







xpath
1、xpath安装
安装lxml库
pip install lxml -i pip源
2、解析流程、使用
解析流程
- 实例化一个etree的对象,把即将被解析的页面源码加载到该对象。
- 调用该对象的xpath方法结合着不同形式的xpath表达进行标签定位和数据提取。
使用
from lxml import etree # 导包
# 解析本地文件第一种方式
parser = etree.HTMLParser(encoding='UTF-8')
tree = etree.parse('./xxx.html', parser=parser)
# 解析本地文件或者网络动态HTML
f = open('./xxx.html', 'r', encoding='UTF-8')
data = f.read()
tree = etree.HTML(data)
print(tree)
# 整合 推荐使用HTML方式
tree = etree.HTML(open('./xxx.html', 'r', encoding='UTF-8').read())
print(tree)
3、xpath语法
XPath 是一门在 XML 文档中查找信息的语言。XPath 用于在 XML 文档中通过元素和属性进行导航。
-
3.1 路径表达式
表达式 描述 / 从根节点选取。 // 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 ./ 当前节点再次进行xpath @ 选取属性。 在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:
路径表达式 结果 /html 选取根元素 bookstore。注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! //li 选取所有li 子元素,而不管它们在文档中的位置。 //ul//a 选择属于 ul元素的后代的所有 li元素,而不管它们位于 ul之下的什么位置。 节点对象.xpath(‘./div’) 选择当前节点对象里面的第一个div节点 //@href 选取名为 href 的所有属性。 下面以 w3school 网址进行举例, 定位以下图片位置。

from lxml import etree # 导包
# 这里由于已经把代码进行复制,所以使用了静态的网页内容。
tree = etree.HTML(open('demo.html', 'r', encoding='utf-8').read())
# 获取需要读取的内容信息
All_Properties = etree.tostring(tree, encoding='utf-8').decode('utf-8')
# 表达式:/ 从根节点选取
a = tree.xpath('/html/body/div/div/a')
a_ = etree.tostring(a[0], encoding='utf-8').decode('utf-8')
print(a_)
# 表达式:// 从当前节点选取
b = tree.xpath('//div/a')
b_ = etree.tostring(b[0], encoding='utf-8').decode('utf-8')
print(b_)
# 表达式:./ 当前节点再次进行xpath
c = tree.xpath('//div/a')
print(c[0].xpath('./text()')) # ['w3school 在线教程']
# 表达式:@ 选择属性
d = tree.xpath('//*[@id="logo"]')
d_ = etree.tostring(d[0], encoding='utf-8').decode('utf-8')
print(d_)

-
3.2 谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
实例
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
路径表达式 结果 /ul/li[1] 选取属于 ul子元素的第一个 li元素。 /ul/li[last()] 选取属于 ul子元素的最后一个 li元素。 /ul/li[last()-1] 选取属于 ul子元素的倒数第二个 li元素。 //ul/li[position() < 3] 选取最前面的两个属于 ul元素的子元素的 li元素。 //a[@title] 选取所有拥有名为 title的属性的 a元素。 //a[@title=‘xx’] 选取所有 a元素,且这些元素拥有值为 xx的 title属性。 //a[@title>10] > < >= <= !=选取 a元素的所有 title元素,且其中的 title元素的值须大于 10。 /bookstore/book[price>35.00]/title 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。
from lxml import etree # 导包
tree = etree.HTML(open('demo.html', 'r', encoding='utf-8').read()) # 获取需要读取的内容信息
# print(tree) # 获取数据信息
All_Properties = etree.tostring(tree, encoding='utf-8').decode('utf-8')
# 获取第一个li
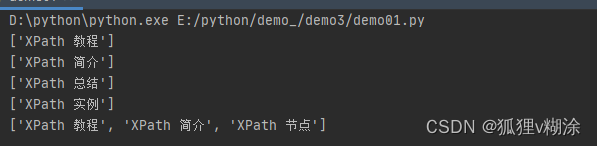
a = tree.xpath("//*[@id ='course']/ul[1]/li[1]//text()")
print(a)
# 获取第二个li
b = tree.xpath("//*[@id ='course']/ul[1]/li[2]//text()")
print(b)
# 获取最后一个li
c = tree.xpath("//*[@id ='course']/ul[1]//li[last()]//text()")
print(c)
# 获取倒数第二个li
d = tree.xpath("//*[@id ='course']/ul[1]//li[last()-1]//text()")
print(d)
# 获取前3个li
e = tree.xpath("//*[@id ='course']/ul[1]//li[position()<4]//text()")
print(e)
3.3 选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点。 一般用于浏览器copy xpath会出现 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /ul/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| //title[@*] | 选取所有带有属性的 title 元素。 |
| //node() | 获取所有节点 |
from lxml import etree # 导包
tree = etree.HTML(open('demo.html', 'r', encoding='utf-8').read()) # 获取需要读取的内容信息
# print(tree) # 获取数据信息
All_Properties = etree.tostring(tree, encoding='utf-8').decode('utf-8')
# 获取选取 元素的所有子元素
a = tree.xpath('//*[@id="course"]/ul/*//text()')
print(a)
# 选取文档中的所有元素
b = tree.xpath('//*[@id="course"]/ul//*/text()')
print(b)
# 选取所有id = course的元素
c = tree.xpath('//*[@id="course"]//text()')
print(c)
# 获取所有节点
d = tree.xpath('//*[@id="course"]//node()')
print(d)

3.4选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| //book/title | //book/price | 选取 book 元素的所有 title 和 price 元素。 |
| //title | //price | 选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
from lxml import etree # 导包
tree = etree.HTML(open('demo.html', 'r', encoding='utf-8').read()) # 获取需要读取的内容信息
# print(tree) # 获取数据信息
All_Properties = etree.tostring(tree, encoding='utf-8').decode('utf-8')
# | 或 匹配id属性
a = tree.xpath('//div[@id="course"]//*/text()|//div[@id="selected"]//*/text() ')
print(a)

3.5 逻辑运算
-
查找所有id属性等于head并且class属性等于s_down的div标签
//div[@id="head" and @class="s_down"] -
选取文档中的所有 title 和 price 元素。
//title | //price注意: “|”两边必须是完整的xpath路径
3.6 属性查询
-
查找所有包含id属性的div节点
//div[@id] -
查找所有id属性等于course的div标签
//div[@id="course"] -
查找所有的class属性
//@class -
//@attrName
//li[@name="xx"]//text() # 获取li标签name为xx的里面的文本内容
-
获取第几个标签 索引从1开始
tree.xpath('//li[1]/a/text()') # 获取第一个 tree.xpath('//li[last()]/a/text()') # 获取最后一个 tree.xpath('//li[last()-1]/a/text()') # 获取倒数第二个
3.7 模糊查询
-
查询所有id属性中包含he的div标签
//div[contains(@id, "he")] -
查询所有id属性中包以he开头的div标签
//div[starts-with(@id, "he")]
3.8 内容查询
查找所有div标签下的直接子节点h1的内容
//div/h1/text()
-
属性值获取
//div/a/@href # 获取a里面的href属性值 -
获取所有
//* #获取所有 //*[@class="xx"] #获取所有class为xx的标签 -
获取节点内容转换成字符串
c = tree.xpath('//li/a')[0] result=etree.tostring(c, encoding='utf-8') print(result.decode('UTF-8'))















 472
472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









