







文章目录
(一)安装CUDA
本部分安装主要参考这篇博客,感谢博主。但自己在安装中还是出现一些问题,查看其他博客等资料后完成安装,故此总结如下 :
前言:
CUDA、cudnn、python、tensorflow-gpu-1.12.0之间对版本很敏感,一定要匹配,不然很可能出现各种坑,下面是个版本对应关系:

一 检查自己的电脑环境是否具备安装CUDA的条件
1) 验证自己的电脑是否有一个可以支持CUDA的GPU
你可以电脑的配置信息中找到显卡的具体型号,如果你是双系统,在Windows下的设备管理器中也可以查到显卡的详细信息;
你也可以在ubuntu的终端中输入命令: lspci | grep -i nvidia,会显示出你的NVIDIA GPU版本信息,不过不是很详细。
我的显示为[GeForce 920MX]:
01:00.0 3D controller: NVIDIA Corporation GM108M [GeForce 920MX] (rev a2)
然后去CUDA的官网查看自己的GPU版本是否在CUDA的支持列表中。
2) 验证自己的Linux版本是否支持 CUDA(Ubuntu 16.04没问题)
输入命令:
uname -m && cat /etc/*release
结果显示:
x86_64
DISTRIB_ID=Ubuntu
DISTRIB_RELEASE=16.04
…
3) 验证系统是否安装了gcc
在终端中输入: gcc --version
结果显示:
gcc (Ubuntu 5.4.0-6ubuntu1~16.04.11) 5.4.0 20160609
…
若未安装请使用下列命令进行安装:
sudo apt-get install build-essential
4) 验证系统是否安装了kernel header和 package development
a、查看正在运行的系统内核版本:
在终端中输入: uname --r
结果显示:
4.4.0-161-generic
b、在终端中输入: sudo apt-get install linux-headers-$(uname -r)
可以安装对应kernel版本的kernel header和package development
结果显示:
…
升级了 0 个软件包,新安装了 0 个软件包,要卸载 0 个软件包,有 4 个软件包未被升级。
表示系统里已经有了,不用重复安装。
若以上各项验证检查均满足要求,便可进行下面的正式安装过程。如果没有满足要求的话,可以参考cuda的官方文档,里面有详细的针对每个问题的解决方案。
二 安装显卡驱动
在ubuntu16.04中,更换驱动非常方便,去系统设置->软件更新->附加驱动->切换到最新的NVIDIA驱动即可。应用更改->重启

运行nvidia-smi看看安装好没
1.若出现下面情况,则成功

2.如出现
NVIDIA-SMI has failed because it couldn't communicate with the NVIDIA driver. Make sure that the latest NVIDIA driver is installed and running.
解决 :
sudo apt-get install dkms
sudo dkms install -m nvidia -v 384-384.130
其中的384-384.130是NVIDIA的版本号,当你不知道的时候,进入/usr/src目录中,可以看到里面有nvidia文件夹,后缀就是其版本号
三、选择安装方式
CUDA提供两种安装方式:package manager安装和runfile安装, package manager 安装方式相对简单一些,但是我在阅读别人博客的过程中发现选择这种方式在安装过程中问题可能多一点,失败的概率较大。为了减少不必要的麻烦我选择runfile安装方式。
下载cuda安装包:cuda各版本官网下载https://developer.nvidia.com/cuda-toolkit-archive,根据系统信息选择对应的版本,runfile安装的话最后一项要选择 runfile文件,如下图片。

下载完后,用MD5 检验,如果序号不和,得重新下载
输入命令:md5sum cuda_9.0.176_384.81_linux.run
(在下载的cuda文件路径在打开终端,输入上面语句)
结果7a00187b2ce5c5e350e68882f42dd507 cuda_9.0.176_384.81_linux.run
四、runfile安装cuda
1 禁用 nouveau驱动
终端中运行: lsmod | grep nouveau
如果有输出则代表nouveau正在加载。需要我们手动禁掉nouveau。
Ubuntu的nouveau禁用方法:
a、在/etc/modprobe.d中创建文件blacklist-nouveau.conf
输入命令:sudo vi /etc/modprobe.d/blacklist-nouveau.conf (利用vi编辑器编辑和保存文件)
在文件中输入一下内容:
blacklist nouveau
options nouveau modeset=0
b、执行:
sudo update-initramfs -u
c、再执行:
lsmod | grep nouveau
若无内容输出,则禁用成功,若仍有内容输出,请检查操作,并重复上述操作。
若上述操作没问题,且重复操作后还是有输出,则重启一下就没输出了。
注 : vi的基本操作见这篇博客的第6条。
vi是Linux终端下或控制台下常用的编辑器,基本的操作方式为:vi /路径/文件名
例如:vi /etc/fstab表示显示/etc/fstab文件的内容。使用键盘上的Page Up和Page Down键可以上下翻页;按下Insert键,可以见到窗口左下角有“Insert”字样,表示当前为插入编辑状态,这时从键盘输入的内容将插入到光标位置;再按下Insert键,左下角将有“Replace”字样,表示当前为替换编辑状态,这时从键盘输入的内容将替换光标位置的内容。
以下操作建议手机拍照,建议把下载的cuda_9.0.176_384.81_linux.run文件重命名为cuda.run并移动到Home文件夹下(为了安装方便)
2 重启电脑,进入登录界面的时候,不要登录进入桌面(否则可能会失败,若不小心进入,请重启电脑),直接按Ctrl+Alt+F1进入文本模式(命令行界面),登录账户。
3 输入 sudo service lightdm stop 关闭图形化界面
4 切换到cuda安装文件的路径: cd /home/user
user是你的用户名
5 运行sudo sh cuda.run,
1)首先会显示用户许可证信息,

按空格键直至进度条显示到100%,或,按ctrl+c
2)上一步结束后,若等待安装中出错
The driver installation is unable to locate the kernel source.
解决 :sudo apt install dkms
再运行 sudo sh cuda.run
然后按照提示一步步操作,
a .
accept—>no(driver,此前已安装过驱动,若在这安装CUDA自带的驱动,可能会导致后面操作出错)
b.
遇到提示是否安装openGL ,选择no(如果你的电脑跟我一样是双显,且主显是非NVIDIA的GPU在工作需要选择no,否则可以yes),其他都选择yes或者默认即可。(如果您的电脑是双显卡且在这一步选择了yes,那么你极有可能安装完CUDA之后,重启图形化界面后遇到登录界面循环问题:输入密码后又跳回密码输入界面。
这是因为你的电脑是双显,而且用来显示的那块GPU不是NVIDIA,则OpenGL Libraries就不应该安装,否则你正在使用的那块GPU(非NVIDIA的GPU)的OpenGL Libraries会被覆盖,然后GUI就无法工作了。)
c.
余下的就按提示输入yes或默认选项
安装成功后,会显示installed,否则会显示failed。
6 输入 sudo service lightdm start重新启动图形化界面。
返回到图形化登录界面后,输入密码登录。
如果能够成功登录,则表示不会遇到循环登录的问题,基本说明CUDA的安装成功了。
如果你遇到了重复登陆情况,不用急着重装系统,官方教程上有提及,原因上一步的注中有提及,在安装openGL时你可能不注意选择了yes,请卸载cuda,然后重装。
卸载:由于登陆进入不到图形用户界面(GUI),但我们可以进入到文本用户界面(TUI)
在登陆界面状态下,按Ctrl + Alt + f1,进入TUI
执行
$ sudo /usr/local/cuda-8.0/bin/uninstall_cuda_8.0.pl
$ sudo /usr/bin/nvidia-uninstall
然后重启
$ sudo reboot
重新安装.run 再次安装时请一定留意,在提示是否安装OpenGL时,你的是双显卡应该选则n。
7 重启电脑,检查Device Node Verification。
执行ls /dev/nvidia*
可能出现a、b两种结果,请对号入座。
a、若结果显示
/dev/nvidia0 /dev/nvidiactl /dev/nvidia-uvm
或显示出类似的信息,应该有三个(也有可能出现四个文件)(包含一个类似/dev/nvidia-nvm的),则安装成功。
b、大多数结果可能会是这样
ls: cannot access/dev/nvidia*: No such file or directory
或是这样的,只出现
/dev/nvidia0 /dev/nvidiactl
a中的一个或两个,但没有/dev/nvidia-num,即文件显示不全。
不用着急也不用急着重装系统(我在安装时就是这种情况),官方指导中有详细的解决方案,但是我的方法和官方稍微有些出入。
首先要添加一个启动脚本(添加启动脚本的方法大致有两种,我采用最直接的方法,另一种可以先创建一个文件然后通过mv的方式移动到启动文件夹下,可自行百度)
执行sudo vi /etc/rc.local
如果你是第一次打开这个文件,它应该是空的(除了一行又一行的#注释项外)。这文件的第一行是
#!/bin/sh -e
把-e去掉(这步很重要,否则它不会加载这文本的内容)
然后把下列内容除了#!/bin/bash外复制到其中,(before exit 0 )保存退出。
#!/bin/bash
/sbin/modprobe nvidia
if [ "$?" -eq 0 ]; then
# Count the number of NVIDIA controllers found.
NVDEVS=`lspci | grep -i NVIDIA`
N3D=`echo "$NVDEVS" | grep "3D controller" | wc -l`
NVGA=`echo "$NVDEVS" | grep "VGA compatible controller" | wc -l`
N=`expr $N3D + $NVGA - 1`
for i in `seq 0 $N`; do
mknod -m 666 /dev/nvidia$i c 195 $i
done
mknod -m 666 /dev/nvidiactl c 195 255
else
exit 1
fi
/sbin/modprobe nvidia-uvm
if [ "$?" -eq 0 ]; then
# Find out the major device number used by the nvidia-uvm driver
D=`grep nvidia-uvm /proc/devices | awk '{print $1}'`
mknod -m 666 /dev/nvidia-uvm c $D 0
else
exit 1
fi
下次重启时,你应该能直接看到/dev目录下的三个nvidia的文件
输入: ls /dev/nvidia*
结果显示:/dev/nvidia0 /dev/nvidiactl /dev/nvidia-uvm
(也可能是四个/dev/nvidia0 /dev/nvidiactl /dev/nvidia-modeset /dev/nvidia-uvm)
成功!
8 设置环境变量
终端中输入 sudo gedit /etc/profile
在打开的文件末尾,添加以下两行。
64位系统:
export PATH=/usr/local/cuda-9.0/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
32位系统:
export PATH=/usr/local/cuda-9.0/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
保存文件,并重启。因为source /etc/profile是临时生效,重启电脑才是永久生效。
这里有点与官方安装文档稍有不同,需要说明:
官方文档里说只需在终端中运行上述两条export语句即可,但如果不将它们不写入/etc/profile文件的话,这样的环境变量在你退出终端后就消失了,不起作用了,所以写入才是永久的做法。
9 重启电脑,检查上述的环境变量是否设置成功。
a、 验证驱动版本
敲入cat /proc/driver/nvidia/version
结果显示
NVRM version: NVIDIA UNIX x86_64 Kernel Module 384.81 Sat Sep 2 02:43:11 PDT 2017
GCC version: gcc version 5.4.0 20160609 (Ubuntu 5.4.0-6ubuntu1~16.04.5)
b、 验证CUDA Toolkit
敲入
nvcc -V 会输出CUDA的版本信息
如果是这样的:
The program ‘nvcc’ is currently not installed. You can install it by typing:
sudo apt-get install nvidia-cuda-toolkit
可能是环境配置没有成功,请重复上述步骤7)。
五、 尝试编译cuda提供的例子
1)打开终端输入: cd /home/xxx/NVIDIA_CUDA-9.0_Samples 其中xxx是你自己的用户名,通过命令cd进入NVIDIA_CUDA-9.0_Samples目录。
然后终端输入:make
系统就会自动进入到编译过程,整个过程大概需要十几到二十分钟,请耐心等待。如果出现错误的话,系统会立即报错停止。
第一次运行时可能会报错,提示的错误信息可能会是系统中没有gcc,
解决办法就是通过命令重新安装gcc就行,在终端输入: sudo apt-get install gcc 安装完gcc后, 再make就正常了。
如果编译成功,最后会显示Finished building CUDA samples,如下图所示。

2)运行编译生成的二进制文件。
编译后的二进制文件 默认存放在NVIDIA_CUDA-9.0_Samples/bin中。
接着在上一个终端中输入 : cd /home/lxxx/NVIDIA_CUDA-9.0_Samples/bin/x86_64/linux/release 其中xxx是你自己的用户名
然后在终端输入 : ./deviceQuery
结果如下图所示:看到类似如下图片中的显示,则代表CUDA安装且配置成功,其中 Result = PASS代表成功,若失败 Result = FAIL

3)最后再检查一下系统和CUDA-Capable device的连接情况
终端输入 : ./bandwidthTest
看到类似如下图片中的显示,则代表成功

完成
(二) 安装cuDNN
- https://developer.nvidia.com/rdp/cudnn-archive 下载cudnn(需要注册账号登录):
下载好cudnn-9.0-linux-x64-v7.6.4.38.tgz之后:
cd ~/下载
tar zxvf cudnn-9.0-linux-x64-v7.6.4.38.tgz
sudo cp cuda/include/cudnn.h /usr/local/cuda/include/
sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64/
sudo chmod a+r /usr/local/cuda/include/cudnn.h
sudo chmod a+r /usr/local/cuda/lib64/libcudnn*
(3)查看cudnn版本
在终端输入
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
如果出现下图所示版本信息,说明安装成功。

完成
(三)安装Anaconda
本部分安装部分查看自这篇博客,感谢博主。
注意anaconda 和其自带的python 版本对应关系:

下载地址:清华镜像源
安装
可查看官方文档:https://docs.continuum.io/anaconda/install/linux.html
1)bash Anaconda3-4.2.0-Linux-x86_64.sh

根据提示输入回车

这里需要查看注册信息,回车浏览完信息即可

阅读完注册信息后,这里输入“yes”
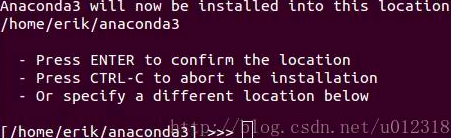
回车即可进行安装

这里输入“yes”选择加入环境变量

看到这些信息说明已经安装完成。
根据信息“For this change to become active, you have to open a new terminal.”(要使这个更改生效,必须打开一个新的终端。)这句话提示,需要在新的终端窗口使用anaconda,打开新的终端,查看相应的版本信息

安装完,输入anaconda-navigator启动图形界面时,可能会出错

解决 :https://blog.csdn.net/qq_42647047/article/details/104930803
完成
(四)安装tensorflow-gpu-1.12.0
本次安装在Anaconda的root环境下
source activate root
#安装tensorflow-gpu一般是外网,且安装库较大,建议大家使用下面静态网站下载,下载速度比默认路径快
pip install tensorflow-gpu==1.12.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
装完之后测试
import tensorflow as tf
sess = tf.Session()
a = tf.constant(1)
b = tf.constant(2)
print(sess.run(a+b))
若出错
ImportError: libcublas.so.9.0: cannot open shared object file: No such file or directory
检查 /usr/local/cuda-9.0/lib64 下是否有 libcublas.so.9.0
如果有,终端输入:
sudo ldconfig /usr/local/cuda-9.0/lib64















 164
164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









