







比赛地址:周赛超链接
由于本人较懒,格式原因可能不太会注意,原题地址就不单独贴了。直接进上方超链看对应题号就可以。且出于能力原因我一般第四题都不会看,是个每周稳两道冲三道的菜鸡(笑),即可能只更新前三题的思路和反思。对应序号括号后面的是对应力扣题号,可以直接搜到。
题-思-解
1(2413)、最小偶倍数

1.1 我的思路
- 首先知道n可能为1,即考虑n为1时候的边界情况,但1为奇数,可以包含在后面的判断中。
- 若n为奇数则与2的最小公倍数一定是两个数相乘,若n为偶数则一定为n,因为n比1大,即不可能是0。这也限定了是偶数的时候 >= 2 ,由偶数的性质直接可得答案为n。代码直接写出。
1.2 代码
1.2.1 mycode
class Solution {
public:
int smallestEvenMultiple(int n) {
if (n % 2 == 0){
return n;
} else{
return 2 * n;
}
}
};
1.3 反思
代码风格可以进行优化,即第二个else去掉在外面进行对2n的return,这样给了函数一个返回值出口,更加严谨。有时自己用if不能cover到所有的情况。
2(2414)、最长的字母连续子字符串的长度
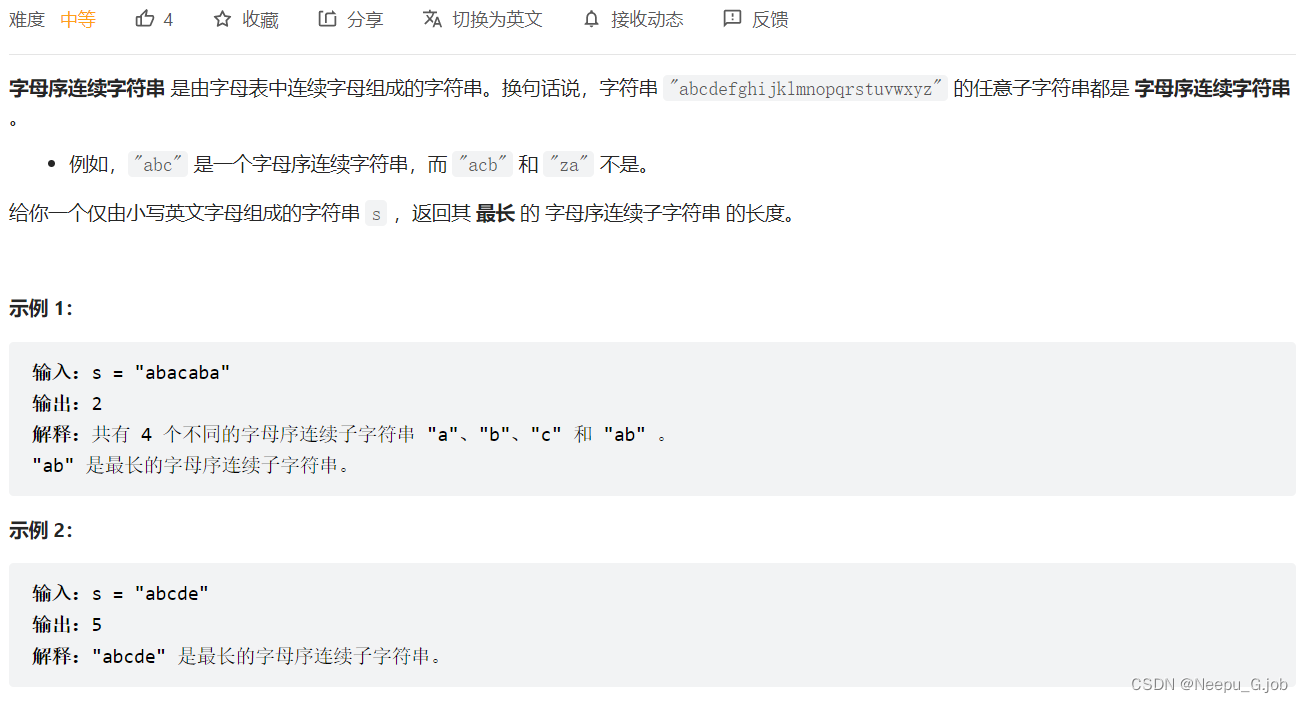
注意:答案仅由小写字母组成
2.1 我的思路
- 维护一个类似的滑动窗口。当前后字母ASCII码差大于1的时候就代表不连续,则初始化窗口开始位置。
- 只需要遍历一次字符串s,不一样的是在ASCII差值不为1的时候要更新longest即当前连续字符串长度为1。 在i = sSize -
- 1的时候需要再判断一次longest和result的关系,不然会造成最后一个字符串的长度丢失,用例会测出来。
2.2 代码
2.2.1 mycode
class Solution {
public:
int longestContinuousSubstring(string s) {
int sSize = s.size();
int longest = 1;
int result = 1;
for (int i = 1; i < sSize; ++i) {
if (s[i] - s[i-1] == 1){
longest++;
} else{
if (longest > result) result = longest;
longest = 1;
}
}
if (longest > result) result = longest;
return result;
}
};
2.2.2 Leetcode_DP
class Solution {
public:
int longestContinuousSubstring(string s) {
int length = s.size();
int dp0 = 1;
int dp1 = 1;// 初始化
int max = dp0;
for(int i = 1; i < length; i++){
if(s[i] == s[i-1] + 1){
dp1 = dp0 + 1;
}else{
dp1 = 1;
}
max = fmax(dp1, max);
dp0 = dp1;
}
return max;
}
};
//作者:da2zling-albattani8r0
2.3 反思
- 对于滑动窗口来说这道题确实没有什么技术含量,只需要更新连续的字符串记录最大长度就可以。
- 对于DP来说,下一步的计算依赖于上一步的记录,判断方式是一样的,不过需要 max 来临时记录当前的最大长度,按照代码圈数来说更少,但空间利用率和时间利用率两者差别并不大,这道题没有发挥DP回溯的优势。递推公式就是:
dp[i] = dp[i-1] + 1
3(2415)、翻转二叉树的奇数层


3.1 我的思路
- 创建存放各层地址的
vector<TreeNode*> - DFS记录所有奇数层节点的地址
- 将奇数层所有指针指向的val以整层节点数量的1/2为对称轴对调
3.2 代码
3.2.1 mycode(mySaveDFS)
class Solution {
public:
void bianli(vector<vector<TreeNode*>> &vec, TreeNode* node ,int deepth){
if (node == nullptr) return;
if (deepth % 2 != 0){
vec[deepth].emplace_back(node);
}
bianli(vec, node->left, deepth+1);
bianli(vec, node->right, deepth+1);
}
TreeNode* reverseOddLevels(TreeNode* root) {
vector<vector<TreeNode*>> jiucuncundizhi(14);
bianli(jiucuncundizhi, root->left, 1);
bianli(jiucuncundizhi, root->right, 1);
//得到了装满的数组,准备遍历
int tempint = 0;
for (int i = 1; i < jiucuncundizhi.size(); ++i) {
if (jiucuncundizhi[i].size() != 0){
for (int j = 0; j < jiucuncundizhi[i].size() / 2;) {
tempint = jiucuncundizhi[i][j]->val;
jiucuncundizhi[i][j]->val = jiucuncundizhi[i][jiucuncundizhi[i].size() - 1 - j]->val;
jiucuncundizhi[i][jiucuncundizhi[i].size() - 1 - j]->val = tempint;
j += 1;
}
}
}
return root;
}
};
3.2.2 纯血DFS
class Solution {
public:
void dfs(TreeNode * ll, TreeNode * rr, int level){
if (ll == NULL || rr == NULL){
return ;
}
if (level % 2 == 1){
int tmp = ll->val;
ll->val = rr->val;
rr->val = tmp;
}
//这里思路比较重要,左右递归
dfs(ll->left, rr->right, level + 1);
dfs(ll->right, rr->left, level + 1);
}
TreeNode* reverseOddLevels(TreeNode* root) {
if (root == NULL){
return root;
}
dfs(root->left, root->right, 1);
return root;
}
};
//作者:XingHe_XingHe
3.2.2.1 逻辑review
重点就在于如何成功递归完毕整个二叉树,这里用了技巧,太厉害了捏。对称走下去就是对称的!左右一组右左一组,这样到了对应奇数层就可以直接交换了,holy谢特。
3.2.3 纯血BFS
class Solution {
public:
TreeNode* reverseOddLevels(TreeNode* root) {
if (root == NULL){
return root;
}
queue<TreeNode *> q;
q.push(root);
int level = 0;
vector<TreeNode *> line;
while (!q.empty()){
int curLen = (int)q.size();
for (int _ = 0; _ < curLen; _ ++){
TreeNode * x = q.front(); q.pop();
if (level % 2 == 1){
line.push_back(x);
}
if (x->left){
q.push(x->left);
}
if (x->right){
q.push(x->right);
}
}
if (level % 2 == 1){
for (int i = 0; i < curLen / 2; i ++){
int tmp = line[i]->val;
line[i]->val = line[curLen - 1 - i]->val;
line[curLen - 1 - i]->val = tmp;
}
line.clear();
}
level ++;
}
return root;
}
};
//作者:XingHe_XingHe
3.2.3.1 逻辑review
鼠鼠用不太好BFS捏,准备开专栏,最近更线段树专栏和BFS专栏。
3.3、反思
我的DFS,终究不还不能算是DFS,人家DFS利用二叉树对称性递归,我的DFS其实只是个披着DFS皮的穷举。BFS鼠鼠本来就不太用捏,看了二十分钟介绍大约就是DFS是隐性栈,BFS是隐性队列。DFS象征着穷举,象征着巧妙的递归。BFS象征着迭代,象征着结果的收束。
4(2416)、字符串的前缀分数和
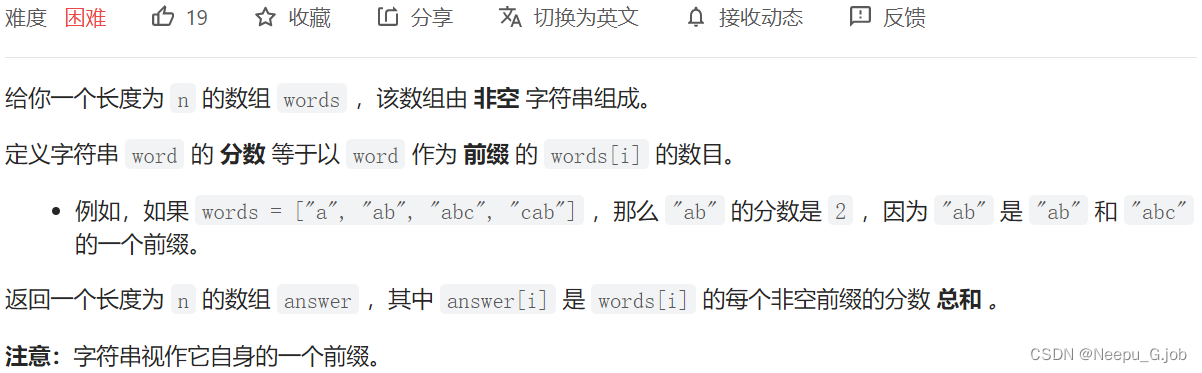
4.1 我的思路
- 从头到尾线性遍历数组,每个单独的string也按照前缀形式遍历。
- 每个前缀都记录到map里面(这里可以换用unordered_map优化内存)
- 在遍历前缀的同时初始化数组eachForKey,每一位对应相应长度的前缀,用来sum
- 最后遍历eachForKey,以其值为key,连加对应map里面的value
4.2 代码
4.2.1 mycode
class Solution {
public:
vector<int> sumPrefixScores(vector<string>& words) {
//一眼丁真,鉴定为 hashmap+线性遍历
map<string,int>countMap;
string tempStr;
int wordsSize = words.size();
vector<int>result(wordsSize);
vector<vector<string>>eachForKey(wordsSize);
int sum = 0;
for (int i = 0; i < wordsSize; ++i) {
for (int j = 0; j < words[i].size(); ++j) {
tempStr.push_back(words[i][j]);
eachForKey[i].push_back(tempStr);
if (countMap.find(tempStr) == countMap.end()){
countMap.emplace(tempStr,1);
} else{
countMap[tempStr]++;
}
}
tempStr.clear(); //initial
}
/*
* 得到了:
* 1、countMap,key是所有不同的前缀,value是对应string拥有的数量
* 2、eachForKey,装着每个words[i]对应的所有前缀,用来遍历上面的countMap得到数量sum
* 3、result在下面步骤中被填满
* */
for (int i = 0; i < wordsSize; ++i) {
for (int j = 0; j < eachForKey[i].size(); ++j) {
sum += countMap[eachForKey[i][j]]; //stepAdd
}
result[i] = sum; //give
sum = 0; //initial
}
return result;
}
};
4.2.3 字典树trie + 优化插入和查找
#define N 500100
int idx;
void insert(char *s, int (*trie)[26], int *cnt)
{
int i, u, p = 0;
for (i = 0; s[i]; i++) {
u = s[i] - 'a';
if (!trie[p][u])
trie[p][u] = ++idx;
p = trie[p][u];
cnt[p]++;
}
}
int query(char *s, int (*trie)[26], int *cnt)
{
int i, u, p = 0, res = 0;
for (i = 0; s[i]; i++) {
u = s[i] - 'a';
if (!trie[p][u])
return res;
p = trie[p][u];
res += cnt[p];
}
return res;
}
int* sumPrefixScores(char ** words, int wordsSize, int* returnSize){
int *ans, i, j;
int trie[N][26] = {0}, cnt[N] = {0};
ans = malloc(wordsSize * sizeof(int));
memset(ans, 0, wordsSize * sizeof(int));
idx = 0, *returnSize = wordsSize;
for (i = 0; i < wordsSize; i++)
insert(words[i], trie, cnt);
for (i = 0; i < wordsSize; i++)
ans[i] += query(words[i], trie, cnt);
return ans;
}
4.3 反思
字典树不会,开新篇:
总结
- 数学 + 找规律,没有技术含量。
- 同实现的代码两种风格,我是线型迭代,另外解是DP递归,思路不一样值得推敲。
- 翻转二叉树奇数层节点,自己方法是存储+DFS,不过这道题貌似用BFS更好些,也有DFS的不同用法,就是遍历的时候左节点和另外分支的右节点放在一起,右节点和另外分支的左节点放在一起实现镜像对称遍历,很有意思。
- trie不会捏!















 1028
1028











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









