







《------往期经典推荐------》
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
目录
引言

在视觉人工智能领域,一个能够同时处理多种视觉任务的统一模型一直是研究者们追求的目标。如今,这一愿景正由VisionReasoner变为现实。这个基于强化学习的创新框架,不仅打破了传统视觉模型的任务局限,更以惊人的性能在检测、分割、计数等十大视觉任务中超越基线模型,为视觉智能开辟了全新的可能性。
一、VisionReasoner:重新定义视觉智能的统一框架
1. 核心创新:从单一任务到多元认知的跨越
传统的视觉模型往往专注于单一任务,如目标检测或图像分割,难以在不同视觉任务间实现高效迁移。VisionReasoner的核心突破在于通过精心设计的多目标认知学习策略和系统的任务重构,将多种视觉感知任务统一到一个共享模型中。

研究者发现,尽管视觉任务形式多样,但大多可归为检测、分割和计数这三大基本类型。基于这一洞察,VisionReasoner构建了一个能够处理这些核心任务的统一架构,通过强化学习机制提升模型的推理能力,使其能够分析视觉输入并生成结构化的推理过程,最终输出用户所需的结果。
2. 强化学习驱动的智能推理
VisionReasoner的强大能力源于其独特的强化学习框架。该框架设计了两类奖励函数来引导模型学习:
- 格式奖励:包括促进结构化推理的思考奖励和防止冗余推理的非重复奖励,确保模型输出清晰、有条理的推理过程。
- 准确性奖励:由多目标IoU奖励和L1奖励组成,用于精确的定位,强化模型的多目标认知能力。
这种奖励机制不仅提高了模型的推理质量,还通过结合批量计算和匈牙利算法的高效匹配管道,在保持匹配精度的同时显著提升了计算效率。
3. 惊人的性能表现
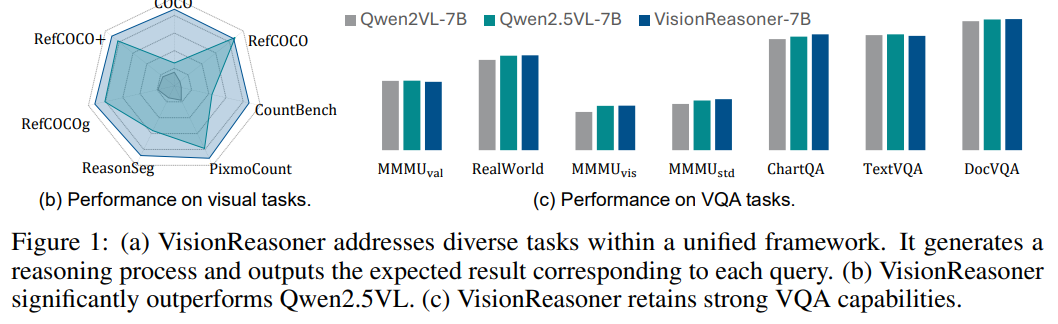
VisionReasoner的实力在广泛的实验中得到了充分验证。在三大关键领域的十项任务评估中,它展现出了超越现有模型的卓越性能:
- 在COCO数据集(检测任务)上,相比Qwen2.5VL实现了29.1%的相对提升
- 在ReasonSeg数据集(分割任务)上,相对优势达到22.1%
- 在CountBench数据集(计数任务)上,也实现了15.3%的性能提升
更令人印象深刻的是,VisionReasoner-7B模型仅使用7,000个样本进行训练,却展现出了强大的测试时推理能力和有效的多任务泛化能力,这充分证明了统一框架的高效性和潜力。
二、应用场景
1. 精准目标检测:从地标识别到日常物品
VisionReasoner在目标检测任务中表现出色,能够准确识别并定位图像中的目标物体。无论是识别纽约市的标志性建筑自由女神像,还是定位日常生活中的常见物品,它都能生成详细的推理过程,解释其识别决策的依据。

检测任务示例:
问题:哪座建筑是地标且最适合合影?
推理过程:图像左侧的自由女神像是一个突出特征,它是自由的著名象征……被公认为自由女神像。自由女神像也是常见的旅游景点,经常出现在纽约市的照片中。
2. 精细图像分割:从遮阳设施到复杂场景
在图像分割任务中,VisionReasoner能够精确勾勒出目标物体的轮廓,即使是形状复杂的物体也能处理得当。例如,在识别能够为人们提供遮阳的物体时,它不仅能识别出帐篷等遮阳设施,还能详细描述其特征和功能。

分割任务示例:
问题:分割可以帮助人们遮阳的物体。
推理过程:任务是识别可以提供遮阳的物体……通常是帐篷或天篷。在图像中,……看起来像帐篷,因为它们有圆顶形状并设置在地面上。这些结构可能是为聚集在周围的人提供遮阳的。
3. 智能目标计数:从渔业工具到复杂场景统计
VisionReasoner的计数能力同样令人印象深刻。它能够准确统计图像中目标物体的数量,并且在计数过程中展现出强大的推理能力。例如,在统计有助于捕鱼的物体时,它能够识别出船只等关键工具,并给出清晰的计数依据。

计数任务示例:
问题:有多少个可以帮助捕鱼的物体?
推理过程:为了确定有多少物体可以帮助捕鱼……船通常用于捕鱼,船上经常存放网、钓竿和其他捕鱼装备。我会数船的数量。
结果:总数是8。
4. 复杂场景推理:从空间关系到逻辑判断

除了基本的检测、分割和计数任务,VisionReasoner还能处理需要复杂推理的视觉任务。例如,在判断什么能让女士站得更高时,它能够识别出梯子这一关键物体,并解释其推理过程。
复杂推理示例:
问题:找到能让女士站得更高的东西。
推理过程:问题是要找出能让女士站得更高的物体。这位女士已经站在梯子上了,梯子是提升她的物体。梯子是最符合能让她站得更高的物体。
三、使用方法与示例
1. 环境搭建与模型下载
首先,克隆VisionReasoner仓库并创建虚拟环境:
git clone https://github.com/dvlab-research/VisionReasoner.git
cd VisionReasoner
conda create -n visionreasoner_test python=3.12
conda activate visionreasoner_test
pip3 install torch torchvision
pip install -r requirements.txt
然后,下载预训练模型:
mkdir pretrained_models
cd pretrained_models
git lfs install
git clone https://huggingface.co/Ricky06662/VisionReasoner-7B
git clone https://huggingface.co/Ricky06662/TaskRouter-1.5B
2. 快速推理:从简单问题到复杂任务
计数任务示例

python vision_reasoner/inference.py --query "这张图片中有多少架飞机?"
推理过程输出:
图像中显示了一组在空中飞行的飞机。每架飞机都很明显,可以单独计数。飞机排列成特定的队形,后面有可见的烟雾轨迹,这是航展或演示中常见的现象。
最终答案:
感兴趣物体的总数是:10
分割任务示例
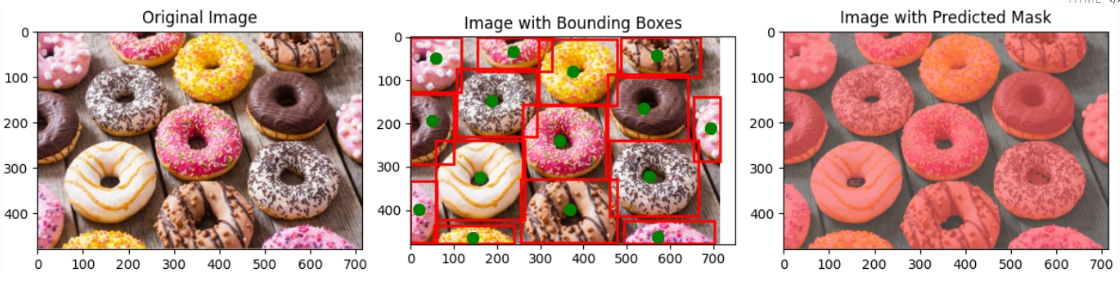
python vision_reasoner/inference.py --image_path "assets/donuts.png" --query "请分割甜甜圈"
推理过程输出:
任务涉及识别和分割图像中的各个甜甜圈。每个甜甜圈在颜色、糖霜和配料上都不同,这有助于将它们彼此区分开来。目标是将每个甜甜圈识别为一个单独的物体,并为它们提供边界框。
复杂推理任务示例
python vision_reasoner/inference.py --image_path "assets/stand_higher.png" --query "找到能让女士站得更高的东西"
推理过程输出:
问题是要找出能让女士站得更高的物体。这位女士已经站在梯子上了,梯子是提升她的物体。梯子是最符合能让她站得更高的物体。
3. 混合推理模式:智能选择最佳策略
VisionReasoner的混合推理模式能够根据查询的复杂程度智能切换策略,在简单查询上使用直接检测(如YOLO-World)以加快响应速度,在复杂任务上则采用基于推理的方法。
简单查询示例
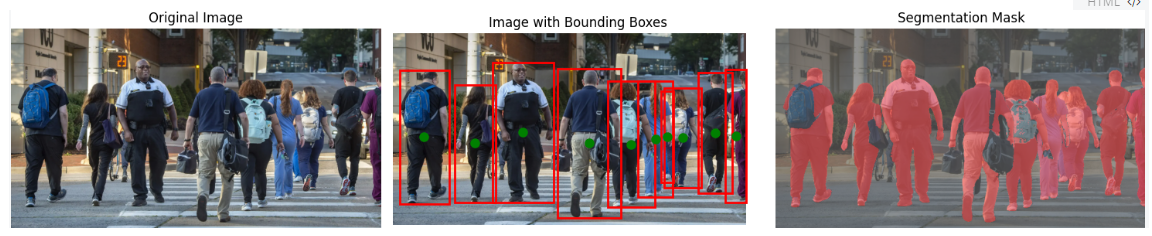
python vision_reasoner/inference.py --image "assets/crowd.png" --query "人" --hybrid_mode
在这种情况下,模型直接使用YOLO-World进行检测,无需经过推理过程,响应速度更快。
复杂查询示例

python vision_reasoner/inference.py --image "assets/crowd.png" --query "面向镜头的人" --hybrid_mode
推理过程输出:
任务涉及识面向镜头的人,然后找到最匹配的物体。图像中央有一个穿白衬衫和黑背心的人,似乎正直接面向镜头。其他人都是背对着镜头,所以他们不是目标。穿白衬衫和黑背心的人最符合面向镜头的描述。
四、影响与未来展望
VisionReasoner的出现标志着视觉人工智能领域的一个重要里程碑。它不仅证明了统一视觉模型的可行性,还为未来的研究开辟了多个令人兴奋的方向:
-
更广泛的任务覆盖:目前,VisionReasoner已经能够处理四大基本任务类型,未来有望进一步扩展到3D图像处理、医学图像分析等更专业的领域。
-
多模态融合的深化:随着模型的不断进化,VisionReasoner有望实现更深度的多模态融合,将视觉感知与语言理解、甚至音频处理等能力更紧密地结合起来。
-
实际应用的拓展:从智能监控到自动驾驶,从医疗诊断到工业质检,VisionReasoner的统一框架为各种实际应用场景提供了强大的技术支持,有望带来巨大的社会和经济效益。
-
强化学习的创新:VisionReasoner的成功也为强化学习在视觉领域的应用提供了新的思路和方法,有望推动相关算法的进一步创新和发展。
VisionReasoner不仅是一个技术突破,更是一个新的起点。它向我们展示了人工智能在视觉认知领域的巨大潜力,也让我们对未来的智能世界有了更多的想象空间。随着这一框架的不断完善和扩展,我们有理由相信,一个更加智能、更加通用的视觉人工智能时代正在到来。
好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











