






ResNet相当于将学习目标改变了,不再是学习一个完整的输出,而是目标值H(X)和x的差值,也就是所谓的残差F(x) := H(x)-x
假设现有一个比较浅的网络(Shallow Net)已达到了饱和的准确率,这时在它后面再加上几个恒等映射层(Identity mapping,也即y=x,输出等于输入),这样就增加了网络的深度,并且起码误差不会增加,也即更深的网络不应该带来训练集上误差的上升。而这里提到的使用恒等映射直接将前一层输出传到后面的思想,便是著名深度残差网络ResNet的灵感来源。
ResNet引入了残差网络结构(residual network),通过这种残差网络结构,可以把网络层弄的很深(据说目前可以达到1000多层),并且最终的分类效果也非常好,残差网络的基本结构如下图所示,很明显,该图是带有跳跃结构的:
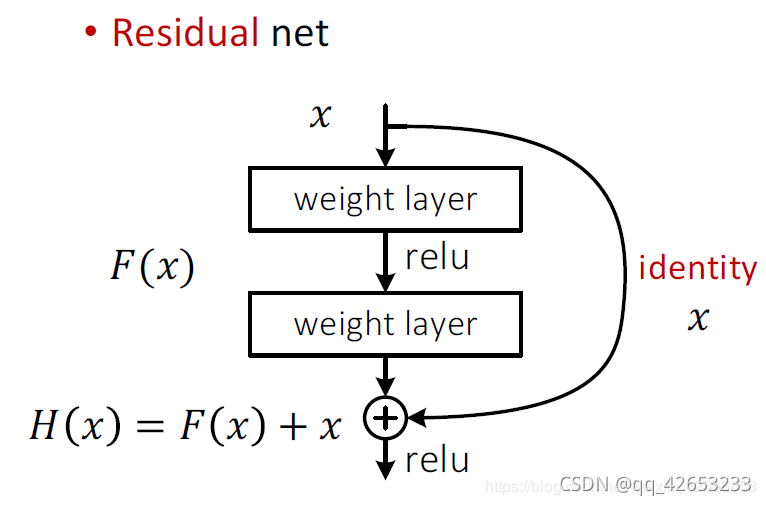
假定某段神经网络的输入是x,期望输出是H(x),即H(x)是期望的复杂潜在映射,如果是要学习这样的模型,则训练难度会比较大;
回想前面的假设,如果已经学习到较饱和的准确率(或者当发现下层的误差变大时),那么接下来的学习目标就转变为恒等映射的学习,也就是使输入x近似于输出H(x),以保持在后面的层次中不会造成精度下降。
在上图的残差网络结构图中,通过“shortcut connections(捷径连接)”的方式,直接把输入x传到输出作为初始结果,输出结果为H(x)=F(x)+x,当F(x)=0时,那么H(x)=x,也就是上面所提到的恒等映射。于是,ResNet相当于将学习目标改变了,不再是学习一个完整的输出,而是目标值H(X)和x的差值,也就是所谓的残差F(x) := H(x)-x,因此,后面的训练目标就是要将残差结果逼近于0,使到随着网络加深,准确率不下降。
关于为什么学习目标从H(x)变为F(x),这里理解为,因为最终期望输出是Hn(x),而当第i次,F(x)=0时,公式 Hi(x)=F(x)+x=0+x,即Hi(x)=x,而由于损失函数的存在,迫使x要不断趋向于Hn(),则学习目标就变成Hn(x)-x。与没有使用跳跃式结构的网络相比,本质目标相同,即从x到Hn()的变化,但是由于网络是上一层的输出作为下一层的输入,是一个传递的过程,无法将某一层的输入x与后面n的输出Hn(X)进行比较,实质上学习的目标是Hi+1(x)-xi。














 884
884











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









