






我将在本文介绍如何通过 unsloth 框架以 LoRA 的方法微调 Qwen3-14B 模型。

到目前还有很多小伙伴还不明白什么时候应该微调?那么请看下图:

接下来我们再看一下本文使用的 LoRA 微调方法的优势:

LoRA(Low-Rank Adaptation of Large Language Models,大型语言模型的低秩自适应)是一种流行的轻量级训练技术,可以显著减少可训练参数的数量。它的工作原理是将少量的新权重插入模型中,并且只训练这些权重。这使得使用 LoRA 进行训练的速度更快、内存效率更高,并且生成的模型权重更小(只有几百 MB),更易于存储和共享。LoRA 还可以与 DreamBooth 等其他训练技术结合使用,以加速训练。
我们将在本文介绍如何微调使模型成为一个"双重人格"的助手,既能进行普通闲聊,又能在需要时切换到更严谨的思考模式来解决复杂问题,特别是数学问题。简而言之,微调后的模型获得的能力:
- 双模式操作能力:
- 普通对话模式: 适用于日常聊天场景。
- 思考模式( Thinking Mode ): 用于解决需要推理的问题。
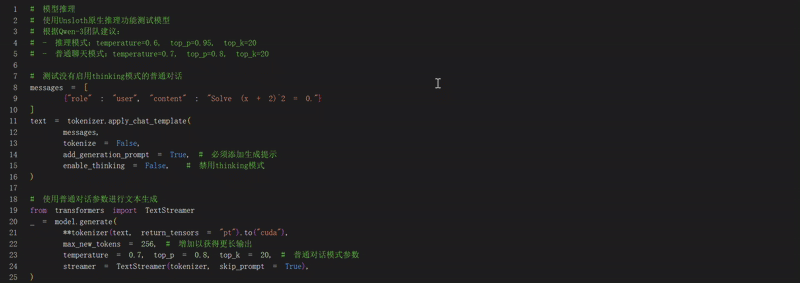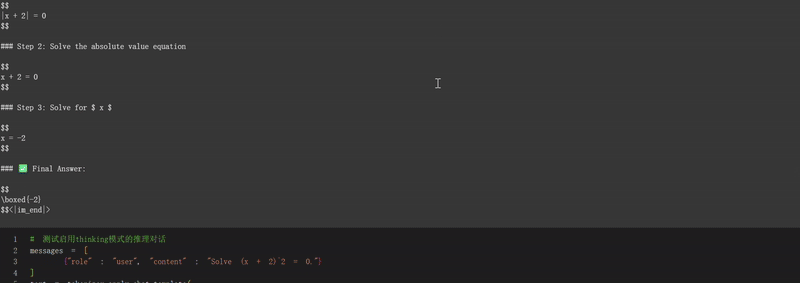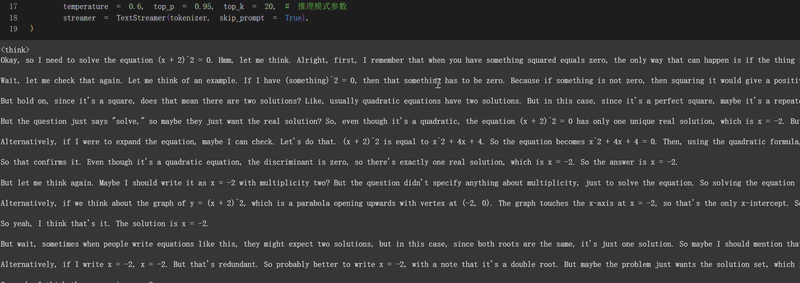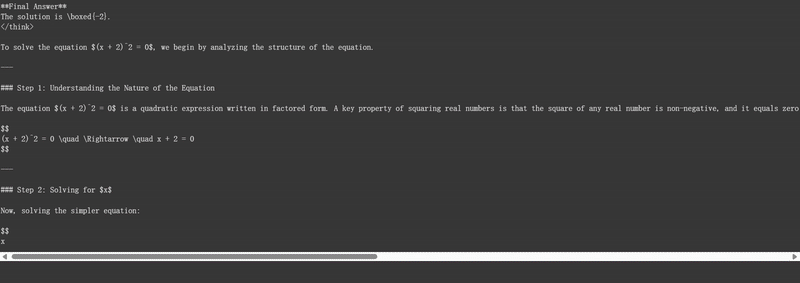
- 数学推理能力: 能够解决数学问题并展示详细的推理过程,如示例中的"解方程(x + 2)^2 = 0"。
- 对话能力保持: 同时保持了自然对话的能力,能够进行流畅的多轮对话。
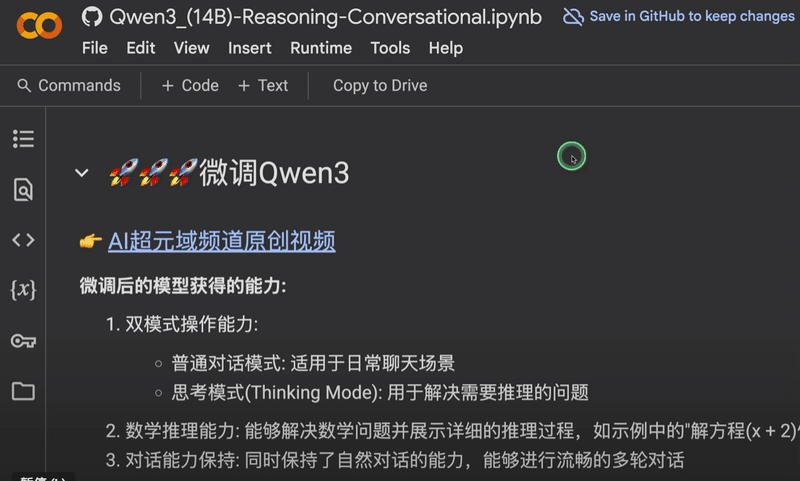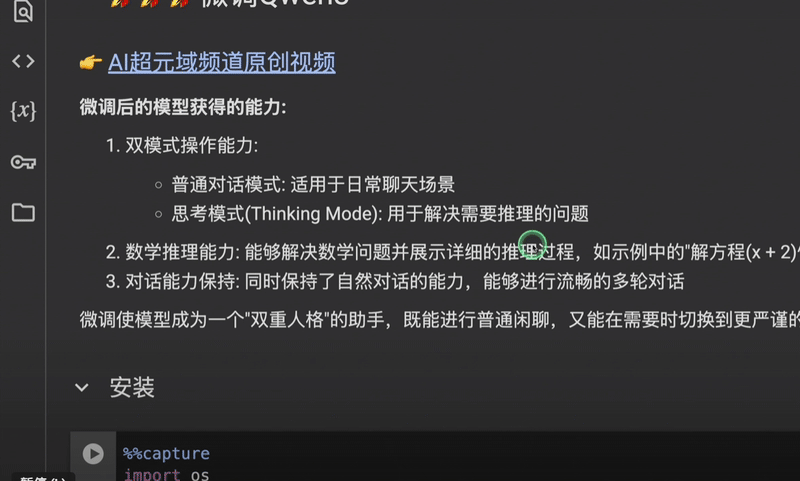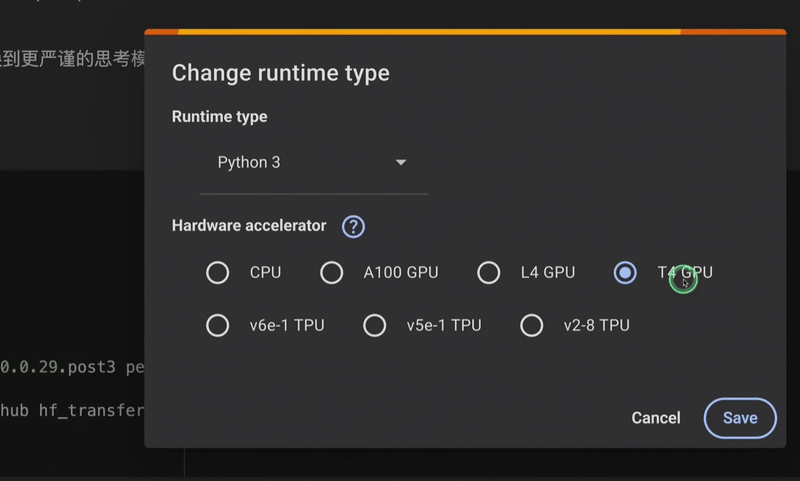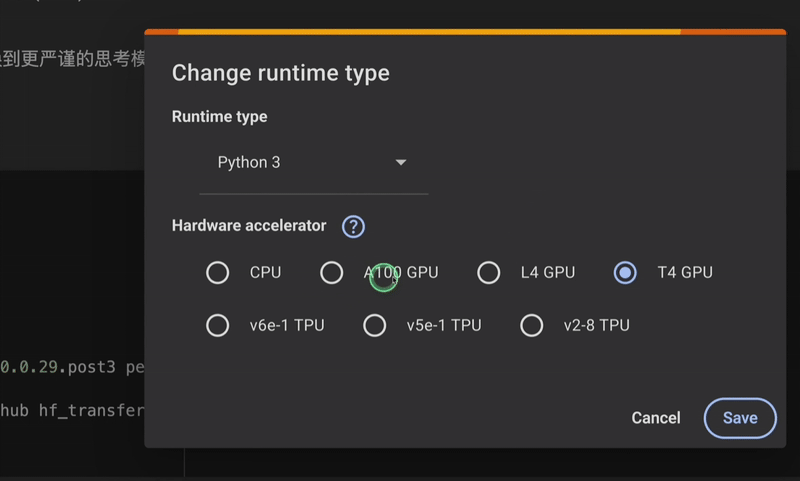
首先我们在谷歌 Colab 上选择算力,推荐使用 T4 GPU 或者 A100 GPU:
现在我们可以加载 14 B模型:
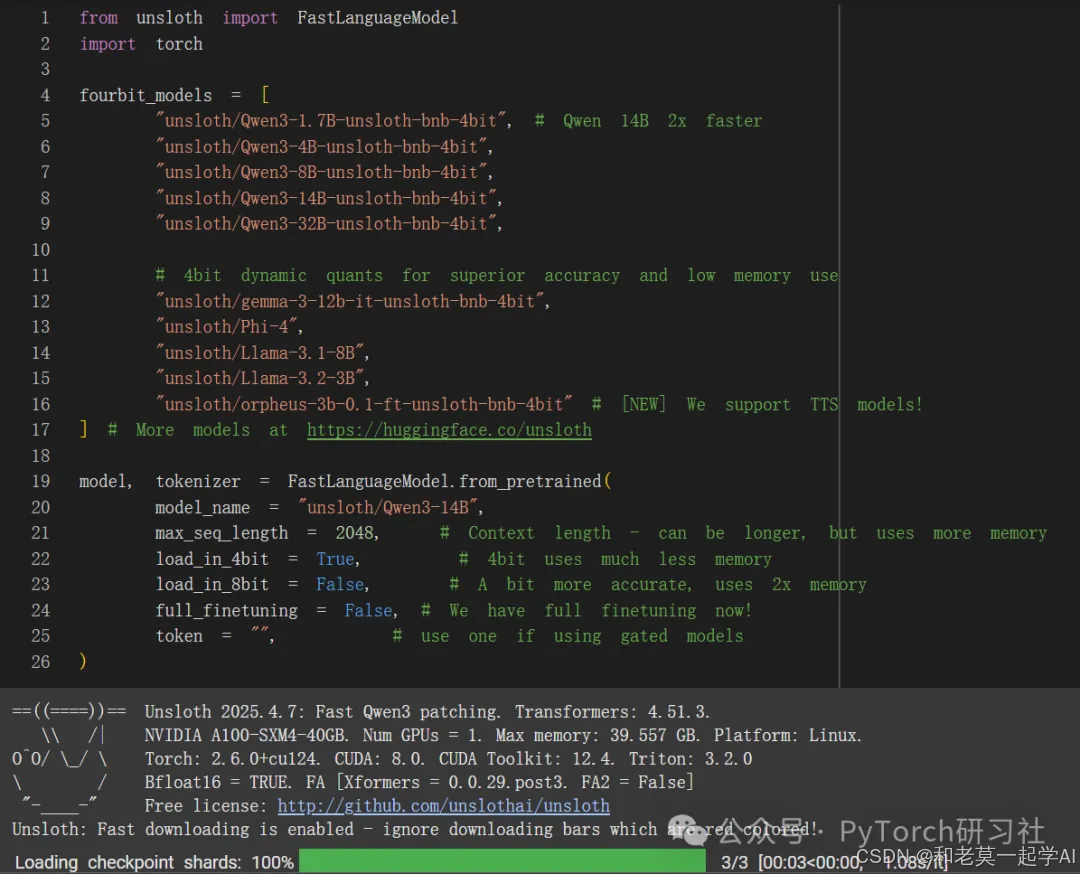
我们现在添加 LoRA 适配器,因此我们只需要更新 1% 到 10% 的参数!

准备数据
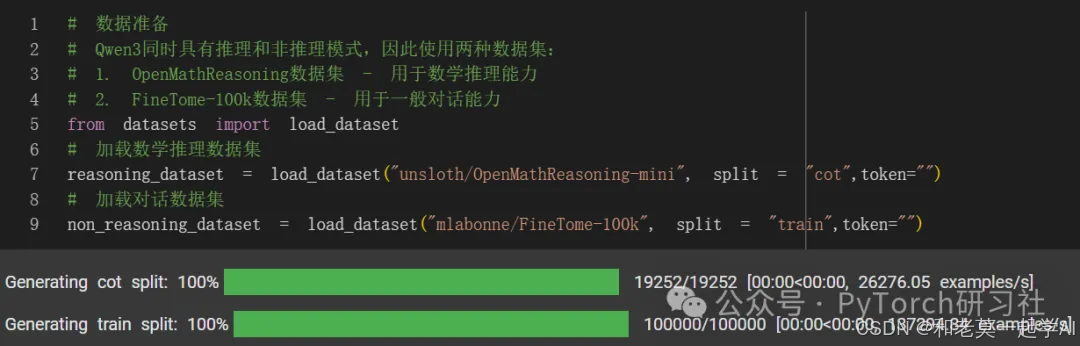
Qwen3 既有推理模式,也有非推理模式。因此,我们应该使用两个数据集:
- Open Math Reasoning 数据集,该数据集曾用于赢得 AIMO(AI Mathematical Olympiad,AI 数学奥林匹克 - 进步奖 2)挑战赛!我们从使用 DeepSeek R1 的可验证推理轨迹中抽取了 10%,其准确率超过 95%。
- 我们还利用了 Maxime Labonne 的 FineTome-100k 数据集(ShareGPT 格式)。但我们还需要将其转换为 HuggingFace 的常规多轮对话格式。
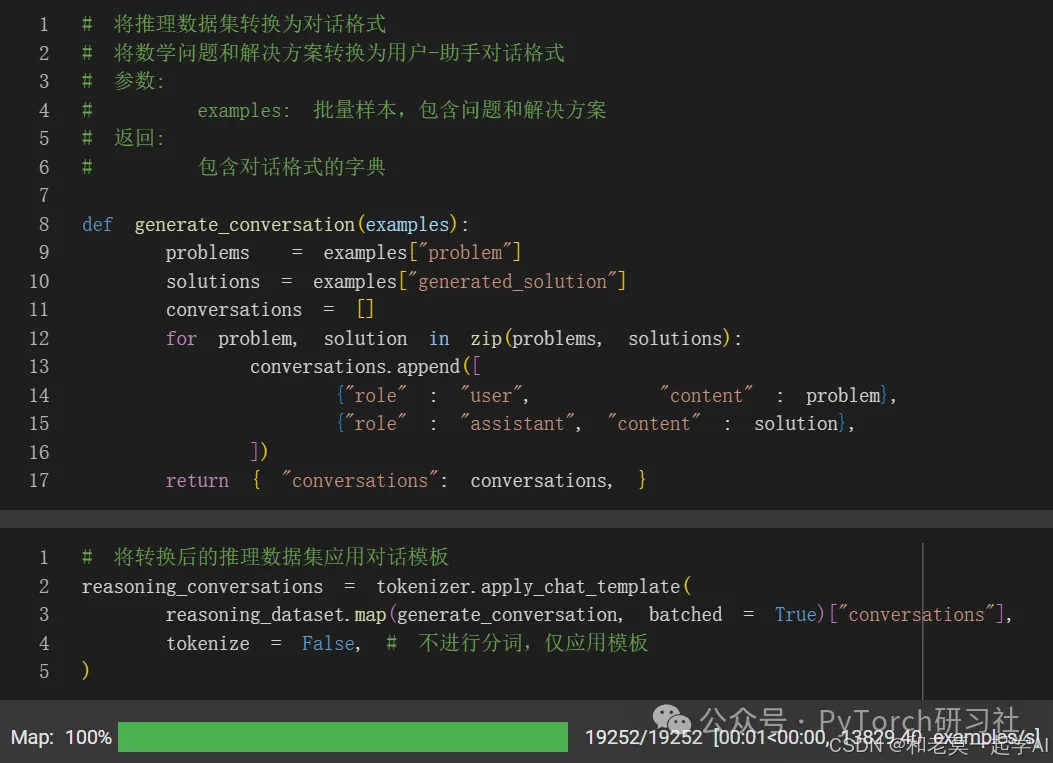
我们现在将推理数据集转换为对话格式:
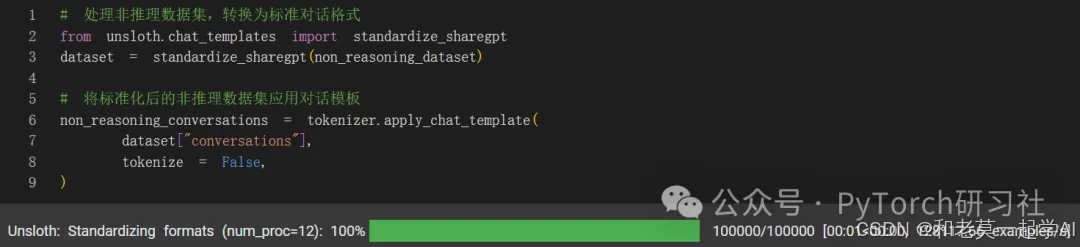
接下来,我们将非推理数据集也转换为对话格式。
首先,我们必须使用 Unsloth 的 standardize_sharegpt 函数来修复数据集的格式。

非推理数据集要长得多。假设我们希望模型保留一些推理能力,但我们特别想要一个聊天模型。
让我们定义一个纯聊天数据的比例。目标是定义两种数据集的某种混合。让我们选择 25% 的推理数据和 75% 的聊天数据:
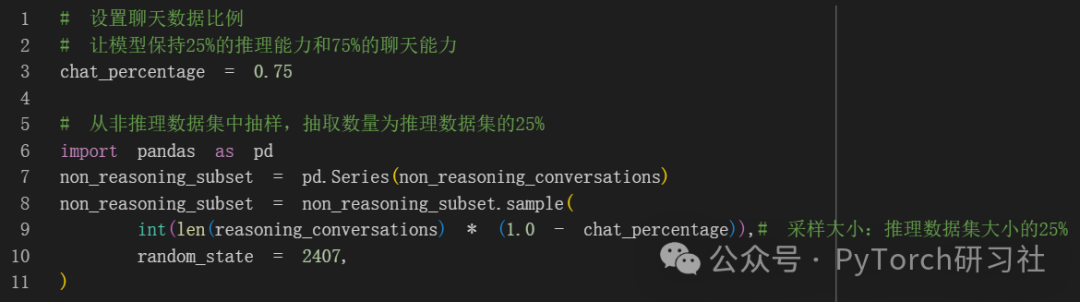
最后合并数据集:
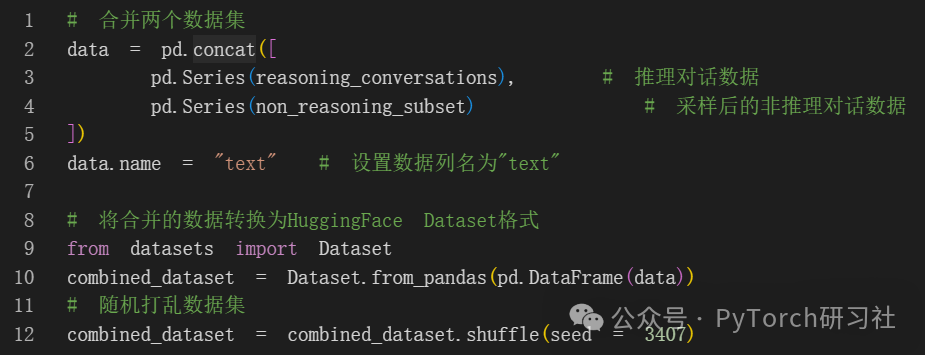

训练模型
现在让我们使用 Huggingface TRL 的 SFTTrainer!我们执行 60 步来加快速度,但你可以设置 num_train_epochs=1 进行完整运行,并关闭 max_steps=None。
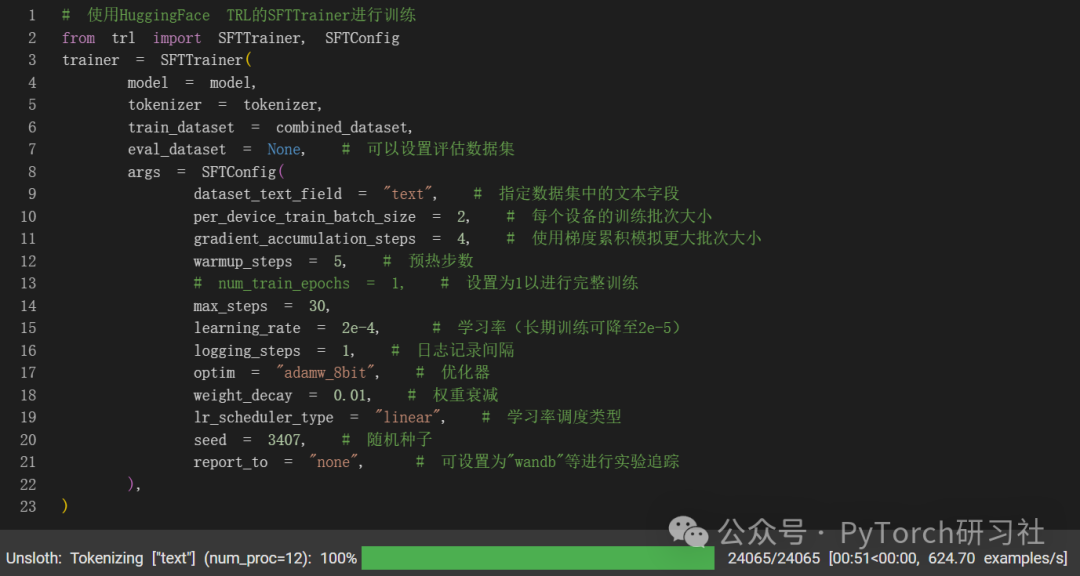
让我们开始训练模型吧!要恢复训练,请设置 trainer.train(resume_from_checkpoint = True)
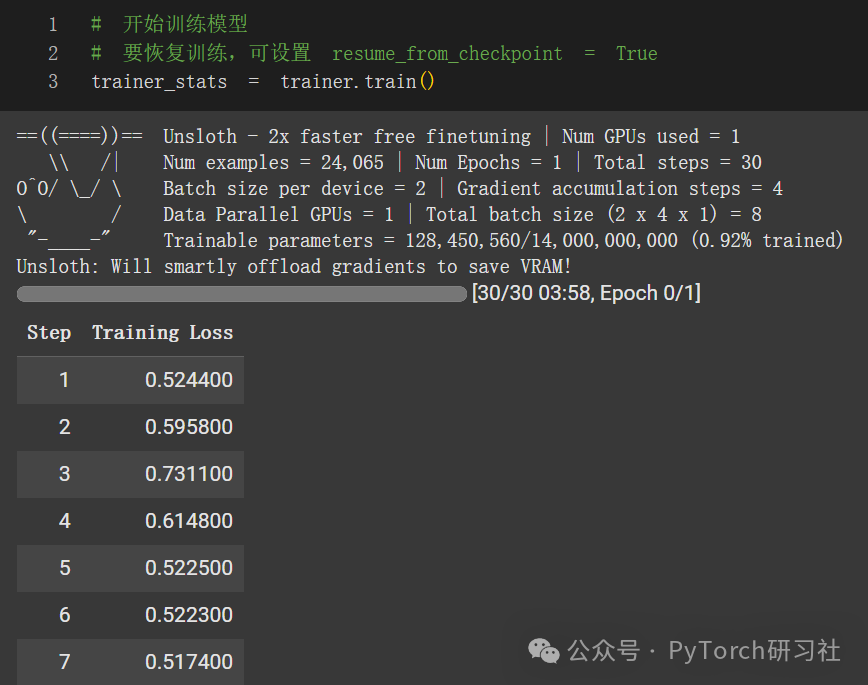
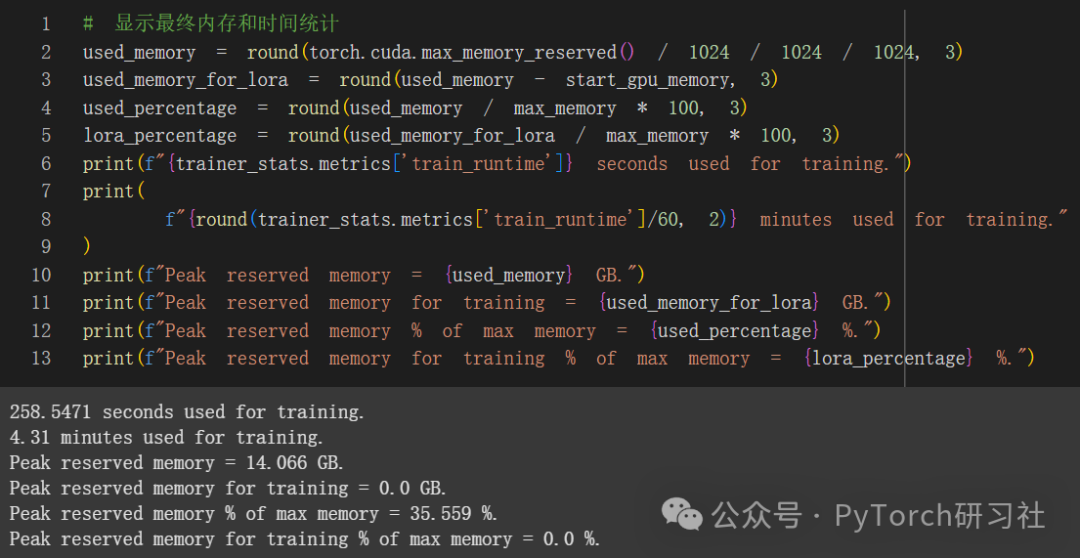
推理
让我们通过 Unsloth 原生推理来运行模型!根据 Qwen-3 团队的说法,
- 推理的推荐设置是:temperature = 0.6、top_p = 0.95、top_k = 20。
- 对于基于普通聊天的推理,temperature = 0.7、top_p = 0.8、top_k = 20。
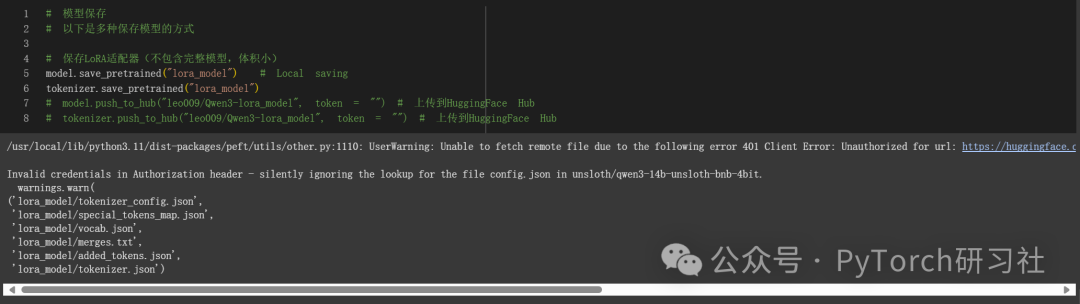
保存、加载微调模型
要将最终模型保存为 LoRA 适配器,请使用 Huggingface 的 push_to_hub 进行在线保存,或使用 save_pretrained 进行本地保存。
[注意] 这仅保存 LoRA 适配器,而不是完整模型。后面我来介绍如何保存为 16 位或 GGUF 格式。
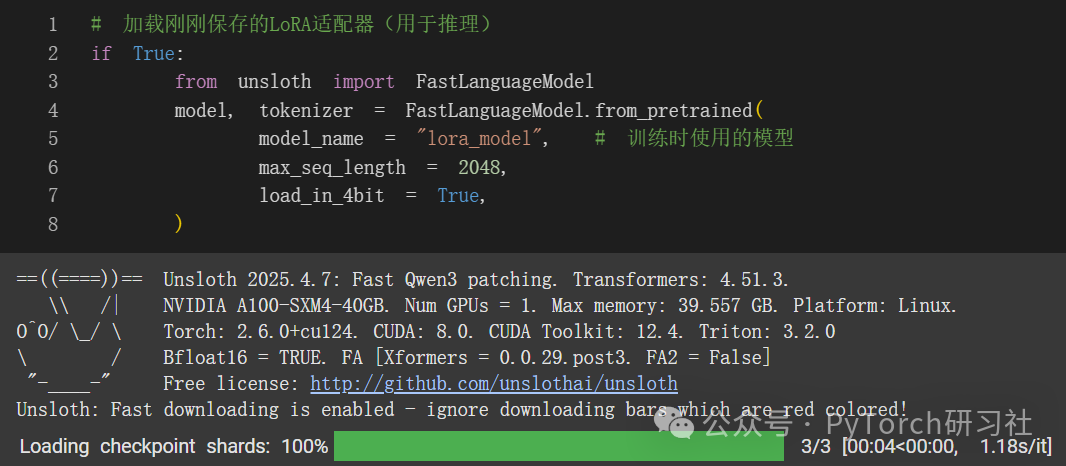
现在,如果你想加载我们刚刚保存用于推理的 LoRA 适配器,请将 False 设置为 True:
保存为 VLLM 的 float16
选择 merged_16bit 保存 float16,或选择 merged_4bit 保存 int4。使用 push_to_hub_merged 上传到你个人的 Hugging Face 账户!
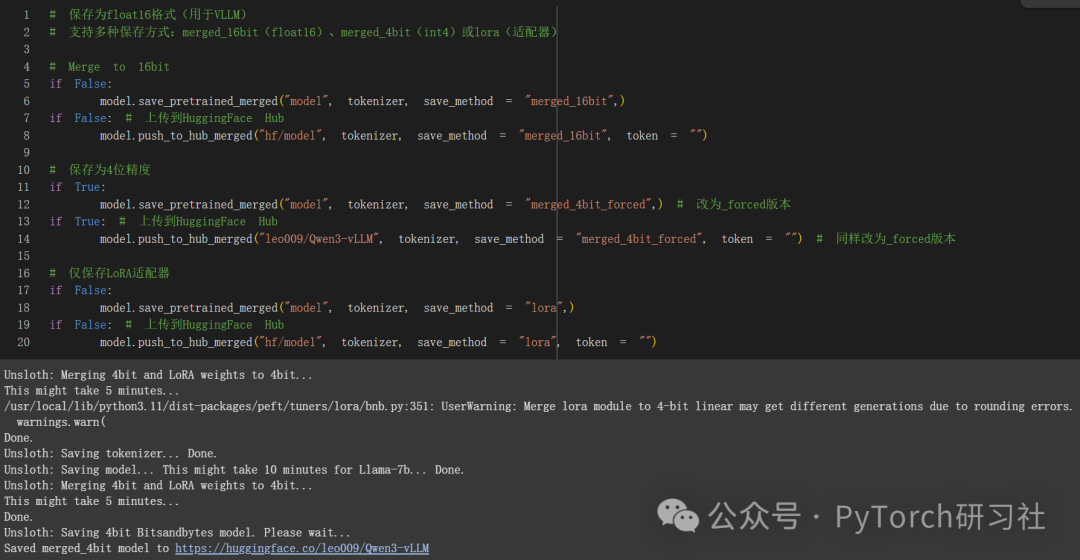
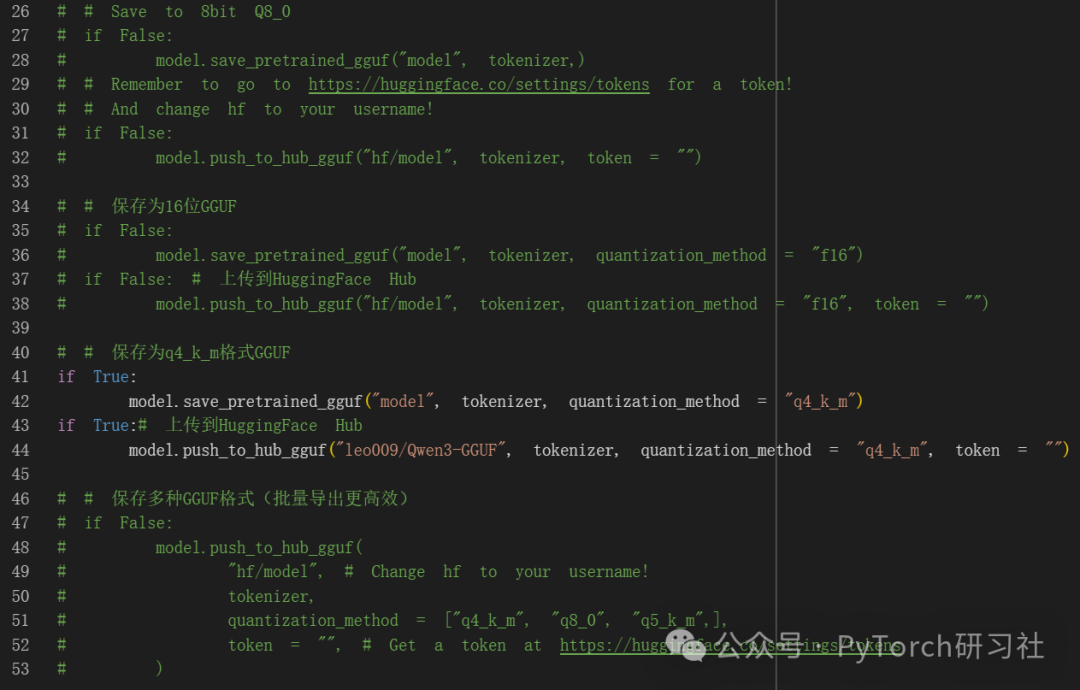
GGUF / llama.cpp 转换
使用 save_pretrained_gguf 进行本地保存,使用 push_to_hub_gguf 上传到 HF。
- q8_0 - 快速转换。资源占用较高,但通常可以接受。
- q4_k_m - 推荐。使用 Q6_K 处理 attention.wv 和 feed_forward.w2 张量的一半,否则使用 Q4_K。
- q5_k_m - 推荐。使用 Q6_K 处理 attention.wv 和 feed_forward.w2 张量的一半,否则使用 Q5_K。
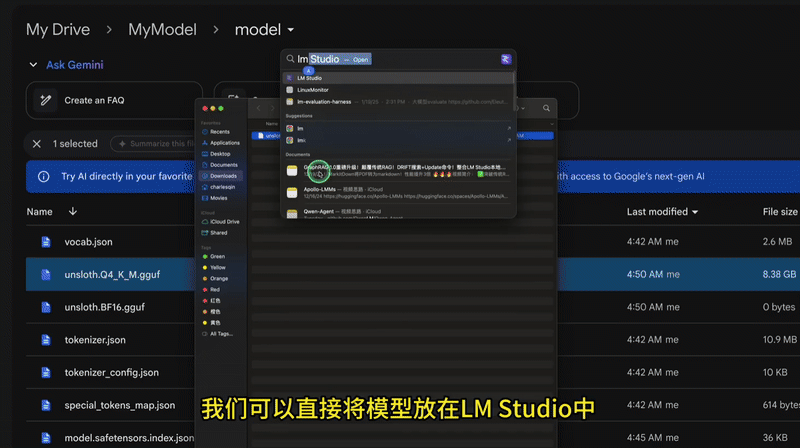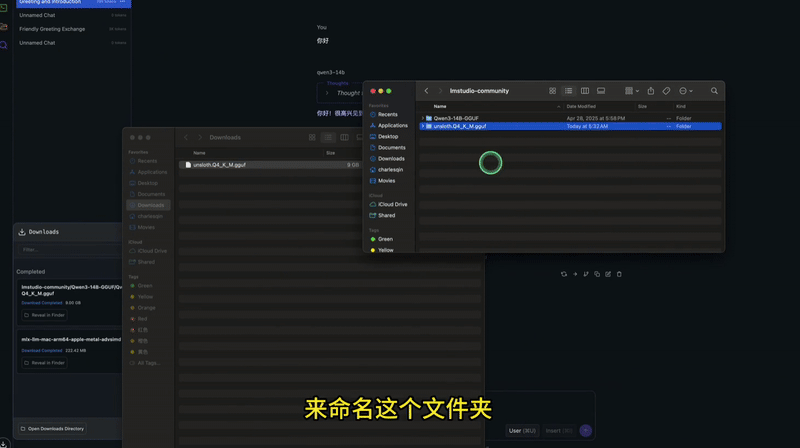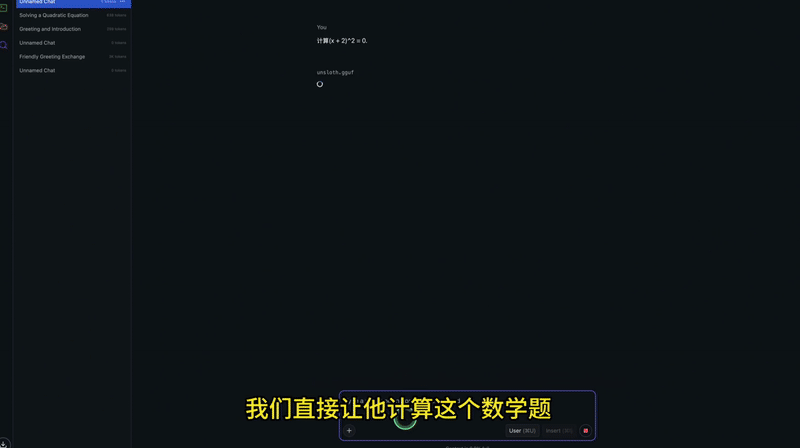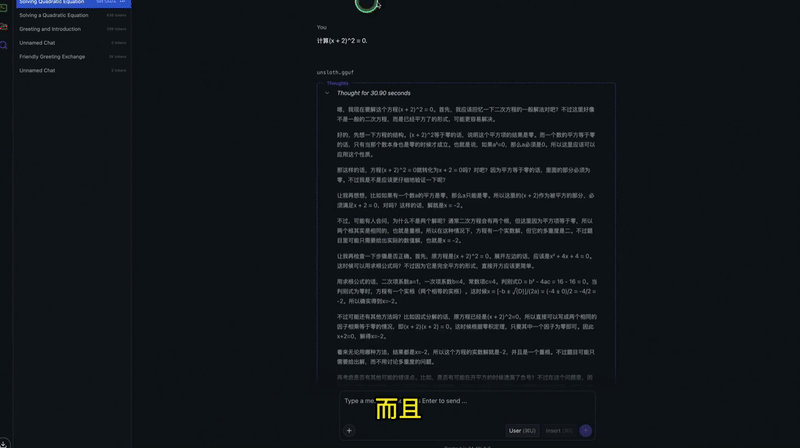
本地部署
接下来就是将 GGUF 文件下载到本地,以便本地部署运行。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
如果你真的想学习大模型,请不要去网上找那些零零碎碎的教程,真的很难学懂!你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!
大模型全套学习资料领取
这里我整理了一份AI大模型入门到进阶全套学习包,包含学习路线+实战案例+视频+书籍PDF+面试题+DeepSeek部署包和技巧,需要的小伙伴文在下方免费领取哦,真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段


二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。



三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。



四、LLM面试题


五、AI产品经理面试题

六、deepseek部署包+技巧大全

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









