







IDEA+Maven运行调试MapReduce程序
文章目录
新建java类
在项目的左侧文件目录中,选择
s
r
c
src
src ->
m
a
i
n
main
main ->
j
a
v
a
java
java,鼠标右键点击,选择
N
e
w
New
New ->
J
a
v
a
C
l
a
s
s
Java Class
JavaClass
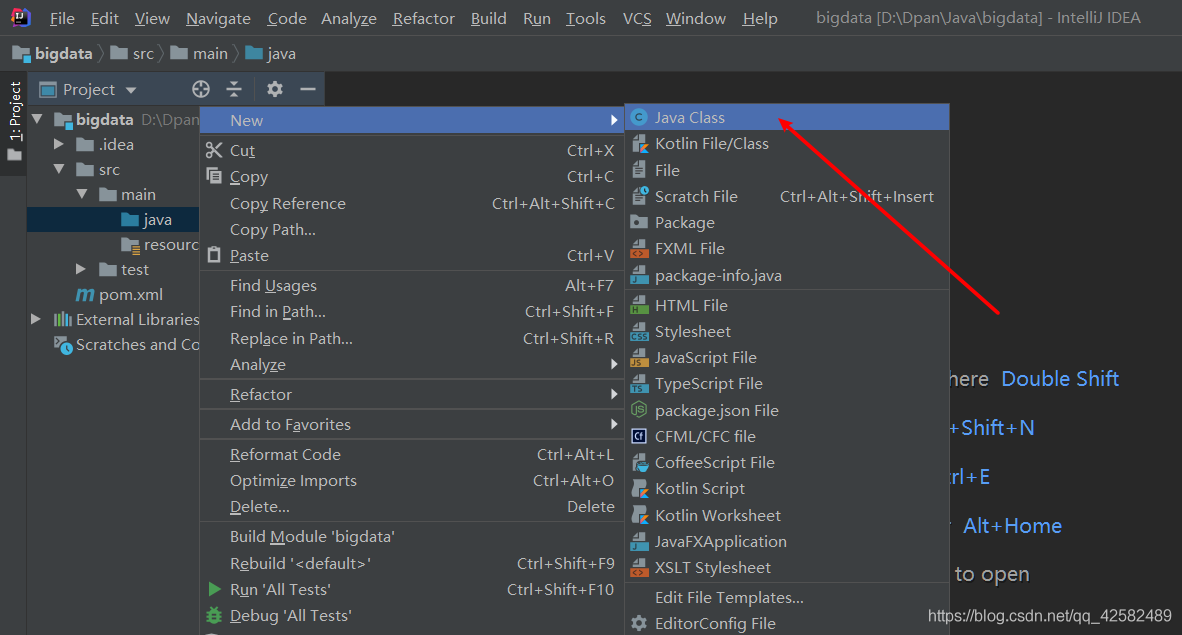
在弹窗中输入你想要建类的名字,回车即可。这里我们使用Hadoop官方给出的教程代码 WordCount
在刚才建立的 WordCount类中添加代码,WordCount对输入文件字符进行计数,输出计数的结果。
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
配置输入文件路径
在 b i g d a t a bigdata bigdata 下新建一个 i n p u t input input 文件夹,添加一个或者多个文件到 i n p u t input input 中。注意 input 和 src 是同级目录
鼠标右键点击 bigdata,选择
N
e
w
New
New ->
D
i
r
e
c
t
o
r
y
Directory
Directory
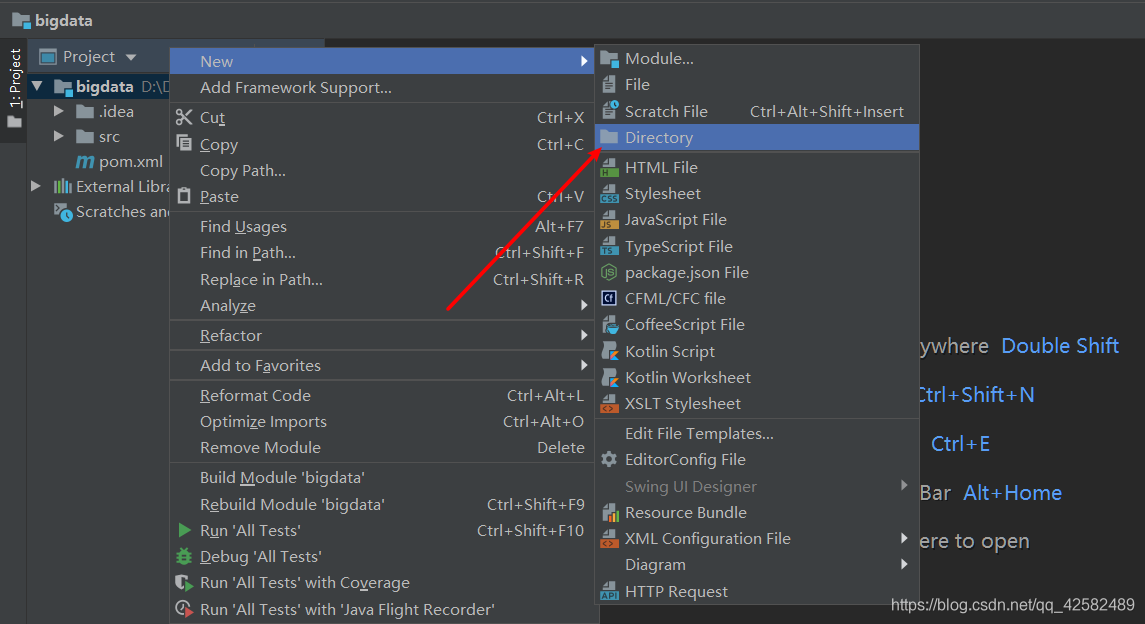
在新弹窗的“NAME”中输入名字“input”
这时候我们看到,input文件夹已经建立成功,我们在里面导入需要的输入文件就可以了
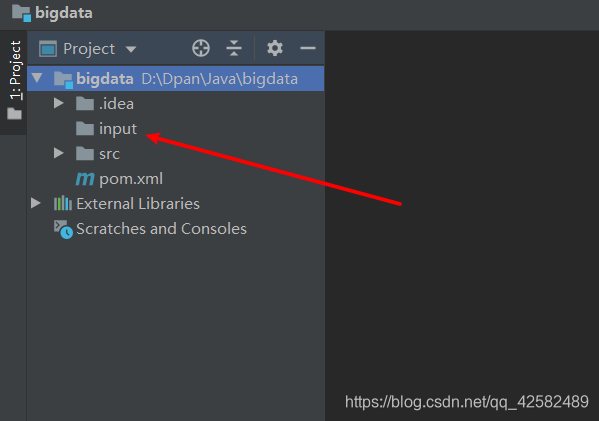
修改level参数
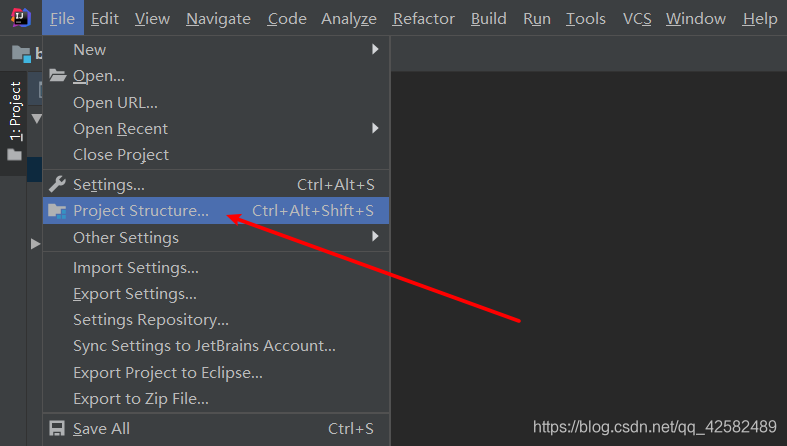
在IDEA菜单栏中点击
F
i
l
e
File
File ->
P
r
o
j
e
c
t
S
t
r
u
c
t
u
r
e
Project Structure
ProjectStructure
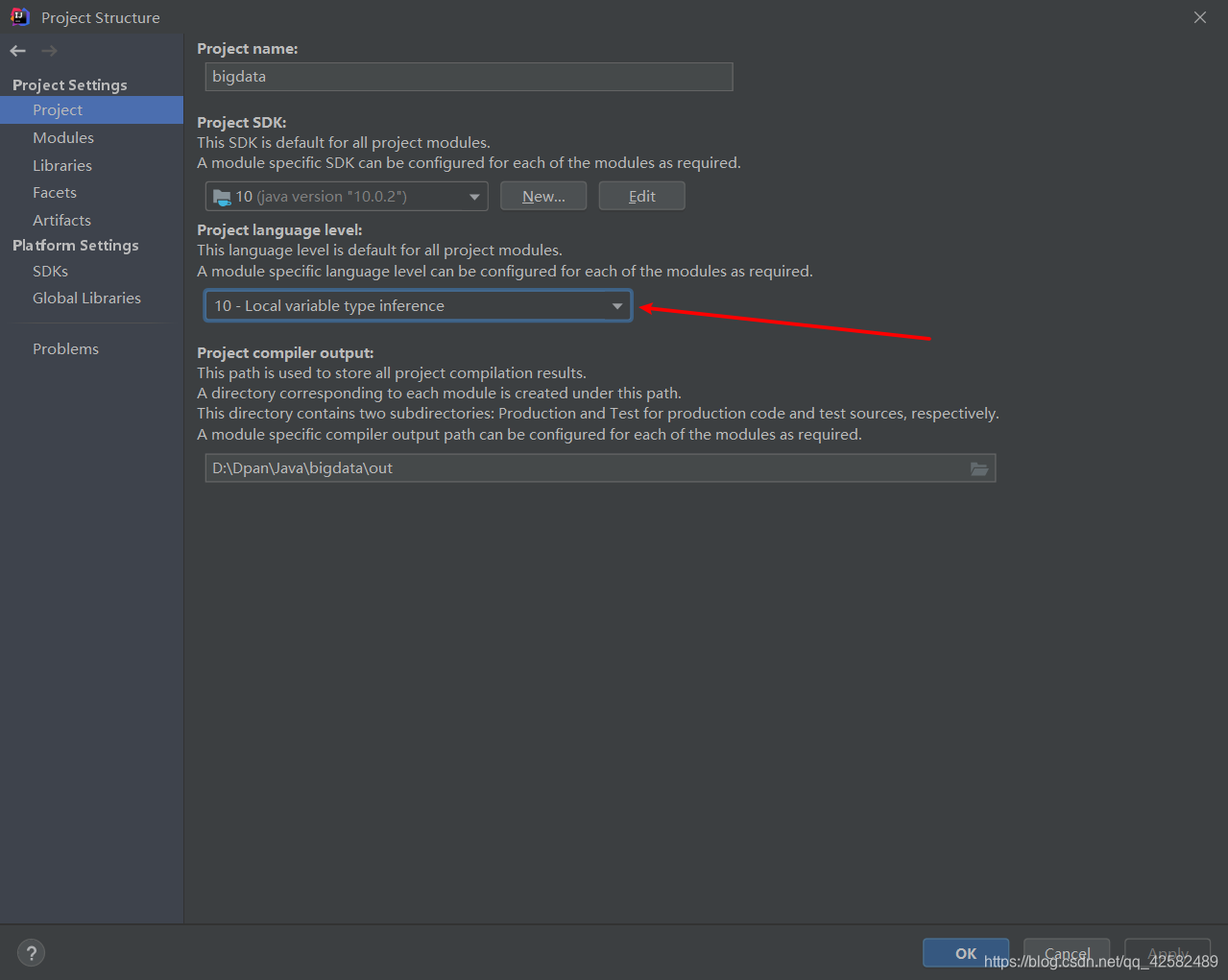
在新窗口的左侧 Project Setting 中选择 Project ,查看moduls版本,这里可以看到我的版本是10
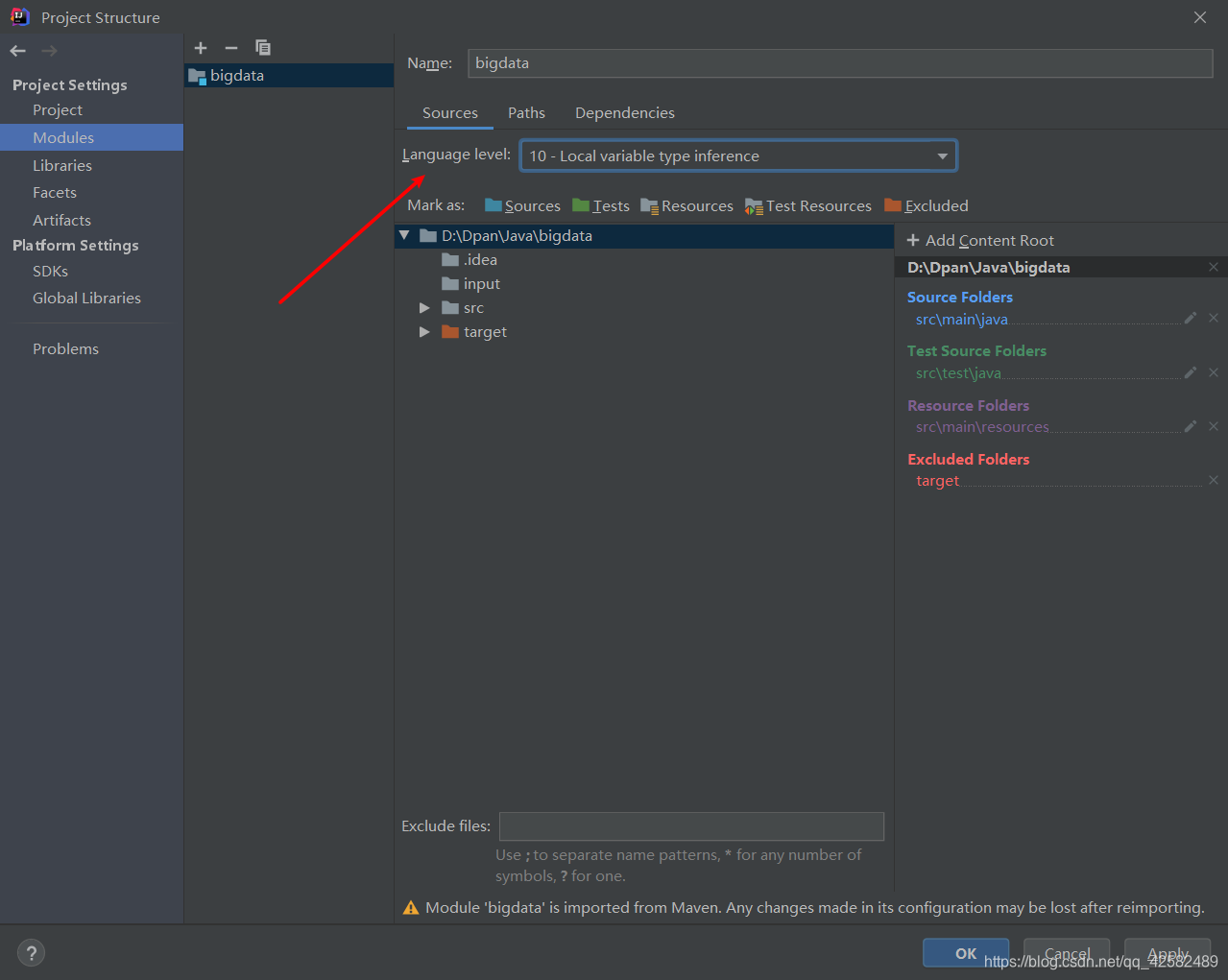
Project Setting 选择 Modules,将 sources 选项卡下的 Language-level 改为对应版本,这里我们选择10,点击OK
添加Application配置
在IDEA的菜单栏中点击
R
u
n
Run
Run ->
E
d
i
t
C
o
n
f
i
g
u
r
a
t
i
o
n
s
Edit Configurations
EditConfigurations
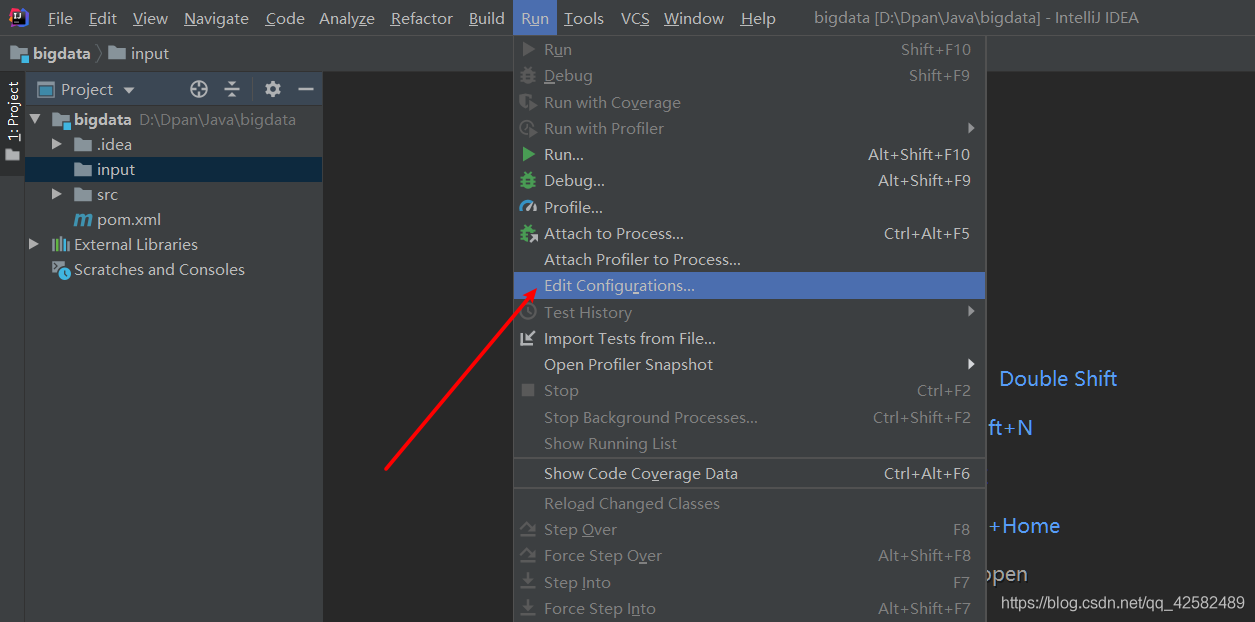
在新窗口中点击左上方的加号,选择 Application
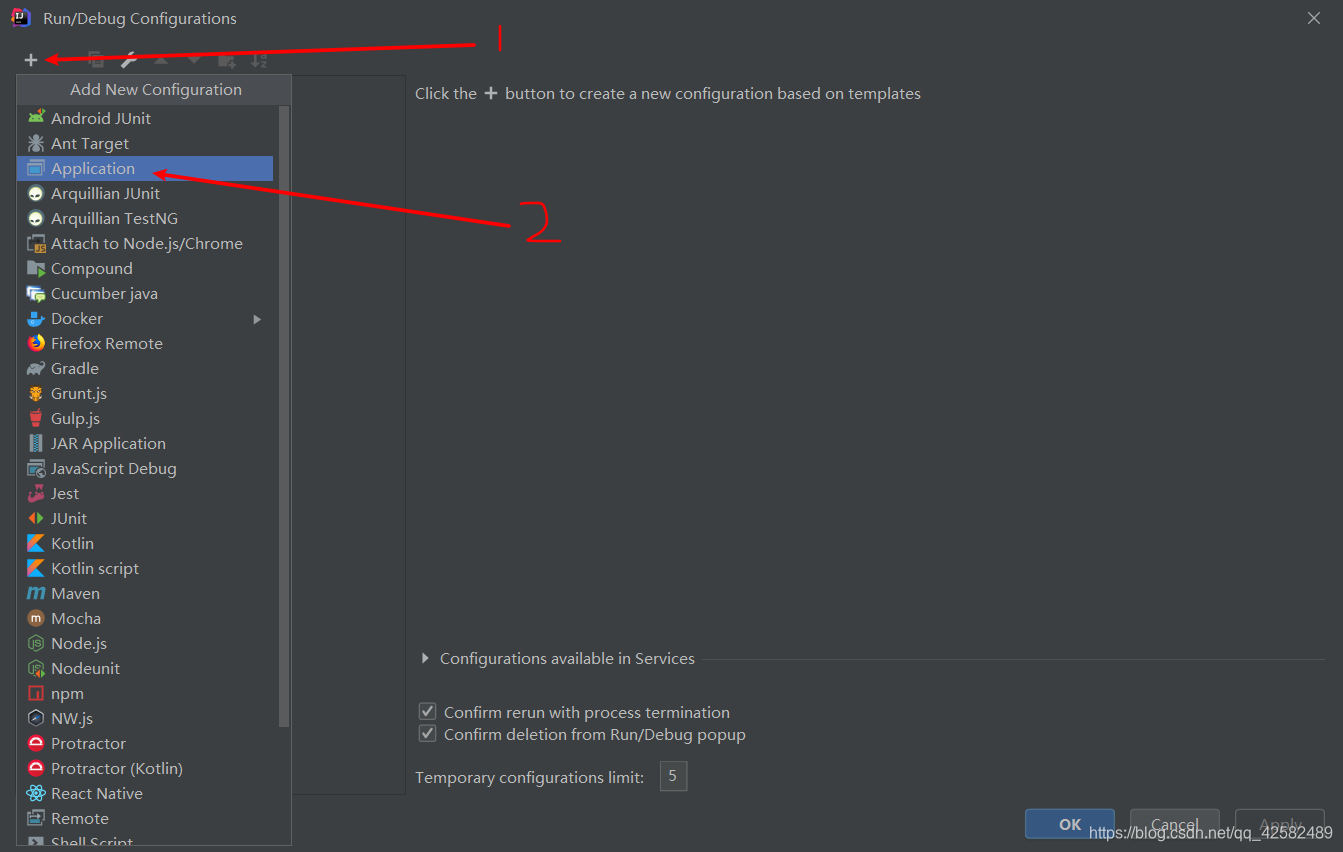
配置步骤依次为:
- 在 Application 的 Name 填写你要运行时选择的名字,这里我们改为 WordCount。
- 在 Main class 选择为你要运行的程序,点击右边的 ⋅ ⋅ ⋅ ··· ⋅⋅⋅就可以选择,这里我们选择WordCount
- 在 Program arguments 填写 i n p u t / o u t p u t / input/ output/ input/output/,意味着输入路径为刚才创建的 input 文件夹,输出为 output。这个 output 系统会自动创建。注意 input/ 和 output/ 之间有一个空格,这表示 input 和 output 是两个参数。
- 配置完毕,点击OK
运行
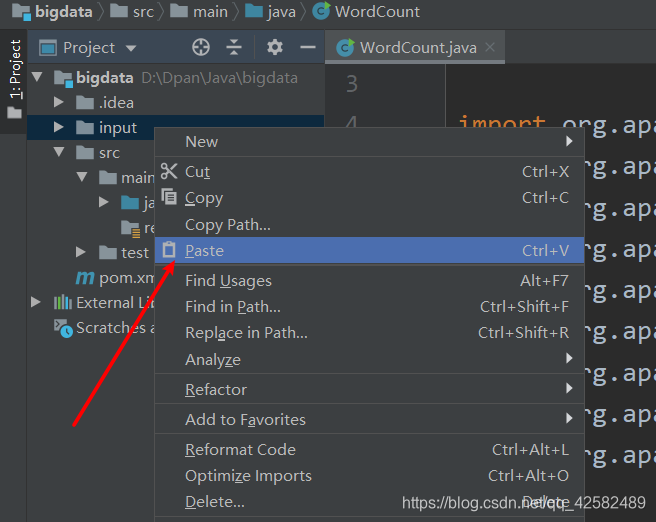
在input文件夹中先导入你需要用到的输入文件。将文件复制一下,再进入 IDEA ,对着 input 文件夹点击鼠标右键,点击 Paste,弹窗点击OK,就可以将文件粘贴进入 input 中。导入文件成功后,就可以开始运行程序了。
如果要删除文件也很简单,选中文件,右击鼠标,选择 Delete 删除即可
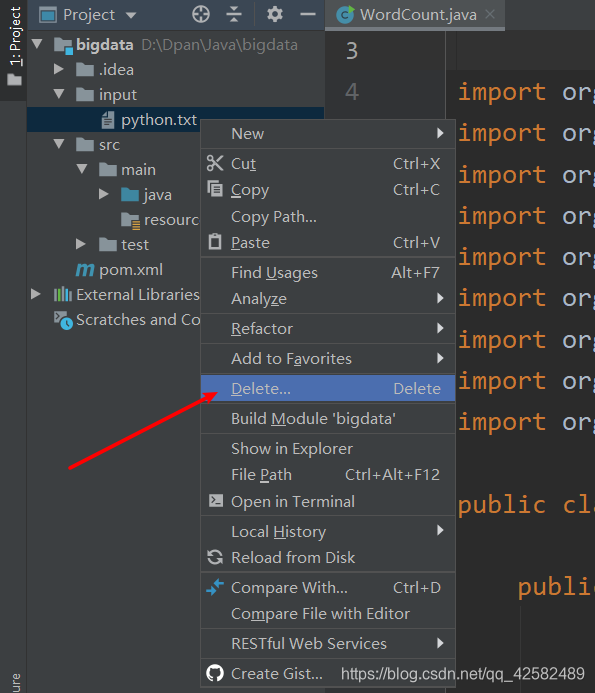
运行程序有两种常用方式,直接点击右上角的绿色三角运行符号,或者在程序中右键空白处再点击运行
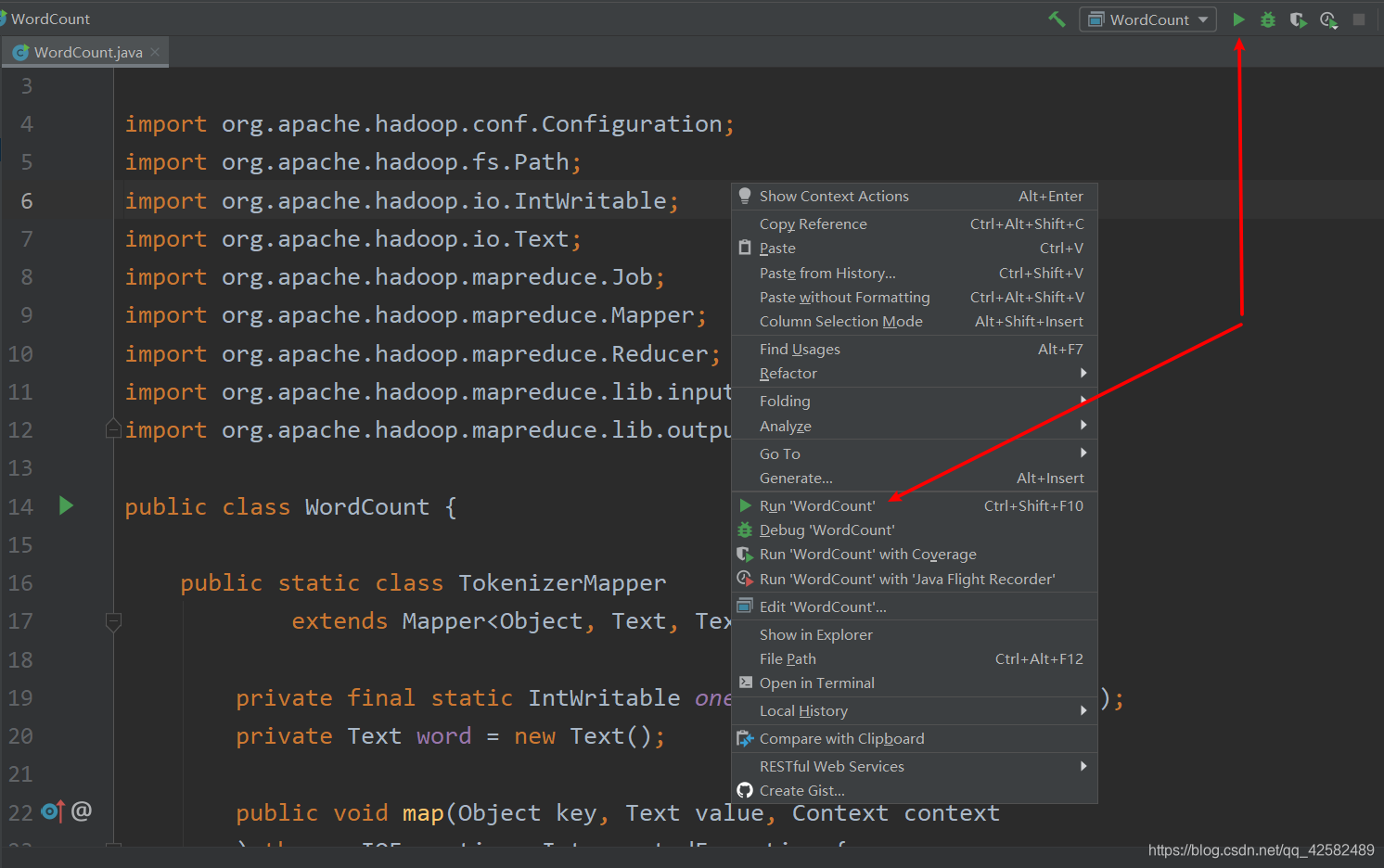
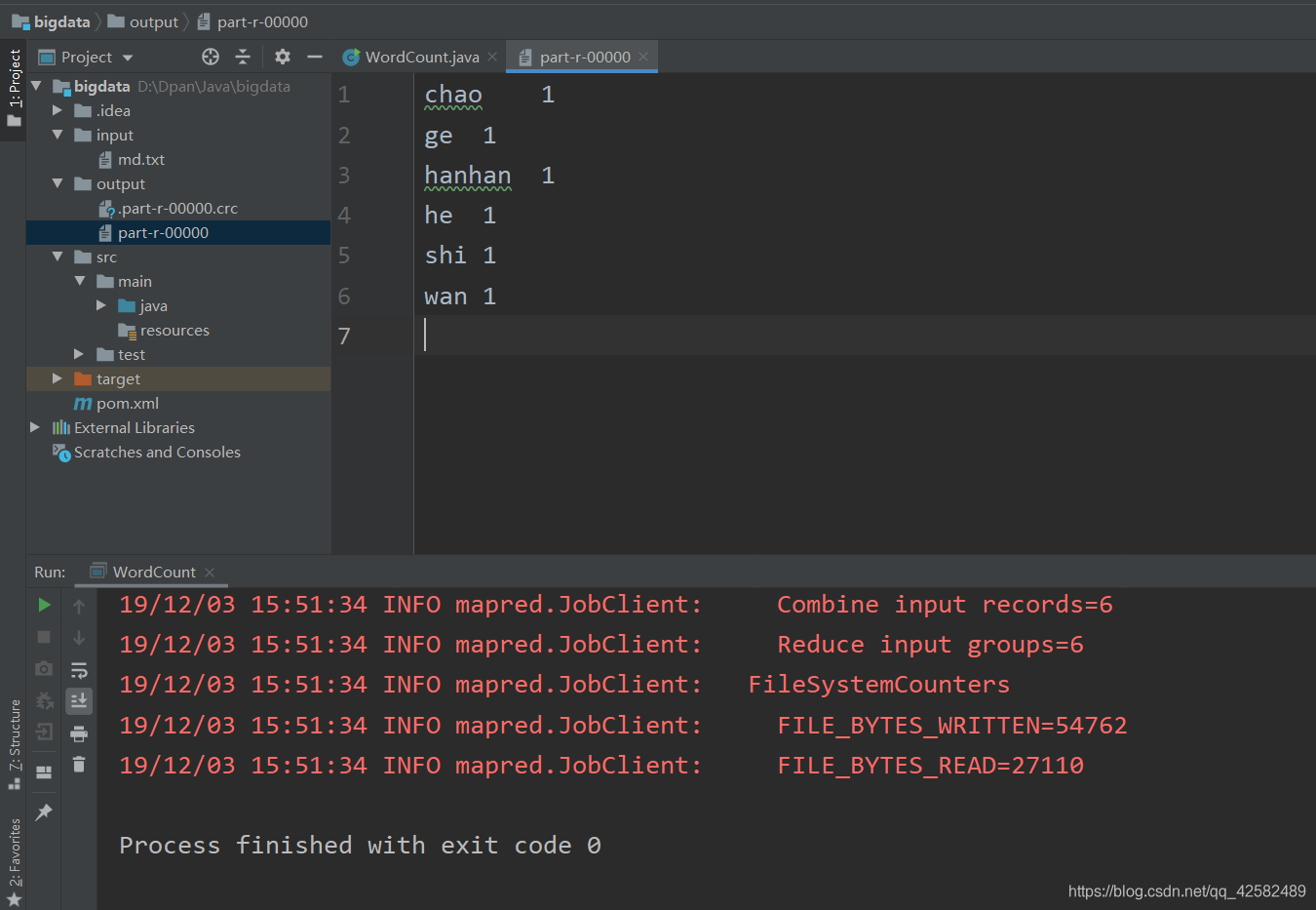
点击开始运行之后,IDEA 下方会显示 Hadoop 的运行输出。待程序运行完毕后,IDEA 的左侧项目目录会出现新的文件夹 output,里面存放的 part-r-00000 就是运行的结果了!
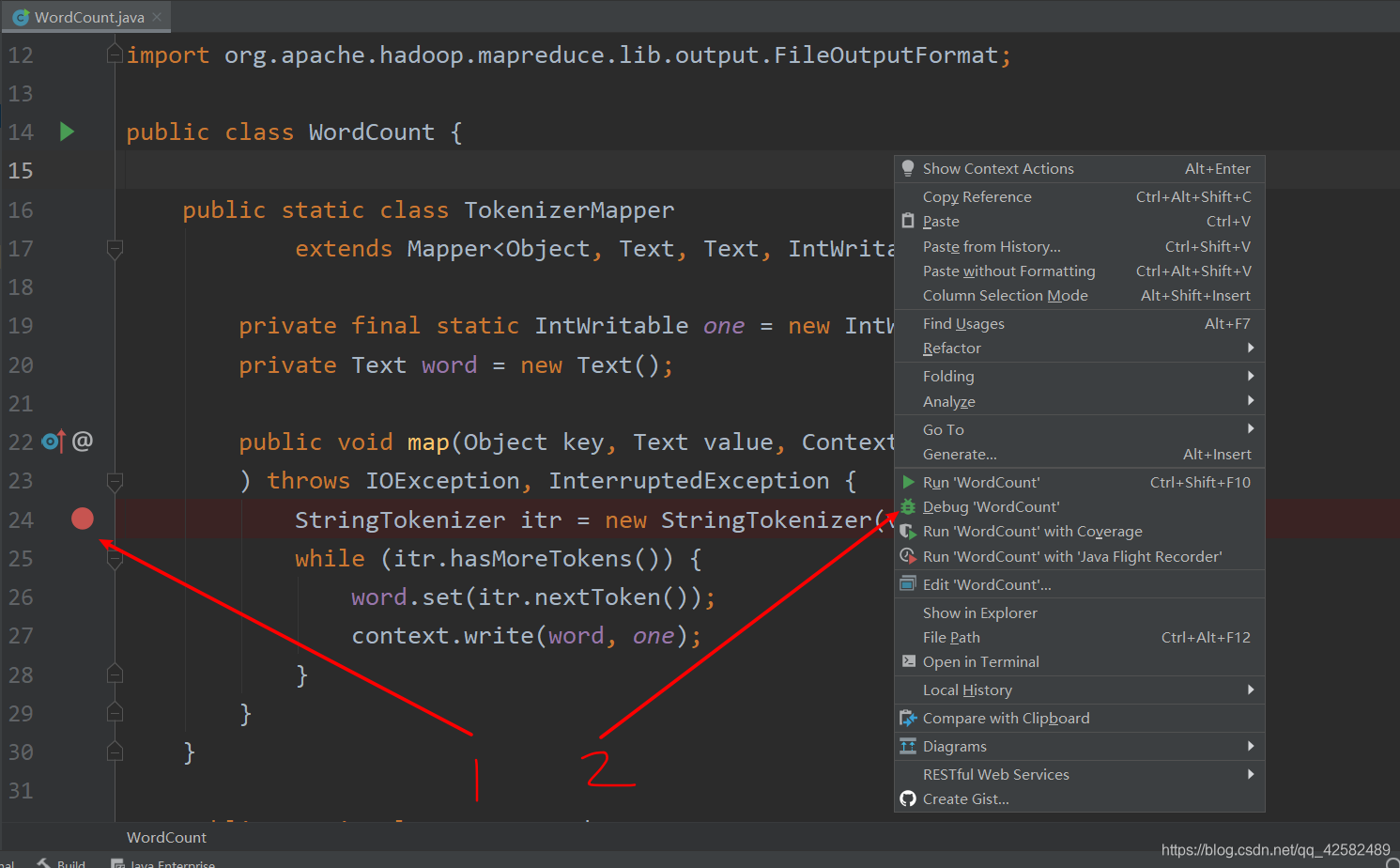
调试
调试的时候需要先加上断点,我们在需要调试的代码前单击加上断点,鼠标右击空白处,选择 Debug ‘WordCount’ 就可以开始调试,程序会在断点处停下。
常见报错
Error:java: 不支持发行版本 5
本地运行的是 JDK10,这个报错的原因是项目编译配置使用的 Java 版本不对
-
IDEA菜单栏中点击 “File -> Project Structure”,查看“Project”和“Modules”中Java版本和本地Java版本是不是一致。如果不一致,改成本地使用的Java版本。
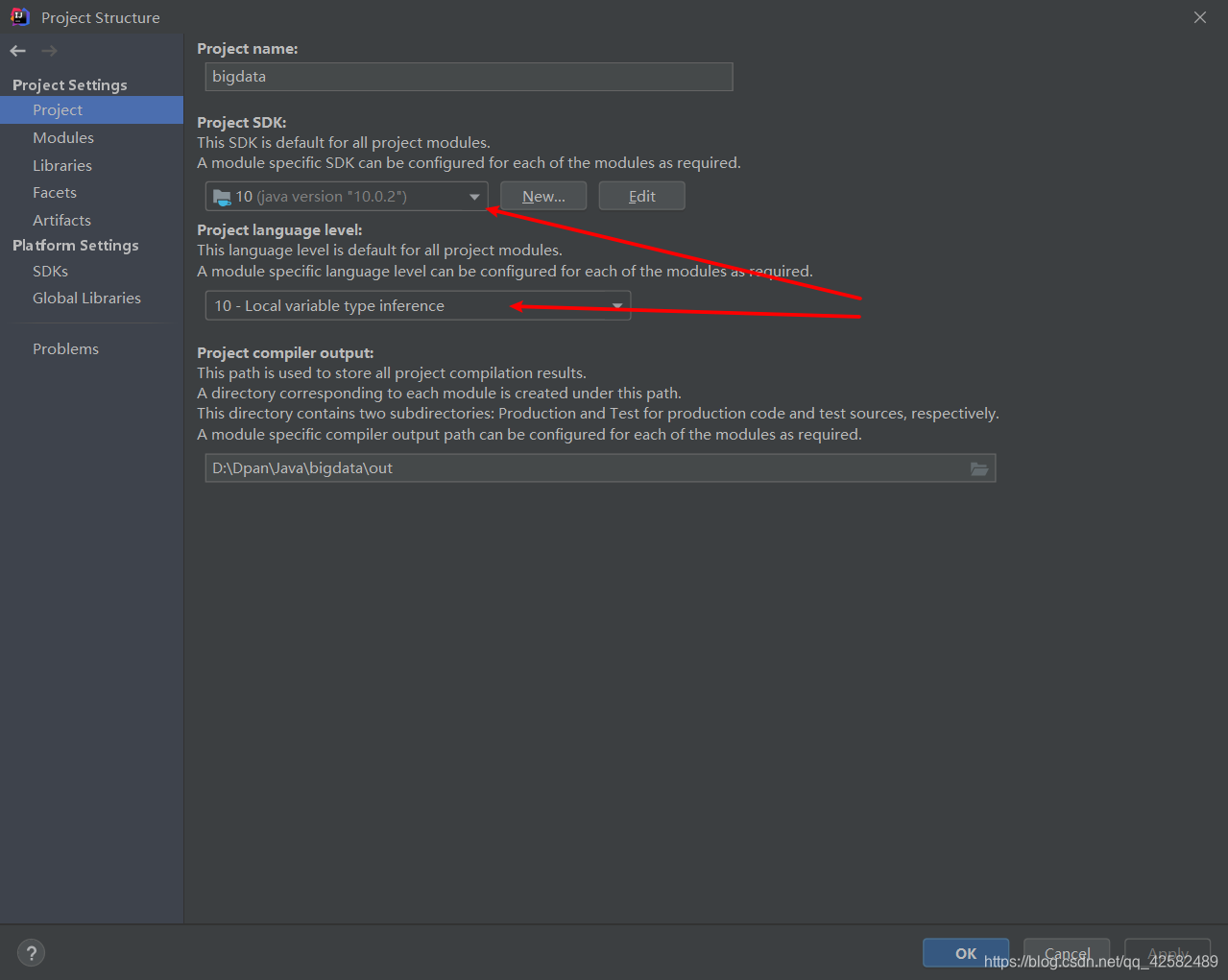
-
IDEA菜单栏中点击 “File” -> “Setting”,选择 “Bulid, Execution,Deployment” -> “Compiler” -> “Java Compiler”,把项目的 Target bytecode version 设置为本地版本,同时把
Project bytecode version 也改为本地版本。
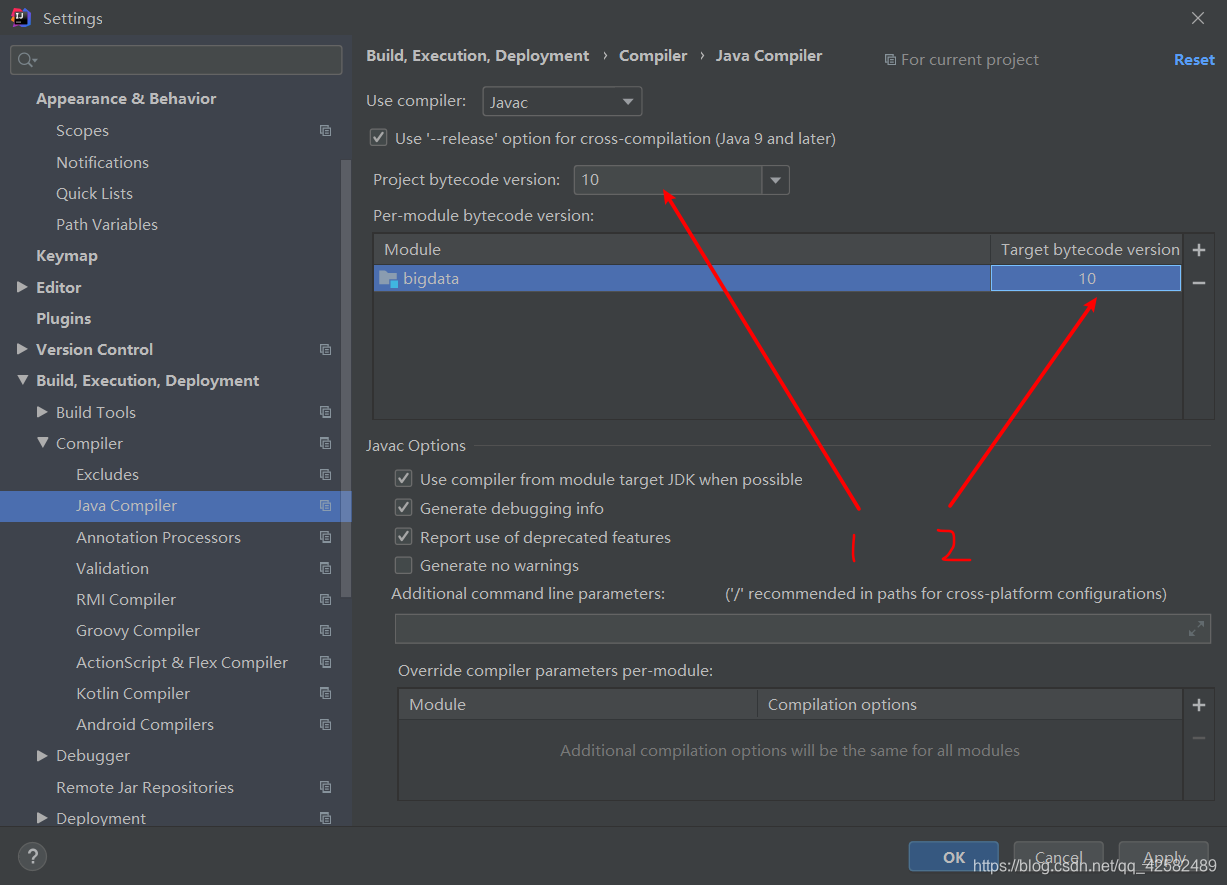
这两步修改完之后,这个错误就被解决了
系统找不到指定的文件
Exception in thread “main” java.io.IOException: Cannot run program “chmod”: CreateProcess error=2, 系统找不到指定的文件。
如果遇到这个错误,是因为 Windows 下需要安装 x64 cygwin。
解决方法是,到 cygwin 官网下载 setup-x86_64.exe,安装之后,把 bin 目录配置到 Windows 的环境变量 path 中,重启 IDEA 就可以了。
具体的 Cygwin 安装过程请参考这篇博客 windows 安装cygwin教程
Windows下的权限问题
Windows下的权限错误有两种。第一种:
ERROR security.UserGroupInformation: PriviledgedActionException as …
第二种:
Exception in thread “main” java.io.IOException: Failed to set permissions of path: …
这都是因为当前用户没有权限来设置路径权限(Linux就不会遇到这个问题)
解决方法有三种:
- 给hadoop打补丁,Hadoop解决windows下权限问题,这个方法适合于Hadoop环境,因为这里我们使用的是Maven,此方法不适合。
- 将当前用户设置为超级管理员,或以超级管理员登录运行此程序。(这个方法好像失效了,推荐使用第三种方法)
- 将 Hadoop-core 的版本进行回退。首先,我们查看 pom.xml 的 hadoop-core 版本。如果版本是1.2.1 及以上的,将版本设置为 0.20.2 ,重新导入依赖。之后,相应的 main 方法里面的 Job job = Job.getInstance(conf, “word count”); 改成 Job job = new Job(conf, “word count”); 这样问题就解决了。
运行Hadoop,真心建议还是使用 Linux 或者 MacOS,Windows下错误太多了。
参考博客
参考博客 Hadoop: Intellij结合Maven本地运行和调试MapReduce程序 (无需搭载Hadoop和HDFS环境)















 1999
1999











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









