






HashSet
介绍
1、HashSet实现了Set接口
2、HashSet 底层实际上是 HashMap
3、可以存放null值,但是只能有一个null, 但元素不能重复
4、HashSet不保证元素是有序的(即取出和存放的顺序不一致),取决于hash后,再确定索引的结果(取出的顺序虽然不是添加的顺序,但他是固定的。)
5、不能有重复的元素或者对象(注意是对象)。
package com.zhang.test_package.set_;
import java.util.HashSet;
public class HashSet_ {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
// HashSet不能添加相同的元素
hashSet.add("zhang"); //T
hashSet.add("zhang"); // F
// 两个均可以添加成功,根据地址进行判断
hashSet.add(new Dog("A")); // T
hashSet.add(new Dog("d")); // T
// 能添加成功一个,看源码,进行解析
hashSet.add(new String("cheng")); // T
hashSet.add(new String("cheng")); // F
System.out.println(hashSet);
}
}
class Dog{
private String name;
public Dog(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Dog{" +
"name='" + name + '\'' +
'}';
}
}
HashSet底层机制
HashSet底层是HashMap,HashMap的底层是(数组 + 单向链表 + 红黑树)
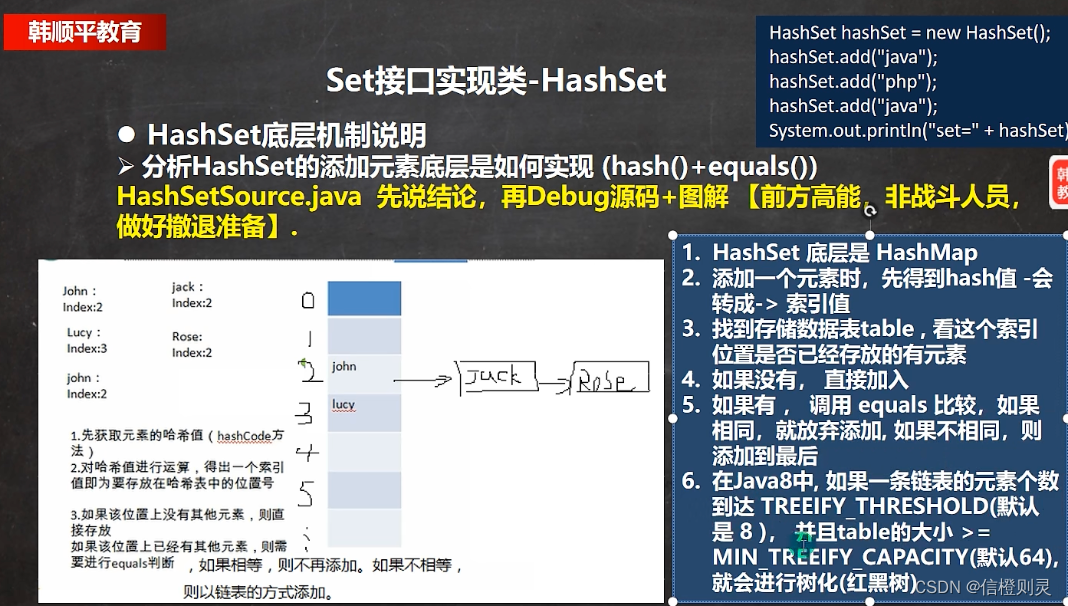
1、HashSet的底层是HashMap
2、当添加一个元素的时候,会先得到一个hash值,对哈希值进行运算,得出一个索引值,即为要存放在哈希表中的位置号。
3、找到存储数据表table(默认长度为16),在表中查看索引值的位置上是否已经存放元素。
临界值(threshold)是16 × loadFactor(0.75) = 12,如果table中使用达到了临界值,就会进行两倍扩容(16 × 2 = 32),此时临界值为:32 × 0.75 = 24;以此类推,如果当table的一条链表个数大于8个时,且table总数量 ≥64,就会进行树化(红黑树)。注意:只要往HashSet中加入一个数据,就算一个。

4、如果没有存放元素的话,则直接加入
5、如果有元素的话,则调用equals方法进行比较(此处不止判断equals,在传入对象的时候,通过equals进行重写),如果遇到相同元素,则放弃添加,如果没有,则添加到链表最后
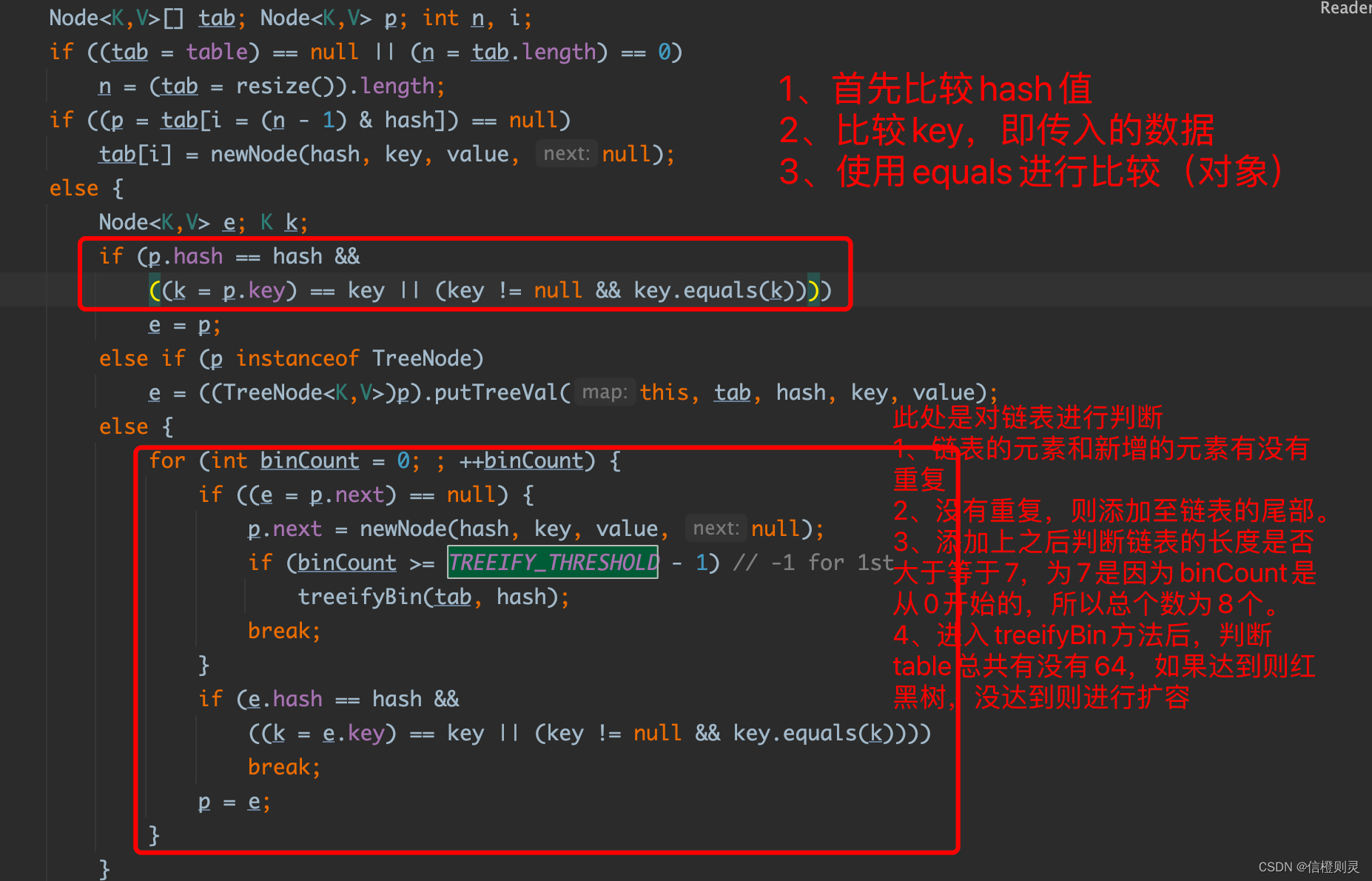
添加到链表最后时,会对链表的长度进行判断,如果超过了8个,则再对整个table进行判断,如果整个table的大小没超过64,则对table进行扩容(是进行扩容,不是放在其他节点),如果超过了64,则进行红黑树化。
6、在java8后,如果一条链表的元素个数超过 TREEIFY_THRESHOLD(默认是8),并且table的大小 ≥ MIN_TREEIFY_CAPACITY(默认64),就会进行树化(红黑树)。
HashSet机制测试代码
package com.zhang.test_package.set_;
import java.util.HashSet;
public class HashSetSource {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
// 测试HashSet的扩容机制
for (int i = 0; i < 1020; i++) {
hashSet.add(i);
}
System.out.println(hashSet);
// 测试在单一链表大于8时,到转为红黑树的过程
for (int i = 0; i < 100; i++) {
hashSet.add(new Book(i));
}
}
}
class Book{
public int i;
public Book(int i) {
this.i = i;
}
@Override
public int hashCode() {
return 100;
}
}
测试题
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IXGnXBO9-1689781241836)(https://flowus.cn/preview/3010e640-4f75-4a52-95ae-1d2713fe069b)]](https://img-blog.csdnimg.cn/133f54c6402e43c39aa03f4b33992c99.png)
package com.zhang.exercise;
import java.util.HashSet;
import java.util.Objects;
public class HashSetTest {
public static void main(String[] args) {
Employee zhang = new Employee("zhang", 12);
Employee cheng = new Employee("cheng", 18);
HashSet hashSet = new HashSet();
hashSet.add(zhang);
hashSet.add(cheng);
hashSet.add(new Employee("zhang", 12));
System.out.println(hashSet);
}
}
class Employee {
private String name;
private int age;
public Employee(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "name=" + name + " age=" + age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Employee employee = (Employee) o;
return age == employee.age && Objects.equals(name, employee.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
在hashCode的代码中,注意到类型是object,而 int 会装箱 Integer 如果数值不在-128~127显然不是一个对象,但Integer底层重写了hashCode返回本身数值,所以即便Integer对象不同得到的hashCode也是一样的。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kyKvrGH6-1689781241837)(https://flowus.cn/preview/87a74e23-460a-454d-8680-7078a6105a33)]](https://img-blog.csdnimg.cn/848ddc371bad4b8e9d146b9cd6e0445f.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BUPBxF4g-1689781241837)(https://flowus.cn/preview/76b643df-32e4-468e-844d-c3070f372a9d)]](https://img-blog.csdnimg.cn/1d53516f39dc4b219201b72c440459fe.png)
LinkedHashSet
1、LinkedHashSet 是 HashSet的子类
2、LinkedHashSet 底层是LinkedHashMap, 底层维护了 数组 + 双向链表 的 结构
3、LinkedHashSet 根据元素的 hashCode 值来决定元素的存储位置,同时使用链表维护元素的次序,这使得元素看起来是以插入顺序保存的。
4、LinkedHashSet 不允许添加重复元素。
底层原理
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-p9iQ8Jqq-1689781241837)(https://flowus.cn/preview/8a864042-ba3f-4225-8acd-ebcb70f7b27f)]](https://img-blog.csdnimg.cn/f6595442ea5441199f975e3a489d8df8.png)
1、在LinkedHashSet 中维护了一个hash表和双向链表(LinkedHashSet 有head 和 tail)
2、每一个节点有 before 和after 属性,这样可以形成双向链表
3、在添加一个元素时,先求hash值,再求索引,确定该元素在table的位置,然后将添加的元素加入到双向链表(如果已经存在,则不添加[原则上和hashSet一致])
4、在遍历LinkedHashSet时能确保插入顺序和遍历顺序一致















 396
396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









