







语义相似度的计算是一个比较复杂的过程。今天打算先比较详细的介绍下几个相似度的距离衡量算法。
相似度的排名衡量,在向量数据库 vector db 的 query 中,被大量使用。还是直接上干货,理解下背后的逻辑和概念比较重要,后面看看源码 chroma vector db 是怎么处理这个过程的。
1)cosine距离
cosine距离基于余弦相似度的计算。这类算法之前在我之前写的LLM(3)中对原理有详细介绍,不熟悉的读者可以去看看,余弦相似度总的来说就是衡量N维空间上的两个N维向量他们的方向是否相似。实际上,从数学的角度上说,他并不关心绝M维分量绝对数值的大小,更关心的是两个向量间方向是否一致。说直白点,可以举个例子,假设你是一个学生,我们需要定义一个M维向量来表示你对所有学科知识的掌握度,假设这3维向量分别是[English, Math, Physical],一个小学生的3维向量可能是[0.13, 0.16, 0.05], 一个大学生他的3维向量可能是[0.63, 0.84, 0.45], 虽然在绝对值的投影上,他们差别很大,毕竟大学生掌握的知识比小学生多很多。但在向量方向的维度上,你会方向他两基本保持了一致,都是数学比较’突出‘,所以我们可以估计他们两的数学上都有些优势,从这个意义上进行划分,我们可以将他们归为同一类人,即数学比较好的那类人。尽管两者在绝对投影上差距很大,但是那不重要,重要的是相对方向的一致性。
总结来说,Cosine距离衡量的是两个向量在方向上的差异性,而不是在大小上的差异。它基于余弦相似度的概念,后者计算两个向量之间的夹角的余弦值,用于度量两个向量在方向上的相似度。Cosine距离定义为1减去余弦相似度。
具体公式如下:
如果有两个向量A和B,则A和B之间的余弦相似度是:
similarity = (A dot B) /( (|A|) * (|B|))
其中,(A dot B)表示A和B的点积,(|A|)和(|B|)分别是A和B的模长。
因此,Cosine距离可以定义为:
(\text{distance}(A, B) = 1 - \text{similarity}(A, B))
用于对内容评分来区分兴趣的相似度和差异,同时修正了不同内容间可能存在的度量标准不统一的问题。因为我们看的是方向,不是绝对值权重。
该距离越小,代表两个句子之间的语义相似度越高。
举个例子:
query = "减少数据冗余" docs = db3.similarity_search_with_relevance_scores(query)

我们可以看到 -461 那个得分是最高的。但是需要指出,chroma db 在实现时,有些问题,因为cosine的值理论是应该是[-1, 1], 他没有进行最后的归一化,所以导致用 1 减后生成了负数。但这不影响我们对该距离的理解。这个问题,后面我会定位,到底是源码或是使用哪里出了问题,应该使用归一化的函数后,再进行distance 计算。但chroma db 只给出了一个 API,理论上不应该出问题。--这个地方会选用的embedding function 相关,如果使用默认的all-MiniLM-L6-v2 就不会有问题,但我使用的是 nomic-embed-text 就会有这个问题。词向量估计差距有点大,但说实在的 all-MiniLM-L6-v2 对中文的支持相对差劲,不如 nomic-embed-text。但很可惜,如果你后面要使用 collection 等概念做 query,那么nomic-embed-text 无法支持,因为它不支持embedable 接口。但庆幸的是它实现了Embedding,所以在 chroma 可以使用。但你如果使用chroma 的 collection 上 做 query,那是不行的,当然你可以自己做一个 wrapper,将 nomic-embed-text 转为 实现 embedable 接口,但这不是本文讨论的重点。你知道即可。
2) l2距离
L2距离(欧氏距离)衡量的是两个点之间的直线距离。在计算两点之间的L2距离时,我们简单地对每个维度上的差值进行平方,然后将这些平方值相加,最后取平方根。其实说直白点,就是初高中数学里的M维空间的绝对距离。
具体公式如下:
如果有两个点(P(x_1, y_1, ..., z_1))和(Q(x_2, y_2, ..., z_2)),则它们之间的L2距离是:
(\text{distance}(P, Q) = \sqrt{(x_2 - x_1)^2 + (y_2 - y_1)^2 + ... + (z_2 - z_1)^2})
L2距离能够体现个体数值特征的绝对差异,所以更多的用于需要从维度的数值大小中体现差异的分析,如根据用户行为指标,分析用户价值的相似度或差异。因为这里要看的可能是绝对值的大小,而不是看’方向‘是否一致的计算。在最近邻居搜索中,L2距离也常用于比较数据点之间的相似性。
上面同样的例子,采用L2计算后的值为:

3) ip 距离
ip(Inner Product)也称为点积,它计算两个向量在空间中的点乘结果,结果是一个数值。
具体公式如下:
如果有两个向量A和B,则它们的内积是:A dot B
内积主要用于计算向量之间的夹角和判断两个向量的相似度,但它本身并不直接作为距离度量来使用。在某些特定情况下,如计算两个向量之间的角度时,内积是一个重要的工具。
上面同样的例子,采用ip计算后的值为:

其实你一会发现他和 cosine 距离数值是一样的,这可能是 在chroma db 中有着相同实现的缘故。
综上,
cosine距离关注方向差异,适用于兴趣相似度分析。
l2距离关注绝对距离,适用于需要体现数值特征差异的分析。
ip内积主要用于计算向量夹角和相似度,不是直接的距离度量。
你可以根据你的需求做选择,但在文本分析上,我更偏向 cosine,因为他能较好的反应出语义相似度,特别是在词性分析,理解时候,广泛应用。
我们分析下 chroma 源码的实现,让你有更深层次的理解:
similarity_search_with_relevance_scores
->
relevance_score_fn = self._select_relevance_score_fn() 这其实是一个根据类重载的函数,我们分析下_select_relevance_score_fn ,定位到我们需要的 上:(Chroma db) 可以看到: 我们定义了三种衡量相似度的距离: 余弦相似度,欧几里得几何距离及max inner 我们可以透过
print(chromadb.config.Settings())
将配置打印出来:

可以看到其实没有配置metadata,所以采用 l2 相似度计算
我们看看这三种计算关联性得分的不同,其实很简单:
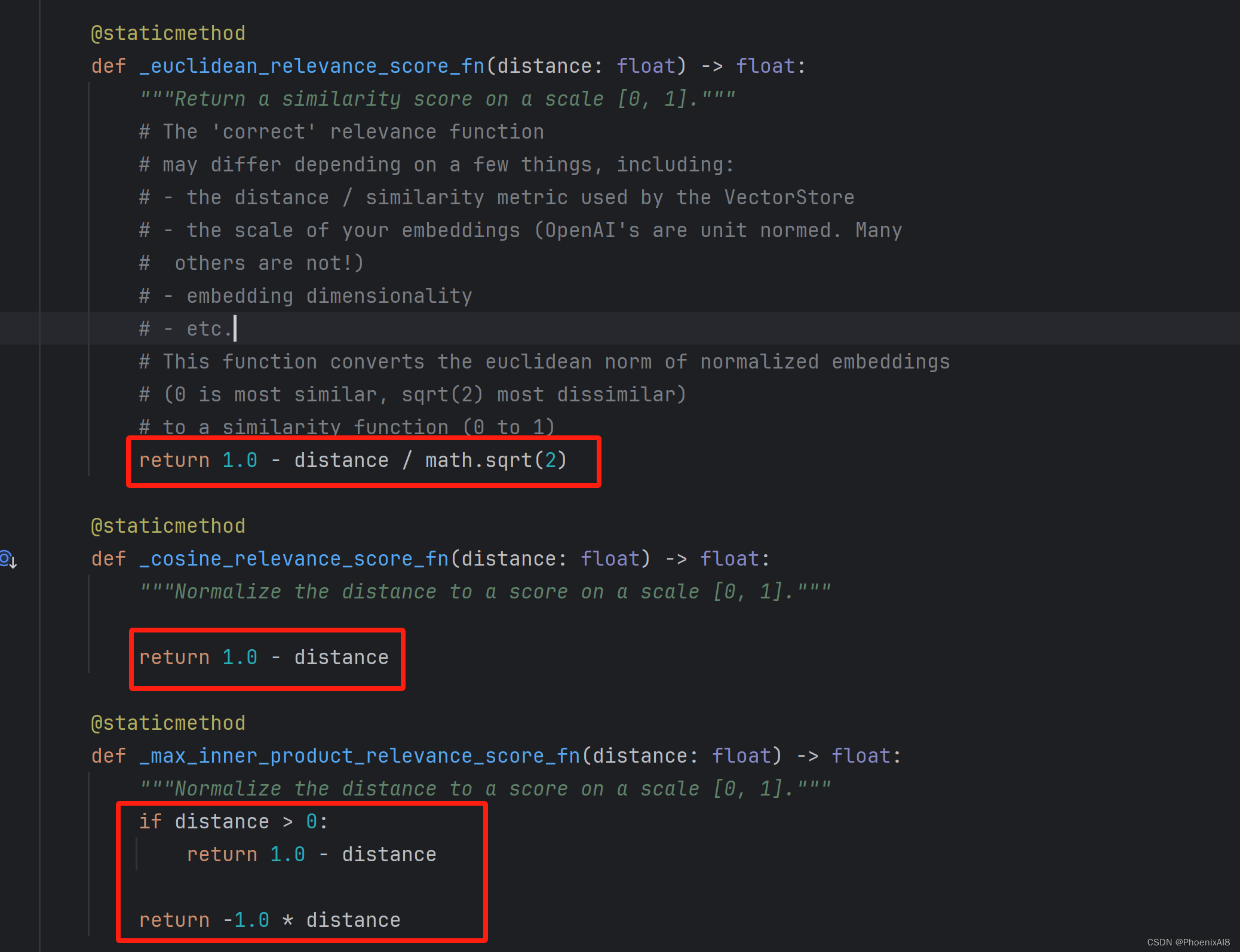
看完了 _select_relevance_score_fn,我们再看:
docs_and_scores = self.similarity_search_with_score(query, k, **kwargs)
本质调用:
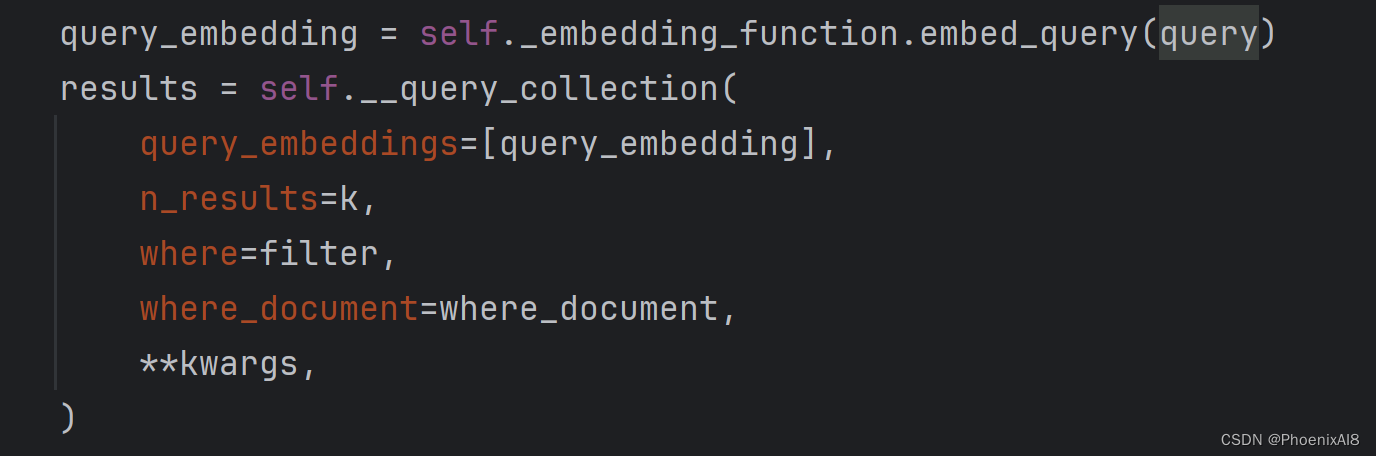
今天先写到这里
















 920
920











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









