







urllib与requests基础
一、urllib基础
1、urllib.Request基本用法
1.1 基础语法
import urllib.request
url = 'http://www.baidu.com'
# 进行请求
response = urllib.request.urlopen(url)
# print(response)
# 获取状态码
print(response.getcode())
# 获取URL
print(response.geturl())
# 获取请求头
print(response.getheaders())
# 读取响应
print(response.read().decode('UTF-8'))
# 下载数据 保存文件名称为baidu.html
urllib.request.urlretrieve(url, filename='baidu.html')
1.2 构造简单请求
import urllib.request
url = 'http://www.baidu.com' # 获取url
request = urllib.request.Request(url) # 发起响应
print(request) # 获取对象

1.3 添加 headers 参数
import urllib.request
url = 'http://www.baidu.com' # 获取url
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"} # 构造headers
request = urllib.request.Request(url, headers=headers) # 构造请求
response = urllib.request.urlopen(request) # 发起请求
with open('baidu.html', 'wb') as f:
f.write(response.read())
1.4 添加data参数
import urllib.request
import urllib.parse
import json
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/15.0 Safari/605.1.15',
}
data = {
'cname': '',
'pid': '',
'keyword': '北京',
'pageIndex': 1,
'pageSize': 10,
}
# 使用post方式
# 需要
data = urllib.parse.urlencode(data).encode('utf-8')
req = urllib.request.Request(url, data=data, headers=headers)
res = urllib.request.urlopen(req)
print(res.getcode())
print(res.geturl())
data = json.loads(res.read().decode('utf-8'))
# print(data)
for i in data['Table1']:
print(i)
1.5 response.read()
获取响应的html字符串,bytes类型
#发送请求
response = urllib.request.urlopen("http://www.baidu.com")
#获取响应
response.read()
2、urllib请求百度首页
import urllib.request
url = 'http://www.baidu.com'
#构造headers
headers = {"User-Agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)"}
#构造请求
request = urllib.request.Request(url, headers = headers)
#发送请求
response = urllib.request.urlopen(request)
#获取html字符串
html_str = response.read().decode('utf-8')
print(html_str)
3、urllib小结
- urllib.request中实现了构造请求和发送请求的方法。
- urllib.request.Request(url,headers,data)能够构造请求。
- urllib.request.urlopen能够接受request请求或者url地址发送请求,获取响应。
- response.read()能够实现获取响应中的bytes字符串。
二、requests模块
1、requests安装
pip install requests
2、requests基础函数
import requests
url = 'http://www.baidu.com'
response = requests.get(url) # 发起get请求
print(response) # <Response [200]>
response.encoding = 'UTF-8' # 设置编码
print(response.text) # 打印一下响应内容
print(response.content.decode('UTF-8')) # 返回bytes
print(response.url) # 获取请求的url http://www.baidu.com/
print(response.status_code) # 获取状态码 200
print(response.request.headers) # 获取响应对应的请求头
# {'User-Agent': 'python-requests/2.24.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
print(response.cookies) # 获取响应的cookie <RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]>
print(response.ok) # true
response的常用属性:
-
response.text响应体 str类型 -
response.encoding从HTTP header中猜测的响应内容的编码方式 -
respones.content响应体 bytes类型 -
response.status_code响应状态码 -
response.request.headers响应对应的请求头 -
response.headers响应头 -
response.request.cookies响应对应请求的cookie -
response.cookies响应的cookie(经过了set-cookie动作) -
response.url获取访问的url -
response.json()获取json数据 得到内容为字典 (如果接口响应体的格式是json格式时) -
response.ok如果status_code小于200,response.ok返回True。
如果status_code大于200,response.ok返回False。
3、requests模块get请求
需求:通过requests向百度首页发送请求,获取百度首页的数据。
import requests
url = 'https://www.baidu.com' # 获取url
response = requests.get(url) # 发送get请求
print(response.text) # 打印响应内容
3.1 response.text 与response.content的区别
response.text- 类型:str
- 修改编码方式:
response.encoding="gbk/UTF-8"
response.content- 类型:bytes
- 修改编码方式:
response.content.deocde("utf8")
获取网页源码的通用方式:
response.content.decode()response.content.decode("UTF-8")response.text
推荐使用response.content.deocde()的方式获取响应的html页面
3.2 练习,下载照片
- 图片的url:
https://www.baidu.com/img/bd_logo1.png - 利用requests模块发送请求获取响应。
- 以2进制写入的方式打开文件,并将response响应的二进制内容写入。
import requests
url = 'https://www.baidu.com/img/bd_logo1.png' # 图片的url
response = requests.get(url) # 响应本身就是一个图片,并且是二进制类型
# 以二进制+写入的方式打开文件
with open('baidu.png', 'wb') as f:
# 写入response.content bytes二进制类型
f.write(response.content)
4、发送带header的请求
4.1 不添加hearder参数
先以不填写header的方式进行访问百度网页。代码如下:
import requests
url = 'https://www.baidu.com'
response = requests.get(url)
with open('baidu.html', 'wb') as f:
# 写入response.content bytes二进制类型
f.write(response.content)
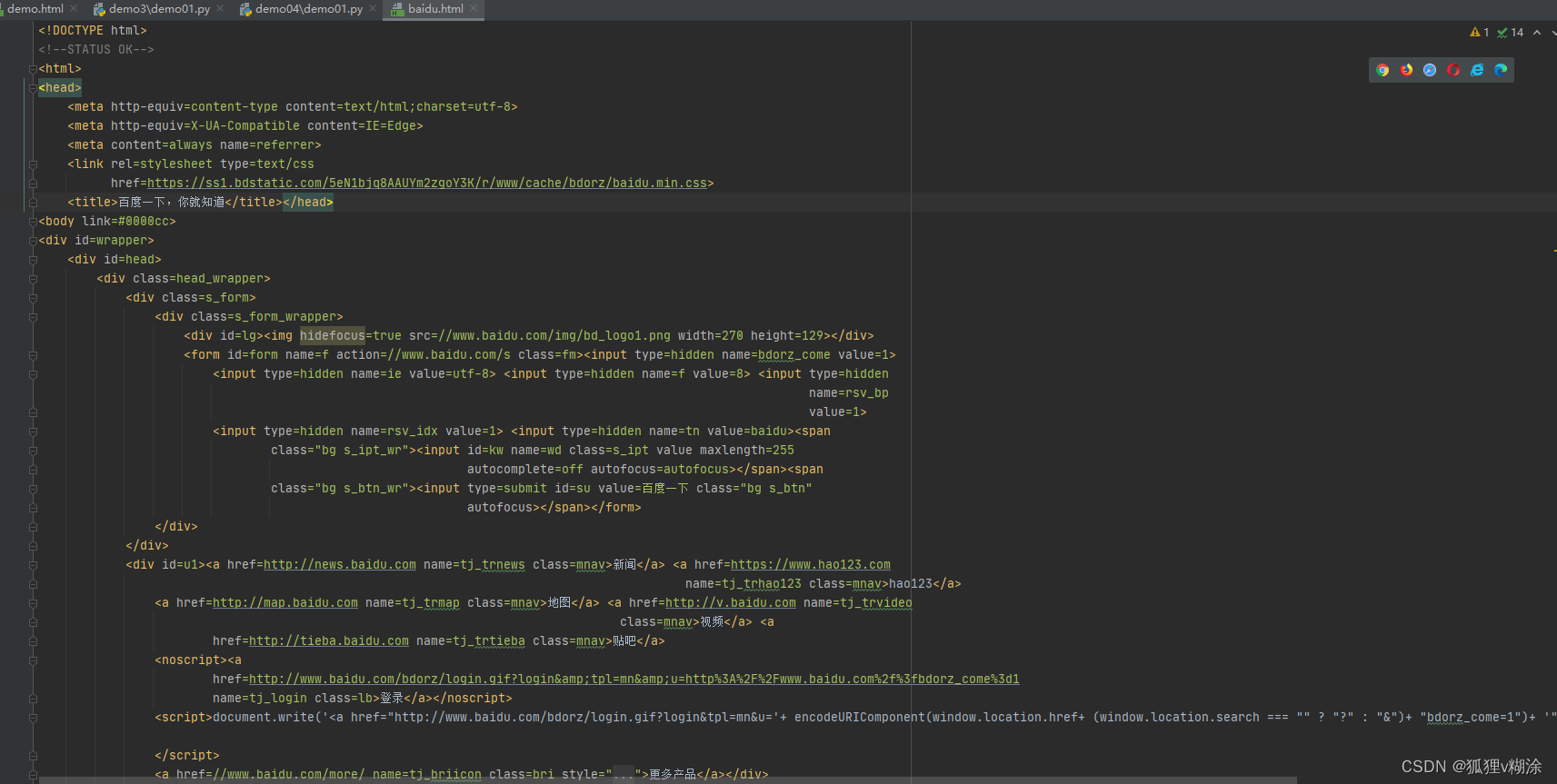 发现代码中的百度首页的源码非常少,这时候需要使用header修改进行模拟浏览器,获取到与浏览器一致的内容。
发现代码中的百度首页的源码非常少,这时候需要使用header修改进行模拟浏览器,获取到与浏览器一致的内容。
4.2 添加header参数
header的形式:字典
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
用法
requests.get(url, headers=headers)
4.5 完整的代码
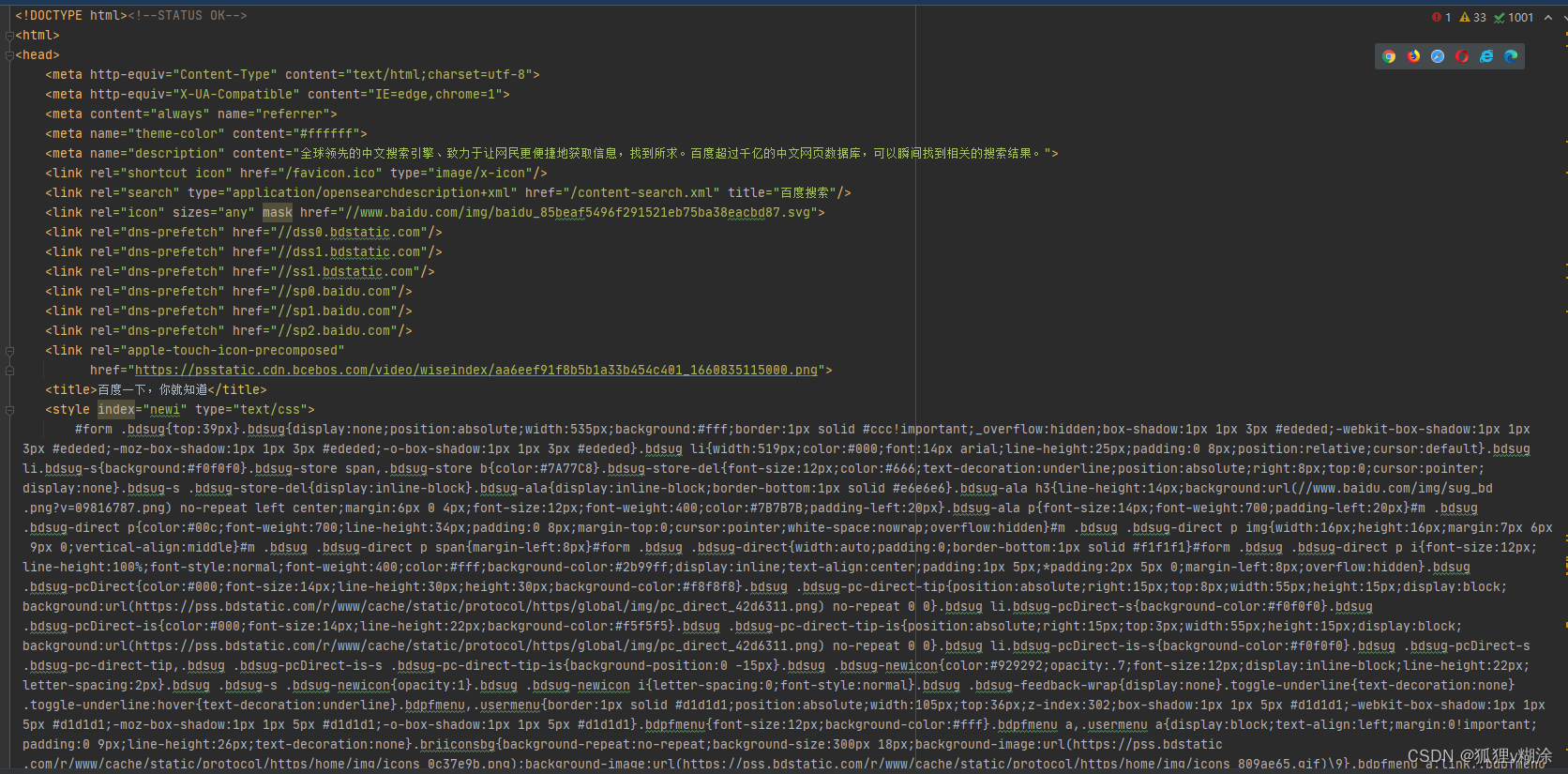
import requests
url = 'https://www.baidu.com'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
response = requests.get(url, headers=headers)
with open('baidu.html', 'wb') as f:
# 写入response.content bytes二进制类型
f.write(response.content)
5、requests 带参数的请求
5.1 请求参数的形式:字典
kw = {'wd':'张三丰'}
5.2 请求参数的用法
requests.get(url,params=kw)
5.3 两种方式:发送带参数的请求
-
对
https://www.baidu.com/s?wd=python发起请求可以使用requests.get(url, params=kw)的方式# 方式一:利用params参数发送带参数的请求 import requests headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"} # 最后有没有问号结果都一样 url = 'https://www.baidu.com/s?' # 请求参数是一个字典 即wd=python kw = {'wd': 'python'} # 带上请求参数发起请求,获取响应 response = requests.get(url, headers=headers, params=kw) print(response.content) -
也可以直接对
https://www.baidu.com/s?wd=python完整的url直接发送请求,不使用params参数# 方式二:直接发送带参数的url的请求 import requests headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"} url = 'https://www.baidu.com/s?wd=python' # url中包含了请求参数,所以此时无需params response = requests.get(url, headers=headers) print(response.content)
6、requests模块post请求
6.1 requests发送post请求语法:
-
用法:
response = requests.post("http://www.baidu.com/", data = data, headers=headers) -
data 的形式:字典
6.2 POST请求练习
下面面我们通过金山翻译的例子看看post请求如何使用:
地址:https://www.iciba.com/fy
-
模拟浏览器获取数据
import requests import json headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"} url = 'https://ifanyi.iciba.com/index.php?c=trans&m=fy&client=6&auth_user=key_ciba&sign=99730f3bf66b2582' data = { 'from': 'zh', 'to': 'en', 'q': 'lucky ' } res = requests.post(url, headers=headers, data=data) # print(res.status_code) # 返回的是json字符串 需要在进行转换为字典 data = json.loads(res.content.decode('UTF-8')) # print(type(data)) print(data) print(data['content']['out'])















 1688
1688











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









