







pandas是python字典和numpy的结合,它的每一行每一列都可以赋予一个名字,其真正的数据则是numpy数据。
它的主要数据结构是Series(一维数据)与DataFrame(二维数据)。
基本介绍
import pandas as pd
import numpy as np
# 定义一维数据
s = pd.Series([1,3,6,np.nan,44,1])
print(s)
# 定义日期的数据
dates = pd.date_range('20220318',periods=6)
print(dates)
# 定义二维数据,指定行索引index和列索引columns
df = pd.DataFrame(np.random.randn(6,4),index=dates,columns=['a','b','c','d'])
print(df)
# 定义二维数据,使用默认索引
df1 = pd.DataFrame(np.arange(12).reshape(3,4))
print(df1)
# 用字典定义DataFrame
df2 = pd.DataFrame({
'A':1.,
'B':pd.Timestamp('20220318'),
'C':pd.Series(1,index=list(range(4)),dtype='float32'),
'D':np.array([3]*4,dtype='int32'),
'E':pd.Categorical(["test","train","test","train"]),
'F':'foo'
})
print(df2)
# DataFrame的属性
print(df2.dtypes)
print(df2.index)
print(df2.columns)
print(df2.values)
print(df2.describe()) # 计算values中数字数据的统计数据
print(df2.T) # 转置
# 按照index进行顺序
print(df2.sort_index(axis=1,ascending=False))
print(df2.sort_index(axis=0,ascending=False))
# 按照values进行排序
print(df2.sort_values(by='E'))
结果:
0 1.0
1 3.0
2 6.0
3 NaN
4 44.0
5 1.0
dtype: float64
DatetimeIndex(['2022-03-18', '2022-03-19', '2022-03-20', '2022-03-21',
'2022-03-22', '2022-03-23'],
dtype='datetime64[ns]', freq='D')
a b c d
2022-03-18 -0.686373 0.975663 -0.164654 -0.134341
2022-03-19 0.721421 2.056876 0.012457 -1.293365
2022-03-20 0.484431 -0.786625 1.069571 1.466806
2022-03-21 0.912695 0.488881 -0.733907 0.868177
2022-03-22 -0.406071 -2.308976 1.377417 -0.423213
2022-03-23 0.961852 -0.734838 1.221765 -2.290225
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
A B C D E F
0 1.0 2022-03-18 1.0 3 test foo
1 1.0 2022-03-18 1.0 3 train foo
2 1.0 2022-03-18 1.0 3 test foo
3 1.0 2022-03-18 1.0 3 train foo
A float64
B datetime64[ns]
C float32
D int32
E category
F object
dtype: object
Int64Index([0, 1, 2, 3], dtype='int64')
Index(['A', 'B', 'C', 'D', 'E', 'F'], dtype='object')
[[1.0 Timestamp('2022-03-18 00:00:00') 1.0 3 'test' 'foo']
[1.0 Timestamp('2022-03-18 00:00:00') 1.0 3 'train' 'foo']
[1.0 Timestamp('2022-03-18 00:00:00') 1.0 3 'test' 'foo']
[1.0 Timestamp('2022-03-18 00:00:00') 1.0 3 'train' 'foo']]
A C D
count 4.0 4.0 4.0
mean 1.0 1.0 3.0
std 0.0 0.0 0.0
min 1.0 1.0 3.0
25% 1.0 1.0 3.0
50% 1.0 1.0 3.0
75% 1.0 1.0 3.0
max 1.0 1.0 3.0
0 ... 3
A 1 ... 1
B 2022-03-18 00:00:00 ... 2022-03-18 00:00:00
C 1 ... 1
D 3 ... 3
E test ... train
F foo ... foo
[6 rows x 4 columns]
F E D C B A
0 foo test 3 1.0 2022-03-18 1.0
1 foo train 3 1.0 2022-03-18 1.0
2 foo test 3 1.0 2022-03-18 1.0
3 foo train 3 1.0 2022-03-18 1.0
A B C D E F
3 1.0 2022-03-18 1.0 3 train foo
2 1.0 2022-03-18 1.0 3 test foo
1 1.0 2022-03-18 1.0 3 train foo
0 1.0 2022-03-18 1.0 3 test foo
A B C D E F
0 1.0 2022-03-18 1.0 3 test foo
2 1.0 2022-03-18 1.0 3 test foo
1 1.0 2022-03-18 1.0 3 train foo
3 1.0 2022-03-18 1.0 3 train foo
pandas选择数据
import pandas as pd
import numpy as np
dates = pd.date_range('20220318',periods=6)
df = pd.DataFrame(np.arange(24).reshape((6,4)),index=dates,columns=['A','B','C','D'])
print(df)
# 索引列
print(df['A'],df.A)
print(df[0:3],df['20220319':'20220321'])
# 用label来筛选 loc
print(df.loc['20220322'])
print(df.loc[:,['A','B']])
# 用位置来筛选 iloc
print(df.iloc[3,1])
print(df.iloc[3:5,1:3])
print(df.iloc[[1,3,5],1:3])
# 条件筛选
print(df[df.A<8])
结果:
A B C D
2022-03-18 0 1 2 3
2022-03-19 4 5 6 7
2022-03-20 8 9 10 11
2022-03-21 12 13 14 15
2022-03-22 16 17 18 19
2022-03-23 20 21 22 23
2022-03-18 0
2022-03-19 4
2022-03-20 8
2022-03-21 12
2022-03-22 16
2022-03-23 20
Freq: D, Name: A, dtype: int32 2022-03-18 0
2022-03-19 4
2022-03-20 8
2022-03-21 12
2022-03-22 16
2022-03-23 20
Freq: D, Name: A, dtype: int32
A B C D
2022-03-18 0 1 2 3
2022-03-19 4 5 6 7
2022-03-20 8 9 10 11 A B C D
2022-03-19 4 5 6 7
2022-03-20 8 9 10 11
2022-03-21 12 13 14 15
A 16
B 17
C 18
D 19
Name: 2022-03-22 00:00:00, dtype: int32
A B
2022-03-18 0 1
2022-03-19 4 5
2022-03-20 8 9
2022-03-21 12 13
2022-03-22 16 17
2022-03-23 20 21
13
B C
2022-03-21 13 14
2022-03-22 17 18
B C
2022-03-19 5 6
2022-03-21 13 14
2022-03-23 21 22
A B C D
2022-03-18 0 1 2 3
2022-03-19 4 5 6 7
pandas设置值
import pandas as pd
import numpy as np
dates = pd.date_range('20220318',periods=6)
df = pd.DataFrame(np.arange(24).reshape((6,4)),index=dates,columns=['A','B','C','D'])
print(df)
df.iloc[2,2] = 1111
df.loc['20220318'] = 2222
df.A[df.A>4] = 0
print(df)
# 添加一列
df['F'] = np.nan
print(df)
# 虽然添加了一列数字,但是显示全是NaN
df['E'] = pd.Series(np.array([1,2,3,4,5,6]))
print(df)
df['E'] = pd.Series(np.array([1,2,3,4,5,6]),index=dates)
print(df)
结果:
A B C D
2022-03-18 0 1 2 3
2022-03-19 4 5 6 7
2022-03-20 8 9 10 11
2022-03-21 12 13 14 15
2022-03-22 16 17 18 19
2022-03-23 20 21 22 23
A B C D
2022-03-18 0 2222 2222 2222
2022-03-19 4 5 6 7
2022-03-20 0 9 1111 11
2022-03-21 0 13 14 15
2022-03-22 0 17 18 19
2022-03-23 0 21 22 23
A B C D F
2022-03-18 0 2222 2222 2222 NaN
2022-03-19 4 5 6 7 NaN
2022-03-20 0 9 1111 11 NaN
2022-03-21 0 13 14 15 NaN
2022-03-22 0 17 18 19 NaN
2022-03-23 0 21 22 23 NaN
A B C D F E
2022-03-18 0 2222 2222 2222 NaN NaN
2022-03-19 4 5 6 7 NaN NaN
2022-03-20 0 9 1111 11 NaN NaN
2022-03-21 0 13 14 15 NaN NaN
2022-03-22 0 17 18 19 NaN NaN
2022-03-23 0 21 22 23 NaN NaN
A B C D F E
2022-03-18 0 2222 2222 2222 NaN 1
2022-03-19 4 5 6 7 NaN 2
2022-03-20 0 9 1111 11 NaN 3
2022-03-21 0 13 14 15 NaN 4
2022-03-22 0 17 18 19 NaN 5
2022-03-23 0 21 22 23 NaN 6
pandas处理丢失数据
import pandas as pd
import numpy as np
dates = pd.date_range('20220318',periods=6)
df = pd.DataFrame(np.arange(24).reshape((6,4)),index=dates,columns=['A','B','C','D'])
df.iloc[0,1] = np.nan
df.iloc[1,2] = np.nan
print(df)
# 丢掉nan所在的列
print(df.dropna(axis=1,how='any')) # how={'any','all'},默认是'any'
# 丢掉nan所在的行
print(df.dropna(axis=0,how='any'))
# 用零填充nan
print(df.fillna(value=0))
# 返回一个DataFrame,每个值都是bool,代表是否是nan
print(df.isnull())
# 判断是否有缺失数据
print(np.any(df.isnull())==True)
结果:
A B C D
2022-03-18 0 NaN 2.0 3
2022-03-19 4 5.0 NaN 7
2022-03-20 8 9.0 10.0 11
2022-03-21 12 13.0 14.0 15
2022-03-22 16 17.0 18.0 19
2022-03-23 20 21.0 22.0 23
A D
2022-03-18 0 3
2022-03-19 4 7
2022-03-20 8 11
2022-03-21 12 15
2022-03-22 16 19
2022-03-23 20 23
A B C D
2022-03-20 8 9.0 10.0 11
2022-03-21 12 13.0 14.0 15
2022-03-22 16 17.0 18.0 19
2022-03-23 20 21.0 22.0 23
A B C D
2022-03-18 0 0.0 2.0 3
2022-03-19 4 5.0 0.0 7
2022-03-20 8 9.0 10.0 11
2022-03-21 12 13.0 14.0 15
2022-03-22 16 17.0 18.0 19
2022-03-23 20 21.0 22.0 23
A B C D
2022-03-18 False True False False
2022-03-19 False False True False
2022-03-20 False False False False
2022-03-21 False False False False
2022-03-22 False False False False
2022-03-23 False False False False
True
pandas导入导出


import pandas as pd
# 会自动加上index
data = pd.read_csv('student.csv')
print(data)
data.to_pickle('student.pickle')
结果:
原始数据如下图所示:
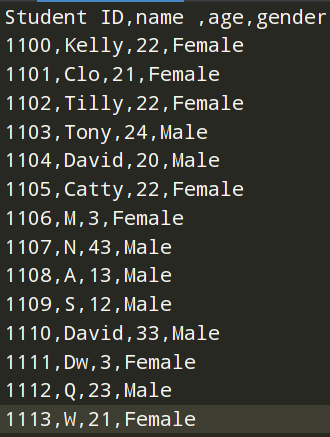
Student ID name age gender
0 1100 Kelly 22 Female
1 1101 Clo 21 Female
2 1102 Tilly 22 Female
3 1103 Tony 24 Male
4 1104 David 20 Male
5 1105 Catty 22 Female
6 1106 M 3 Female
7 1107 N 43 Male
8 1108 A 13 Male
9 1109 S 12 Male
10 1110 David 33 Male
11 1111 Dw 3 Female
12 1112 Q 23 Male
13 1113 W 21 Female
pandas合并concat
import pandas as pd
import numpy as np
# concatenating
df1 = pd.DataFrame(np.ones((3,4))*0,columns=['a','b','c','d'])
df2 = pd.DataFrame(np.ones((3,4))*1,columns=['a','b','c','d'])
df3 = pd.DataFrame(np.ones((3,4))*2,columns=['a','b','c','d'])
print(df1)
print(df2)
print(df3)
# 保留原始index
res = pd.concat([df1,df2,df3],axis=0)
print(res)
# 忽略原始index,重新赋予index
res = pd.concat([df1,df2,df3],axis=0,ignore_index=True)
print(res)
# join,['inner','outer']
df1 = pd.DataFrame(np.ones((3,4))*0,index=[1,2,3],columns=['a','b','c','d'])
df2 = pd.DataFrame(np.ones((3,4))*1,index=[2,3,4],columns=['b','c','d','e'])
print(df1)
print(df2)
# 相当于两个的并集,不相互重合的地方会用nan填充
res = pd.concat([df1,df2],join='outer',ignore_index=True) # 默认是outer填充
print(res)
# 相当于两个的交集
res = pd.concat([df1,df2],join='inner',ignore_index=True)
print(res)
# 新版本pandas中按列合并只能用merge
df1 = pd.DataFrame(np.ones((3,4))*0,index=[1,2,3],columns=['a','b','c','d'])
df2 = pd.DataFrame(np.ones((3,4))*1,index=[2,3,4],columns=['b','c','d','e'])
# how {'inner','outer','left','right'}
res = pd.merge(df1,df2,how='left',left_index=True,right_index=True)
print(res)
# append 加数据
df1 = pd.DataFrame(np.ones((3,4))*0,columns=['a','b','c','d'])
df2 = pd.DataFrame(np.ones((3,4))*1,columns=['a','b','c','d'])
df3 = pd.DataFrame(np.ones((3,4))*1,columns=['a','b','c','d'])
res = df1.append([df2,df3],ignore_index=True)
print(res)
s1 = pd.Series([1,2,3,4],index=['a','b','c','d'])
res = df1.append(s1,ignore_index=True)
print(res)
结果:
a b c d
0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
a b c d
0 1.0 1.0 1.0 1.0
1 1.0 1.0 1.0 1.0
2 1.0 1.0 1.0 1.0
a b c d
0 2.0 2.0 2.0 2.0
1 2.0 2.0 2.0 2.0
2 2.0 2.0 2.0 2.0
a b c d
0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
0 1.0 1.0 1.0 1.0
1 1.0 1.0 1.0 1.0
2 1.0 1.0 1.0 1.0
0 2.0 2.0 2.0 2.0
1 2.0 2.0 2.0 2.0
2 2.0 2.0 2.0 2.0
a b c d
0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
3 1.0 1.0 1.0 1.0
4 1.0 1.0 1.0 1.0
5 1.0 1.0 1.0 1.0
6 2.0 2.0 2.0 2.0
7 2.0 2.0 2.0 2.0
8 2.0 2.0 2.0 2.0
a b c d
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
3 0.0 0.0 0.0 0.0
b c d e
2 1.0 1.0 1.0 1.0
3 1.0 1.0 1.0 1.0
4 1.0 1.0 1.0 1.0
a b c d e
0 0.0 0.0 0.0 0.0 NaN
1 0.0 0.0 0.0 0.0 NaN
2 0.0 0.0 0.0 0.0 NaN
3 NaN 1.0 1.0 1.0 1.0
4 NaN 1.0 1.0 1.0 1.0
5 NaN 1.0 1.0 1.0 1.0
b c d
0 0.0 0.0 0.0
1 0.0 0.0 0.0
2 0.0 0.0 0.0
3 1.0 1.0 1.0
4 1.0 1.0 1.0
5 1.0 1.0 1.0
a b_x c_x d_x b_y c_y d_y e
1 0.0 0.0 0.0 0.0 NaN NaN NaN NaN
2 0.0 0.0 0.0 0.0 1.0 1.0 1.0 1.0
3 0.0 0.0 0.0 0.0 1.0 1.0 1.0 1.0
a b c d
0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
3 1.0 1.0 1.0 1.0
4 1.0 1.0 1.0 1.0
5 1.0 1.0 1.0 1.0
6 1.0 1.0 1.0 1.0
7 1.0 1.0 1.0 1.0
8 1.0 1.0 1.0 1.0
a b c d
0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
3 1.0 2.0 3.0 4.0
pandas合并merge
import pandas as pd
import numpy as np
left = pd.DataFrame({'key':['K0','K1','K2','K3'],
'A':['A0','A1','A2','A3'],
'B':['B0','B1','B2','B3'],})
right = pd.DataFrame({'key':['K0','K1','K2','K3'],
'C':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3'],})
print(left)
print(right)
# merging two df by key/keys
res = pd.merge(left,right,on='key')
print(res)
# consider two keys
left = pd.DataFrame({'key1':['K0','K0','K1','K2'],
'key2':['K0','K1','K0','K1'],
'A':['A0','A1','A2','A3'],
'B':['B0','B1','B2','B3'],})
right = pd.DataFrame({'key1':['K0','K1','K1','K2'],
'key2':['K0','K0','K0','K0'],
'C':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3'],})
print(left)
print(right)
# left有一对(K1,K0),right有两对(K1,K0),inner方式合并就是把A那一对复制两遍进行合并
# how {'inner','outer','left','right'}, 默认是inner
res = pd.merge(left,right,on=['key1','key2'],how='inner')
print(res)
# how='outer',没有的就用nan
res = pd.merge(left,right,on=['key1','key2'],how='outer')
print(res)
# how='right',基于right进行合并,若left没有的就填充nan
res = pd.merge(left,right,on=['key1','key2'],how='right')
print(res)
df1 = pd.DataFrame({'col1':[0,1],'col_left':['a','b']})
df2 = pd.DataFrame({'col1':[1,2,2],'col_left':[2,2,2]})
print(df1)
print(df2)
# given the indicator a custom name
res = pd.merge(df1,df2,on='col1',how='outer',indicator=True)
print(res)
res = pd.merge(df1,df2,on='col1',how='outer',indicator='indicator_column')
print(res)
# merge by index
left = pd.DataFrame({'A':['A0','A1','A2'],
'B':['B0','B1','B2'],},
index=['K0','K1','K2'])
right = pd.DataFrame({'C':['C0','C1','C2'],
'D':['D0','D1','D2'],},
index=['K0','K1','K2'])
print(left)
print(right)
# left_index and right_index
res = pd.merge(left,right,left_index=True,right_index=True,how='outer')
print(res)
# handle overlapping
boys = pd.DataFrame({'k':['K0','K1','K2'],'age':[1,2,3]})
girls = pd.DataFrame({'k':['K0','K0','K3'],'age':[4,5,6]})
print(boys)
print(girls)
res = pd.merge(boys,girls,on='k',how='inner')
print(res)
res = pd.merge(boys,girls,on='k',how='inner',suffixes=['_boy','_girl']) # 设置同名key的后缀
print(res)
结果:
key A B
0 K0 A0 B0
1 K1 A1 B1
2 K2 A2 B2
3 K3 A3 B3
key C D
0 K0 C0 D0
1 K1 C1 D1
2 K2 C2 D2
3 K3 C3 D3
key A B C D
0 K0 A0 B0 C0 D0
1 K1 A1 B1 C1 D1
2 K2 A2 B2 C2 D2
3 K3 A3 B3 C3 D3
key1 key2 A B
0 K0 K0 A0 B0
1 K0 K1 A1 B1
2 K1 K0 A2 B2
3 K2 K1 A3 B3
key1 key2 C D
0 K0 K0 C0 D0
1 K1 K0 C1 D1
2 K1 K0 C2 D2
3 K2 K0 C3 D3
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K1 K0 A2 B2 C1 D1
2 K1 K0 A2 B2 C2 D2
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K0 K1 A1 B1 NaN NaN
2 K1 K0 A2 B2 C1 D1
3 K1 K0 A2 B2 C2 D2
4 K2 K1 A3 B3 NaN NaN
5 K2 K0 NaN NaN C3 D3
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K1 K0 A2 B2 C1 D1
2 K1 K0 A2 B2 C2 D2
3 K2 K0 NaN NaN C3 D3
col1 col_left
0 0 a
1 1 b
col1 col_left
0 1 2
1 2 2
2 2 2
col1 col_left_x col_left_y _merge
0 0 a NaN left_only
1 1 b 2.0 both
2 2 NaN 2.0 right_only
3 2 NaN 2.0 right_only
col1 col_left_x col_left_y indicator_column
0 0 a NaN left_only
1 1 b 2.0 both
2 2 NaN 2.0 right_only
3 2 NaN 2.0 right_only
A B
K0 A0 B0
K1 A1 B1
K2 A2 B2
C D
K0 C0 D0
K1 C1 D1
K2 C2 D2
A B C D
K0 A0 B0 C0 D0
K1 A1 B1 C1 D1
K2 A2 B2 C2 D2
k age
0 K0 1
1 K1 2
2 K2 3
k age
0 K0 4
1 K0 5
2 K3 6
k age_x age_y
0 K0 1 4
1 K0 1 5
k age_boy age_girl
0 K0 1 4
1 K0 1 5
pandas plot 绘图
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Series
data = pd.Series(np.random.randn(1000),index=np.arange(1000))
data = data.cumsum()
data.plot()
# DataFrame
data = pd.DataFrame(np.random.randn(1000,4),
index=np.arange(1000),
columns=list("ABCD"))
data = data.cumsum()
data.plot()
# plot methods: 'bar', 'hist','box','kde','area','scatter','hexbin','pie'
ax = data.plot.scatter(x='A',y='B',color='DarkBlue',label='Class 1')
data.plot.scatter(x='A',y='C',color='DarkGreen',label='Class 2',ax=ax)
plt.show()
结果:
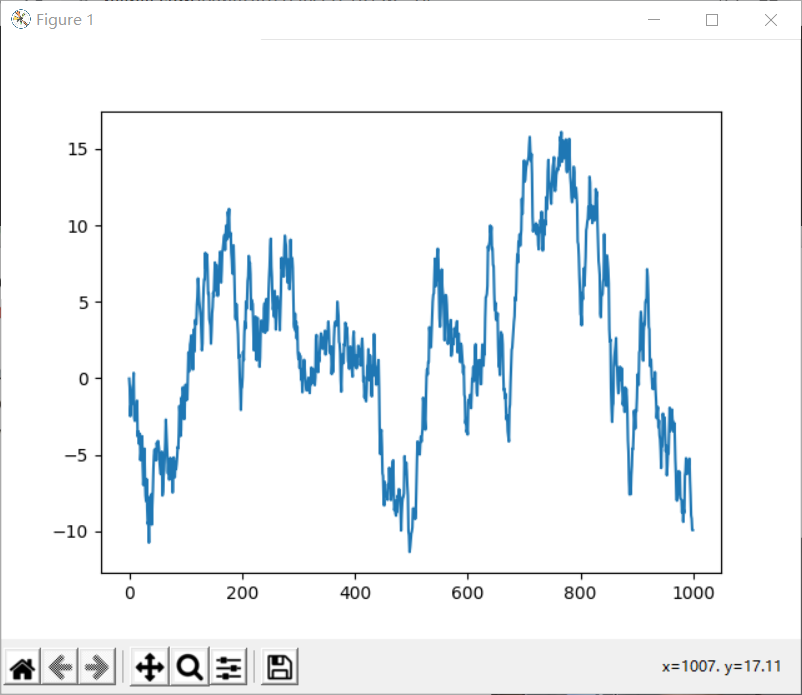
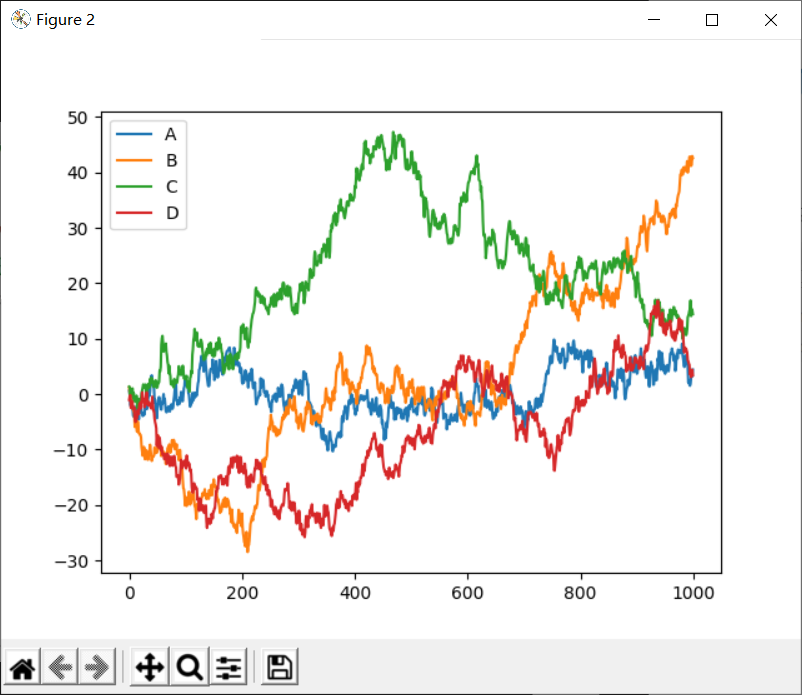
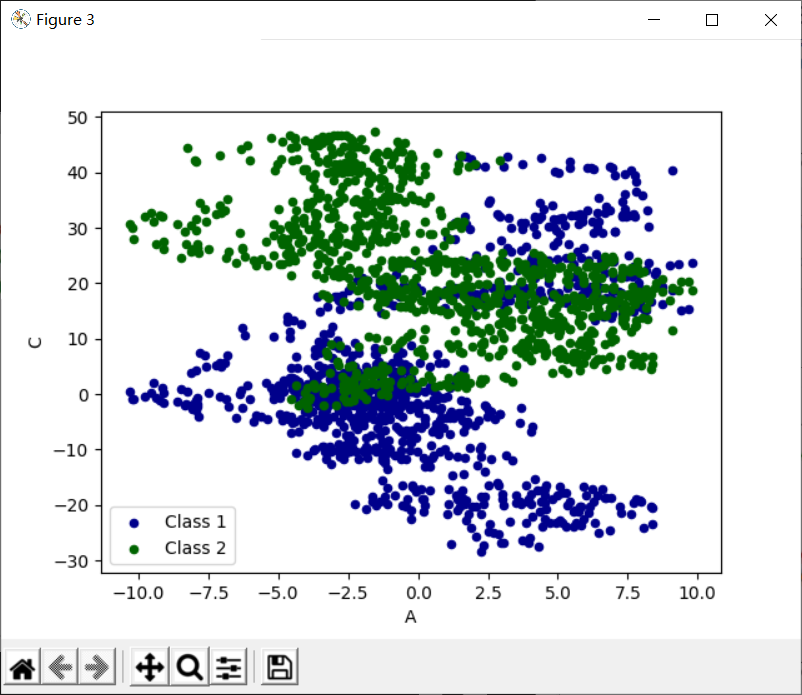
补充














 6425
6425











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









