







Oracle数据库相关
1、数据库系统
数据库系统是由数据库、数据库管理系统、应用系统和数据库管理员构成的。数据库管理系统简称DBMS,即Database Management System,是数据库系统的关键组成部分,包括数据库定义、数据库查询、数据库维护等。我们后端开发人员只需充分了解数据库管理系统的常用操作就行了,当然深入了解数据库也可以。
2、数据库
数据库是一种存储结构,它允许使用各种格式输入、处理和检索数据,不必在每次需要数据的时候重新输入。比如,我们查询某个人的电话号码时,只需要查看电话簿就行了,按照姓名来查询,那么这个电话簿就相当于一个数据库。
数据库的具有以下特点:
- 实现数据的共享
数据共享包含所有用户可以同时存取数据库中的数据,也包括用户可以使用各种方式通过接口来使用数据库,并提供数据共享。 - 减少数据的冗余
同文件系统相比,数据库实现了数据共享,从而避免了用户各自建立自己的文件,减少了大量的重复数据,减少了数据冗余,维护了数据的一致性。 - 数据的独立性
数据的独立性包括数据库中数据库的逻辑结构和应用程序相互独立,也包括数据物理结构的变化并不会影响数据的逻辑结构。 - 数据实现集中控制
文件管理的方式中,数据是处于一种分散状态的,不同的用户或同一用户在不同处理中其文件其文件之间没有关系。但是利用数据库可以对数据进行集中控制和管理,并通过数据模型表示各种数据的组织以及数据间的联系。 - 数据的一致性和可维护性
以确保数据的安全性和可靠性。包括以下几点:
安全性控制:以防止数据的丢失、错误更新个越权使用。
完整性控制:保证数据的正确性、有效性和相容性。
并发控制:使在同一时间周期内,允许对数据实现多路存取,又能防止用户之间的不正常交互作用。
故障的发现和恢复。
2.1、数据库的结构
从发展的历史来看,数据库是数据管理的高级阶段,是由文件管理系统发展起来的。数据库的基本结构可以分为3个层次。
- 物理数据层:它是数据库的最内层,是物理存储设备上实际存储的数据集合。这些数据是原始数据,是用户加工的对象,由内部模式描述的指令操作处理的字符和字组成。
- 概念数据层:它是数据库的中间层,是数据库的整体逻辑表示,指出了每个数据的逻辑定义以及数据间的逻辑关系,是存储记录的集合。涉及的是数据库所有对象的逻辑关系,而不是它们的物理情况,是数据库管理员概念下的数据库。
- 逻辑数据层:它是用户所看到和使用的数据库,是一个或一些特定用户使用的数据集合,即逻辑记录的集合。
我们使用数据库产品时,基本上都是使用的逻辑数据层。
2.2、数据库种类
数据库系统一般是基于某种数据模型。可以分为层次型、网状型、关系型、面向对象型等。
- 层次型数据库:层次型数据库类似于树结构,是一组通过链接而相互联系在一起的记录。层次模型的特点是记录之间的联系是通过指针来实现的。由于层次模型层次顺序严格而复杂,因此对数据进行各项操作都很困难。
- 网状型数据库:网络模型是使用网络结构表示实体类型、实体之间联系的数据模型。网络模型容易实现多对多的联系。要求必须十分熟悉数据库的逻辑结构。
- 面向对象型数据库:建立在面向对象的模型基础上。
- 关系型数据库:关系型数据库是目前市面上最流行的数据库,是基于关系模型建立的数据库,关系模型是由一系列的表格组成的。比如MySQL、Oracle、Sql Server等产品。
3、SQL语言
SQL,全称为Structure Query Language,结构化查询语言。被广泛地应用于大多数数据库中,使用SQL语言可以方便地查询、操作、定义和控制数据库中数据。SQL语言主要由以下几个部分组成:
- DDL:Data Definition Language,数据定义语言,如create、alter、drop语句等。
- DML:Data Manipulation Language,数据操纵语言,如select、insert、update、delete等,即我们常说的增删改查,也是我们用的最多的。
- DCL:Data Control Language,数据控制语言,如grant、revoke等。
- TCL:Transaction Control Language,事务控制语言,如commit、rollback等。
在开发中,我们后端用的最多的就是DML数据操作语言了,增删改查。以下简单说一下:
(1)select查询
语法如下:
SELECT 字段 FROM 表名
WHERE 条件表达式
GROUP BY 字段
HAVING 条件表达式
ORDER BY 字段 ASC/DESC
例子:
select name,age,sex,address from person where age >=18 order by name desc;
(2)insert插入
语法格式:
INSERT INTO 表名 [(字段1,字段2,…)] VALUES (属性值1,属性值2,…);
例子:
insert into person (name,age,address) values
("云过梦无痕",25,"湖北");
(3)update修改
语法格式:
UPDATE 表名 SET 字段名 = 新的值 WHERE 条件表达式;
例子:
update person set name = "云儿" where name = "云过梦无痕" and age = 25;
(4)delete删除
语法格式:
DELETE FROM 表名 WHERE 条件表达式;
例子:
delete from person where where name = "云儿" and age = 25;
4、Oracle数据库
Oracle Database,又名Oracle RDBMS,或简称Oracle。是甲骨文公司的一款关系数据库管理系统。它是在数据库领域一直处于领先地位的产品。可以说Oracle数据库系统是目前世界上流行的关系数据库管理系统,系统可移植性好、使用方便、功能强,适用于各类大、中、小、微机环境。它是一种高效率、可靠性好的、适应高吞吐量的数据库方案。
提前说明一下:Oracle数据库对电脑的配置要求有一点高。
4.1、下载及安装
这里直接跳过。
4.2、服务的开启
安装完成后会在系统服务里添加7个服务,如下:
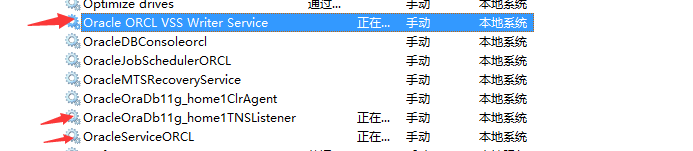
一般只用开启箭头标记的3个服务即可。
4.3、GUI工具
Oracle数据库安装成功后并不提供友好的界面,也就是说用户和它交互的界面是很不友好的,类似窗口。可以自己下载支持Oracle数据库的视图化GUI工具,使用GUI工具可以使操作简单化,常用的Navicat、PLSQL Developer等。
4.4、用户的创建
这里直接使用Navicat了。先建立和Oracle数据库的连接:

可以先测试一下能否连接的上,然后直接确定连接。
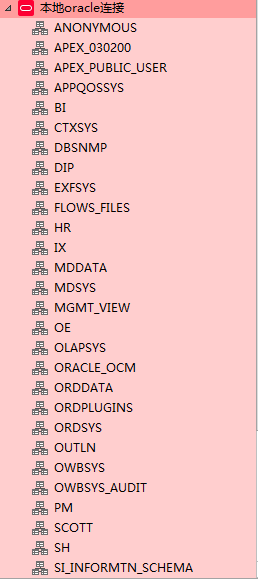
连接上左边一列显示的是当前数据库的所有用户,可以自定义添加新的用户:
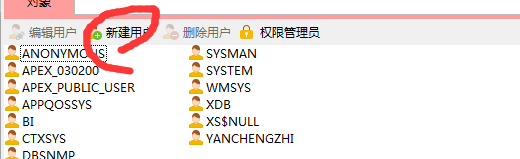

填写用户名、密码,选择默认表空间、临时表空间等。

勾选需要的权限。


分配完毕之后,直接点保存。
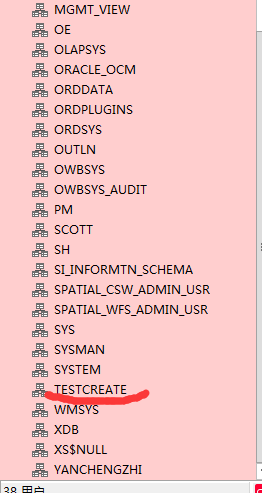
刚才创建的用户,也可以删除掉。
右边选中,右键-删除用户-确认,即可完成用户的删除。
4.5、表空间
4.5.1、概念
Oracle数据库直接存储数据的载体是数据库表,而Oracle数据库设计时将表存储在表空间中进行管理。如果把Oracle数据库看作是一个实体房间,那表空间是房间内可自由分配的空间,表和表空间都是物理性的存在于硬盘上,表空间使得数据库管理更加灵活,极大提高了数据库性能。可以将表空间看作是表的载体。
4.5.2、表空间的作用
- 避免磁盘空间突然耗竭的风险
- 规划数据更加灵活
- 提高数据库性能
- 提高数据库安全性
4.5.3、创建表空间
可以通过SQL语句来创建,如下:
CREATE tablespace test_demo datafile 'f:/database/test2/test_demo.dbf' SIZE 20M autoextend ON next 5m maxsize 500m;
说明:在f:/database/test2目录下创建test_demo表空间,后缀是dbf,初始大小为20M,自动增长,每次增长5M,表空间最大为500M。
执行SQL语句,查看目录:

也可以通过Navicat来创建,简单一点。



填好直接保存就行了。
4.5.3、删除表空间
直接选择表空间,右键-删除表空间即可。


需要说明的是,只是删除逻辑结构,并不会删除物理文件。
SQL语句删除如下:
DROP TABLESPACE demo including contents
AND datafiles;
COMMIT;
会将表空间以及相应的物理文件一并删除。先创建:


再删除:


物理文件也没了。
4.6、数据库表
4.6.1、相关说明
- 数据库表是直接存储数据的地方
- 数据库表是最常用来进行数据增删改查的
- 数据库表有行和列构成,每行被称为数据实体,每列被称为实体的属性
4.6.2、数据表的创建
这里只写SQL语句:
CREATE TABLE y1 (
id VARCHAR2 ( 128 ) NOT NULL,
name VARCHAR2 ( 64 ) NOT NULL,
createtime DATE NULL,
descs VARCHAR2 ( 3000 )
) tablespace users;
执行:
创建成功。关键字是CREATE TABLE。
4.6.3、数据表的查询
SQL语句:
SELECT
*
FROM
y1;
执行:
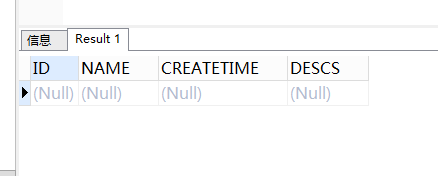
表中暂时没有数据。查询的关键字是select。
4.6.4、数据表的修改
SQL语句:
--删除已有列drop
ALTER TABLE y1 DROP COLUMN descs;
commit;
执行:

--添加新列add
ALTER TABLE y1 ADD descs VARCHAR2 ( 128 ) NOT NULL;
commit;
执行:

--修改已有列,重新命名rename
ALTER TABLE y1 RENAME COLUMN descs TO descs2;
commit;
执行:

--修改已有列长度modify
ALTER TABLE y1 MODIFY (
name VARCHAR2 ( 200 ));
commit;
执行:

--修改表名称rename
ALTER TABLE y1 RENAME TO y2;
commit;
执行:
修改表的关键字ALTER。
4.6.5、数据表的删除
SQL语句如下:
--删除整个数据表
DROP TABLE y2;
执行:

已经查询不到了,说明表已经删除成功。注意删除表是用DROP,清空表数据用DELETE。
4.7、数据约束
4.7.1、数据约束的目的
数据约束的根本目的在于保持数据的完整性。数据的完整性是指数据的精确性和可靠性,即数据库中的数据都是符合某种预定义规则,当用户输入的数据不符合这些规则时,将无法实现对数据库的更改。主要有主键约束、外键约束、唯一性约束、默认约束、检查约束5种。
4.7.2、主键约束
主键约束是数据库中最常见的约束。主键约束可以保证数据的完整性,即防止数据表中的两条记录完全相同,通过将主键纳入查询条件,可以达到查询结果最多返回一条记录的目的,主键约束的最终目的是确保数据库中的记录是唯一的,在更多情况下称之主键为行的唯一索引。这就要求表中主键列所填充的数据值不允许重复,主键约束属于唯一约束。数据表中用一列或多列来标识当前记录行在表中是唯一记录的列称之为主键列,建立主键即建立主键约束。主键是实体行完整性约束的一种重要标志,数据库表有行和列构成,每行称为数据实体,每列称为实体属性。
(1)主键约束的特点
- 主键值在表中不允许重复
- 主键值不允许为空
- 主键针对实体通常不具备实际意义,只作为行唯一标识使用
- 主键不建议经常修改,最好是不改的
- 考虑性能,不建议设置联合主键
(2)建立主键约束
使用GUI工具建立主键很简单,推荐使用这种方式。
以下使用SQL语句建立主键,关键字是PRIMARY KEY。
先建表后建立主键:
--先建表
CREATE TABLE y1 (
id SMALLINT NOT NULL,
NAME VARCHAR ( 128 ) NOT NULL
) TABLESPACE demo;
--再建立主键
ALTER TABLE y1 ADD CONSTRAINT pk_id1 PRIMARY KEY ( id );
COMMIT;
执行:

主键建立成功。
建表的同时建立主键:
-- 建表的同时建立主键约束
CREATE TABLE y2 (
id SMALLINT NOT NULL PRIMARY KEY,
NAME VARCHAR ( 128 ) NOT NULL
) TABLESPACE demo;
执行:

主键约束建立成功。
测试:
-- 插入两行数据
INSERT INTO y2 ( "ID", "NAME" ) VALUES (1, 'ycz');
INSERT INTO y2 ( "ID", "NAME" ) VALUES (2, 'zcy');
执行,然后查询:
select * from y2;
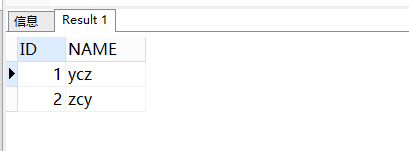
再添加一条记录:

主键重复,不允许添加,所以主键约束是为了保证数据的唯一性。
4.7.3、外键约束
外键约束是引用完整性约束,外键约束是表与表之间关联引用的唯一方式(主表与从表,从表依附于主表,不能孤立存在)。
(1)外键约束的特点
- 外键值不允许为空
- 外键值必须来源于所引用主表的主键值
- 外键列数据类型通常必须与主键列数据类型相同
- 不能在删除主表数据时导致从表的外键孤立存在
(2)外键约束的建立
同样适用GUI工具创建外键很简单,推荐使用。这里只用SQL语句建立。
先删除y1、y2表:
DROP TABLE y1;
DROP TABLE y2;
COMMIT;
然后创建主表:
CREATE TABLE y1 (
id VARCHAR ( 12 ) NOT NULL PRIMARY KEY,
dep_name VARCHAR ( 32 ) NOT NULL,
create_date TIMESTAMP NOT NULL,
descs VARCHAR ( 128 )
) TABLESPACE demo;
然后建立从表:
CREATE TABLE y2 (
id VARCHAR ( 12 ) NOT NULL PRIMARY KEY,
emp_name VARCHAR ( 32 ) NOT NULL,
entry_date TIMESTAMP NOT NULL,
emp_id VARCHAR ( 12 ) NOT NULL,
descs VARCHAR ( 128 )
) TABLESPACE demo;
从表根据主表主键建立外键:
-- 依据主表主键建立外键
ALTER TABLE y2 ADD CONSTRAINT fk_empid1 FOREIGN KEY ( emp_id )
REFERENCES y1 ( id );
查看:

外键是创建成功的。外键的关键字是FOREIGN KEY。
也可以在建表的同时创建外键:
CREATE TABLE y3 (
id VARCHAR ( 12 ) NOT NULL PRIMARY KEY,
emp_name VARCHAR ( 32 ) NOT NULL,
entry_date TIMESTAMP NOT NULL,
emp_id VARCHAR ( 12 ) NOT NULL,
FOREIGN KEY(emp_id) REFERENCES y1(id),
descs VARCHAR ( 128 )
) TABLESPACE demo;
执行后查看表结构:

外键创建成功。此时y1表是主表,y2和y3都是从表,删除y1是删除不了的:
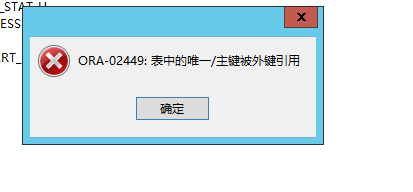
因为存在着引用关系,y2和y3表的外键列引用了y1表的主键列,所以无法删除,只能先删除y2和y3表,再删除y1表,即先删除从表,再删除主表。
在主表y1中添加两条数据:
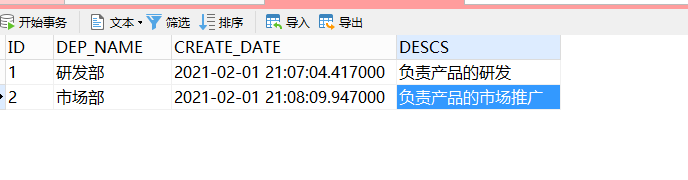
然后尝试添加从表的数据:

因为emp_id列为外键列,只能引用主键列的值,y1的主键列只有1和2两个值,其他值是无法引用的:

只能在主表的主键值中选,无法选择其他值。

4.7.4、唯一约束
唯一性约束限制记录行中的某个列字段值在所有行中是唯一,通常主键约束就隶属于唯一性约束,但唯一性约束不一定是主键约束。
(1)唯一约束的特点
值是唯一的,不允许重复。
(2)建立唯一约束
SQL语句如下:
-- 添加唯一约束
ALTER TABLE y1 ADD CONSTRAINT un_name UNIQUE ( DEP_NAME );
执行,然后尝试添加y1表的数据:

dep_name有唯一约束条件,每个值都是唯一的,不允许重复。唯一约束的关键字是UNIQUE。

4.7.5、默认约束
默认值约束是设定表中的某个列在未填充数据时,系统将使用设置的预定义默认值填充列值,如果显示设置了默认值则默认值失效。
注意:设置了默认约束的列是一定要允许NULL,默认值就是在未设置列的值时起作用。
SQL建立默认约束如下:
-- 建表
CREATE TABLE y4 (
NAME VARCHAR ( 12 ) NOT NULL,
sex VARCHAR ( 2 ) NOT NULL,
address VARCHAR ( 12 ) DEFAULT '未知'
) TABLESPACE demo;

添加数据测试:
-- 指定address的值
INSERT INTO y4 ( "NAME", "SEX", "ADDRESS" ) VALUES
( '云过梦无痕', '男', '湖北' );
-- 指定address的值为default
INSERT INTO y4 ( "NAME", "SEX", "ADDRESS" )
VALUES
( '童话', '男',DEFAULT);
-- 不指定address的值
INSERT INTO y4 ( "NAME", "SEX")
VALUES
( '李丽芬', '女');
执行,然后查看表:

设置为default和不设置的都会以默认值来填充。
4.7.6、检查约束
检查约束是限制表中的某个列字段值的一种强大规则,只有符合检查约束条件的值才能作为这个列字段的值,如限定年龄在18-60岁之间,地址必须在北上广这个范围,邮件地址必须以.com结尾等。
先建表:
CREATE TABLE y5 (
id VARCHAR ( 10 ) NOT NULL PRIMARY KEY,
NAME VARCHAR ( 12 ) NOT NULL,
age number NOT NULL,
sex VARCHAR ( 2 ) NOT NULL,
address VARCHAR ( 12 ) NOT NULL,
email VARCHAR ( 20 ) DEFAULT '未知'
) TABLESPACE demo;
然后建立检查约束:
-- 添加检查约束
-- 年龄只允许18到60岁
ALTER TABLE y5 ADD CONSTRAINT ck_age1 CHECK ( age >= 18 AND age <= 60 );
-- 地址只允许在湖北、湖南、重庆三个地方选
ALTER TABLE y5 ADD CONSTRAINT ck_add1 CHECK ( ADDRESS IN ( '湖北', '湖南', '重庆' ) );
-- 邮箱只允许以@qq.com结尾,即只能是腾讯邮箱
ALTER TABLE y5 ADD CONSTRAINT ck_email2 CHECK ( email like '%@qq.com' );
添加y5表的数据:

地址违反检查约束,修改地址为湖北:

年龄违反检查约束,修改年龄为25:
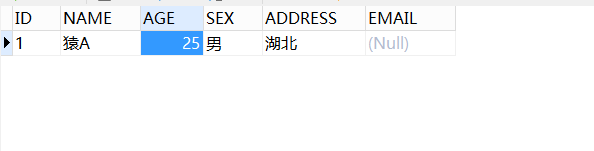
可以了,因为邮箱允许为空,所以不填也能添加,但是一旦填了,必须以@qq.com结尾:

违反了邮箱检查约束,修改后缀为@qq.com:

可以了。
4.7.7、约束的删除
约束的删除SQL如下:
-- 删除检查约束
ALTER TABLE y5 DROP CONSTRAINT CK_AGE1;

年龄的约束条件已经删除了,不再受18-60的条件限制。
4.8、Oracle的常用数据类型
不同数据库产品所支持的数据类型有所差异,Oracle中的常用数据类型主要应用场景为建立数据表时定义列的类型、函数、存储过程的变量定义。这些数据类型大致可分为4类:字符型(character)、数值型(number)、日期型(date)、大对象类型(LOB)。
4.8.1、字符型
Oracle中的字符型有4种,如下:
- Char(长度):固定长度,最大限制2000字节。
- Varchar(长度):可变长度,最大限制4000字节。
- Varchar2(长度):等同Varchar最大限制为4000字节(推荐使用该种类型)。
- String(长度):编程类型,不能定义表的列类型。
注意,使用String类型定义字符串在Oracle中是不允许的,定义字符串使用最多的是varchar2类型。
4.8.2、日期类型
(1)日期的几种类型
Date类型
默认的格式为日月年,如18-9月-1995表示1995年9月18日,必须这样写才能识别,如下:
insert into test_table values('鄢承志','18-9月-1995');
Timestamp类型
时间戳类型,精确到毫秒。
Sysdate类型
函数获取系统日期时间,如下:
select to_char(sysdate,'yy-mm-dd dy ddd') from dual;
Systimestamp类型
函数获取系统日期时间毫秒,如下:
select to_char(systimestamp,'yyyy-mm-dd hh24:mi:ss:ff') from dual;
提示:使用to_date和to_char对日期时间和字符串之间实现转换,如下:
insert into test_table values('ycz',to_date('1995-09-18','yyyy/mm/dd'));
注意使用to_date是带两个参数的,一个时间的字符串表示,一个给定格式。to_date是将字符串转为日期类型,to_char是将日期类型转为字符串类型。
(2)日期格式的表示符号
年(yy,yyy,yyyy)
月(mm,MM,mon,Month)
天(dd(月份天),ddd(年份天))
周(dy(简写),day(全写))
时(hh,hh24)
分(mi)
秒(ss)
毫秒(ff(1-9))
以下对日期类型进行测试:
-- 建表
CREATE TABLE demo (
NAME varchar2 ( 10 ) NOT NULL,
birth date
);
--添加数据
INSERT INTO demo VALUES ( 'ycz', '18-9月-1995' );
--测试to_date方法,将字符串转换为时间格式
INSERT INTO demo VALUES ( 'ycz2', to_date ( '1995-09-18', 'yyyy/mm/dd' ) );
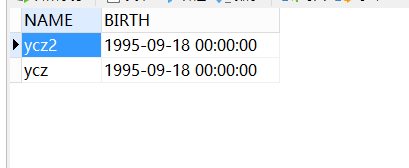
数据添加成功。
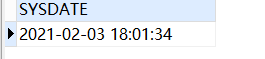
--sysdate是获取系统时间
SELECT sysdate FROM DUAL;
--yy表示2位年
--mm表示月
--dd表示天
--dy表示周几
--测试to_char方法,将时间格式转换为字符串格式
SELECT
to_char ( sysdate, 'yy-mm-dd dy' )
FROM
DUAL;
--systimestamp数据类型测试
SELECT
to_char ( systimestamp, 'yyyy-mm-dd hh24:mm:ss' )
FROM
DUAL;


4.8.3、Lob类型
有3种类型,如下:
- Clob
用于存储大型文本数据。 - Blob
用于存储二进制数据。 - Bfile
用于存储大文件数据。
4.8.4、数值类型
表示常用的数值。有以下5种:
- Number
最常用的类型,可应用列和编程。 - Int
整型,可应用列和编程(会四舍五入)。 - Integer
整型,可应用列和编程(会四舍五入)。 - Float
浮点类型,可应用列和编程。 - Dec
类似于浮点类型,可应用列和编程。
4.8.5、伪列类型
Rowid:记录行ID,由18个英文字母组成。
Rownum :查询数据行生成的行号码(从1开始)。
提示:rowid和rownum只有在查询过程中生成,只能查询,无法进行任何修改。
以下进行测试:
-- 建表
CREATE TABLE person (
NAME varchar2 ( 20 ) NOT NULL,
age INT NULL,
height FLOAT NULL,
-- number类型有2个参数
-- 第1个参数表示有效数字位数
-- 第2个参数表示保留位数
money number ( 20, 3 )
);
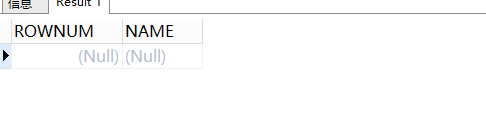
SELECT
rowid,
rownum,
NAME
FROM
person;
此时是查不到rowid和rownum的,因为表中没有记录。
插入几条数据:
--整型数据会自动四舍五入
INSERT INTO person VALUES ( 'ycz', 25.3, 183.5, 5000.123134 );
INSERT INTO person VALUES ( 'jga', 20, 155.8, 4000.32312 );
INSERT INTO person VALUES ( 'lja', 22, 152.6, 4423.32312 );
再查询rownum:
SELECT
rowid,
rownum,
person.*
FROM
person;

可以看到,rownum的最大值就是表中记录的条数。
4.9、序列
Sequence序列是Oracle中自动生成不重复数据的对象。序列主要有以下特征和应用:
- 自动提供唯一的数值
- 共享对象
- 主要用于提供主键
- 将序列值装入内存可以提高访问效率
4.9.1、序列的创建
SQL创建序列的语法如下:
CREATE sequence 序列名
increment BY a -- 每次递增值为a
START WITH b -- 默认开始值为b
MAXVALUE c -- 最大值为c
minvalue d -- 最小值为d
nocycle -- 不循环
nocache -- 不缓存
以下使用SQL语句创建一个序列:
-- 创建表
CREATE TABLE demo2 (
id number ( 20 ) NOT NULL PRIMARY KEY,
NAME varchar2 ( 20 ) NOT NULL
);
--创建序列
CREATE sequence demo_seq
increment BY 5 -- 每次递增值为5
START WITH 15 -- 默认开始值为15
MAXVALUE 100 -- 最大值为100
minvalue 15 -- 最小值为15
nocycle -- 不循环
nocache -- 不缓存
4.9.2、序列的应用
获取序列下一个值:序列名称.nextval。
获取序列当前值:序列名称.currval。
删除序列对象:drop sequence 序列名称。
SQL测试:
-- nextval自动增长序列值
INSERT INTO demo2 VALUES ( demo_seq.nextval, '陆小凤' );
INSERT INTO demo2 VALUES ( demo_seq.nextval, '花满楼' );
INSERT INTO demo2 VALUES ( demo_seq.nextval, '西门吹雪' );
INSERT INTO demo2 VALUES ( demo_seq.nextval, '叶孤城' );
INSERT INTO demo2 VALUES ( demo_seq.nextval, '司空摘星' );

可以看到递增值为5,从15开始,那么第一个值就是15+5=20。
--currval获取当前序列值
SELECT
demo_seq.currval 当前序列值
FROM
DUAL;

当前序列值确实是40,没问题。
使用Navicat视图工具创建序列:


这个序列是我刚才用SQL创建的那个。可以新建一个序列:




创建成功。下面删除序列,直接右键删除序列即可。使用SQL删除的话如下:
-- 删除序列
DROP sequence "demo_seq2";
因为刚才保存的序列名称是小写的,所以要加双引号,要不然找不到,Oracle中最好名称都是大写,大写这里就不用加双引号了。
4.10、增删改查
4.10.1、添加记录
添加记录的关键字是INSERT。语法如下:
-- 依次插入3列,后面的3个值依次对应每列
INSERT INTO 表名 ( colu1, colu2, colu3 )
VALUES (val1,val2,val3);
-- 从第1列开始,按照顺序依次插入值val1,val2,val3,……
INSERT INTO 表名 VALUES ( val1, val2, val3,…… );
以下使用SQL进行测试。先准备两张表:
-- 建立部门表
CREATE TABLE DEPARTMENT (
ID VARCHAR2 ( 64 ) NOT NULL,
NAME VARCHAR2 ( 64 ) NOT NULL,
CODE VARCHAR2 ( 12 ) NOT NULL,
NEWDATE DATE,
DESCS VARCHAR2 ( 2000 )
) tablespace demo;
-- 为列添加注释
COMMENT ON TABLE DEPARTMENT IS '部门信息表';
COMMENT ON COLUMN DEPARTMENT.ID IS '主键id';
COMMENT ON COLUMN DEPARTMENT.NAME IS '部门名称';
COMMENT ON COLUMN DEPARTMENT.CODE IS '部门代码';
COMMENT ON COLUMN DEPARTMENT.NEWDATE IS '成立日期';
COMMENT ON COLUMN DEPARTMENT.DESCS IS '说明';
-- 添加主键
ALTER TABLE DEPARTMENT ADD constraint PK_ID_DEP111 primary key ( ID );
-- 建立员工表
CREATE TABLE EMPLOYEE (
ID VARCHAR2 ( 64 ) NOT NULL,
NAME VARCHAR2 ( 64 ) NOT NULL,
GENDER NUMBER DEFAULT 1,
BIRTH DATE,
ADDRESS VARCHAR2 ( 128 ),
PHONE VARCHAR2 ( 16 ),
ENTRYDATE DATE,
EMAIL VARCHAR2 ( 32 ),
DEPID VARCHAR2 ( 64 ) NOT NULL,
DESCS VARCHAR2 ( 2000 )
) tablespace demo;
-- 为每列添加注释
COMMENT ON TABLE EMPLOYEE IS '员工信息表';
COMMENT ON COLUMN EMPLOYEE.ID IS '主键';
COMMENT ON COLUMN EMPLOYEE.NAME IS '员工真实姓名';
COMMENT ON COLUMN EMPLOYEE.GENDER IS '性别';
COMMENT ON COLUMN EMPLOYEE.BIRTH IS '生日';
COMMENT ON COLUMN EMPLOYEE.ADDRESS IS '住址';
COMMENT ON COLUMN EMPLOYEE.PHONE IS '手机号码';
COMMENT ON COLUMN EMPLOYEE.ENTRYDATE IS '入职日期';
COMMENT ON COLUMN EMPLOYEE.EMAIL IS '邮箱号码';
COMMENT ON COLUMN EMPLOYEE.DEPID IS '部门id外键';
COMMENT ON COLUMN EMPLOYEE.DESCS IS '备注';
-- 添加主键
ALTER TABLE EMPLOYEE ADD CONSTRAINT PK_ID_EMP111 PRIMARY KEY ( ID );
-- 添加外键
ALTER TABLE EMPLOYEE ADD CONSTRAINT FK_DEPID_EMP1111 FOREIGN KEY ( DEPID )
REFERENCES DEPARTMENT ( ID );
然后开始添加记录:
-- 部门表添加记录
INSERT INTO DEPARTMENT ( ID, NAME, CODE, NEWDATE, DESCS )
VALUES
( 'DEPID1001', '生产部', 'SCB1001', to_date ( '12-10-2015', 'dd-mm-yyyy' ), '协调规划统筹产品制造' );
INSERT INTO DEPARTMENT ( ID, NAME, CODE, NEWDATE, DESCS )
VALUES
( 'DEPID1002', '事业部', 'SYB1002', to_date ( '12-10-2015', 'dd-mm-yyyy' ), '统筹规划公司战略方向' );
INSERT INTO DEPARTMENT ( ID, NAME, CODE, NEWDATE, DESCS )
VALUES
( 'DEPID1003', '人事部', 'RSB1003', to_date ( '12-10-2015', 'dd-mm-yyyy' ), '统筹公司人员调配招聘协调培训' );
INSERT INTO DEPARTMENT ( ID, NAME, CODE, NEWDATE, DESCS )
VALUES
( 'DEPID1004', '市场部', 'SCB1004', to_date ( '12-10-2015', 'dd-mm-yyyy' ), '市场规划,统筹,开拓' );
INSERT INTO DEPARTMENT ( ID, NAME, CODE, NEWDATE, DESCS )
VALUES
( 'DEPID1005', '销售部', 'XSB1005', to_date ( '12-10-2015', 'dd-mm-yyyy' ), '产品推广宣传营销策略制定及执行' );
INSERT INTO DEPARTMENT ( ID, NAME, CODE, NEWDATE, DESCS )
VALUES
( 'DEPID1006', '研发部', 'YFB1006', to_date ( '12-10-2015', 'dd-mm-yyyy' ), '负责公司产品研发' );
INSERT INTO DEPARTMENT ( ID, NAME, CODE, NEWDATE, DESCS )
VALUES
( 'DEPID1007', '质检部', 'RSB1007', to_date ( '12-10-2015', 'dd-mm-yyyy' ), '公司产品质量监督检测' );
COMMIT;
查询一下:
SELECT
*
FROM
DEPARTMENT;

一共有7个部门。
-- 员工表中添加记录
INSERT INTO EMPLOYEE ( ID, NAME, GENDER, BIRTH, ADDRESS, PHONE, ENTRYDATE, EMAIL, DEPID, DESCS )
VALUES
(
'emp1004',
'洪七公',
1,
to_date ( '08-05-1970', 'dd-mm-yyyy' ),
'贫穷岛屿',
'13966550020',
to_date ( '12-04-2015', 'dd-mm-yyyy' ),
'hqg@163.com',
'DEPID1004',
NULL
);
INSERT INTO EMPLOYEE ( ID, NAME, GENDER, BIRTH, ADDRESS, PHONE, ENTRYDATE, EMAIL, DEPID, DESCS )
VALUES
(
'emp1005',
'丘处机',
1,
to_date ( '10-05-1980', 'dd-mm-yyyy' ),
'道观',
'15544885665',
to_date ( '12-06-2015', 'dd-mm-yyyy' ),
'qcj@163.com',
'DEPID1004',
NULL
);
INSERT INTO EMPLOYEE ( ID, NAME, GENDER, BIRTH, ADDRESS, PHONE, ENTRYDATE, EMAIL, DEPID, DESCS )
VALUES
(
'emp1006',
'梅超风',
0,
to_date ( '10-10-1982', 'dd-mm-yyyy' ),
'骷髅岛',
'13222556687',
to_date ( '12-06-2017', 'dd-mm-yyyy' ),
'meifeng@163.com',
'DEPID1001',
NULL
);
INSERT INTO EMPLOYEE ( ID, NAME, GENDER, BIRTH, ADDRESS, PHONE, ENTRYDATE, EMAIL, DEPID, DESCS )
VALUES
(
'emp1007',
'陈旋风',
1,
to_date ( '10-10-1982', 'dd-mm-yyyy' ),
'桃花岛',
'13355006699',
to_date ( '12-06-2017', 'dd-mm-yyyy' ),
'cxf@163.com',
'DEPID1001',
NULL
);
INSERT INTO EMPLOYEE ( ID, NAME, GENDER, BIRTH, ADDRESS, PHONE, ENTRYDATE, EMAIL, DEPID, DESCS )
VALUES
(
'emp1008',
'王重阳',
1,
to_date ( '25-05-1970', 'dd-mm-yyyy' ),
'重阳宫',
'15633201447',
to_date ( '12-04-2015', 'dd-mm-yyyy' ),
'wcy@163.com',
'DEPID1001',
NULL
);
INSERT INTO EMPLOYEE ( ID, NAME, GENDER, BIRTH, ADDRESS, PHONE, ENTRYDATE, EMAIL, DEPID, DESCS )
VALUES
(
'emp1009',
'马玉',
1,
to_date ( '10-05-1980', 'dd-mm-yyyy' ),
'重阳宫',
'14455889900',
to_date ( '11-06-2017', 'dd-mm-yyyy' ),
'mayu@163.com',
'DEPID1002',
NULL
);
INSERT INTO EMPLOYEE ( ID, NAME, GENDER, BIRTH, ADDRESS, PHONE, ENTRYDATE, EMAIL, DEPID, DESCS )
VALUES
(
'emp1010',
'周伯通',
1,
to_date ( '10-05-1974', 'dd-mm-yyyy' ),
'流浪街',
'15500556699',
to_date ( '12-03-2015', 'dd-mm-yyyy' ),
'zbt@163.com',
'DEPID1002',
NULL
);
INSERT INTO EMPLOYEE ( ID, NAME, GENDER, BIRTH, ADDRESS, PHONE, ENTRYDATE, EMAIL, DEPID, DESCS )
VALUES
(
'emp1011',
'铁木真',
1,
to_date ( '10-06-1974', 'dd-mm-yyyy' ),
'蒙古包',
'13350639978',
to_date ( '12-04-2015', 'dd-mm-yyyy' ),
'tmz@163.com',
'DEPID1002',
NULL
);
INSERT INTO EMPLOYEE ( ID, NAME, GENDER, BIRTH, ADDRESS, PHONE, ENTRYDATE, EMAIL, DEPID, DESCS )
VALUES
(
'emp1012',
'完颜洪烈',
1,
to_date ( '25-09-1976', 'dd-mm-yyyy' ),
'蒙古包',
'13255023699',
to_date ( '18-03-2015', 'dd-mm-yyyy' ),
'wyhl@163.com',
'DEPID1003',
NULL
);
INSERT INTO EMPLOYEE ( ID, NAME, GENDER, BIRTH, ADDRESS, PHONE, ENTRYDATE, EMAIL, DEPID, DESCS )
VALUES
(
'emp1013',
'华筝公主',
0,
to_date ( '22-10-1997', 'dd-mm-yyyy' ),
'蒙古包',
'13122005489',
to_date ( '12-04-2017', 'dd-mm-yyyy' ),
'hzgz@163.com',
'DEPID1003',
NULL
);
INSERT INTO EMPLOYEE ( ID, NAME, GENDER, BIRTH, ADDRESS, PHONE, ENTRYDATE, EMAIL, DEPID, DESCS )
VALUES
(
'emp1014',
'托雷',
1,
to_date ( '22-10-1995', 'dd-mm-yyyy' ),
'蒙古包',
'13122005488',
to_date ( '12-04-2017', 'dd-mm-yyyy' ),
'tuolei@163.com',
'DEPID1003',
NULL
);
INSERT INTO EMPLOYEE ( ID, NAME, GENDER, BIRTH, ADDRESS, PHONE, ENTRYDATE, EMAIL, DEPID, DESCS )
VALUES
(
'emp1015',
'徐茂公',
1,
to_date ( '08-05-1971', 'dd-mm-yyyy' ),
'瓦岗寨',
'17788002599',
to_date ( '15-04-2017', 'dd-mm-yyyy' ),
'xmg@163.com',
'DEPID1005',
NULL
);
INSERT INTO EMPLOYEE ( ID, NAME, GENDER, BIRTH, ADDRESS, PHONE, ENTRYDATE, EMAIL, DEPID, DESCS )
VALUES
(
'emp1016',
'李蓉蓉',
0,
to_date ( '22-10-1997', 'dd-mm-yyyy' ),
'宫廷',
'15633220011',
to_date ( '12-09-2017', 'dd-mm-yyyy' ),
'lrongrong@163.com',
'DEPID1005',
NULL
);
INSERT INTO EMPLOYEE ( ID, NAME, GENDER, BIRTH, ADDRESS, PHONE, ENTRYDATE, EMAIL, DEPID, DESCS )
VALUES
(
'emp1017',
'李师师',
0,
to_date ( '22-10-1997', 'dd-mm-yyyy' ),
'红袖楼',
'15420369959',
to_date ( '12-09-2018', 'dd-mm-yyyy' ),
'lss@163.com',
'DEPID1005',
NULL
);
INSERT INTO EMPLOYEE ( ID, NAME, GENDER, BIRTH, ADDRESS, PHONE, ENTRYDATE, EMAIL, DEPID, DESCS )
VALUES
(
'emp1018',
'秦琼',
1,
to_date ( '22-11-1992', 'dd-mm-yyyy' ),
'瓦岗寨',
'15066339985',
to_date ( '12-09-2018', 'dd-mm-yyyy' ),
'qinqiong@163.com',
'DEPID1005',
NULL
);
INSERT INTO EMPLOYEE ( ID, NAME, GENDER, BIRTH, ADDRESS, PHONE, ENTRYDATE, EMAIL, DEPID, DESCS )
VALUES
(
'emp1019',
'罗成',
1,
to_date ( '22-11-1994', 'dd-mm-yyyy' ),
'瓦岗寨',
'15699804788',
to_date ( '15-04-2017', 'dd-mm-yyyy' ),
'luocheng@163.com',
'DEPID1005',
NULL
);
INSERT INTO EMPLOYEE ( ID, NAME, GENDER, BIRTH, ADDRESS, PHONE, ENTRYDATE, EMAIL, DEPID, DESCS )
VALUES
(
'emp1020',
'程咬金',
1,
to_date ( '10-05-1980', 'dd-mm-yyyy' ),
'瓦岗寨',
'15066332033',
to_date ( '12-09-2017', 'dd-mm-yyyy' ),
'cyj@163.com',
'DEPID1007',
NULL
);
INSERT INTO EMPLOYEE ( ID, NAME, GENDER, BIRTH, ADDRESS, PHONE, ENTRYDATE, EMAIL, DEPID, DESCS )
VALUES
(
'emp1021',
'单雄信',
1,
to_date ( '10-05-1978', 'dd-mm-yyyy' ),
'二贤庄',
'16022559988',
to_date ( '12-03-2015', 'dd-mm-yyyy' ),
'sxx@163.com',
'DEPID1007',
NULL
);
INSERT INTO EMPLOYEE ( ID, NAME, GENDER, BIRTH, ADDRESS, PHONE, ENTRYDATE, EMAIL, DEPID, DESCS )
VALUES
(
'emp1001',
'郭靖',
1,
to_date ( '22-04-1997', 'dd-mm-yyyy' ),
'大漠沙如雪',
'13345669988',
to_date ( '12-04-2017', 'dd-mm-yyyy' ),
'guojing@163.com',
'DEPID1006',
NULL
);
INSERT INTO EMPLOYEE ( ID, NAME, GENDER, BIRTH, ADDRESS, PHONE, ENTRYDATE, EMAIL, DEPID, DESCS )
VALUES
(
'emp1002',
'黄蓉',
0,
to_date ( '08-04-1998', 'dd-mm-yyyy' ),
'桃花岛',
'13115447522',
to_date ( '12-04-2017', 'dd-mm-yyyy' ),
'hrong@163.com',
'DEPID1006',
NULL
);
INSERT INTO EMPLOYEE ( ID, NAME, GENDER, BIRTH, ADDRESS, PHONE, ENTRYDATE, EMAIL, DEPID, DESCS )
VALUES
(
'emp1003',
'东邪',
1,
to_date ( '08-05-1971', 'dd-mm-yyyy' ),
'桃花岛',
'13325996633',
to_date ( '12-04-2015', 'dd-mm-yyyy' ),
'dongxie@163.com',
'DEPID1006',
NULL
);
COMMIT;
查询一下:
SELECT
*
FROM
employee;


一共21条记录。
4.10.2、修改记录
修改的关键字是UPDATE,语法如下:
UPDATE 表名
SET colu1 = val1,
colu2 = val2,
colu3 = val3…… [
WHERE
CONDITION restriction]
先添加一条记录:
INSERT INTO DEPARTMENT ( ID, NAME, CODE, NEWDATE, DESCS )
VALUES
( 'DEPIDxxxx', 'test', 'xxxxxx', to_date ( '12-10-2015', 'dd-mm-yyyy' ), 'xxxxxx' );

下面就修改新添加的记录:
-- 修改记录
UPDATE DEPARTMENT
SET descs = 'test测试',
CODE = '未知部门'
WHERE
NAME = 'test'
AND CODE = 'xxxxxx';

修改成功。
4.10.3、删除记录
删除记录的关键字是DELETE,语法如下:
DELETE
FROM
表名 [
WHERE
CONDITION restriction];
注意:中括号里的是可选项,如果没有限制条件,则是删除表中的所有内容,删除内容后要找回较麻烦,所以删除操作要谨慎。
注意delete与drop的区别:
- delete是删除表中的记录行,即表中的内容,表结构还在。
- 而drop是删除整个表的内容和结构。
下面删除上面新添加的记录,删除一般都是按照主键来删除的,因为主键是唯一。
-- 删除记录
DELETE
FROM
DEPARTMENT
WHERE
ID = 'DEPIDxxxx';

那条记录已经没有了。
4.10.4、查询记录
查询是最复杂的一个,也是实际开发中用的最多的。
4.10.4.1、简单查询
常用语法如下:
-- 无任何限制查询
SELECT * FROM 表名;
-- 查询显示若干列数据
SELECT
colu1,
colu2,
colu3,
......
FROM 表名;
-- 指定查询表和列别名
SELECT
s.id 编号,
s.NAME 姓名,
s.birth 生日
FROM 表名 s;
-- 基本查询中的条件限制:
SELECT
*
FROM 表名
WHERE 限制表达式;
以下测试:
SELECT
*
FROM
employee;

-- 查询并显示指定列
SELECT
id,
NAME,
gender,
birth,
address
FROM
employee;

-- 查询并显示指定列,为列添加别名
SELECT
id 员工编号,
NAME 员工姓名,
gender 员工性别,
birth 员工生日,
address 员工住址
FROM
employee;

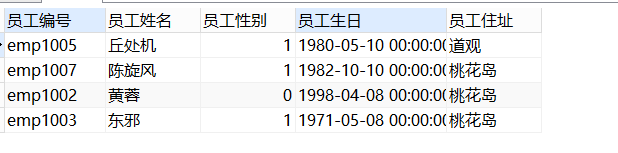
-- 按限制条件查询
SELECT
id 员工编号,
NAME 员工姓名,
gender 员工性别,
birth 员工生日,
address 员工住址
FROM
employee
WHERE
address IN ( '桃花岛', '道观' );
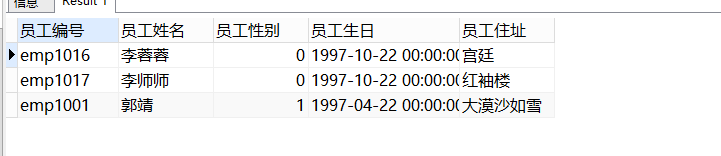
-- 按限制条件查询
SELECT
id 员工编号,
NAME 员工姓名,
gender 员工性别,
birth 员工生日,
address 员工住址
FROM
employee
WHERE
NAME LIKE '郭%'
OR
NAME LIKE '李%';
4.10.4.2、时间范围查询
时间范围内限制查询可以使用between and语句。如下:
-- 查询生日在1970年到1980年之间的员工记录
SELECT
id 员工编号,
NAME 员工姓名,
gender 员工性别,
birth 员工生日,
address 员工住址
FROM
employee
WHERE
birth BETWEEN to_date ( '1970-1-1', 'yyyy-mm-dd' )
AND to_date ( '1980-1-1', 'yyyy-mm-dd' );

查询结果是正确的。
4.10.4.3、去除重复记录查询
去重数据使用关键字distinct即可。如下:
-- 查询所有员工的地址,不许重复
SELECT DISTINCT
address 所有地址
FROM
employee;

可以看到查询结果正确。
4.10.4.4、查询结果排序
Oracle查询语句中使用order by语句对查询结果进行排序。
- asc:设置自然排序(升序/正序),可省略此关键字。
- desc:设置倒序排序(倒序/降序)。
如下:
-- 按照性别升序
SELECT
id 员工编号,
NAME 员工姓名,
gender 员工性别,
birth 员工生日,
address 员工住址
FROM
employee
ORDER BY
gender;

结果正确。
-- 按照出生日期降序
SELECT
id 员工编号,
NAME 员工姓名,
gender 员工性别,
birth 员工生日,
address 员工住址
FROM
employee
ORDER BY
birth DESC;

可以看到生日最晚的排在前面,出生日期越早的越往后面排。
4.10.4.5、自然连接查询
表连接查询的目的在于组合多表中的数据作为查询结果显示。
自然连接(NATURAL JOIN)是一种特殊的等值连接,将表中具有相同名称的列自动进行匹配,关键字是NATURAL JOIN。要进行自然连接的话,必须保证表的列名相同,且相同列名的数据类型也相同,否则是无法进行连接的。
person表数据如下:

person2表数据如下:
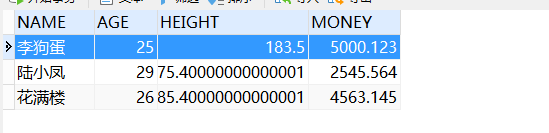
姓名为李狗蛋的这条记录是完全重复的,那么可以使用自然连接将其查出来:
--使用自然连接查询
SELECT
*
FROM
person
NATURAL JOIN person2;

4.10.4.6、内连接查询
设置连接条件,只匹配符合条件的数据进行组合,使用关键字inner join,连接多张表。内连接通常使用where或on关键字设置连接条件,使用on关键字是标准方式,连接条件一般是主外键,如下:
-- inner join on内连接多表连接查询
SELECT
dep.NAME 部门名称,
emp.id 员工编号,
emp.NAME 员工姓名,
emp.birth 员工生日,
emp.address 员工住址
FROM
DEPARTMENT dep
INNER JOIN employee emp
ON dep.id = emp.DEPID;

4.10.4.7、外连接查询
设置连接条件,以主连接表作为最终连接从参考,分为左外连接left join on和右外连接right join on。
语法如下:
-- 左外连接
SELECT
*
FROM
表 1 LEFT [ OUTER ]
JOIN 表 2 ON 表 1.id = 表 2.s_id;
-- 右外连接
SELECT
*
FROM
表 1 RIGHT [ OUTER ]
JOIN 表 2 ON 表 1.id = 表 2.s_id;
先在部门表中添加一条记录:

这个测试部是新添加的,这个部门没有员工。
下面是左连接的例子:
-- left join on左连接
-- 左连接是以左表为主表
SELECT
dep.NAME 部门名称,
emp.id 员工编号,
emp.NAME 员工姓名,
emp.birth 员工生日,
emp.address 员工住址
FROM
DEPARTMENT dep
LEFT JOIN employee emp
ON dep.id = emp.DEPID;

部门表为主表,部门表的所有记录都会显示出来。
然后以员工表为主表测试:
SELECT
dep.NAME 部门名称,
emp.id 员工编号,
emp.NAME 员工姓名,
emp.birth 员工生日,
emp.address 员工住址
FROM
employee emp
LEFT JOIN DEPARTMENT dep
ON dep.id = emp.DEPID;
员工表为主表,员工表中的记录都会显示出来,可以看到没有测试部的记录,因为现在部门表是从表了。
下面是右连接的例子:
-- right join on右连接查询
-- 右连接以右表为主表
SELECT
dep.NAME 部门名称,
emp.id 员工编号,
emp.NAME 员工姓名,
emp.birth 员工生日,
emp.address 员工住址
FROM
employee emp
RIGHT JOIN DEPARTMENT dep
ON dep.id = emp.DEPID;

现在的主表是部门表,部门表的所有记录会显示。
再测试:
SELECT
dep.NAME 部门名称,
emp.id 员工编号,
emp.NAME 员工姓名,
emp.birth 员工生日,
emp.address 员工住址
FROM
DEPARTMENT dep
RIGHT JOIN employee emp
ON dep.id = emp.DEPID;

现在员工表是主表,没有测试部员工记录。
注意:注意区分外连接的主表和从表,左连接中,left join on前面的是主表,后面是从表,right join on前面的是从表,后面的是主表。
4.10.4.8、Union联合查询
Union对两个查询结果集进行合并操作,将完全重复的记录剔除(合并重复行),相当于合并操作之后再执行一次distinct操作。
提示:Union可以对字段名不同但数据类型相同的结果集进行合并,Union只允许对最终合并的结果集进行order by。
Union查询的限制条件:
- 两个数据源或结果集必须具有相同的列数量。
- 依次按照2个数据源的字段顺序合并。
- 相互合并的字段名称可以不同,但数据类型必须相同或者是兼容类型。
- 使用Union前数据源字段名称作为最终结果集字段名称。
person表数据:

person2表数据:
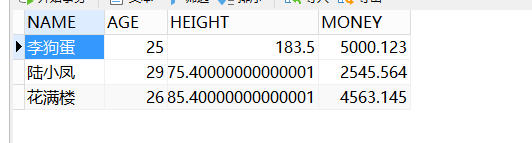
李狗蛋这条记录是完全重复的。现在使用Union联合查询:
-- Union联合多表查询
-- 相当于多个查询结果取并集
SELECT * FROM person
UNION
SELECT * FROM person2;

查询结果只有1条李狗蛋的记录。
关键:Union联合查询是对多个查询结果进行合并,取并集。
4.10.4.9、Union all联合查询
union all查询与union同为并集操作,但是union all查询并不删除最终结果集中的重复记录,因此union all的操作要快于union。测试如下:
-- Union all联合多表查询
-- 相当于多个查询结果取并集,不去除重复记录
SELECT * FROM person
UNION ALL
SELECT * FROM person2;

李狗蛋有2条记录,并没有去除重复记录。
关键:Union all联合查询为取并集,将多个查询结果取并集,不去除重复记录。
4.10.4.10、Intersect联合查询
Intersect查询用于获得两个结果集的1,也就是只有都出现在两个表中的数据才会被查询返回,intersect多用于某个表对于另外一个表完全重复数据行的筛选。intersect和natural join连接查询功能非常类似。测试如下:
-- Intersect联合查询取重复记录
SELECT * FROM person
INTERSECT
SELECT * FROM person2;

筛选出了重复记录李狗蛋。
4.10.4.11、Minus联合查询
minus联合查询称之为减集,如A minus B则A中和B中同时有的数据将会被剔除掉而只保留A中有而B中没有的数据,也就是先做交集,再做补集。测试如下:
-- Minus联合查询先做交集
-- 再做person表的补集
SELECT * FROM person
MINUS
SELECT * FROM person2;
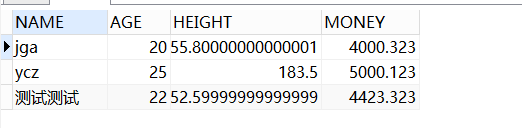
取person表相对于交集的补集。
和person表对比:
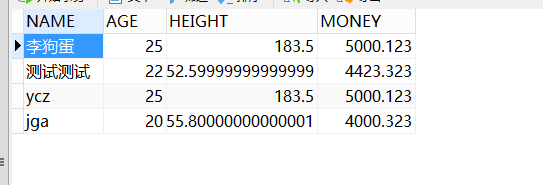
交集李狗蛋没有了。
再测试:
-- Minus联合查询先做交集
-- 再做person2表的补集
SELECT * FROM person2
MINUS
SELECT * FROM person;
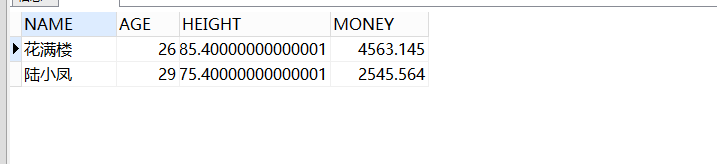
李狗蛋也没有了,取person2表相对于交集的补集。对比person表:
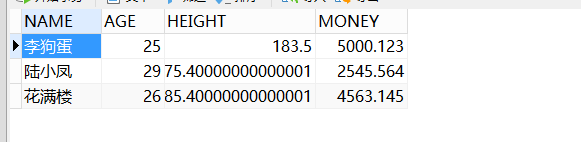
关键:取交集的补集,注意补集是相对于主表而言的,Minus前面的表即为主表。
4.10.4.12、子查询
子查询是指嵌套在查询语句中的查询语句,子查询出现的位置一般为条件语句,如where条件,Oracle会首先执行子查询,然后执行父查询。
子查询整个结果集会和父结果集中每个结果进行预算,通常效率比较低,因此建议在实际应用中如果能够不使用子查询则尽量少用。
以下进行测试:
-- 子查询查询没有员工的部门
SELECT
dep.id 部门编号,
dep.NAME 部门名称
FROM
DEPARTMENT dep
WHERE
dep.id NOT IN ( SELECT depid FROM employee );

4.10.4.13、查询结果填充表
可以将查询结果填充进表里。如下:
建立新表,并将查询的结果填充进此表:
-- 创建新表
-- 并将男性员工的记录填充进此表
CREATE TABLE man_employee AS
SELECT
id,
NAME,
birth,
gender,
address
FROM
employee
WHERE
gender = '1';
查看man_employee表数据:

全部是男性员工记录,没问题。
将查询记录填充进已存在的表:
-- 将所有女性员工记录插进表里
INSERT INTO man_employee
SELECT
id,
NAME,
birth,
gender,
address
FROM
employee
WHERE
gender = '0';

增加了5条女性记录。
4.10.4.14、分页查询
分页的目的在于将过多符合条件的结果记录按照自定义数量显示数据,从而减少内存开销并提高查询效率。
Oracle中通常使用联合、子查询以及结合伪列rowid和rownum实现对结果进行分页。以下介绍3种方式实现记录的分页。
(1)minus结合rownum查询分页
可以使用minus联合查询结合rownum来实现分页查询,因为rownum是对应记录条数的。如下:
-- 第1页记录
SELECT * FROM employee
WHERE rownum <= 10
minus
SELECT * FROM employee
WHERE rownum <= 0;
-- 第2页记录
SELECT * FROM employee
WHERE rownum <= 20
minus
SELECT * FROM employee
WHERE rownum <= 10;
-- 第3页记录
SELECT * FROM employee
WHERE rownum <= 30
minus
SELECT * FROM employee
WHERE rownum <= 20;



拿查第2页记录的SQL语句来分析一下:
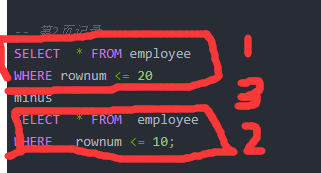
- 先查询rownum小于等于20的所有记录,也就是20条。
- 然后查询rownum小于等于10的所有记录,也就是10条。
- 然后按照minus联合查询,先取交集,也就是前面10条记录,再对20条记录取这10条记录的补集,也就是后面的10条记录,那么就是第二页需要的数据。
其实可以看到,这种方法的效率是非常低下的,因为要做太多事情。虽然可以达到分页的目的,但是效率太低下了,不建议使用。
(2)子查询结合rownum查询分页
可以使用子查询结合rownum来实现分页,如下:
-- 第1页
SELECT
*
FROM
( ( SELECT rownum rn, e2.* FROM ( SELECT * FROM employee e ) e2 WHERE rownum <= 10 ) e3 )
WHERE
e3.rn >= 1;
-- 第2页
SELECT
*
FROM
( ( SELECT rownum rn, e2.* FROM ( SELECT * FROM employee e ) e2 WHERE rownum <= 20 ) e3 )
WHERE
e3.rn >= 11;
-- 第3页
SELECT
*
FROM
( ( SELECT rownum rn, e2.* FROM ( SELECT * FROM employee e ) e2 WHERE rownum <= 30 ) e3 )
WHERE
e3.rn >= 21;



这种更不建议用,查询里面嵌套了2个子查询,太过复杂,甚至还不如第1种方式。
(3)子查询结合rowid、rownum分页
可以子查询结合rowid、rownum来实现分页,如下:
-- 第1页
SELECT
*
FROM
employee
WHERE
rowid IN ( SELECT rowid FROM employee WHERE rownum <= 10 )
AND rownum <= 10;
-- 第2页
SELECT
*
FROM
employee
WHERE
rowid not IN ( SELECT rowid FROM employee WHERE rownum <= 10 )
AND rownum <= 10;
-- 第3页
SELECT
*
FROM
employee
WHERE
rowid NOT IN ( SELECT rowid FROM employee WHERE rownum <= 20 )
AND rownum <= 10;



注意第1页的SQL有点不一样,后面的n-1页SQL差不多。推荐使用这种子查询结合rowid、rownum的形式实现记录分页。
4.11、Oracle预定义函数
Oracle数据库系统中定义了很多的函数(预定义)。这些函数能够完成本身特有的数据操作功能,执行效率更高并重复使用。Oracle中的预定义函数按照对数据的操作执行特征可以分为2种:单行函数和多行函数。
4.11.1、单行函数
单行函数对每个记录只执行一次。常见的单行函数分为以下几种:
4.11.1.1、字符串函数
常见的字符串函数如下:
- substr(source,start,length):提取子串。
- instr(source,target,start,rank):查找字符串,返回索引值。
- ltrim(source):左侧去空格。
- rtrim(source):右侧去空格。
- trim(source):去空格,不分左右。
- to_char(date,format):按指定格式转换日期。
- lpad(source,length,prefix):左侧补齐。
- rpad(source,length,prefix):右侧补齐。
- lower(source):转换小写。
- upper(source):转换大写。
- initcap(source):首字母变大写。
- length(source):获取长度。
- replace(source,old,new):字符串替换。
- concat(left,right):连接字符串,可使用||代替此函数。
以下测试:
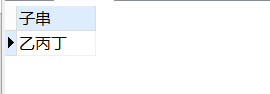
-- 截取字符串
SELECT
substr( '甲乙丙丁戊己庚辛', 2, 3 ) 子串
FROM
DUAL;
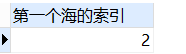
-- 查找第一个海的位置
SELECT
instr( '上海人来自海上', '海', 1, 1 ) 索引
FROM
DUAL;
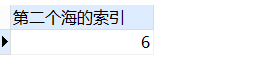
-- 查找第二个海的位置
SELECT
instr( '上海人来自海上', '海', 1, 2 ) 索引
FROM
DUAL;
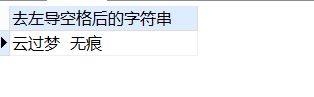
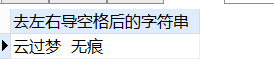
-- 去掉左导空格
SELECT
ltrim( ' 云过梦 无痕 ' ) 去左导空格后的字符串
FROM
DUAL;
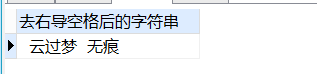
-- 去掉右导空格
SELECT
rtrim( ' 云过梦 无痕 ' ) 去右导空格后的字符串
FROM
DUAL;
--去掉左右导空格
SELECT
trim( ' 云过梦 无痕 ' ) 去左右导空格后的字符串
FROM
DUAL;
-- 时间格式转换为字符串格式
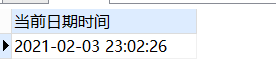
SELECT
to_char ( sysdate, 'yyyy-mm-dd hh24:mm:ss' ) 当前日期时间
FROM
DUAL;
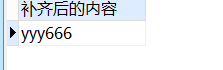
-- 左侧补齐
SELECT
lpad( '666', 6, 'y' ) 补齐后的内容
FROM
DUAL;
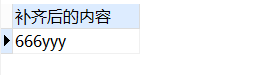
-- 右侧补齐
SELECT
rpad( '666', 6, 'y' ) 补齐后的内容
FROM
DUAL;
-- 转换成大写
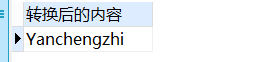
SELECT
upper( 'yanchengzhi' ) 转换后的内容
FROM
DUAL;
-- 转换成小写
SELECT
lower( 'AOTEMAN' ) 转换后的内容
FROM
DUAL;
-- 首字母转换为大写
SELECT
initcap ( 'yanchengzhi' ) 转换后的内容
FROM
DUAL;


-- 获取字符串长度
SELECT
length( '云过梦无痕' ) 字符串长度
FROM
DUAL;
-- 替换字符串中的旧串
SELECT REPLACE
( '皮里布袋戏', '皮里', '霹雳' ) 新的内容
FROM
DUAL;
-- 连接字符串
SELECT
concat( 'yan', 'cheng' ) 连接后的内容
FROM
DUAL;
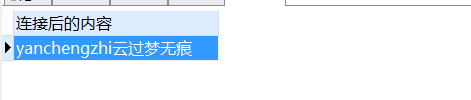
-- 使用||可多重连接
SELECT
( 'yan' || 'cheng' || 'zhi' || '云过' || '梦无痕' ) 连接后的内容
FROM
DUAL;



这是常用的一些函数,其他的可自行查阅相关API文档。
4.11.1.2、日期时间函数
常用的日期时间函数如下:
- to_date(datestr,format):将字符串按照指定格式转换为日期。
- to_timestamp(datestr,format):将字符串按照指定格式转换为日期时间。
- add_months(date,i):在指定日期上加上i个月,i可以为负数。
- last_day(date):返回当前日期月份的最后一天。
- months_between(date1,date2):返回日期date1和date2相差的月数。
- current_date:返回当前系统日期的字符串形式。
- current_timestamp:返回当前系统日期和时间的字符串形式。
- sysdate:返回当前系统日期的字符串形式。
- systimestamp:返回当前系统日期和时间的字符串形式。
- extract(year from date):提取日期年份。
- extract(month from date):提取日期月份。
- extract(day from date):提取日期天。
- extract(hour from date):提取日期时。
- extract(minute from date):提取日期分。
- extract(second from date):提取日期秒。
以下进行测试:
---字符串转换为时间格式
SELECT
to_date ( '1995-09-18', 'yyyy-MM-dd' ) 当前日期
FROM
DUAL;
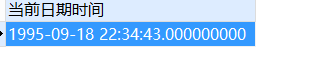
-- 字符串转换为日期时间格式
SELECT
to_timestamp ( '1995-09-18 22:34:43', 'yyyy-MM-dd HH24:mi:ss' ) 当前日期时间
FROM
DUAL;
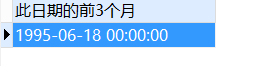
-- 在指定日期的基础上增加几个月,可以是负的
SELECT
add_months ( to_date ( '1995-09-18', 'yyyy-MM-dd' ),-3 ) 此日期的前3个月
FROM
DUAL;
-- 获取当前月的最后一天
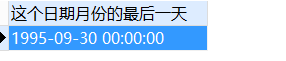
SELECT
last_day( to_date ( '1995-09-18', 'yyyy-MM-dd' ) ) 这个日期月份的最后一天
FROM
DUAL;
-- 获取两个日期之间的相差月数,前面的减后面的
SELECT
months_between ( to_date ( '1995-09-18', 'yyyy-MM-dd' ), to_date ( '2000-05-21', 'yyyy-MM-dd' ) ) 两日期的月份之差
FROM
DUAL;


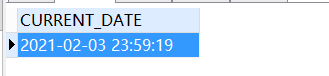
-- 获取当前日期
SELECT CURRENT_DATE
FROM
DUAL;
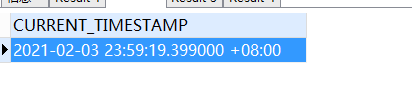
-- 获取当前日期时间
SELECT CURRENT_TIMESTAMP
FROM
DUAL;
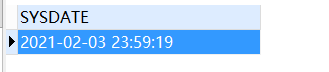
-- 获取当前日期
SELECT
sysdate
FROM
DUAL;
-- 获取当前日期时间
SELECT
systimestamp
FROM
DUAL;

-- 提取系统日期时间年份
SELECT
extract( YEAR FROM sysdate ) 当前年
FROM
DUAL;
-- 提取系统日期时间月份
SELECT
extract( MONTH FROM sysdate ) 当前月
FROM
DUAL;
-- 提取系统日期时间的天
SELECT
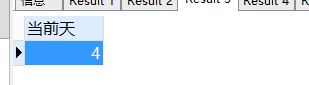
extract( DAY FROM sysdate ) 当前天
FROM
DUAL;
-- 提取系统日期时间的时,与外国有8小时时差
SELECT
extract( HOUR FROM CURRENT_TIMESTAMP ) 当前时
FROM
DUAL;
-- 提取系统日期时间的分
SELECT
extract( MINUTE FROM CURRENT_TIMESTAMP ) 当前分
FROM
DUAL;
-- 提取系统日期的秒
SELECT
extract( SECOND FROM CURRENT_TIMESTAMP ) 当前秒
FROM
DUAL;





4.11.1.3、数学计算函数
Oracle中提供的数学函数可以处理日常使用到的大多数数学运算,在使用数学运算时通常应保证被操作的数据是数值类型,如果是字符串则在保证字符串中是数字时是可以使用这些数学函数的。
常用的计算函数如下:
- abs函数:abs函数是计算绝对值的函数,参数可以是一个值类型,也可以是字符串类型,如果是字符串类型则必须保证字符序列是数字。
- round(sourcenum,decimallen):其中decimallen是可选参数,设置小数点保留位数,如果省略则不保留小数。
- ceil(number):函数有1个参数,该函数将参数向上取整,以获得大于等于该参数的最小整数。
- floor(number):与ceil函数相反,用于返回小于等于某个参数的最大整数。
- sign(number):sign返回参数的正负性,正数则返回1,负数则返回-1,0则返回0。
- sqrt(number):返回平方根,number为非负数。
- power(m,n):返回m的n次幂结果。
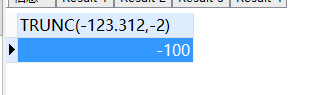
- trunc(number,len):用于截取部分数字,类似于round函数,与round函数不同的是,该函数不对数值进行四舍五入处理,而是直接截取。
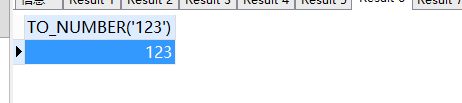
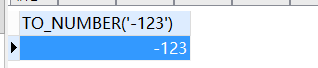
- to_number函数:将给定的数值(字符串类型)转换为值类型。
以下进行测试:
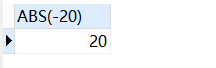
-- 计算绝对值
SELECT
abs( 20 )
FROM
DUAL;
SELECT
abs( - 20 )
FROM
DUAL;
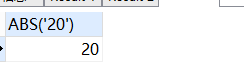
SELECT
abs( '20' )
FROM
DUAL;
--此语句失效,字符串中包含了无效字符 s SELECT
abs( '20s' )
FROM
DUAL;

-- 保留有效数字
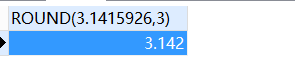
SELECT
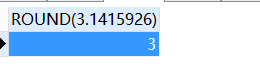
round( 3.1415926, 3 )
FROM
DUAL;
SELECT
round( 3.1415926 )
FROM
DUAL;
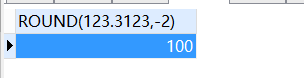
SELECT
round( 123.3123,- 2 )
FROM
DUAL;
SELECT
ceil( 5.12 )
FROM
DUAL;-- 计算大于等于该数的最小整数
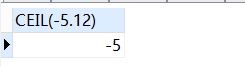
SELECT
ceil( - 5.12 )
FROM
DUAL;
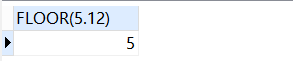
SELECT
floor( 5.12 )
FROM
DUAL;-- 计算小于等于该数的最大整数
SELECT
floor( - 5.12 )
FROM
DUAL;


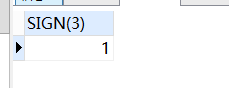
-- sign函数返回数的正负
-- 负数返回- 1
SELECT
sign( - 3 )
FROM
DUAL;
-- 正数返回 1
SELECT
sign( 3 )
FROM
DUAL;
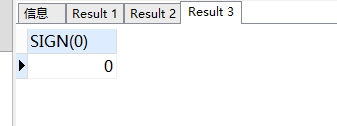
-- 0返回0
SELECT
sign( 0 )
FROM
DUAL;

-- 计算平方根
SELECT
sqrt( 9 )
FROM
DUAL;
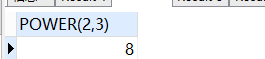
-- 计算指数运算,2的3次方
SELECT
power( 2, 3 )
FROM
DUAL;
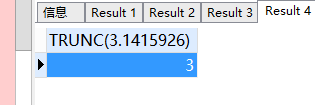
-- 截取小数位数,不进行四舍五入
SELECT
trunc ( 3.1415926, 3 )
FROM
DUAL;
SELECT
trunc ( 3.1415926 )
FROM
DUAL;
SELECT
trunc ( - 123.312,- 2 )
FROM
DUAL;
SELECT
to_number ( '123' )
FROM
DUAL;
-- 将字符串转换为数值类型
SELECT
to_number ( '-123' )
FROM
DUAL;


4.11.1.4、其他函数
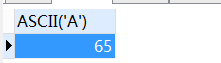
- ascii(number|string):返回给定数值或字符串首字母的ascii数字值。
- chr(number|string):返回给定数值的字母形式。
- nvl(obj1,obj2):判断空,如果obj1不为空则返回obj1,如果obj1为空则返回obj2。
- nvl2(target,res1,res2):判断空,如果target不为空则返回res1,否则返回res2。
以下进行测试:
-- 返回字符对应的ASCII码值
SELECT
ascii( 'A' )
FROM
DUAL;
-- 返回字符串首字母对应的ASCII码值
SELECT
ascii( 'abcasd' )
FROM
DUAL;
SELECT
chr ( '121' )
FROM
DUAL;
SELECT
chr ( 121 )
FROM
DUAL;
-- 返回数字或数字型字符对应的ASCII字符
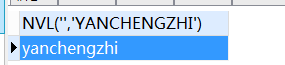
SELECT
nvl ( '', 'yanchengzhi' )
FROM
DUAL;
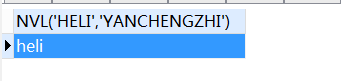
SELECT
nvl ( 'heli', 'yanchengzhi' )
FROM
DUAL;
-- 返回非空的字符串
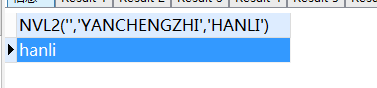
SELECT
nvl2 ( '', 'yanchengzhi', 'hanli' )
FROM
DUAL;
-- 返回非空的字符串
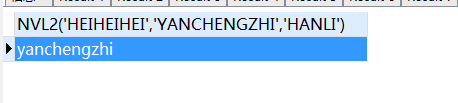
SELECT
nvl2 ( 'heiheihei', 'yanchengzhi', 'hanli' )
FROM
DUAL;



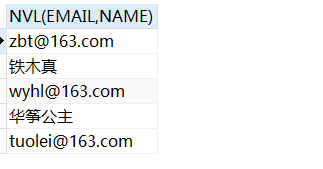
-- 邮箱为空,则返回员工姓名,不为空则返回邮箱
SELECT
nvl ( email, name )
FROM
employee;
SELECT
'员工' || name || nvl2 ( email, '有邮箱', '没有邮箱' )
FROM
employee;

4.11.2、多行函数
聚合函数又称为多行函数,在对数据库表进行查询时聚合函数对符合要求的多个数据行一起实施聚合逻辑运算,一个聚合函数最终返回一个聚合值。
常用的聚合函数如下:
- count():统计数据行条目数。
- max():获取最大值。
- min():获取最小值。
- sum():统计总和。
- avg():统计平均数。

先统计这张表,测试如下:
-- 统计员工人数,按照主键统计
SELECT
count( id ) 总人数
FROM
e2;
-- 统计员工的最高工资和最低工资
SELECT
max( SALARY ) 员工最高薪水,
min( SALARY ) 员工最低薪水
FROM
e2;
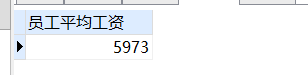
-- 统计员工的平均工资
SELECT
round( avg( SALARY ) ) 员工平均工资
FROM
e2;
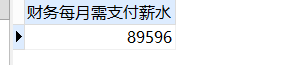
-- 统计财务部每月需发放薪水
SELECT
sum( SALARY ) 财务每月需支付薪水
FROM
e2;


4.11.3、分组聚合统计
Oracle在聚合函数使用数据统计前可以实现先分组然后再聚合计算,Oracle中使用group by进行分组并且支持多列分组。
在实现分组聚合过程中Oracle数据库系统也支持对分组后进行筛选;分组后的筛选使用having字句在group by后面实现对分组进行筛选限制。
以下进行测试:
-- 连接查询并按照部门进行分组聚合
SELECT
dep.NAME 部门名称,
emp.id 员工编号,
emp.NAME 员工姓名,
emp.birth 员工生日,
emp.address 员工住址
FROM
DEPARTMENT dep
INNER JOIN EMPLOYEE emp ON dep.ID = emp.DEPID
GROUP BY
dep.NAME,
emp.id,
emp.NAME,
emp.birth,
emp.address
ORDER BY
dep.NAME;

-- 连接查询并按照部门进行分组聚合
-- 使用having子句筛选
SELECT
dep.NAME 部门名称,
emp.id 员工编号,
emp.NAME 员工姓名,
emp.birth 员工生日,
emp.address 员工住址
FROM
DEPARTMENT dep
INNER JOIN EMPLOYEE emp ON dep.ID = emp.DEPID
GROUP BY
dep.NAME,
emp.id,
emp.NAME,
emp.birth,
emp.address
HAVING
emp.address NOT IN ( '桃花岛', '道观','蒙古包' )
ORDER BY
dep.NAME;

可以看到,使用having子句筛选出了住址不在桃花岛、道观、蒙古包的所有员工记录。
-- 连接查询并按照部门进行分组聚合
-- 使用having子句筛选出非销售部、市场部的员工
SELECT
dep.NAME 部门名称,
emp.id 员工编号,
emp.NAME 员工姓名,
emp.birth 员工生日,
emp.address 员工住址
FROM
DEPARTMENT dep
INNER JOIN EMPLOYEE emp ON dep.ID = emp.DEPID
GROUP BY
dep.NAME,
emp.id,
emp.NAME,
emp.birth,
emp.address
HAVING
dep.NAME NOT IN ( '市场部','销售部' )
ORDER BY
dep.NAME;

查询结果并不包含市场部和销售部的员工。
4.12、视图
在Oracle数据库中视图是数据库中特有的对象。视图主要是用于数据查询,它不会存储数据(物化视图除外)。这是视图和数据表的重要区别。视图的数据来源于一个或多个表中的数据,可以利用视图进行查询、插入、更新和删除数据,操作视图就是间接操作数据库表。通常情况下,视图主要用于查询,不提倡通过视图而更新与视图相关的表,因为视图中的数据只是一个或多个表中的局部数据(部分数据)。
Oracle中的视图有关系视图、内嵌视图、物化视图等。
4.12.1、关系视图
关系视图是3种视图中比较简单和常用的视图。可以将关系视图看作对简单或复杂查询的定义。它的输出可以看作一个虚拟的表,该表的数据是由其它基础数据表提供的。由于关系视图并不存储真正的数据,因此占用数据库资源也较少。
(1)创建视图
语法如下:
CREATE OR REPLACE VIEW 视图名称 AS
SELECT
表 OR其它视图……
视图的关键字是VIEW。
以下创建视图:
-- 查询emp表中湖北和重庆的员工记录
-- 并创建视图保存查询结果
CREATE OR REPLACE VIEW view_demo AS
SELECT
*
FROM
emp
WHERE
address LIKE '湖北%'
OR address LIKE '重庆%';
然后查询视图:
SELECT
*
FROM
view_demo;

通过Navicat查看:

提示:视图中的数据来源于实际的物理表,修改视图中的数据实际就是更改视图数据的来源表,在通常情况下不提倡通过视图修改数据。视图实际上是一种虚拟表,可把它当做表来处理。
(2)只读关系视图
只提供数据源的查询,不支持修改,建议用这种。
语法如下:
CREATE OR REPLACE VIEW 视图名称 AS
SELECT
表 OR其它视图……
WITH READ only;
实际上只是在普通视图的基础上加了WITH READ only来进行限制而已。
以下创建一个只读视图:
-- 创建只读视图
CREATE OR REPLACE VIEW view_demo_read_only AS
SELECT
*
FROM
emp
WHERE
address LIKE '湖北%'
OR address LIKE '重庆%'
WITH READ only;
(3)删除视图
删除视图并不会影响源表中数据,删除的只是副本,但是修改视图源表中的相应数据会发生改变。
语法:drop view 视图名称。
现在将可以修改的视图删除掉,如下:
--删除视图
DROP VIEW view_demo;
再查询:
SELECT
*
FROM
view_demo;

视图已经删除了。
4.12.2、内嵌视图
内嵌视图是非存在于Oracle数据库中的对象,它只是查询过程中生成的结果数据集;内嵌视图通常以子查询的方式出现在SQL操作中。内嵌视图通常对于数据库的开销有更大的优势,可以适当使用。内嵌视图的创建不使用create关键字创建,通常在查询语句中创建内嵌视图,在执行完SQL操作后,内嵌视图会自动销毁。
4.12.3、物化视图
物化视图也叫快照,物化视图和表一样生成物理文件并占用磁盘空间,对于数据库及磁盘空间都有一定的开销维护,在物化视图上可以像普通表一样创建索引。
创建语法:
CREATE materialized VIEW 视图名称 AS
SELECT
*
FROM
表名;
实际上开发中用的最多的是关系视图,内嵌视图和物化视图作为了解即可。
4.13、PL/SQL块
PL/SQL是过程化语言(Procedural Language/SQL)。是对SQL语句的扩展,增加了编程语言的特点,所以PL/SQL就是把数据操作和查询语句组织在PL/SQL代码的过程性单元中,通过逻辑判断、循环等操作实现复杂功能,在定义复杂业务的函数、过程及建立触发器时使用。PL/SQL中通常只能使用数据DML(数据操纵)语言和DCL(数据控制)语言,如:insert、update、select into、delete、commit、rollback、savepoint。不允许使用DDL(数据定义)语言create、drop、alter等。
4.13.1、组成结构
语法如下:
declare
变量1 类型[长度];
变量2 类型[长度];
begin
数据处理语句;
exception
异常处理语句;
end;
一般包括声明单元和执行单元,执行单元中包含异常处理单元。声明单元是可选的,执行单元是必须的。
declare声明单元
PL/SQL使用declare关键字声明变量定义,此单元必须在PL/SQL的最前面。
变量的限制如下:
- 通常变量名称可以包括字母、下划线、数字、#、$。
- 变量名称不能超过30个字符。
- 第一个字符必须是字母。
- 不区分大小写。
- 不能使用任何关键字。
例子:
declare
name varchar2(64);--声明变量
age int:=25;--声明变量并赋值
address String(64);--声明编程类型变量
4.13.2、PL/SQL编程变量类型
- char:定长字符类型,包括子类character、string、rowid、Nchar,最长限制在2000个字符。
- varchar2:可变字符类型,包括varchar、string、nvarchar2最长限制在4000个字符。
- number(p,s):值类型,包括子类int、integer、smallint、dec、double。
- date:日期类型。
- boolean:布尔类型。
- %type:复合类型变量。
- %rowtype:复合类型变量。
复合类型单独说明:
(1)%type自定义复合类型
%type可存储多个数据且可以是不同类型的组合。如下:
declare
type T_record is Record(
t_1 students.id%type,
t_2 students.name%type,
t_3 students.age%type
);
T_var T_record;
begin
select id,name,age into T_var from students2 where id ='stu001';
dbms_output.put_line(to_char(T_var.t_3));
end;
(2)%rowtype自定义复合类型
%rowtype是%type类型的扩展,可存储查询返回数表的一个未知列数量及类型的功能,使用更加方便。如下:
declare
R_var students %rowtype;
begin
select * into R_var from students where id= 'stu001';
dbms_output.put_line(R_var.name);
end;
以下使用SQL进行测试,使用PL/SQL DeveloperGUI工具进行,因为Navicat不支持,PL/SQL Developer是Oracle开发的产品,对于Oracle数据库的支持比较好。
declare
-- declare和begin之间是声明单元
-- 一般对变量进行声明
name string(64);
age int:=25;
begin
-- begin和end之间是执行单元
name:='花满楼';
age:=age+2;
-- dbms为输出语句
dbms_output.put_line('大侠姓名'||name||',年龄'||age||'岁!');
end;
执行,输出如下:

-- 先查询除数为0的错误编号
select 7/0 from dual;
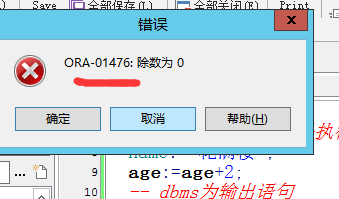
除数为0的错误编号为-1476。下面开始写PL/SQL块:
declare
m int:=5;
n int;
s int;
-- 声明异常变量
error_zero exception;
-- 异常初始化
pragma exception_init(error_zero,-1476);
begin
n:=2;
s:=m/n;
-- 正常执行的情况
dbms_output.put_line(m||'除以'||n||'的结果是:'||s);
-- 发生异常时
exception when error_zero then
dbms_output.put_line('发生错误,0不能作为除数!');
end;
执行:
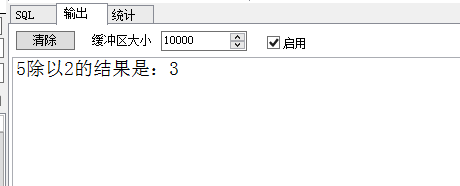
然后将修改n的值为0,如下:
declare
m int:=5;
n int;
s int;
-- 声明异常变量
error_zero exception;
-- 异常初始化
pragma exception_init(error_zero,-1476);
begin
-- n:=2;
n:=0;
s:=m/n;
-- 正常执行的情况
dbms_output.put_line(m||'除以'||n||'的结果是:'||s);
-- 发生异常时
exception when error_zero then
dbms_output.put_line('发生错误,0不能作为除数!');
end;
再执行:

--%type定义复合类型变量
declare
type E_line is record(
e_name emp.name %type,
e_sex emp.sex %type,
e_address emp.address %type
);
E_var E_line;
begin
-- 将查询结果装进E_var中
select name,sex,address into E_var from emp where id='emp1005';
dbms_output.put_line('姓名:'||E_var.e_name);
dbms_output.put_line('性别:'||E_var.e_sex);
dbms_output.put_line('住址:'||E_var.e_address);
end;
执行:

-- %rowtype自定义复合类型变量
declare
row_emp emp %rowtype;
id_eq string(64):='emp1003';
begin
-- 将查询结果装进row_emp类型中
select * into row_emp from emp where id=id_eq;
dbms_output.put_line('姓名:'||row_emp.name);
dbms_output.put_line('性别:'||row_emp.sex);
dbms_output.put_line('生日:'||to_char(row_emp.birth,'yyyy-MM-dd'));
dbms_output.put_line('电话:'||row_emp.phone);
dbms_output.put_line('住址:'||row_emp.address);
end;
执行:

4.13.3、if else基本逻辑语句
if可以单独使用,else必须要结合if使用,elsif等价于Java的else if语句。
语法:
if 布尔表达式 then 满足if执行的语句;
elsif 布尔表达式 then 满足if执行的语句;
else 对应else执行的语句;
end if;
以下进行测试:
-- 测试if else语句
declare
age int:=25;
mess string(60):='已经老大不小了,赶紧找女朋友!';
mess2 string(20):='小学生一个!';
begin
if age<18 then
dbms_output.put_line(mess2);
else
dbms_output.put_line(mess);
end if;
end;
执行:

-- 测试if elsid语句
declare
score int:=85;
begin
if (score>=0 and score<=100) then
if score>=90 then
dbms_output.put_line('成绩优秀!');
elsif score>=80 then
dbms_output.put_line('成绩良好!');
elsif score>=70 then
dbms_output.put_line('成绩一般!');
elsif score>=60 then
dbms_output.put_line('成绩刚好及格!');
end if;
else
dbms_output.put_line('成绩合法区间:[0,100]!');
end if;
end;
执行:

4.13.4、case when语句
类似于Java的switch 语句。
语法:
when 布尔表达式 then 执行语句;
when 布尔表达式 then 执行语句;
else 执行语句;
end case;
以下进行测试:
-- 测试Case when语句
declare
score int:=60;
begin
if (score>=0 and score<=100) then
case
when score>=90 then
dbms_output.put_line('成绩优秀!');
when score>=80 then
dbms_output.put_line('成绩良好!');
when score>=70 then
dbms_output.put_line('成绩一般!');
when score>=60 then
dbms_output.put_line('成绩刚好及格!');
end case;
else
dbms_output.put_line('成绩合法区间:[0,100]!');
end if;
end;
执行:

4.13.5、loop循环语句
语法如下:
loop
[业务处理语句]
[exit]--退出循环
end loop;
以下进行测试:
--测试loop循环
--判断并统计1到100之间有多少个能被10整除的数
declare
num int:=1;
total int:=0;
begin
loop
if(num mod 10 = 0) then
total:=total+1;
dbms_output.put_line('第'||total||'个数是:'||to_char(num));
end if;
num:=num+1;
-- 大于100时退出循环
if num>100 then
exit;
end if;
end loop;
dbms_output.put_line('1到100之间能被10整除的数一共有:'||total||'个!');
end;
执行:

4.13.6、while循环语句
语法如下:
while 布尔表达式 loop
[业务处理语句]
[循环变量更新]
end loop;
以下进行测试:
--使用while循环完成1到100之间的累加和计算
declare
sums int:=0;
num int:=1;
begin
while(num<=100) loop
sums:=sums+num;
num:=num+1;
end loop;
dbms_output.put_line('1到100之间累加和为:'||sums);
end;
执行:

4.13.7、for循环语句
语法如下:
for i in 1..n loop
[业务处理语句]
end loop;
以下进行测试:
--for循环计算1到100之间的偶数累加和
declare
sums int:=0;
begin
for i in 1..100 loop
if(i mod 2 = 0) then
sums:=sums+i;
end if;
end loop;
dbms_output.put_line('1到100之间的偶数累加和是:'||sums);
end;
执行:
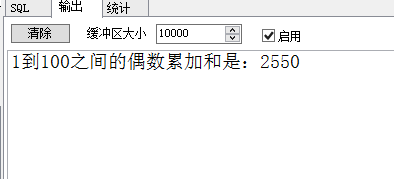
4.14、自定义函数
Oracle中支持用户自定义函数以能够处理更加复杂的数据业务;在Oracle数据库系统中函数和存储过程都是预编译的PLSQL代码块的封装,它们具有高效性及重用性。在Oracle中函数必须有一个返回值,存储过程没有返回值;函数和存储过程都支持参数定义从而接收外部调用的数据传递到函数或存储过程中。
分为有参函数和无参函数,其中有参函数又分为输入型参数、输出型参数及输入输出型参数。函数的关键字是function。
4.14.1、函数的定义
定义语法:
create [or replace] function function_name [(...)]
return date_type is/as
begin
return data;
end [function_name];
函数可以有参数,也可以没有参数,并没有硬性的要求,根据业务而定。
4.14.2、无参函数
无参函数很简单,就是函数中不接收任何参数,这个非常简单,如下:
-- 无参函数的定义
create or replace function fun_demo1
return string is
mess string(64):='2021年到了!';
begin
return mess||'你好鸭!';
end;
-- 调用函数
-- 可以在PL/SQL块中调用
begin
dbms_output.put_line(fun_demo1);
end;
-- 也可以在select中使用
select fun_demo1||name from emp;
执行:


4.14.3、有参函数
有参函数的参数可以有3种类型:
- in:输入类型,只接收调用时输入,此类型可以省略。
- out:输出类型,不接收调用输入,此类型函数返回后必须使用变量接收。
- in out :输入输出型,可接收输入也可以输出,函数内可对此类型赋值。
4.14.3.1、in输入类型参数
直接使用例子说明:
-- in输入类型参数
create or replace function fun_demo2(a in number,b in number)
return number is
begin
return a * b;
end;
-- 调用函数
declare
a number:=10;
b number:=2.5;
begin
-- 调用的时候需要按要求传入两个参数
dbms_output.put_line(a||'乘以'||b||'的结果是:'||fun_demo2(a,b));
end;
执行:

4.14.3.2、out输出类型参数
例子如下:
-- out输出类型参数
create or replace function fun_demo3(a in number,b out number)
return string is
mess string(64):='已经计算完毕!';
begin
-- 输出类型参数必须接收一个值
b:=a*2;
return mess;
end;
-- 调用函数
declare
n number:=25;
m number;
begin
dbms_output.put_line(fun_demo3(n,m));
dbms_output.put_line('计算完毕后m的值是:'||m);
end;
执行:

4.14.3.3、in out输入输出类型参数
例子如下:
-- in out输入输出类型参数
create or replace function fun_demo4(a in out number)
return number is
begin
a:=sqrt(a);
return power(a,4);
end;
-- 函数调用
declare
m number:=20;
begin
dbms_output.put_line('计算结果是:'||fun_demo4(m));
dbms_output.put_line('现在的m值为:'||m);
end;
执行:

4.14.3.4、删除函数
语法:drop function 函数名。
4.15、存储过程
Oracle中存储过程与函数的最大区别在于函数必须有返回值,而存储过程没有返回值。存储过程在Oracle数据库中使用procedure关键字定义。存储过程与函数一样也支持in、out、in out三种形式的参数。
定义的语法:
create or replace procedure proc_name[(参数列表)] is/as
begin
PLSQL语句块
end [proc_name];
以下通过一个例子来说明:
-- 定义一个存储过程
-- 计算梯形面积
create or replace procedure pro_demo1(up in float,down in float,h in float,area out float) is
mess string(64):='梯形面积计算完毕!';
begin
area:=(up+down)*h/2;
dbms_output.put_line(mess);
end;
-- 调用存储过程
declare
a float:=4.5;
b float:=5.5;
c float:=4;
area float;
begin
-- 调用存储过程,刷新area值
pro_demo1(a,b,c,area);
dbms_output.put_line('上底为'||a||',下底为'||b||',高为'||c||'的梯形面积是:'||area);
end;
执行:

删除存储过程:drop procedure 存储过程名称。
4.16、触发器
触发器(trigger)在Oracle中是功能强大的功能代码执行单元,定义格式通常像存储过程和函数,较函数或存储过程复杂;不同的是触发器不允许用户显示调用也不带返回值和参数,它是在满足某种条件时自动触发执行的。触发器通常在需要时由专门数据库开发人员或DBA开发制定。
触发器的作用如下:
- 约束数据功能(触发器是一种复杂的约束定义)。
- 根据触发动作完成复杂的业务数据处理和记录。
4.16.1、触发器的分类
可以分为以下4类:
(1)DML触发器
这是最常用的触发器,通常在执行insert、delete和update时自动触发。
(2)instead of触发器
建立在视图上的触发器对象,不提倡使用。
(3)DDL触发器
当发生create、alter、drop、truncate命令时触发此类型触发器。
(4)DB触发器
当数据库系统发生startup、shutdown、logon、logoff是触发DB触发器。
作为后端的开发人员,我们只需要了解DML触发器即可。
4.16.2、触发器的定义
语法如下:
create or replace trigger tig_name {before|after}--动作前或动作后触发
{insert|delete|update [of column [col1,col2,col3……]]}--触发动作
on table_name|view_name--选项表或视图
[referencing{old[as]old|new[as]new|parent as parent}]--选项
[for each row]--行级触发器
[when condition]--触发约束条件
begin
PL/SQL_block--触发主体
end;
触发器的关键字是trigger。
说明:DML触发器分为before触发器和after触发器,而before和after都可以分为语句及触发器和行级触发器,而语句级触发器和行级触发器都可以分为insert触发器、delete触发器和update触发器。
4.16.3、触发器的实现
先定义一个触发器出来:
-- 触发器
-- 是在满足某种条件后自动触发的
create or replace trigger trig_demo1
-- 更新之前触发
before update
on emp -- 这个触发器作用在emp表
referencing old as o new as n -- 别名
for each row -- 行级触发
begin
-- 触发器的功能代码,放在执行单元中
dbms_output.put_line('行级触发器被触发!');
end;
按照这个触发器的定义,是在更新emp表时触发的,且在更新动作之前,下面更新emp表中的3条记录:
-- 更新emp表
update emp set name = '云过梦无痕' where name = '剑来';
update emp set name = '中二病' where id = 'emp1002';
update emp set name = '尹诗琪' where email = '18642364@163.com';
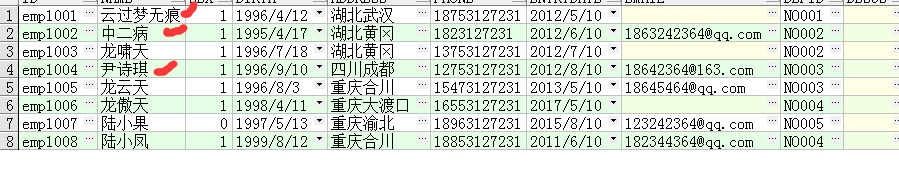
更新成功,再看输出语句:

可以看到这个触发器被触发了3次,因为更新了3次,且设置的是for each row行级触发,每行更新成功都会触发。
4.16.4、触发器的启用、禁用、删除
先创建一张表:
-- 建表
-- 这张表记录数据的插入
create table trig_insert_log(
id int not null primary key,
insert_time varchar(19) not null,
descs varchar(32) not null
);
select * from trig_insert_log;

这张表现在是没有数据的。
再创建一个序列:
-- 再创建一个序列,用来自增主键
create sequence trig_seq
start with 1 -- 1开始
increment by 1 -- 每次自增1
maxvalue 100000 -- 最大值
minvalue 1 -- 最小值
nocycle -- 不循环
nocache; -- 不缓存
创建触发器:
-- 创建触发器
-- 每次向emp表中添加数据时都向日志表中添加记录
create or replace trigger trig_demo2
after insert -- 插入后触发
on emp
for each row -- 行级触发
begin
insert into trig_insert_log(id,insert_time,descs) values
(trig_seq.nextval,to_char(systimestamp,'yyyy-MM-dd hh24:mi:ss'),'添加新记录!');
end;
向emp中添加记录进行测试:
insert into emp(id,name,sex,birth,address,phone,entryDate,depid) values
('emp1018','猿A',1,'12-4月-1996','湖北武汉','18753127231','10-5月-2012','NO001');
insert into emp(id,name,sex,birth,address,phone,entryDate,depid) values
('emp1019','猿B',1,'12-4月-1996','重庆九龙坡','1453127231','10-5月-2014','NO004');
insert into emp(id,name,sex,birth,address,phone,entryDate,depid) values
('emp1020','猿C',1,'12-4月-1996','四川成都','18753127231','10-5月-2012','NO002');
insert into emp(id,name,sex,birth,address,phone,entryDate,depid) values
('emp1021','猿D',1,'12-4月-1996','四川成都','18753127231','10-5月-2012','NO002');
insert into emp(id,name,sex,birth,address,phone,entryDate,depid) values
('emp1022','猿E',1,'12-4月-1996','四川成都','18753127231','10-5月-2012','NO003');
查询emp表:

5条记录添加成功了,再看trig_insert_log表:
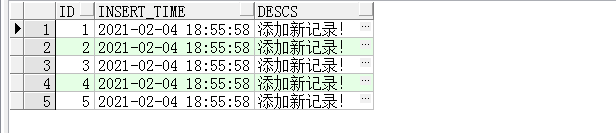
日志记录成功了。
禁用触发器:
-- 禁用触发器
alter trigger trig_demo2 disable;
再向emp表中添加记录:
insert into emp(id,name,sex,birth,address,phone,entryDate,depid) values
('emp1023','猿F',1,'12-4月-1996','四川成都','18753127231','10-5月-2012','NO003');
再看日志表:
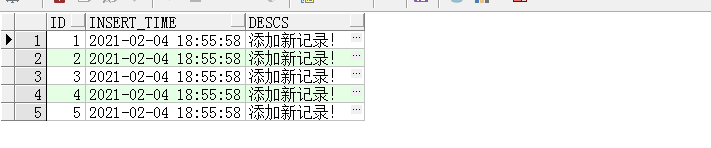
并没有添加新的日志记录,因为触发器禁用了,无法触发。
启用触发器:
-- 启用触发器
alter trigger trig_demo2 enable;
向emp中添加一条记录:
insert into emp(id,name,sex,birth,address,phone,entryDate,depid) values
('emp1024','猿G',1,'12-4月-1996','四川成都','18753127231','10-5月-2012','NO003');
查看emp表:
再看日志表:
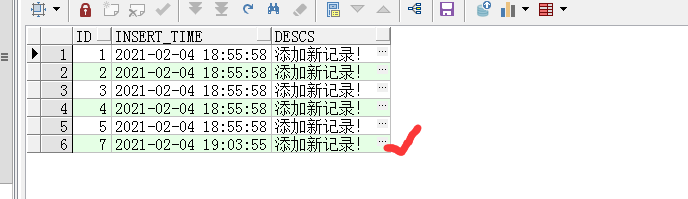
日志记录成功,触发器触发了。
删除触发器:
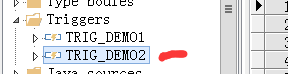
触发器现在是有的,然后现在删除:
-- 删除触发器
drop trigger trig_demo2;

没了,删除成功。
4.17、事务
数据库事务(Database Transaction),是指作为独立的逻辑工作单元执行的一系列操作,要么完全地执行,要么完全地不执行。事务处理可以确保除非事务性单元内的所有操作都成功完成,否则不会永久更新面向数据的资源。
4.17.1、事务的特性
事务有4大特性,如下:
- 原子性:事务必须是原子工作单元,是不可分割的。对于其数据修改,要么全都执行,要么全都不执行。
- 隔离性:由并发事务所作的修改必须与任何其它并发事务所作的修改相互隔离。事务查看数据时数据所处的状态,要么是另一并发事务修改它之前的状态,要么是另一事务修改它之后的状态,事务不会查看中间状态的数据(事务间是不透明的),称之为隔离性。
- 一致性:事务在完成时,必须使所有的数据都保持一致状态。在相关数据库中,所有规则都必须应用于事务的修改,以保持所有数据的完整性。事务结束时,所有数据操作都必须是正确的。
- 永久性:事务在执行完成之后,对于系统的影响是永久性的。事务中所做的任何修改即使出现致命的系统故障也将一直保持。
4.17.2、事务的控制
- commit :提交事务处理。
- rollback :撤销/回滚事务处理。
- savepoint:事务保存点。
- rollback to savepoint:回滚到事务保存点。
4.17.3、例子
下面模拟银行转账事务处理,大概的步骤如下:
- 添加转入方账号交易记录
- 添加转出方账号交易记录
- 更新转入方账户余额
- 更新转出方账户余额
创建账户余额表:
-- 创建账户余额表accounts
create table accounts(
seq int not null,
balance number not null,
descs int not null,
atime varchar2(30) not null,
id int not null primary key
);
-- 为balance余额添加约束,不小于0
alter table accounts add constraint ban_ch check(balance>=0);
--插入两条记录
--转入方
insert into accounts values(demo_seq.nextval,30000,1,to_char(systimestamp,'yyyy-MM-dd HH24:mi:ss'),102);
--转出方
insert into accounts values(demo_seq.nextval,30000,0,to_char(systimestamp,'yyyy-MM-dd HH24:mi:ss'),103);
select * from accounts;

转入方ID为102,转出方ID为103,现在转入方和转出方余额都是30000。
创建转账记录表:
-- 创建转账记录表business
create table business(
seq number not null,
money number not null,
descs int not null,
btime varchar2(19) not null,
id int not null primary key
);

用这两张表完成银行转账业务。
以下用SQL模拟转账业务:
-- 银行转账业务
declare
success string(64):='转账成功!';
fail string(64):='转账失败!';
-- 定义异常变量
error_fail exception;
-- 异常变量初始化
pragma exception_init(error_fail,-2290);
begin
-- 转入记录
insert into business values(trig_seq.nextval,10000,1,to_char(systimestamp,'yyyy-MM-dd HH24:mi:ss'),trig_seq.nextval);
-- 转出记录
insert into business values(trig_seq.nextval,10000,0,to_char(systimestamp,'yyyy-MM-dd HH24:mi:ss'),trig_seq.nextval);
--更新账户余额表
--转入方账户加钱
update accounts set balance=balance+10000 where id=102;
--转出方账户扣钱
update accounts set balance=balance-10000 where id=103;
-- 事务提交
commit;
-- 转账成功时
dbms_output.put_line(success);
-- 失败时
exception when error_fail then
dbms_output.put_line(fail);
-- 事务回滚
rollback;
end;
执行,查看business表:
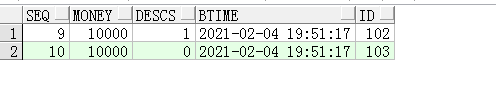
查看accounts表:

转账成功了。
再执行一次,交易表:

余额表:

再执行一次,交易表:
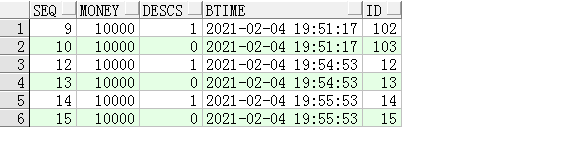
余额表:

现在转出方的余额是0了,按照实际情况无法进行转账。再执行:

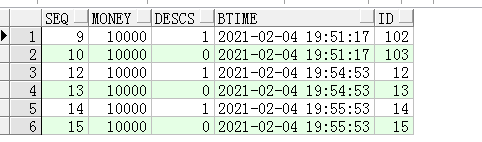

转账失败时事务进行了回滚,也就是相当于什么也没执行,交易表和余额表没有变化。
再通过一个例子测试事务回滚到保存点。如下:
-- 创建一张表
create table home(
id number not null primary key,
address varchar2(20) not null
);
-- 测试事务回滚到保存点
declare
fail string(64):='插入失败,0不能作为除数!';
success string(64):='插入记录成功!';
zero_exc exception;
pragma exception_init(zero_exc,-1476);
begin
-- 向表中插入2条数据
insert into home values(trig_seq.nextval,'湖北');
insert into home values(trig_seq.nextval,'湖南');
--记录事务回滚的保存点,发生错误时,恢复到保存点以前的数据状态
savepoint save_point;
-- 再插入2条数据
insert into home values(trig_seq.nextval,'成都');
insert into home values(trig_seq.nextval,'重庆');
-- 这里错误发生,会回滚到保存点
dbms_output.put_line(5/0);
-- 事务提交
commit;
-- 事务成功时
dbms_output.put_line(success);
-- 事务失败时
exception when zero_exc then
dbms_output.put_line(fail);
-- 事务回滚到保存点之前的状态
rollback to save_point;
end;
执行,输入:

查看home表:
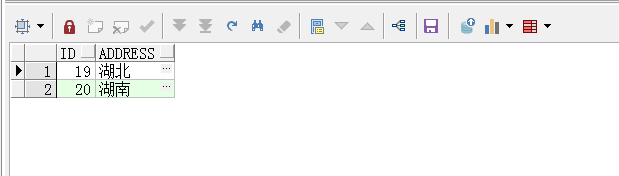
可以看到,发生错误时,事务并不是完全撤销了,而是回滚到设立的保存点之前的状态:

保存点之前的,依然是有效的,保存点之后的,全部撤销。















 2357
2357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









