






推荐系统(十八) 大厂实践经验学习:双塔模型
01双塔模型
1.1 模型应用
双塔模型被广泛应用于推荐系统的召回和粗排阶段,应用过程中也存在一定区别:
(1)负样本构造
-
召回:正样本是真实正例,负样本通过采样(全局采样、batch内采样等)得到
-
粗排:要接近精排,样本与精排一致,正负样本都是从用户的真实正负例中选取
召回是从海量候选集中,要把用户可能感兴趣的或完全不相关的item区分开来,所以召回在线上所面对的数据环境,就是鱼龙混杂、良莠不齐,负样本除了曝光未点击的真实负例外,也要包含未曝光的样本,目的就是让训练样本尽量符合线上真实分布,让模型“见见世面“。
(2)线上预测
-
召回:把item向量导入faiss,建立索引,获取user向量,在faiss中做近邻搜索,得到topn相似item作为召回候选
-
粗排:item向量不需要导入faiss建立索引,只需要以kv方式存储起来,获取user向量,kv库中检索获取item向量,通过内积得到粗排打分,选取topn送入精排
1.2 存在问题
双塔模型主要问题是特征交叉能力受限:
-
特征上,user和item塔分别以user特征和item特征作为输入,本身缺少user与item交叉组合类特征
-
结构上,user和item塔最后一层向量内积交叉时,已经是高层特征交叉,一些细粒度和细节特征信息被损失掉,失去了与参与特征交叉的机会,影响两侧特征交叉效果。
-
1.3 解决思路
(1)减少特征信息损失:不再完全依赖DNN拟合能力,筛选重要特征参与交叉,减少无关特征干扰,或引入多种交叉网络(FM、DCN等),多种交叉方式取长补短,减少特征损失,如SENet双塔模型、并联双塔模型
(2)蒸馏学习:以精排模型为teacher,指导双塔模型学习,通过蒸馏学习的方式,弥补双塔模型特征和结构上的不足
(3)引入交叉信息或特征:引入增强向量,隐式学习两塔之间特征交互,或舍弃双塔结构,直接引入交叉特征,如对偶增强双塔、阿里COLD
02SENet双塔模型
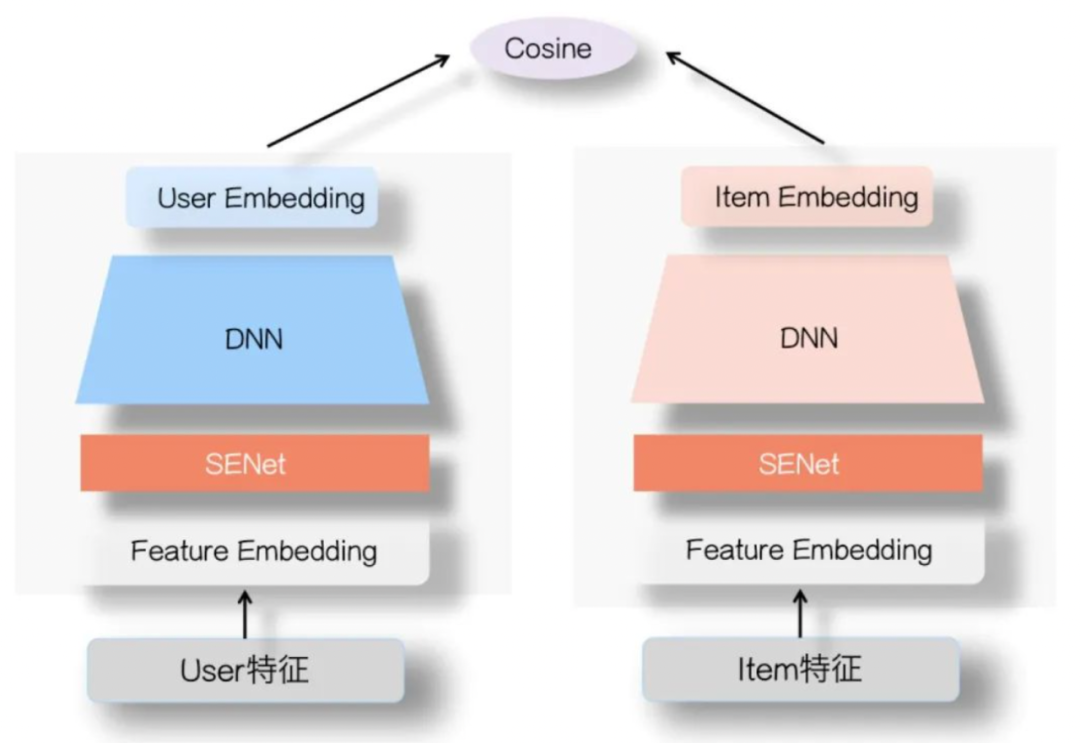
如图所示,用户侧塔和Item侧塔在特征Embedding层上,各自加入一个SENet模块,两个SENet各自对User侧和Item侧的特征,进行动态权重调整:
-
动态抑制User或者Item内的部分低频无效特征,甚至清除掉(如果权重为0的话)不重要甚至是噪音的特征
-
突显那些对高层User Embedding和Item Embedding的特征交叉起重要作用的特征
通过SENet更有利于表达两侧的特征交互,避免单侧无效特征经过DNN双塔非线性融合时带来的噪声,同时又带有非线性的作用。
03并联双塔
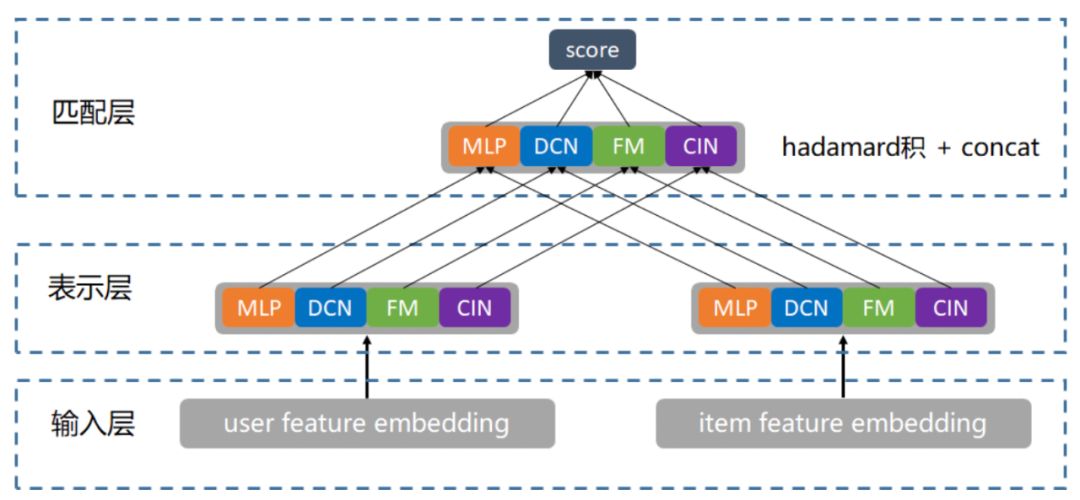
如图所示,主要思路:
-
通过"并联"多个双塔结构(MLP、DCN、FM、FFM、CIN),不同的交叉方式,特征交叉组合有一定差异性,比如FM实现浅层显式交叉,DCN和CIN可以实现深度显式交叉,从多个角度和层次学习输入层特征的融合和交互,相互取长补短,减少细节特征的丢失,缓解双塔内积的瓶颈。
-
对"并联"的多个双塔引入LR进行带权融合,即多个user和item向量进行hadamard积(相当于多个双塔拼接),再经过一个LR得到融合结果。
04蒸馏学习
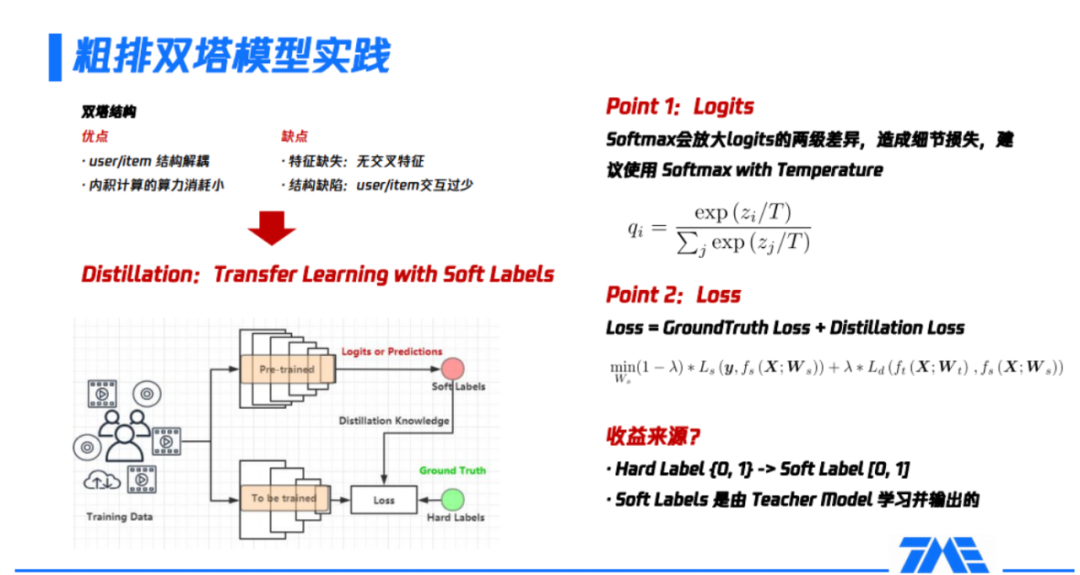
如图所示,模型蒸馏本质上是一种迁移学习(transfer learning),transfer的方式是通过所谓的label,区别于我们平时理解的样本label离散值,变为了0到1之间的一个连续值。如左下角是一个常见的蒸馏模型架构图,这个里面会有涉及到两个模型,第一个模型叫做教师模型,叫做teacher,第二个模型是学生模型,叫做student。这两个模型的总体思路是teacher模型是一个非常大、非常复杂、学习到的东西非常多的模型,teacher模型会把学习到的知识传导给student模型,受限于某些原因,该模型没有办法做得很复杂,或者它的规模必须限制在一定范围内的子模型。
具体流程如下:
(1)准备训练样本,对teacher模型预训练,即得到了teacher模型;
(2)把teacher模型最后一层或倒数第二层的输出结果,作为传递给student模型的信息,这部分通常是logits或softmax的形式,也叫做soft labels;
(3)把soft labels传导到student模型,作为模型loss的一部分,因为student模型除了要拟合teacher模型传递的信息,也要去拟合样本真实的分布。
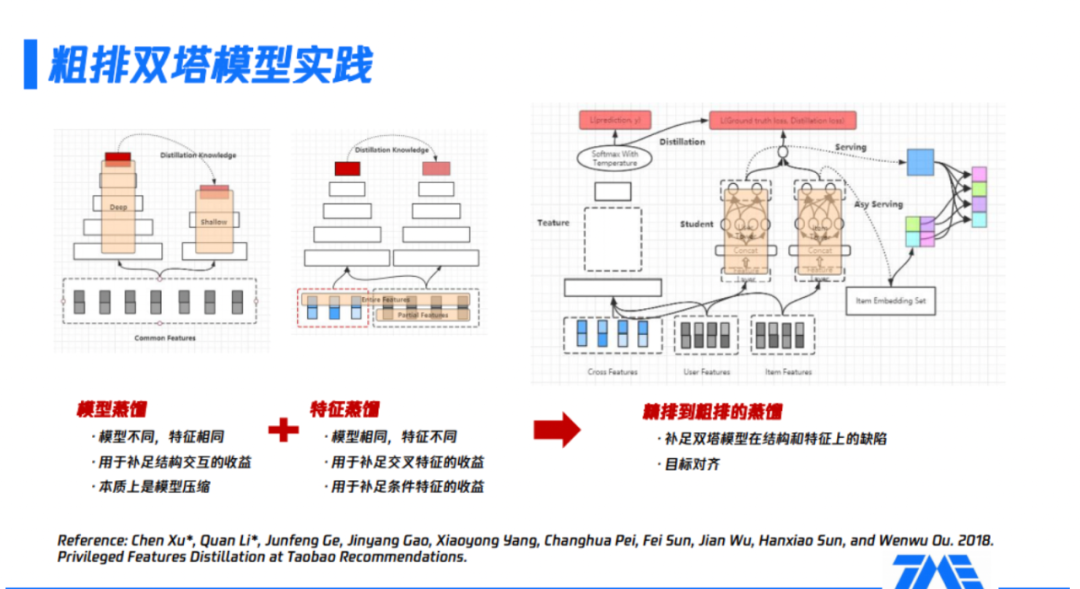
如图所示,精排模型通常是一个被充分训练的、参数量很大、表达能力很强的模型,如果通过蒸馏精排模型获取粗排模型,那么目标的一致性和学习能力的上限都符合预期。具体操作方式如上图右侧:
(1)左侧的teacher模型是精排模型,该模型使用全量的特征,包括三大类,即user侧特征、item侧特征及它们的交叉特征;曲线框里表示复杂的精排网络结构;最后的softmax with temperature就是整个精排模型的输出内容,后续会给到粗排模型进行蒸馏。
(2)中间的粗排模型,模型未使用交叉特征,在user tower和item tower交互后,加上精排模型传递过来的logits信息,共同的构成了粗排模型的优化目标。整个粗排模型的优化目标,同时对真实样本和teacher信息进行了拟合。
(3)右侧展示的是训练完粗排模型后,通过user serving产出user embedding,再与item embedding做内积运算,完成整个排序的过程。
05对偶增强双塔
双塔两侧,每个query(或user)和item新增一个增强向量作为输入,当样本标签为正样本时,根据另一个塔输出的表示向量(最后一层输出),来更新增强向量,这样一个塔的输入就携带了另一个塔的高阶信息,隐式地实现了两个塔之间的信息交互。
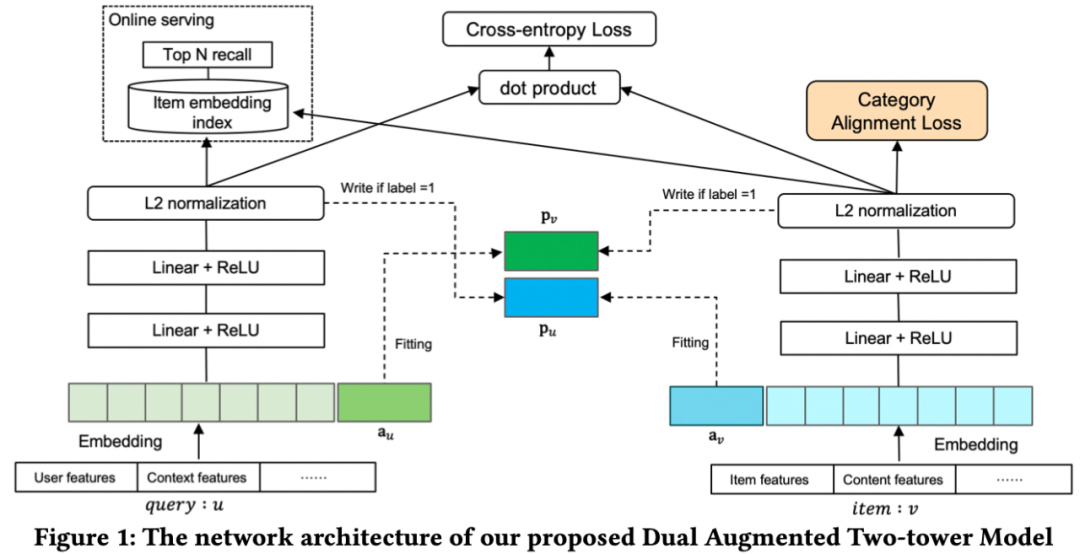
增强向量更新主要包括minic loss和stop gradient策略:
-
minic loss:采用均方差损失函数,目标是用增强向量来拟合与另一塔的正向交互,即训练样本为正样本时,增强向量与另一个塔输出的表示向量之间趋于一致,如下式,样本为负样本时,loss为0,为正样本时,loss非0,通过这种方式使增强向量包含了另一个塔的高阶信息,实现两个塔之间的信息交互。
-
stop gradient:由于minic loss是为了学习更新增强向量 和 ,应该冻结双塔输出的表示向量 和 ,因此 和 不对 和 进行梯度回传。
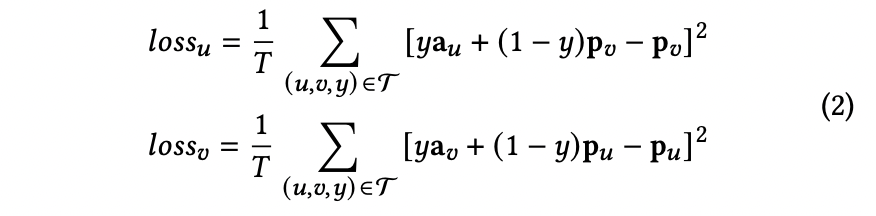
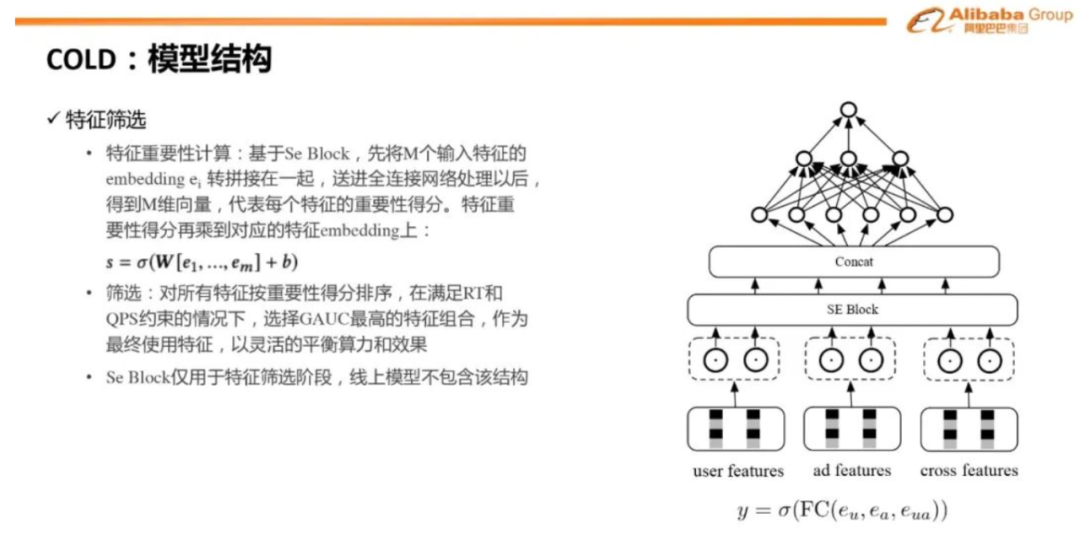
06阿里COLD
重新思考模型和算力的关系,从两者联合设计优化的视角出发,提出了新一代的粗排架构COLD,可以灵活地对模型效果和算力进行平衡,具有几个特点:
(1)基于算法-系统Co-Design视角设计,算力作为一个变量与模型进行联合优化
(2)模型结构没有限制,可以任意使用交叉特征
(3)工程优化解决算力瓶颈
(4)在线实时系统,实时训练,实时打分,以应对线上分布快速变化
大致工作为:
(1)先训练模型得到特征重要性得分,选择重要性最高的TopK个特征作为候选特征
(2)基于GAUC、QPS和RT指标等离线指标,对效果和算力进行平衡,最终在满足QPS和RT要求情况下,选择GAUC最高的一组特征组合,作为COLD最终使用的特征,后续的训练和线上打分都基于选择出来的特征组合。
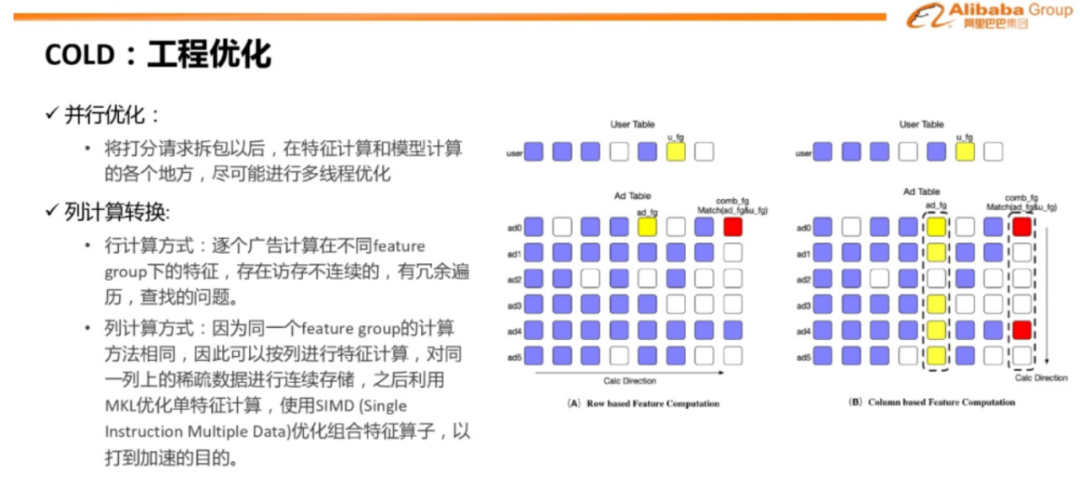
(3)为了给COLD使用更复杂的特征模型打开空间,工程上同时进行优化。















 366
366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









