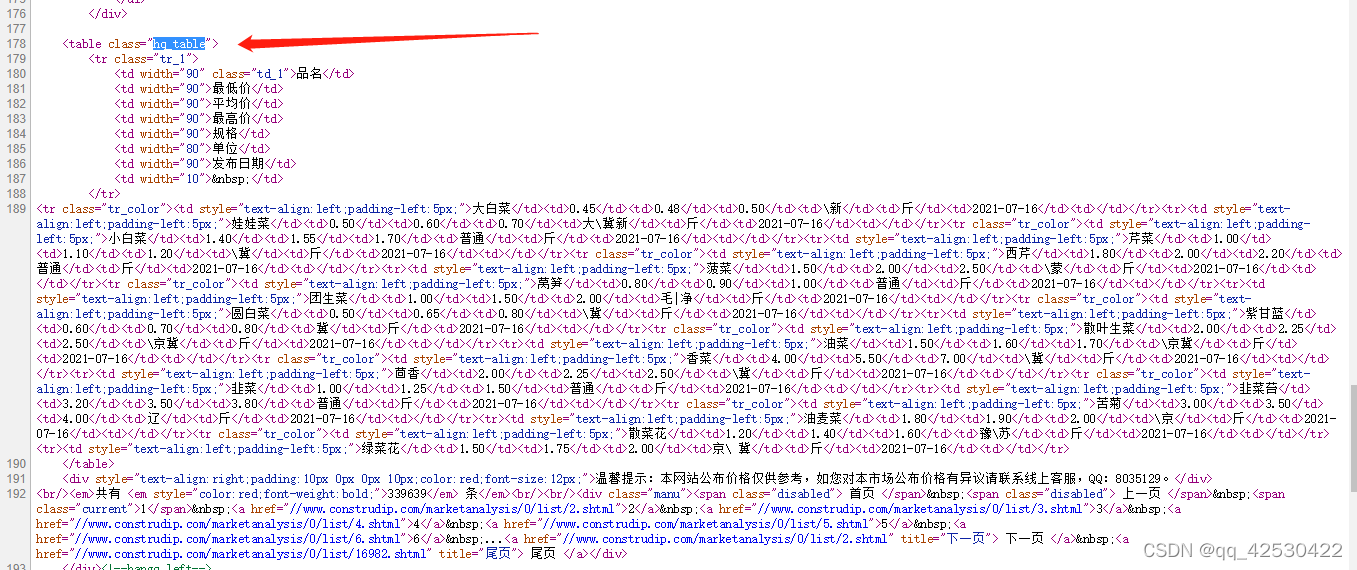
# table = page.find("table", class_="hq_table") #class是python中的关键字
table = page.find("table", attrs={"class": "hq_table"}) #和上面的语句相同,使用字典的形式
# print(table)
#建立一个文件
f = open("菜价.csv", mode="w", encoding="utf-8")
csvwriter = csv.writer(f)
#拿到所有数据行
trs = table.find_all("tr")[1:]
for tr in trs: #每一行
tds = tr.find_all("td") #拿到每一行中的所有td
name = tds[0].text #.text 表示拿到被标签标记的内容
low = tds[1].text
avg = tds[2].text
high = tds[3].text
gui = tds[4].text
kind = tds[5].text
date = tds[6].text
csvwriter.writerow([name, low, avg, high, gui, kind, date])
f.close()
print("Over")
2、美图网站图片下载
图片下载地址在源代码中
对下载地址位置进行缩小,先从主页面依次获得子页面的地址

main_page = BeautifulSoup(resp.text, "html.parser")
alist = main_page.find("div", class_="TypeList").find_all("a") #把范围第一次缩小
在循环中,依次进入子页面,拿到子页面的下载地址,进入后获得图片的下载地址
href = url + a.get('href').strip("bizhitupian/weimeibizhi/")+"htm" #strip()是将有重复的这个内容去掉
定位到图片下载地址

# 拿到子页面的源代码
child_page_resp = requests.get(href)
child_page_resp.encoding = "utf-8"
child_page_text = child_page_resp.text
# 从子页面中拿到图片的x下载路径
child_page = BeautifulSoup(child_page_text, "html.parser")
div = child_page.find("div", class_="ImageBody")
img = div.find("img") #把范围缩小到img的属性中
# print(img.get("src"))
src = img.get("src") #拿到网页中src中的属性
全部代码:
# 1、拿到主页面的源代码,然后提取到子页面的链接地址,href
# 2、通过href拿到子页面的内容,从子页面中找到图片的下载地址 img->src
# 3、下载图片
import requests
from bs4 import BeautifulSoup
import time #防止频繁访问服务器被封号
url = "https://umei.net/bizhitupian/weimeibizhi/"
resp = requests.get(url)
resp.encoding = 'utf-8'
# print(resp.text)
#把源代码交给bs
main_page = BeautifulSoup(resp.text, "html.parser")
alist = main_page.find("div", class_="TypeList").find_all("a") #把范围第一次缩小
# print(alist)
for a in alist:
# print(url + a.get('href').strip("bizhitupian/weimeibizhi/")+"htm") #直接通过get就可以拿到属性的值
href = url + a.get('href').strip("bizhitupian/weimeibizhi/")+"htm"
# print(href)
# 拿到子页面的源代码
child_page_resp = requests.get(href)
child_page_resp.encoding = "utf-8"
child_page_text = child_page_resp.text
# 从子页面中拿到图片的x下载路径
child_page = BeautifulSoup(child_page_text, "html.parser")
div = child_page.find("div", class_="ImageBody")
img = div.find("img") #把范围缩小到img的属性中
# print(img.get("src"))
src = img.get("src") #拿到网页中src中的属性
#下载图片
img_resp =requests.get(src)
img_name = src.split("/")[-1] #拿到url中的最后一个/之后的内容
with open("img/"+ img_name, mode="wb") as f: #加上这个"img/"+ 就开始报错了;必须手动建立一个img文件夹
# with open("img/" + img_name, mode="wb") as f:
f.write(img_resp.content) #图片内容写入文件;img_resp.content 拿到的是图片的字节
print("Over!", img_name)
time.sleep(1)
f.close()
child_page_resp.close()
print("All Over!!")
三、xpath模块
xpath对数据的几种处理方式
from lxml import etree
tree = etree.XML(xml) #表示拿取为xml文件数据
tree = etree.parse("a.html", etree.HTMLParser()) #表示拿取数据为当地文件类型
html = etree.HTML(resp.text) #表示数据为html文件类型
result1 = tree.xpath("/book") # /表示层级关系,第一个/是根节点
result2 = tree.xpath("/book/name/text()") #text()拿文本
result3 = tree.xpath("/book/author//nick/text()") #拿取author中的所有nick;包含div中的nick
print(result3)
result4 = tree.xpath("/book/author/*/nick/text()") #* 任意的节点,通配符
result2 = tree.xpath("/html/body/ol/li/a[@href='dapao']/text()") #[@xxx=xxx] 属性的筛选,关于herf为dapao的标签
1、对周八戒网站数据获取
数据在源代码中

from lxml import etree
import requests
url = "https://beijing.zbj.com/search/f/?type=new&kw=saas"
resp = requests.get(url)
# print(resp.text)
#解析
html = etree.HTML(resp.text)
divs = html.xpath("/html/body/div[6]/div/div/div[2]/div[5]/div[1]/div")
for div in divs:
price = div.xpath("./div/div/a/div[2]/div[1]/span[1]/text()")[0].strip("¥")
title = "saas".join(div.xpath("./div/div/a/div[2]/div[2]/p/text()")) #连接标题,“saas”是搜索的字符串
com_name = div.xpath("./div/div/a/div[1]/p/text()")
# "//*[@id="utopia_widget_76"]/a[1]/div[1]/p/text()"
location = div.xpath("./div/div/a[2]/div[1]/div/span/text()")
print(com_name)















 349
349











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









