







大多数的应用程序都需要与外部的输入/输出设备I/O(Input/Output)进行数据交换。在Java中,所有的I/O机制都是基于数据“流”方式进行输入/输出。这些“数据流”可视为同一台计算机不同设备或网络中不同计算机之间流动的数据序列。如同水管里的水流一样,在水管的一端一点一滴地供水,而在水管的另一端看到的是一股连续不断的水流。
Java把这些不同来源和目标的数据统一抽象为“数据流”。当Java程序需要读取数据时,就会开启一个通向数据源的流,这个数据源可以是文件、内存、也可以是网络连接。而当Java程序需要写入数据时,也会开启一个通向目的地的流,这时,数据就可以想象为管道中“按需流动的水”。流为操作各种物理设备提供了一致的接口。通过打开操作将流关联到文件,通过关闭流操作将流和文件解除关联。
这些流序列中的数据通常有两种形式:文本流和二进制流。文本流每一个字节存放一个ASCII码,代表一个字符(而对于Unicode编码来说,每两个字节表示一个字符)。使用文本流时,可能会发生一些字符型转换。例如,在windows操作系统中,当输出换行字符的时候,它可以被转换为回车和换行序列。二进制流,也称字节流,它是把数据按其内存中存储的以字节形式“原封不动”地输出或存储。两者的区别与联系可以用下面的例子(以ASCII码为例)来说明。的区别与联系可以用下面的例子(以ASCII码为例)来说明。例如,有一个整型数12345,其在内存当中仅需要2个字节,由于系统为整型数据分配4个字节,所以其高位两个字节均为0,而按文本流形式输出则占用5个字节,分别是“12345”这5个字符对应的ASCII码,如图下所示。

文本流形式与字符一一对应,因而便于对字符进行逐个处理,也便于输出显示,但一般占用较多的内存空间,且花费较多的转化时间(二进制形式与编码之间的转换)。需要注意的是,在Java中使用的是Unicode编码,这是一种定长编码,每个字符都是2字节,因此在存储ASCII码时会额外浪费一个字节的空间。
而用二进制形式输出数值,可以节省外存空间和转化时间,但一个字节并不对应一个字符,不能直接输出字符形式。两种形式各有其优缺点,一般来讲,对于纯文本信息(比如说字符串),以文本形式存储较佳;而对于数值信息,则用二进制形式较好。
I/O流的优势在于简单易用,缺点是效率较低。Java的I/O流提供了读写数据的标准方法。Java语言中定义了许多类专门负责各种方式的输入/输出,这些类都被放在java.io包中。在Java类库中,有关I/O操作的内容非常庞大:有标准输入/输出、文件的操作、网络上的数据流、字符串流和对象流等。
文件操作类——File
尽管包java.io中定义的大多数类是对数据实施流式操作的,但File类例外,它用于处理文件和文件系统。也就是说,File类没有指定数据怎样从文件读取或向文件存储,它仅仅描述了文件本身的属性。
在java.io包之中,File类是唯一一个与文件本身有关的操作类。它定义了一些与平台无关的方法来操作文件,通过调用File类提供的各种方法,能够完成创建、删除文件,重命名文件,判断文件的读写权限及文件是否存在,设置和查询文件创建时间、权限等操作。File类除了对文件操作外,还可以将目录当作文件进行处理——Java中的目录当成File对象对待。
如果要想使用File类进行操作,那么就必须设置一个要操作文件的路径。下面的3个构造方法可以用来生成File对象。

在这里,“directoryPath”表示的是文件的路径名,filename 是文件名,而dirObj 是一个指定目录的File对象。
下面的例子分别用上面的3个构造方法创建了三个文件对象:F1,F2和F3。对象F1是由仅有一个目录路径参数的构造方法生成的。F2是由两个参数——路径和文件名的构造方法生成的。第三个File对象F3的参数包括指向文件F1的路径及文件名。事实上,F3和F2指向相同的文件——在根目录(/)下的文件abc.txt。

Java 能正确处理UNIX和Windows/DOS约定路径分隔符。如果在Windows版本的Java下用斜线(/),路径处理依然正确。请注意:如果在Windows/DOS下使用反斜线(\)来作为路径分隔符,那么就需要在字符串内使用它的转义序列(即两个反斜线“\”)。Java约定是用UNIX和URL风格的斜线“/”来作路径分隔符。
File类中定义了很多获取File对象标准属性的方法。例如getName( )用于返回文件名,getParent( )返回父目录名;exists( )方法在文件存在的情况下返回true,反之返回false。但File类的方法是不对称的,意思是说虽然存在可以验证一个简单文件对象属性的很多方法,但是没有相应的方法来改变这些属性。下表给出了部分常用的File类方法。

下面的例子演示了File类的几个方法的使用。
File方法的使用(FileDemo.java)。




第06行,调用File的构造方法来创建一个File类对象f。其中第06行中路径的分隔符用两个“\”表示转义字符,这一句完全可用下面的语句代替。

07~17行来判断文件是否已经存在,若已经存在,则删除之。如果不存在,则创建之,为了防止创建过程中发生意外,用了try-catch块来捕获异常。18~42行对文件的属性进行了操作,注释部分已经非常清楚地解释了。
在File类中还有许多的方法,读者没有必要去死记这些用法,只要记住在需要的时候去查Java的API手册就可以了。
File类只能对文件进行一些简单操作,如读取文件的属性以及创建、删除和更名等,但并不支持文件内容的读/写。如果想对文件进行实施读写操作,就必须通过输入/输出流来达到这一目的。
以上的程序完成了文件的基本操作,但是在本操作之中可以发现如下的问题。
问题一:在进行操作的时候出现了延迟,因为文件的管理肯定还是由操作系统完成的,那么程序通过JVM(Java虚拟机)与操作系统进行操作,多了一层操作,所以势必会产生一定的延迟。
问题二:在Windows之中路径的分隔符使用“\”,而在Linux中分隔符使用“/”,而现在Java程序如果要想让其具备可移植性,就必须考虑分隔符的问题,所以为了解决这样的困难,在File类中提供了一个常量:public static final Stringseparator。

在日后的开发之中,只要遇见路径分隔符的问题,都可用separator常量来解决。
问题三:以上的程序是直接在d盘的根路径下创建的新文件,如果说现在有目录的时候就发现无法直接创建文件了,因为文件目录不存在,要想创建文件之前首先要先创建目录。
创建一级目录:public boolean mkdir();
创建多级目录:public boolean mkdirs();
而如果要想创建目录应该是根据给定路径的父路径才可以创建,所以要想取得父路径可以使用如下方法。
取得父路径:public File getParentFile();
代码如下所示。

除了以上文件的基本操作之外,在File类之中也提供了一些取得文件信息的方法,如下所示。
⑴ 判断路径是否是文件:public boolean isFile()。
⑵ 判断路径是否是文件夹:public boolean isDirectory()。
⑶ 文件大小:public long length()。
⑷ 取得文件的最后一次修改日期:public long lastModified()。
RandomAccessFile类
除了File类之外,Java还提供了专门处理文件的类,即RandomAccessFile(随机访问文件)类。该类是Java语言中功能最为丰富的文件访问类,它提供了众多的文件访问方法。RandomAccessFile类支持“随机访问”方式,这里“随机”是指可以跳转到文件的任意位置处读写数据。在访问一个文件的时候,不必把文件从头读到尾,而是希望像访问一个数据库一样“随心所欲”地访问一个文件的某个部分,这时使用RandomAccessFile类就是最佳选择。
RandomAccessFile对象类有个位置指示器,指向当前读写处的位置,当读写n个字节后,文件指示器将指向这n个字节后面的下一个字节处。刚打开文件时,文件指示器指向文件的开头处,可以移动文件指示器到新的位置,随后的读写操作将从新的位置开始。RandomAccessFile类在数据等长记录格式文件的随机(相对顺序而言)读取时有很大的优势,但该类仅限于操作文件,不能访问其他的IO设备,如网络、内存映像等。RandomAccessFile类的构造方法如下所示。

这两个构造方法均涉及到一个String类型的参数mode,它决定随机存储文件流的操作模式,下表列出了mode的值及对应的含义。

有关RandomAccessFile类中的成员方法及使用说明请读者参阅Java的JDK开放文档(http://docs.oracle.com/javase/8/docs/api/index.html)。下 面 是 一 个使 用 RandomAccessFile 的 例子,往文件中写入3名员工的信息,然后按照第2名员工、第1名员工、第3名员工的先后顺序读出。RandomAccessFile可以以只读或读写方式打开文件,具体使用哪种方式取决于用户创建RandomAccessFile类对象的构造方法。

提示
当程序需要以读写的方式打开一个文件时,如果这个文件不存在,程序会自动创建此文件。
这里还需要设计一个类来封装员工信息。一个员工信息就是文件中的一条记录,而且必须保证每条记录在文件中的大小相同,也就是每个员工的姓名字段在文件中的长度是一样的,这样才能够准确定位每条记录在文件中的具体位置。假设name中有8个字符,少于8个则补空格(这里用"\u0000"),多于8个则去掉后面多余的部分。由于年龄是整型数,所以不管这个数有多大,只要它不超过整型数的范围,在内存中都是占4个字节大小。
员工信息类的使用(RandomFileDemo.java)。




本程序完成了所要实现的功能,显示出了RandomAccessFile类的作用。
其中43~61行是一个辅助类Employee,用以描述雇员的数据结构。第06~08行定义了3个Employee类对象e1、e2和e3。第09行定义了RandomAccessFile对象ra,它以可读可写“rw”的模式在D盘打开一个名为“employee.txt”的文件。
在第10行中,e1对象中成员name为String类型,String类的getBytes()方法是得到一个系统默认的编码格式的字节数组。在第16行,当一个流完成工作后,一个良好的习惯就是用close()方法将其关闭。代码第17行,重新开启一个流raf,它以只读模式来访问文件“employee.txt”。
代码第19行,使用skipBytes()方法是在文件中跳过给定数量的字节(这里是12个字节)。这个方法以当前的文件指针为基点,其跳转的距离是相对于当前位置。对于第1个员工的信息,其姓名占8字节,年龄占4字节,共计12个字节。
需要注意的是,seek(long n)方法也能完成定位文件指针在文件中的位置。参数n确定读写位置距离文件开头的字节个数,比如seek(0)就是定位文件指针在开始位置。这里的n是从文件开头开始的一个是绝对定位距离。
第52行出现的String.substring(int beginIndex,int endIndex)方法,可以用于取出一个字符串中的部分子字符串,但要注意的一个细节是:第一个int类型的参数beginIndex为开始的索引,对应String数字中的开始位置;第二个参数endIndex是截止的索引位置,对应String中的结束位置。取得的字符串长度为:endIndex -beginIndex。子字符串中的第1个字符对应的是原字符串中的脚标为beginIndex处的字符,但最后的字符对应的是原字符串中的脚标为endIndex-1处的字符,而不是endIndex处的字符。
字节流与字符流
尽管可以使用File进行文件的操作,但是如果要进行文件内容的操作,在Java之中就必须通过两类流操作完成。Java的流操作分为字节流和字符流两种。字符流处理的对象单元是Unicode字符,每个Unicode字符占据2个字节,而字节流输入输出的数据是以单个字节(Byte)为读写单位。这种流操作方式给操作一些双字节字符带来了困难。字符流是由Java虚拟机将单个字节转化为2个字节的Unicode字符,所以它对多国语言支持较好。
要将一段二进制数据,如音频、视频及图像等,写入某个设备,或者从某个设备中读取一段二进制数据,我们需要使用字节流操作进行读写则更加方便。但如果我们操作的对象是一段文本,则使用字节流进行操作,读取时需将文本以字节流的方式读入,如果要将字节显示为字符,就需要使用字节和字符之间的转换。运用面向对象的思想,我们需要一个直接用于操作文本数据的I/O类——字符流。字符流将字节流进行包装,接受字符串输入,并在底层将字符转换为字节。
Java 的流式输入/输出建立在4个抽象类的基础上:InputStream、OutputStream、Reader和Writer。它们用来创建具体的流式子类。尽管程序通过具体子类进行输入/输出操作,但顶层的类定义了所有流类的通用基本功能。
InputStream 和OutputStream被设计成字节流类,而Reader 和Writer 则被设计成字符流类。字节流类和字符流类形成分离的层次结构。通常来说,处理字符或字符串时应使用字符流类,处理字节或二进制对象时应使用字节流类。
一般在操作文件流时,不管是字节流还是字符流,都可以按照如下的流程进行。
使用File类找到一个要操作的文件路径;
通过File类的对象去实例化字节流或字符流的子类;
进行字节(字符)的读/写操作;
IO流属于资源操作,操作的最后必须关闭。
字节流类为处理字节式输入/输出提供了丰富的环境。一个字节流可以与其他任何类型的对象并用,包括二进制数据。这样的多功能性使得字节流对很多类型的程序都很重要。
字节流包含两个顶层抽象类:InputStream和OutputStream。所有的读操作都继承自一个公共超类java.io.InputStream类。所有的写操作都继承自一个公共超类java.io.OutputStream类。这两个抽象类都由不同的子类来具体实现某项“个性化”的功能,完成不同类型设备的输入和输出。下表列出常用的字节流名称及对应功能的简单介绍。

字节输出流——OutputStream
下面我们就从字节输出流OutputStream开始讨论。如果要通过程序输出内容到文件中,则必须使用OutputStream类完成, 它是一个抽象类,它定义了流式字节输出模式,该类的所有方法返回一个void 值,并且在出错的情况下,会抛出一个IOException异常。这个类的定义如下。

可以发现OutputStream类之中实现了两个接口,这两个接口定义如下。

一般而言,很少去关心Closeable和Flushable两个接口,因为OutputStream类是在JDK 1.0的时候就定义的,而上面的两个接口是在JDK 1.5的时候才定义的,人们所关心的不是这两个接口,而是直接观察OutputStream类中定义的方法,下表中显示了OutputStream的方法。

提示
上表中的多数方法由OutputStream的子类来实现。下面以其子类FileOutputStream为例来讨论这些方法的使用和不使用的情况。
对于OutputStream类而言,其本身是一个抽象类,按照面向对象的概念来解释的话,对于抽象类要想实例化必须通过子类完成,如果说现在要操作的是文件的输出,则可以使用子类FileOutputStream类完成。FileOutputStream 创建了一个可以向文件写入字节的类OutputStream,它常用的构造方法如下所示。

如果发生打开文件失败等意外,它们都可以引发IOException或SecurityException异常。在这里, filePath是文件的绝对路径,fileObj是描述该文件的File对象。如果参数append为true,文件则是以设置搜索路径模式打开,在原有文件基础上追加数据。FileOutputStream的创建不依赖于文件是否存在。在创建对象时,FileOutputStream会在打开输出文件之前就创建它。在这种情况下如果试图打开一个只读文件,则会引发一个IOException异常。
字节输入流——InputStream
InputStream 是一个定义了Java流式字节输入模式的抽象类,该类的所有方法在出错时都会引发一个IOException 异常。下表中显示了InputStream的方法。

FileInputStream 类创建一个能从文件读取字节的InputStream 类,它的两个常用的构造方法如下。

这两个构造方法都能引发FileNotFoundException异常。在这里filepath 是文件的绝对路径,fileObj是描述该文件的File对象。
下面的例子创建了两个使用同样磁盘文件且各含一个上面所描述的构造方法的FileInputStream类。

尽管第1个构造方法可能更常用到,但第2个构造方法可允许在把文件赋给输入流之前用File方法更进一步检查文件。当一个FileInputStream被创建时,它可被公开读取。
在下面的综合例子中,首先用FileOutputStream类向文件中写入一个字符串,然后用FileInputStream读出写入的内容。
下面以InputStream 的子类FileInputStream(文件输入流)为例说明上述部分方法的使用。
向文件中写入字符串并读出(StreamDemo.java)。



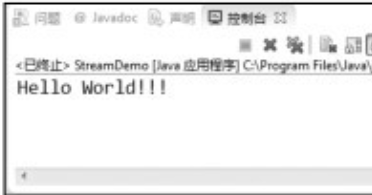

由于要用到OutputStream和InputStream及其子类,同时要用到异常处理的部分类,所以在第02~08行导入相应的类库。事实上,为了“偷懒”起见,可用代码的第01行代替02~08行的功能。“import java.io.”中的“”是通配符,此处代表的是与I/O操作的所有包库。“偷懒”(使用通配符)的代价是,把不需要的包库也导入了—有“浪费之嫌”。
其后的程序分为两个部分,一部分是向文件中写入内容(第12~32行),另一部分是从文件中读取内容(第34~55行)。
⑴ 第12行通过创建一个File类对象f,找到D盘下的一个temp.txt文件,如果没有这个文件,则新创建之。
⑵ 向文件写入内容。
① 第13~ 19行通过File类的对象f作为参数创建OutputStream的对象out(13行),然后再通过新创建子类FileOutputStream来实例化这个OutputStream对象out(15行),这属于对象的向上类型转型。
② 因为字节流主要以操作byte数组为主,所以第21行通过String类中的getBytes()方法,将字符串转换成一个byte数组。需要注意的是,在Java里,一切皆为对象,字符串“Hello World!!!”也是一个字符串对象,所以它也有相应的方法可用,使用一个对象的方法的格式是:“对面名.方法”。这里getBytes()方法的对象就是字符串“Hello World!!!”。
③ 第22~27行调用OutputStream类中的write()方法,将byte数组中的内容写入到文件中。
④ 第28~32行调用OutputStream类中的close()方法,关闭数据流操作。
⑶ 从文件中读入内容。
① 第34~ 39行通过File类的对象f来作为参数,创建InputStream的对象in(36行),然后通过新创建的子类FileInputStream对象,来实例化这个InputStream对象in,这里属于对象的向上类型转型。
② 因为字节流主要以操作byte数组为主,所以第41行声明了一个1024大小的字节(byte)数组,此数组用于存放读入的数据。
③ 第43~48行调用InputStream类中的read()方法将文件中的内容读入到byte数组中,同时返回读入数据的个数。
④ 第49~53行调用InputStream类中的close()方法,关闭数据流操作。
⑤ 第55行将byte数组转成字符串输出。
从本范例中可以看到,大部分的方法操作时都进行了异常处理,这是因为所使用的方法处都用try-catch关键字进行I/O异常捕捉。不清楚的读者可以查找JDK文档,届时相信就可以明白了。
还有一点需要读者注意,Java中,变量的使用都遵循一个原则:先定义,并初始化后,才可以使用。但有时,在我们定义一个引用类型变量时,并无法给出一个确定的值,这时,我们可以先给变量指定一个null值。
在Java中,null常用来标识一个不确定的对象。因此可将null赋给引用类型变量,但不可以将null赋给基本类型变量。
比如:int a = null;是错误的。
Ojbect o = null是正确的。
程序的第13行和34行,均使用了null来初始化out和in这两个对象。随后,这两个对象才被真正有意义地赋值(分别参见第行15和第36行)。学习过C/C++的读者,可以将null理解为C/C++中的NULL(必须大写),即空指针。
字符输出流——Writer
尽管字节流提供了处理任何类型输入/输出操作的足够的功能,但它们不能直接操作Unicode字符。既然Java的一个主要目标是支持“一次编写,处处运行”,那么支持多国语言字符的直接输入/输出是必要的。在这个方面上,Java中的Writer类有着重要的支撑作用。下面将从Writer抽象类开始,介绍字符输出流及其相关子类的一些方法。
Writer 是定义流式字符输出的抽象类,所有该类的方法都返回一个void 值并在出错的条件下引发IOException 异常。表中给出了Writer类中方法。

下面来说明Writer抽象类的子类FileWriter的一些特性。
FileWriter 创建一个可以写文件的Writer 类。它最常用的3个构造方法如下所示。

它们可以引发IOException或SecurityException异常。在这里fileName是包括文件名的绝对路径, ile是描述该文件的File类的对象。如果布尔类型的append为true,则输出的内容附加到文件尾的。FileWriter类的创建不依赖于文件存在与否。在创建文件之前,FileWriter将在创建对象时打开它来作为输出。如果试图打开一个只读文件,将引发一个IOException异常。
字符输入流——Reader
Reader是定义Java的流式字符输入模式的抽象类。Reader是专门进行输入数据的字符操作流,这个类的定义如下。

在Reader类之中也定义了若干个读取数据的方法,该类的所有方法在出错的情况下都将引发IOException 异常。下表中给出了Reader类中的主要方法。

由于Reader类是抽象类,所以要通过文件读取时,肯定使用的是FileReader子类,FileReader子类创建了一个可读取文件内容的Reader类。它最常用的构造方法如下。

每一个构造方法在无法找到打开的文件时,都会引发一个FileNotFoundException异常。在这里filePath是一个文件的完整路径,fileObj是描述该文件的File对象。
下面的例子将【范例(StreamDemo.java)】进行改写,用字符流解决同样的问题,先来看一下代码。
字符流的使用(CharDemo.java)。



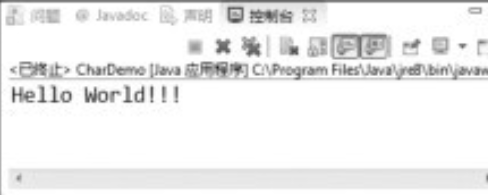
此程序与上面范例的程序类似,也同样分为两部分,一部分是向文件中写入内容(第06~23行),另一部分是从文件中读取内容(第26~45行)。
⑴ 第04行通过一个File类找到D盘下的一个temp.txt文件。
⑵ 向文件写入内容。
① 第05~07行通过File类的对象去实例化Writer的对象out,此时是通过其子类FileWriter实例化的Writer对象,属于对象的向上转型(第07行)。
② 因为字符流主要以操作字符为主,所以第12行声明了一个String类的对象str。
③ 第13~18行调用Writer类中的write()方法将字符串中的内容写入到文件中。
④ 第19~23行调用Writer类中的close()方法,关闭数据流操作。
⑶ 从文件中读入内容。
① 第26~31行通过File类的对象去实例化Reader的对象,此时是通过其子类FileReader实例化的Reader对象,属于对象的向上转型。
② 因为字节流主要以操作char数组为主,所以第33行声明了一个1024大小的char数组,此数组用于存放读入的数据。
③ 第34~40行调用Reader类中的read()方法将文件中的内容读入到char数组中,同时返回读入数据的个数。
④ 第41~45行调用Reader类中的close()方法,关闭数据流操作。
⑤ 第47行将char数组转成字符串输出。
提示
读者可以将范例CharDemo中的第19~23行注释掉,也就是说在向文件写入内容之后不关闭文件,然后直接打开文件,可以发现文件中没有任何内容,这是为什么?从JDK文档之中查找FileWriter类,如下图所示。

由上图可以看到,FileWriter类并不是直接继承自Writer类,而是继承了Writer的子类(OutputStreamWriter),此类为字节流和字符流的转换类,后面会介绍。也就是说真正从文件中读取进来的数据还是字节,只是在内存中将字节转换成了字符。
第20行的“out.close()”的“关闭字符流”功能,可以完成将内存缓冲区的转换好的字符流,刷新输出至(外存储器的)文件中。
由上面的两个例程,可得出一个结论:字符流的操作多了一个中间环节—用到了缓冲区,而字节流没有用到缓冲区,直接对文件“实时”操作。另外,也可以用Writer类中的flush()方法强制清空缓冲区,也就是说,将第20行换成“out.flush();”,也可以保证D盘的“temp.txt”有输出的数据。
字节流与字符流的转换
前面已经讲过,对于数据操作,Java支持字节流和字符流,但有时需要在字节流和字符流之间转换。为此,有两个类:
⑴ 字节输入流变为字符输入流:InputStreamReader;
⑵ 字节输出流变为字符输出流:OutputStreamWriter。
InputStreamReader用于将一个字节流中的字节解码成字符,OutputStreamWriter用于将写入的字符编码成字节后写入一个字节流。
InputStreamReader有两个主要的构造方法。

OutputStreamWriter也有对应的两个主要的构造方法。

为了达到较高的转换效率,避免频繁地进行字符与字节间的相互转换,建议最好不要直接使用这两个类来进行读写,而应尽量使用BufferedWriter类包装OutputStreamWriter类,用BufferedReader类包装InputStreamReader类。

然后,从一个实际的应用中来了解InputStreamReader的作用。怎样用一种简单的方式一下子就读取到键盘上输入的一整行字符呢?只要用下面的两行程序代码就可以解决这个问题。

可见,构建BufferedReader对象时,必须传递一个Reader类型的对象作为参数,而键盘对应的System.in是一个InputStream类型的对象,所以这里需要用到一个InputStreamReader的转换类,将System.in转换成字符流之后,放入到字符流缓冲区之中,之后从缓冲区中每次读入一行数据。

下面用范例来说明这一应用流程。
字节流与字符流的转换使用(代码BufferDemo.java)。



第6行和第7行对BufferedReader对象实例化。因为现在需要从键盘输入数据,因此需要使用System.in进行实例化,但System.in是属于InputStream类型,所以使用InputStreamReader类将字节流转换成字符流,之后将字符流放入到BufferedReader中。
第14行通过BufferedReader类中的readLine()方法,等待键盘的输入数据。
第22行通过Integer类将输入的字符串转换成基本数据类型中的整型。
第23行将输入的数字进行加1操作。
第24行输出修改后的数据。
管道流
在UNIX/Linux中有一个很有用的概念——管道(pipe),它具有将一个程序的输出当作另一个程序的输入的能力。在Java中,它的 I/O系统建立在数据流概念之上,也可以使用“管道”流进行线程之间的通信,在这个机制中,输入流和输出流必须相连接,这样的通信有别于一般的共享数据(Shared Data)缓冲区通信,其不需要一个共享的数据空间。
管道流主要用于连接两个线程间的通信。管道流也分为字节流(PipedInputStream、PipedOutputStream)与字符流(PipedReader、PipedWriter)两种类型,本小节主要讲解管道输入流(PipedInputStream)和管道输出流(PipedOutputStream)。
一个PipedInputStream对象必须和一个PipedOutputStream对象进行连接而产生一个通信管道, PipedOutputStream可以向管道中写入数据,PipedInputStream可以从管道中读取PipedOutputStream写入的数据。如下图所示,这两个类主要用来完成线程之间的通信,一个线程的PipedInputStream对象能够从另外一个线程的PipedOutputStream对象中读取数据。

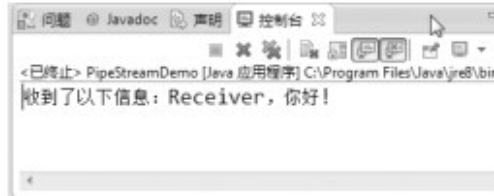
管道流的使用(PipeStreamDemo.java)。



第18~30行声明了一个Sender类,此类继承自Thread类,所以此类覆写了Runnable接口之中的run()方法。第19行声明了一个PipedOutputStream对象out,此对象用于发送信息。
第32~46行声明了一个Receiver类,此类继承自Thread类,所以此类覆写了Runnable接口之中的run()方法。第34行声明了一个PipedInputStream对象in,此对象用于接收其他线程发来的信息。
第05行和第06行分别声明了Sender和Receiver的实例化对象,之后,在第07和08行分别调用sender.getOutputStream()和receiver.getInputStream()方法,返回各自的管道输出流out及管道输入流对象in,在第09行,通过调用管道输出流对象out的connect()方法,将两个管道连接在一起,之后第10和第11行,分别通过start()方法启动线程。
在Sender的run()方法中:在第22行,创建字符串对象s,其内容为"Receiver,你好!"。第24行通过调用getBytes()方法,将s对象中的字符串转换为字节数组,然后将其作为out对象的writer方法的参数,也就是将"Receiver,你好!"字节数组写入到管道。
在Receiver的run()方法中:在第39行中,通过对象in的read()方法,将管道中的数据读取至字节数组buf中,然后在第40行中,将字节数组转换为一个字符串对象s,最后在第41行输出该字符串对象。
从而达到如下目的:将写入到PipedOutputStream输出流的数据,可从对应的PipedInputStream输入流读取。
此外,注意到第37行,声明的字节数组大小为1024,其实这是有讲究的:类PipedInputStream运用的是一个1024字节固定大小的循环缓冲区。实际上,写入PipedOutputStream的数据保存到对应的 PipedInputStream的内部缓冲区。如果对应的 PipedInputStream输入缓冲区已满,再次企图写入PipedOutputStream的线程都将被阻塞,直至出现读取PipedInputStream的操作从缓冲区删除数据。
内存操作流
前面学习的输入和输入流的数据均来自于文件。事实上,如果程序在运行的过程中要产生一些临时文件,可以采用虚拟文件方式实现,Java提供了内存流机制,可以实现类似于内存虚拟文件的功能。
这样,我们既可以从内存中获取数据,也向内存中写入数据,也就是说,可以将内存作为数据的来源和目的地。内存操作流就是实现向内存中读取和写入数据的流类。
内存操作流一共也分为两组:
⑴ 字节内存操作流:ByteArrayOutputStream、ByteArrayInputStream;
⑵ 字符内存操作流:CharArrayWriter、CharArrayReader。
在学习内存操作流之前,有亮点需要读者注意:
⑴ 注意一:不管是文件流还是内存流依然要满足向上转型的要求,都要使用到父类方法;
⑵ 注意二:关于两者的操作形式不同(数据的来源和目的地不同):

对于字节内存操作流而言,ByteArrayInputStream主要完成将数据写入到内存之中,而ByteArrayOutputStream的功能则是将内存中的数据输出。此时,内存作为数据的操作点,如下图所示。

ByteArrayInputStream是输入流(InputStream)的一种子类实现。

它有两个构造方法,每个构造方法都需要一个字节byte数组来作为其数据源。

类似地,ByteArrayOutputStream是输出流(OutputStream)的一种子类实现,其继承体系如下所示。

ByteArrayOutputStream类也有两个构造方法。

在上述的两个构造方法中,前者没有参数,它仅仅在内存当中创建一个字节数组输出流,而后者带参数size,表明在内存当中创建一个指定大小的字节数组输出流。
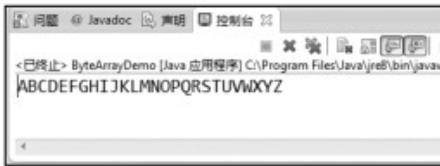
字节流类的使用(ByteArrayDemo.java)。


第05行,创建一个字符串对象tmp,其值为“abcdefghijklmnopqrstuvwxyz”。第06行,调用tmp的getBytes()方法,将tmp转换为字节数组,并将其赋值给字节数组src,这样做的原因是,内存流操作的对象,就是字节数组。第07行,创建一个ByteArrayInputStream对象input,其中src作为其构造方法的参数。
第09行,先创建一个无名ByteArrayDemo()对象,然后调用其自定义的方法transform()来完成字节流的转换。在方法transform()中(第13~28行),第18行,每次通过read()方法读取一个字符,并赋值给c,直到c为-1为止,read()方法在读到流的结尾处返回-1。第20行,调用Character类中的静态方法toUpperCase(),将字符参数转换为大写。第21行,调用write()方法,将C中对应的大写字符输出。
在本范例中,实施I/O操作的同时,并没有任何的文件产生,所以也可以把这种基于内存的操作理解为操作临时文件。这种代码在现阶段之中使用较少,但如果读者日后学习到了AJAX(一种与服务器交换数据并更新部分网页的技术) + XML(一种可扩展标记语言)操作时就会使用。
打印流
在实际应用过程中,有时我们需要打印数据类型的值。打印流为其他输出流增强了功能,使它们能够方便地打印各种数据值表示形式。
输出问题的提出
如果我们要想进行数据的输出,首先想到的就是要使用OutputStream类,但这个类在进行输出数据的时候并不是十分方便。OutputStream类之中所提供的write()方法只适合输出字节数组,但如果要求输出字符、数字、日期,OutputStream类就不能很方便地胜任工作了,那么此时该如何解决这个问题?
在Java的I/O包中,打印流是一个输出信息最方便的流类,它可以将原样输出各种类型的类型。除了输出数据,打印流还提供两项其他功能:⑴ 与其他输出流不同的是,打印流的方法不会抛出IOException,其异常情况仅设置内部标志位, 这些标志位可通过checkError() 方法来读取。⑵ 打印流具有自动刷新的功能。例如,当写入字节数组时,flush()方法会被自动调用。
打印流的使用
为了简化输出的操作难度,在Java中提供了两种打印流:PrintStream(字节打印流)和PrintWriter (字符打印流)。
下面首先以PrintStream类为例进行分析,观察PrintStream类的继承结构。
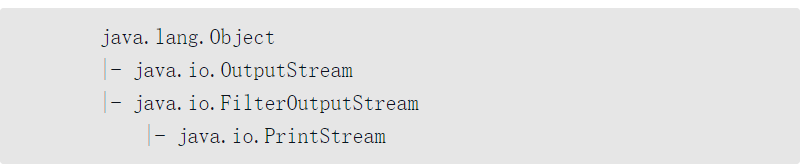
对于打印流而言,它所使用的设计模式称为装饰设计模式,即将一个设计不是非常完善的功能,添加一些代码之后变得完善起来。
PrintStream类提供了一系列的print和println方法,可以实现将基本数据类型的格式转换成字符串输出。在前面的程序中大量用到的“System.out.println”语句中的System.out,就是PrintStream类的一个实例对象。PrintStream有下面几个构造方法。

其中autoflush控制在Java中遇到换行符(\n)时是否自动清空缓冲区,encoding是指定编码方式。关于编码方式,将在文章后面介绍。
println方法与print方法的区别是:前者会在打印完的内容后面再多打印一个换行符(\n),所以println()等于print("\n")。
Java的PrintStream对象具有多个重载的print和println方法,它们可输出各种类型(包括Object)的数据。对于基本数据类型的数据,print和println方法会先将它们转换成字符串的形式,然后再输出,而不是输出原始的字节内容,如整数221的打印结果是字符“2”、“2”、“1”所组合成的一个字符串,而不是整数221在内存中的原始字节数据。对于一个非基本数据类型的对象,print和println方法会先调用对象的toString方法,然后输出toString方法所返回的字符串。
在Java的I/O包中,提供了一个与PrintStream对应的PrintWriter类,PrintWriter类有下列几个构造方法。

PrintWriter即使遇到换行符(\n)也不会自动清空缓冲区,只在设置了autoflush模式下使用了println方法后才会自动清空缓冲区。PrintWriter相对PrintStream最便利的一个地方就是println方法的行为,在Windows下的文本换行是“\r\n”,而在Linux下的文本换行是“\n”。如果希望程序能够生成平台相关的文本换行,而不是在各种平台下都用“\n”作为文本换行,那么就应该使用PrintWriter的println方法,PrintWriter的println方法能根据不同的操作系统而生成相应的换行符。
下面的范例通过PrintWriter类向屏幕上打印信息。
PrintWriter类向屏幕输出信息(SystemPrintDemo.java)。

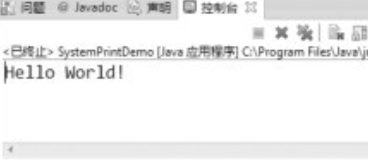
第08行通过System.out实例化PrintWriter,此时PrintWriter类的实例化对象out就具备了向屏幕输出信息的能力,所以在第10行调用print()方法时,就会将内容打印到屏幕上。
下面的范例通过PrintWriter向文件中打印信息。
通过PrintWriter向文件中输出信息(FilePrint.java)


第07行,我们先实例化一个File类对象f。f对应D盘的一个文件temp.txt。需要注意的是,由于安全权限的限制,有时在Windows下的C盘通过程序创建一个文件,是不被允许的,这时会发生一个异常中断。
第10行通过FileWriter类实例化PrintWriter,此时PrintWriter类的实例化对象out就具备了向文件输出信息的能力,所以在第17行调用print()方法时,就会将内容输出到文件之中。
在之前一直使用过的print()、println()这些“耳熟能详”的方法在打印流这里找到“根据地”了,这里我们可以得出一个初步的结论:如果由程序向一个终端输出数据时,一定要使用打印流。
打印流的更新
打印流能够方便地执行输出,为了使输出的格式更加的整洁,在JDK1.5之后,对打印流进行了更新,可以使用格式化输出。即类似C语言中的printf()函数。提供了以下的方法。
Public PrintStream printf(String format,Object… args)
可以设置格式和多个参数。在使用此方法的时候需要使用一些占位标记:字符串(%s)、整数(%d)、小数(%f)、字符(%c)等。
下面通过范例来说明Java中格式化输出的用法。
打印流格式化输出(PrintFormat.java)。




第04~16行,演示了字符串的多种格式输出。第18~26行,演示了整数的多种格式的输出。在第13行中,System.out.printf()方法支持多个参数时,可在%s之间插入变量编号,1
表
示
第
1
个
字
符
串
,
2
表示第1个字符串, 2
表示第1个字符串,2表示第2个字符串,以此类推。第28行到36行,演示了浮点数的多种格式的输出。具体的使用方法在注释中已经详细说明,这里就不再赘述了。
合并(序列)流
SequenceInputStream类可以将多个输入流按顺序连接起来。SequenceInputStream的构造方法是使用一对输入流或者一个输入流的枚举(内含多个输入流)作为参数。

SequenceInputStream类中的主要方法如下表所示。

采用SequenceInputStream类,可以实现多个文件的合并操作。下图所示为两个文件的合并示意图。

使用合并流将两个文件合并(SequenceDemo.java)





第05行,声明了两个文件读入流对象in1和in2,并初始化为null。第07行,声明了一个序列(合并)流s。第08行,声明了一个文件输出流对象out。第11~12行分别构造两个被读入的文件“D:\1. txt”D:\2.txt,第14行构造一个输出文件“D:\12.txt”。这里有两处需要读者注意:
⑴ 在File类中提供了一个常量—路径分隔符:separator,它在Windows中,自动替换为“\”,而在Linux中自动替换为“/”,从而在某种程度上提高了Java程序可移植性。推荐读者用这种方式来处理路径的分隔符。
⑵ 上述提到的文件1.txt、2.txt和12.txt,必须是事先已经存在的,否则会发生异常“java. io.FileNotFoundException”。文件1.txt、2.txt中的数据也是事先写入的,12.txt程序运行前是空文件,运行后为上图右下所示。如果想实现用File类打开某个文件,如果该文件存在,则打开之,如果不存在,则创建之,可以参看【范例(FileDemo.java)】的第06~17行代码。
第20行,将in1和in2这两个输入流合为一个输入流s。第21行,声明了一个文件输出流out。第24行,用了一个while循环,将合并的输入流s中的字节,利用read()方法,逐个读出,并赋值为整型变量c。如果到达输入流的尾部,read()方法会返回-1。然后文件输出流对象out利用write()方法将读出的数据c逐一写入到对应的12.txt。
第31~49行,关闭in1、in2、s和out等流,这是为了防止意外,做了异常处理。
System类对I/O的支持
为了支持标准输入输出设备,Java定义了3个特殊的流对象常量:
错误输出:public static final PrintStream err;
系统输出:public static final PrintStream out;
系统输入:public static final InputStream in。
System.in通常对应键盘,属于InputStream类型,程序使用System.in可以读取从键盘上输入的数据。System.out通常对应显示器,属于PrintStream类型,PrintStream是OutputStream的一个子类,程序使用System.out可以将数据输出到显示器上。键盘可以被当做一个特殊的输入流,显示器可以被当做一个特殊的输出流。System.err则是专门用于输出系统错误的对象,它可视为特殊的System.out。按照Java原本的设计,System.err输出的错误是不希望用户看见的,而System.out的输出是希望用户看见的。
观察下面的程序段:

由于第05行,“abc”是一个字符串,不是Integer.parseInt()方法的合法参数,因此会抛出异常, 06行则是捕获这个异常,07和08行则是输出这两个异常信息,用Eclipse调试,得到如下所示的调试结果图,从图中可以发现,07和08行输出的结果是一样的。

字符编码
计算机里只有数字,计算机软件里的一切都是用数字来表示,屏幕上显示的一个个字符也不例外。最开始计算机是在美国使用,当时所用到的字符也就是现在键盘上的一些符号和少数几个特殊的符号,每一个字符都用一个数字来表示,一个字节所能表示的数字范围内(0~255)足以容纳所有的字符,实际上表示这些字符的数字的字节最高位(bit)都为0,也就是说这些数字都在0~127之间,如字符a对应数字97,字符b对应数字98等,这种字符与数字对应的编码固定下来后,这套编码规则被称为ASCII码(美国标准信息交换码),如下图所示。

随着计算机在其他国家的逐渐应用和普及,许多国家都把本地的字符集引入了计算机,这大大地扩展了计算机中字符的范围。一个字节所能表示的数字范围(仅仅256个字符)是不能容纳所有的中文汉字的(注:《汉语大字典》收字共54678个)。中国大陆将每一个中文字符都用两个字节的数字来表示(这样,在理论上,可以表示256×256=65536个汉字,够汉字用了!),在这个编码机制里,原有的ASCII码字符的编码保持不变,仍用一个字节表示。为了将一个中文字符与两个ASCII码字符相区别,中文字符的每个字节的最高位(bit)都为1,中国大陆为每一个中文字符都指定了一个对应的数字(由于两个字节的最高位都被占用,所以两个字节所能表示的汉字数量理论数为:27×27=16384,有些偏僻的汉字就没有被编码,从而计算机就无法显示和打印),并作为标准的编码固定了下来,这套编码规则称为GBK(国标扩展码,GBK就是“国标扩”的汉语拼音首字母),后来又在GBK的基础上对更多的中文字符(包括繁体)进行了编码,新的编码系统就是GB2312,而GBK则是GB 2312的子集(事实上,GB 2312 也仅仅收录 6763 个常用汉字,仅仅适用于简体中文字)。使用中文的国家和地区很多,同样的一个字符,如“中国”的“中”字,在中国大陆地区的编码是十六进制的D6D0,而在中国台湾地区的编码则是十六进制的A4A4,台湾地区对中文字符集的编码规则称为BIG5(大五码),如下图所示。

在一个国家的本地化系统中出现的一个字符,通过电子邮件传送到另外一个国家的本地化系统中,看到的就不是那个原始字符了,而是另外那个国家的一个字符或乱码。这是因为计算机里面并没有真正的字符,字符都是以数字的形式存在的,通过邮件传送一个字符,实际上传送的是这个字符对应的编码数字,同一个数字在不同的国家和地区代表的很可能是不同的符号。如十六进制的D6D0在中国大陆的本地化系统中显示为“中”这个符号,但在伊拉克的本地化系统中就不知道对应的是一个什么样的伊拉克字符了,反正人们看到的不是“中”这个符号。各个国家和地区都使用各自不同的本地化字符编码,这严重制约了国家和地区间在计算机使用和技术方面的交流。
为了解决各个国家和地区使用各自不同的本地化字符编码带来的不便,人们将全世界所有的符号进行了统一编码,称之为Unicode编码。所有的字符不再区分国家和地区,都是人类共有的符号,如“中国”的“中”这个符号,在全世界的任何一个角落始终对应的都是一个十六进制的数字4E2D。如果所有的计算机系统都使用这种编码方式,在中国大陆的本地化系统中显示的“中”这个符号,发送到德国的本地化系统中,显示的仍然是“中”这个符号,至于那个德国人能不能认识这个符号,就不是计算机所要解决的问题了。Unicode编码的字符都占用两个字节的大小,也就是说全世界所有的字符个数不会超过2的16次方(65536)。
Unicode一统天下的局面暂时还难以形成,在相当长的一段时期内,人们看到的都是本地化字符编码与Unicode编码共存的景象。既然本地化字符编码与Unicode编码共存,那就少不了涉及两者之间的转换问题,而Java中的字符使用的都是Unicode编码,Java技术在通过Unicode保证跨平台特性的前提下也支持了全扩展的本地平台字符集,而显示输出和键盘输入则都是采用的本地编码。
除了上面讲到的GB 2312/GBK和Unicode编码外,常见的编码方式还有:
ISO 8859-1编码:国际通用编码,单一字节编码,理论上可以表示出任意文字信息,但对双字节编码的中文表示,需要转码;
UTF编码:结合了ISO 8859-1和Unicode编码所产生的适合于现在网络传输的编码。考虑到Unicode编码不兼容ISO 8859-1编码,而且容易占用更多的空间:因为对于英文字母,Unicode也需要两个字节来表示。所以Unicode不便于传输和存储。因此而产生了UTF编码,UTF编码兼容ISO 8859-1编码,同时也可以用来表示所有语言的字符,但UTF编码是不等长编码,每一个字符的长度从1~6个字节不等。一般来讲,英文字母还是用一个字节表示,而汉字则使用三个字节。此外,UTF编码还自带了简单的校验功能。
那么清楚了编码之后,就需要来解释什么叫乱码:编码和解码不统一。那么如果要想在开发之中处理乱码,那么首先就需要知道在本机默认的编码是什么。通过下面的程序,来看一下到底什么是字符乱码问题。在这里使用String类中的get Bytes()方法,对字符进行编码转换。
字符编码使用范例1(EncodingDemo.java)。


对此程序读者应该非常清楚,但这里与之前稍有不同的是,在将字符串转换成byte数组的时候,用到了“GB2312”编码。
读到这里读者可能还是无法体会到字符编码问题,那么现在修改一下EncodingDemo程序,将字符编码转换成ISO8859-1,形成【范例(EncodingDemo.java)】,但在执行此程序之前,须先执行下面的【范例(SetDemo.java)】程序。

第05行通过System.getProperties()获取系统参数,该方法返回一个属性Properties对象,类Properties继承自Hashtable类,而Hashtable类用于put()方法。该方法的原型是put(K key, V value),其功能是在hash表中将特定的键值(key)映射为特定的值(value)。在这里,是将键file. encoding(文件编码)映射值为"GB2312"。
执行【范例(SetDemo.java)】程序之后,再运行【范例(EncodingDemo.java)】EncodingDemo.java程序,修改后的程序如下。


由上图可以看到,非英文部分的字符,输出结果出现了乱码,这是为什么?这就是本节要讨论的字符编码问题。之所以会产生这样的问题,是因为在运行这段代码之前,先运行了setDemo.java程序,此程序主要是用来设置JDK环境的编码问题,所以乱码问题主要是由于JDK设置环境所引起的,为什么呢?读者可以运行下面的程序,观察其输出就可以发现问题。
获得系统的属性(GetDemo.java)。

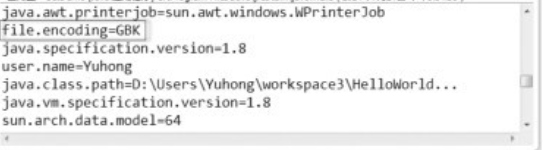
代码第06行,获取系统的属性,并用list()方法全部输出。从输出结果可以看到,在环境变量之中有一个file.encoding=GBK,这清楚地表明了所使用的是GBK编码,而修改过的【范例(EncodingDemo.java)。】EncodingDemo.java程序中的第7行如下。

在这里将字符串“大家一起来学Java语言”的编码换成了ISO8859-1编码。ISO8859-1 通常叫做Latin-1,属于单字节编码,最多能表示的字符范围是0~255,其适用于拉丁语系,很明显,ISO 8859-1编码表示的字符范围很窄,无法表示双字节编码的中文字符,所以就造成了【范例(EncodingDemo.java)。】里的中文字符的乱码问题。
对象序列化
有时我们需要保存对象,以便进一步地操作,这便用到了对象序列化。
对象序列化的基本概念
所谓的对象序列化(在某些书籍中也叫串行化),是指在内存之中保存的对象转化为二进制数据流的形式的一种操作。通过将对象序列化,可以方便地实现对象的传输及保存。但是在Java之中并不是所有的类的对象都可以被序列化,如果一个类对象需要被序列化,则此类一定要实现java. io.Serializable接口。但是这个接口里面也没有定义任何的方法,所以此接口依然属于标识接口,表示一种能力。
在Java中提供有ObjectlnputStream与ObjectOutputStream这两个类用于序列化对象的操作。这两个类是用于存储和读取对象的输入输出流类,不难想象,只要把对象中的所有成员变量都存储起来,就等于保存了这个对象,之后从保存的对象之中再将对象读取进来就可以继续使用此对象。ObjectInputStream与ObjectOutputStream类,用于帮助开发者完成保存和读取对象成员变量取值的过程,但要求读写或存储的对象必须实现了Serializable接口,但Serializable接口中没有定义任何方法,仅仅被用做一种标记,以被编译器做特殊处理。如下范例所示。
对象序列化使用范例1(Person.java)。

在第2行中,类Person实现了Serializable接口,所以此类所定义的对象就可被序列化。
对象输出流——ObjectOutputStream
虽然类已经实现了Serializable接口,但是如果要想真正地实现具体的序列化操作,则用户可以使用ObjectOutputStream类完成,这个类继承结构如下。

由上述类的继承关系,可以发现ObjectOutputStream是OutputStream子类,因为对象序列化之后为二进制数据,所以只能够依靠字节流操作,同时在ObjectOutputStream类中定义了以下两个方法。
⑴ 构造方法。public ObjectOutputStream(OutputStream out) throwsIOException;
⑵ 输出对象:public final void writeObject(Object obj) throws IOException;
ObjectOutputStream 用于将对象序列化,并保存。其操作如下。

ObjectOutputStream 接收一个OutputStream对象用于保存待序列化的对象。然后cout调用writeObject 方法保存对象。
对象输入流——ObjectInputStream
如果希望将已被序列化的对象再反序列化回来,则就可以通过ObjectInputStream类完成,它用于读取将序列化的对象。此类继承关系如下。
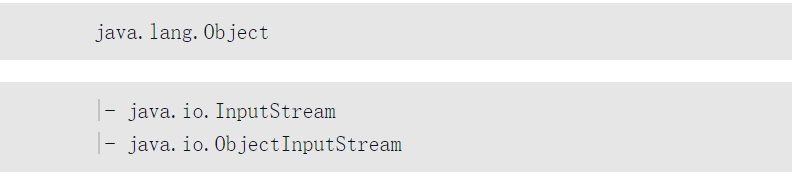
对于ObjectInputStream类之中主要使用的两个方法如下。
⑴ 构造方法。public ObjectInputStream(InputStream in) throwsIOException;
⑵ 对象输入:public final Object readObject() throws IOException,ClassNotFoundException;
实现对象的反序列化(读取对象)操作如下。

ObjectInputStream接收一个InputStream对象用于保存待序列化的对象。然后cin调用readObject方法读取序列化后的对象。在日后的实际开发之中,这些序列化和反序列化的功能会由相关的容器完成。
反序列化的基本概念
反序列化实际上就是使用ObjectInputStream 类创建对象将序列化后的对象读取出来,继续使用此对象。下面的例子结合ObjectInputStream 和OutputStream演示如何序列化对象和反序列化对象。
对象序列化使用范例2(SerializableDemo.java)



第09~14行声明了一个serialize()方法,此方法用于将对象保存在文件之中。第10行、第11行为ObjectOutputStream对象实例化,此对象是通过FileOutputStream对象实例化,所以此类在保存Person对象时,向文件中输出。
第16~22行声明了一个deserialize()方法,此方法用于从文件中读取已经保存的对象。第17行、第18行为ObjectInputStream对象实例化。第19行调用ObjectInputStream类中的readObject()方法,从文件中读入内容,之后将读入的内容转型为Person类的实例。第20行直接打印Person对象实例,在打印对象时,默认调用Person类中的toString()方法。
第26~35行,为【范例(Person.java)】代码,此处为了本例可以独立运行,如果【范例(Person.java)】和【范例(SerializableDemo.java)】同处于一个包(package)内,则本例的第26~35行可以忽略。
transient关键字
在默认情况下,当一个类对象序列化时,会将这个类中的全部属性都保存下来,如果不希望类中的某个属性被序列化(或某些属性不希望被保存,则可以在声明属性之前加上transient关键字。下面的代码修改自【范例(SerializableDemo.java)】,在声明属性时,前面多加了一个transient关键字。


从输出结果可以看到,Person类中的两个属性并没有被保存下来,输出时,是直接输出了这两个属性的默认值null和0。
Java 8 中有关流的新功能
1 Java.io.BufferedReader类中lines()方法。
该方法的原型为:

该方法返回一个Stream类型的对象,其中Stream的元素是从BufferedReader流中读出的多行字符串。下面是使用该方法的范例。
Java 8 BufferReader类中lines()方法的使用(LinesTest.java)。


首先需要说明的是,若想本例得以正确运行,需要有两个前提条件:⑴ 安装Java8的编译环境,这时在控制台模式下即可编译运行。但如果用Eclipse编译运行,还需要确保为Luna (Eclipse 4.4)及以上版本,如果是Kepler (Eclipse 4.2)版本,需要安装支持Java 8的补丁:在Eclipse的[Help]à [EclipseMarketplace]打开应用商店,搜索Java 8 Kepler,然后安装组建,安装完成后需要重启。⑵ 要确保在第10行指定的位置事先创建相应的文件,本例对应的文件在“D:\1.txt”,并含有多行数据。假设其文件内容如下图所示。

第10行中的File.separator 表示文件分隔符,在Windows系统里的值为“\”,在Unix/Linux系统的值为“/”。代码第11行创建输入流对象in。在代码第12行,首先创建字符流对象lines,然后用BufferedReader 对象in的lines()方法用于获取文件中的多行数据。第13行,用字符流对象lines的forEach方法输出每一行数据。第14行,关闭in流。
(2) java.nio.file.Files 类

该方法的作用与lines()方法类似,获取一个文件中的多行内容,并以List集合的方法返回。其中的参数path(java.nio.file.Path)指向的是一个路径,通过File类的toPath()方法可以得到一个这样的对象。下面的范例演示的是该方法的使用。
Files类中readAllLine()方法的使用(AllLinesTest.java)。


需要注意的是使用这个方法如果没有指定字符集,则默认为UTF-8,所以如果文件的编码格式不是UTF-8,则可能出现异常(编译无法通过)或乱码。此外,如果文件是UTF-8格式,在处理中文的时候,还会有部分乱码,如下图所示。

这时,需要将UTF-8格式转换成UTF-8 without BOM格式。BOM(Byte OrderMark)表示的是字节序标记。UTF- 8编码的文件中,BOM占三个字节。如果用记事本把一个文本文件另存为UTF-8编码方式的话,用十六进制文件编辑器(UtraEdit等)打开这个文件,切换到十六进制编辑状态就可以看到开头的FFFE标识。这个标识是用来区分UTF-8编码文件的好办法。上图中的问号”?”就是这个符号无法显示的乱码。
⑶ java.nio.file.Files 类

该方法的作用是按照深度优先遍历(traversed depth-first)的原则遍历由start作为根目录的文件结构树。并将遍历的结果存入Stream集合中返回,其中的每一个元素都是Path类型的文件路径。参数 maxDepth是表示遍历的最大深度,如果是0,表示只遍历根目录,即只返回start指定的根目录所对应的Path对象。如果想要遍历该文件结构中的所有层,则可以将maxDepth参数设置为 Integer.MAX_VALUE。参数options是一个FileVisitOption类型的值,该类型是枚举类型,仅有一个枚举值-FOLLOW_LINKS 。该参数是可选的。如果不填写该参数,那么在遍历到符号链接文件时不会进入其所链接的文件夹中。如果填写了该参数-FileVisitOption.FOLLOW_LINKS,在遍历到符号链接文件时会进入其所链接的文件夹中继续遍历。
该方法是用的范例如下。
Files类中walk()方法的使用(TestWalk.java)。


代码第15行,获取第12行创建的对象file所对应的根目录文件树中的所有文件。第12行中,路径中“./src”中“./”表示是当前目录,这是指TestWalk.java所在的路径。
在 JDK 1.8 中 同 时 提 供 了 一 个 public static Stream
提示
符号链接(symbolic link):符号链接又叫软连接,是一类特殊的文件,这个文件包含了另一个文件的路径名(绝对路径或者相对路径),路径可以是任意的文件或目录,可以链接到不同文件系统的文件。
链接符号的操作是透明的:对符号链接文件进行读写的程序会表现为直接对目标文件进行操作,某些需要特别处理符号链接文件的程序可能会识别链接文件。在Windows7 中创建链接文件的命令是:mklink , 具体的参数可以再DOS下输入mklink然后回车查看详细介绍。
在Java 8 中,还有很多新方法,如java.nio.file.Files 类 public staticStream
1. 使用缓冲流的作用
使用字节流对磁盘上的文件进行操作的时候,是按字节把文件从磁盘中读取到程序中来,或者是从程序写入到磁盘中。相比操作内存而言,操作磁盘的速度要慢很多。因此,我们可以考虑先把文件从硬盘读到内存里面,把它缓存起来,然后再使用一个缓冲流对内存里面的数据进行操作,这样就可以提高文件的读写速度。读者朋友可以同时比较InputStream与BufferedInputStream它们在速度上的差异,从而深入理解缓冲流的优势所在。此外,对文件的操作完成以后,不要忘了关闭流,否则会产生一些不可预测的问题。
2. 字节流和字符流的区别(面试题)
对于现在相同的功能发现有两组操作类可以使用,那么在开发中到底该使用哪种会更好呢?
关于字节流和字符流的选择没有一个明确的定义要求,但是有如下的选择参考:
⑴ Java最早提供的实际上只有字节流,而在JDK 1.1之后才增加了字符流;
⑵ 字符数据可以方便地进行中文的处理,但是字节数据处理起来会比较麻烦;
⑶ 在网络传输或者是进行数据保存的时候,数据操作单位都是字节,而不是字符;
⑷ 字节流和字符流在操作形式上都是类似的,只要一种流会使用了,其他的流都可以采用同样的方式完成;
⑸ 字节流操作时没有使用到缓冲区,字符流操作时需要缓冲区处理数据,字符流会在关闭的时候默认清空缓冲区,如果现在操作时没有关闭,则用户可以使用flush()方法手工清空缓冲区。
所以对于字节流和字符流的选择,我们建议:在开发中尽量都去使用字节流进行操作,因为字节流可以处理图片、音乐、文字,也可以方便地进行传输或者是文字的编码转换;如果在处理中文的时候请考虑字符流。















 212
212











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









