









一、实验目的
算符优先分析法就是仿照算术表达式的运算过程而提出的一种自底向上的语法分析方法。其基本思想是:首先规定算符,这里是文法的终结符之间的优先关系,然后根据这种优先关系,通过比较相邻算符的优先次序来确定句型中的“句柄”,然后进行归约。
算符优先分析法的关键:
算符优先分析法的关键就是寻找当前句型中的最左素短语,并归约它。本次实验的主要目的就是要加深对算符优先分析理论和工作过程的理解。
二、实验要求
实现算符优先分析法需要:
(1)判别文法是否为OG文法。
(2)判别文法是否为OPG文法。首先需要计算FIRSTVT集、LASTVT集,并根据优先关系构造算符优先矩阵,然后判别是否是OPG文法。
(3)进行句子分析。依据分析表判断出某句子是否为给定文法的句子。
程序应满足下列要求:
- 输入一个算符优先关系表,则输出算符优先归约的步骤。要求从输入文件(input.txt)和键盘中输入算符优先分析表,把结果输出到结果文件(result.txt)和显示器。
输出格式,如:
步骤 符号栈 优先关系 输入串 移进或归约
0 # < i+i# 移进
1 #i > +i 归约
… ……… ………… …………
2、程序应能判断出某句子是否为该文法的句子。
3、准备多组测试数据存放于input.txt文件中,测试数据中应覆盖是文法的句子和不是文法的句子两种情况,测试结果要求以原数据与结果对照的形式输出并保存在result.txt中,同时要把结果输出到屏幕。
4、对于上面步骤(1)和(2)虽不需要通过程序来实现,但要求和测试数据一起在实验报告中写明。
5.提前准备
① 实验前,先编制好程序,上机时输入并调试程序。
- 准备好多组测试数据(存放于文件input.txt中)。
6、思考题:请说明自底向上优先分析与自顶向下分析思想的区别。
7、写出实验报告
三、实验过程:
- 算法分析:
- 数据结构和函数:
- 使用二维列表priority表示算符之间的优先关系。
- analyse函数执行算符优先分析的主要逻辑,根据算符优先关系表进行移进或规约操作。
- testchar函数将字符映射为相应的索引值。
- remainString函数用于更新剩余输入串。
- 算法步骤:
- 从输入文件中读取文法和测试句子,并初始化符号栈等参数。
- 针对每个测试句子,添加结束符号 "#" 并进行算符优先分析。
- 在分析过程中,根据当前输入符号、符号栈顶元素以及优先关系表决定是移进还是规约操作。
- 输出每一步的符号栈状态、优先关系、输入符号以及移进或规约操作结果。
- 根据分析结果判断句子是否合法,最终输出结果到 "result.txt" 文件。
- 存在问题:
- 算法可能无法处理所有情况,例如某些输入可能导致错误打印而不是友好的错误消息。
- 没有提供足够的错误处理机制来处理各种异常情况。
- 扩展性和可维护性:
- 程序的可扩展性有限,难以轻松修改以适应不同类型的输入语法。
- 缺乏注释和清晰的代码结构,降低了代码的可维护性。
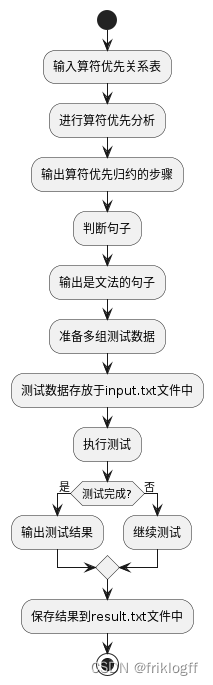
- 程序流程图:
- 程序代码:
priority = [
['>', '<', '<', '<', '>', '>'],
['>', '>', '<', '<', '>', '>'],
['>', '>', '$', '$', '>', '>'],
['<', '<', '<', '<', '=', '$'],
['>', '>', '$', '$', '>', '>'],
['<', '<', '<', '<', '$', '=']
]
def analyse(AnalyseStack):
global k
i = 0
f = len(input)
count = 0
print("\n步骤\t 符号栈\t 优先关系\t 输入串\t 移进或归约")
while i <= f:
a = input[i]
if i == 0:
remainString()
if AnalyseStack[k] in ['+', '*', 'i', '(', ')', '#']:
j = k
else:
j = k - 1
z = testchar(AnalyseStack[j])
if a in ['+', '*', 'i', '(', ')', '#']:
n = testchar(a)
else:
print("错误!该句子不是该文法的合法句子!")
return
p = priority[z][n]
if p == '$':
print("错误!该句子不是该文法的合法句子!")
return
if p == '>':
while True:
Q = AnalyseStack[j]
if AnalyseStack[j - 1] in ['+', '*', 'i', '(', ')', '#']:
j = j - 1
else:
j = j - 2
z1 = testchar(AnalyseStack[j])
n1 = testchar(Q)
p1 = priority[z1][n1]
if p1 == '<':
count += 1
output = f"({count})\t {AnalyseStack}\t {p}\t {a}\t {' ' * 17}{rem}\t 约归"
print(output)
result_file.write(output + "\n")
k = j + 1
i -= 1
AnalyseStack[k] = 'N'
AnalyseStack = AnalyseStack[:k + 1]
break
else:
continue
else:
if p == '<':
count += 1
output = f"({count})\t {AnalyseStack}\t {p}\t {a}\t {' ' * 17}{rem}\t 移进"
print(output)
result_file.write(output + "\n")
k += 1
AnalyseStack.append(a)
remainString()
elif p == '=':
z2 = testchar(AnalyseStack[j])
n2 = testchar('#')
p2 = priority[z2][n2]
if p2 == '=':
count += 1
output = f"({count})\t {AnalyseStack}\t {p}\t {a}\t {' ' * 17}{rem}\t 接受"
print(output)
result_file.write(output + "\n")
result_file.write("该句子是该文法的合法句子。\n")
break
else:
count += 1
output = f"({count})\t {AnalyseStack}\t {p}\t {a}\t {' ' * 17}{rem}\t 移进"
print(output)
result_file.write(output + "\n")
k += 1
AnalyseStack.append(a)
remainString()
else:
print("错误!该句子不是该文法的合法句子!")
return
i += 1
def testchar(x):
if x == '+':
return 0
elif x == '*':
return 1
elif x == 'i':
return 2
elif x == '(':
return 3
elif x == ')':
return 4
elif x == '#':
return 5
else:
return -1
def remainString():
global rem
rem = rem[1:]
# Read input from file
with open("input.txt", "r") as file:
input_lines = file.readlines()
result_file = open("result.txt", "w")
result_file.write("文法为:\n")
result_file.write("(0)E'->#E#\n")
result_file.write("(1)E->E+T\n")
result_file.write("(2)E->T\n")
result_file.write("(3)T->T*F\n")
result_file.write("(4)T->F\n")
result_file.write("(5)F->(E)\n")
result_file.write("(6)F->i\n")
result_file.write("-----------------------------------------\n")
result_file.write(" 算符优先关系表 \n")
result_file.write(" + * i ( ) # \n")
result_file.write(" + > < < < > > \n")
result_file.write(" * > > < < > > \n")
result_file.write(" i > > > > \n")
result_file.write(" ( < < < < = \n")
result_file.write(" ) > > > > \n")
result_file.write(" # < < < < = \n")
result_file.write("-----------------------------------------\n")
for input_str in input_lines:
input_str = input_str.strip()
if input_str:
input_str += '#'
input = list(input_str)
k = 0
AnalyseStack = ['#']
rem = input[1:]
analyse(AnalyseStack)
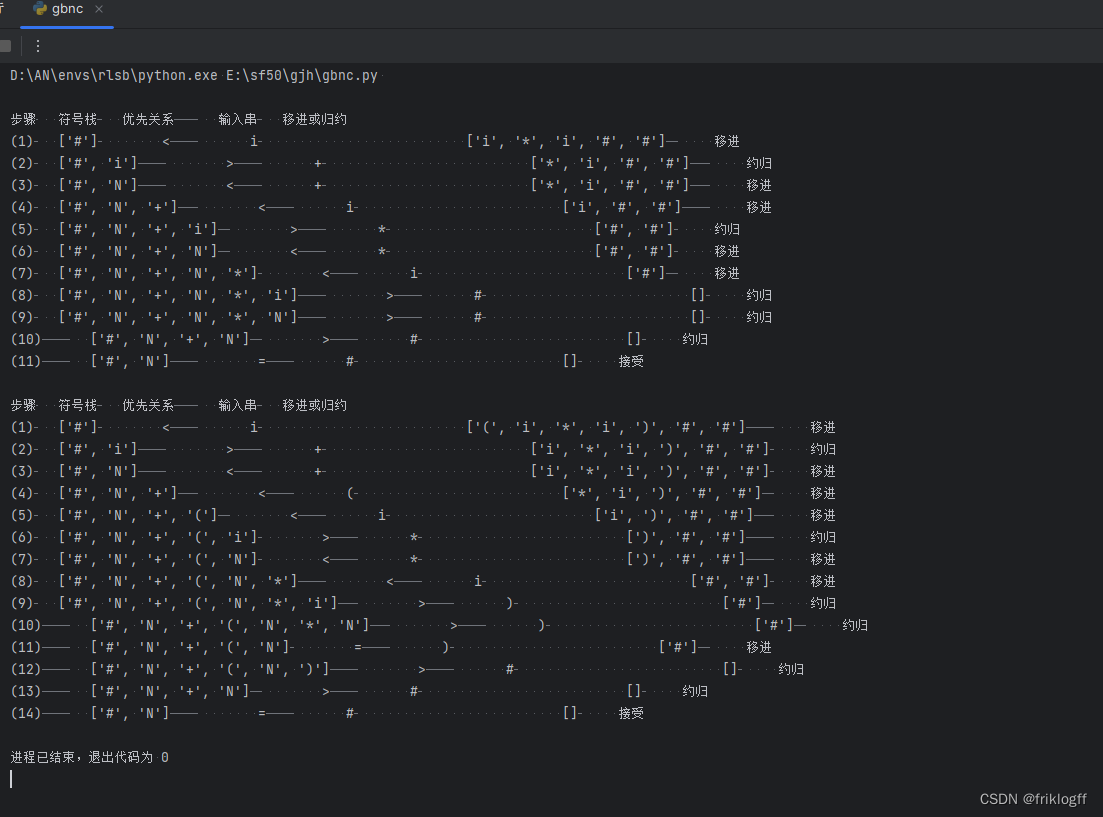
result_file.close()- 程序运行结果截图:
四、思考题:
6、思考题:请说明自底向上优先分析与自顶向下分析思想的区别。
自底向上优先分析:
从输入串底部开始,逐步推导出文法的起始符号。
采用移入-规约或规约-规约操作来构建句子的语法树。
利用算符优先关系表进行移进或归约操作。
对于较复杂的文法和推导关系自底向上方法通常更灵活且能够处理更广泛的文法。
示例算法:LR(0)、SLR、LR(1)等。
自顶向下分析:
从文法的起始符号开始,递归地向下展开,尝试生成输入串。
通过匹配产生式右侧的符号和输入串来构建句子。
自顶向下方法通常使用LL(1)分析器或递归下降分析器实现。
受限于左递归、回溯等问题,可能需要针对特定文法进行修改。
示例算法:LL(1)、LL(k)分析器等。
区别:
方向:自底向上方法是从输入串底部向上推导;自顶向下方法则是从文法的起始符号向下展开。
操作顺序:自底向上方法通过移进或归约操作构建语法树;自顶向下方法通过递归展开生成句子。
适用范围:自底向上方法更灵活,适用于更广泛的文法;自顶向下方法对文法要求更严格,可能需要特定调整以应对左递归等问题。
分析器类型:自底向上方法常用LR分析器实现;自顶向下方法常使用LL分析器实现。
五、实验小结:
通过本次实验,我加深了对算符优先分析算法的理解,学会了如何利用优先关系表来分析句子。
自底向上分析相对自顶向下更具灵活性,可处理更广泛的文法但实现相对复杂。
熟练掌握这些知识将有助于理解不同类型的分析器设计和语法分析的应用场景。



















 1430
1430

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











