







目前随着AI应用的爆发式增长,支持AI模型训练的显卡硬件也变得炙手可热。目前,由于xx颁布了芯片销售禁令,随着而来的是,在国内高端的英伟达显卡买不到了,中低端的显卡价格也水涨船高。在此环境下,华为技术有限公司自研的达芬奇架构的Ascend芯片映入了AI开发者的视野,据说Ascend910高端型号的芯片的算力已经跟NVIDIA A100旗鼓相当,但是前者价格是后者的十分之一!!! 目前国内生成式AI巨头,比如阿里的通义千问,智谱AI的ChatGLM都对华为Ascend芯片做了适配,可见未来Ascend芯片无论是市场前景还是行业应用,都将越来越普遍,或许在不久,显卡不再是英伟达一家独大。
想了解更多有关Ascend芯片的架构及特点,可以查看官方写的论文,地址:
本文记录如何在拥有Ascend310芯片的Ubuntu服务器上搭建docker推理环境并完成YOLO8推理。
一、驱动下载安装
直接到Ascend官网,根据自己的芯片型号下载对应的驱动

我们安装上面页面给出的下载链接,下载driver和固件

驱动的安装也较为简单,首先增加对软件包的可执行权限
chmod +x A300-3010-npu-driver_23.0.0_linux-x86_64.run
chmod +x A300-3010-npu-firmware_7.1.0.3.220.run然后执行下面的命令安装:
./A300-3010-npu-driver_23.0.0_linux-x86_64.run --full --install-for-all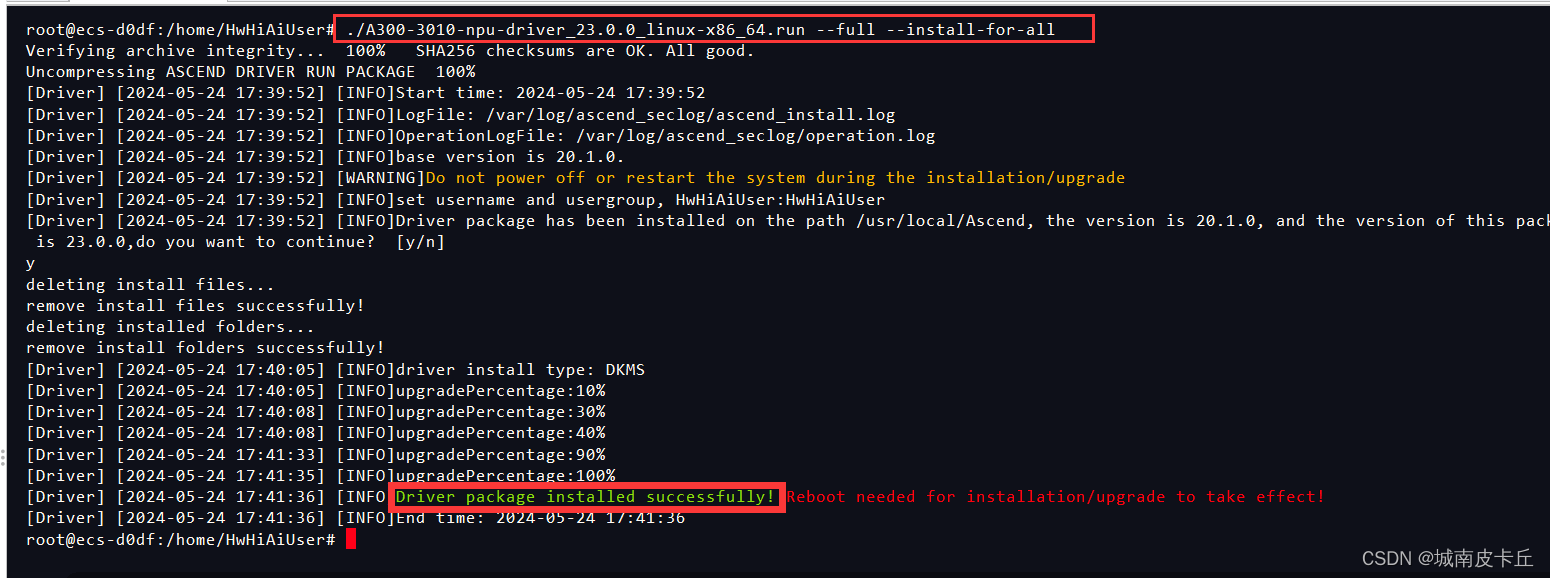
关机重启,驱动安装成功
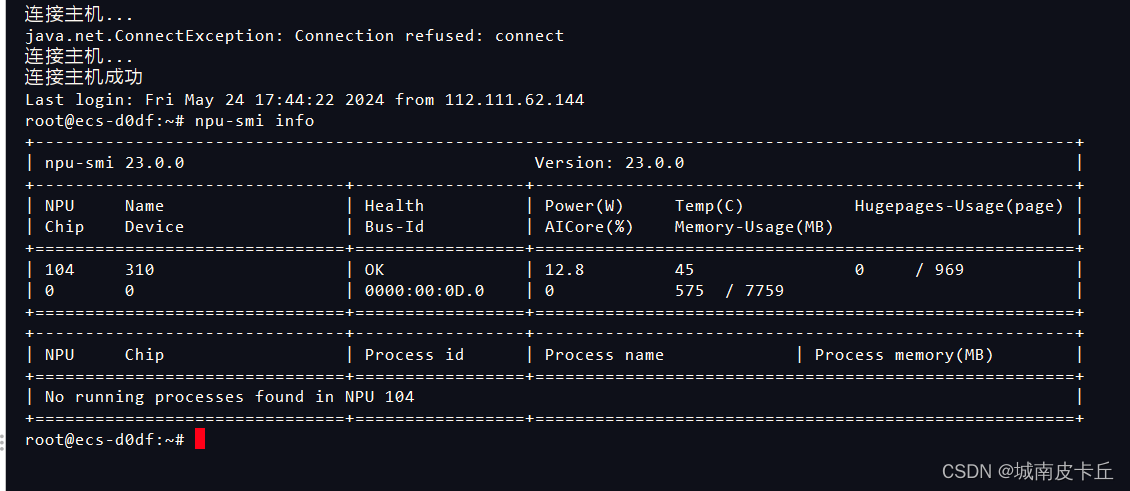
关于驱动安装,官方也给出了具体的详细教程:
二、Docker环境搭建
Ascend芯片推理环境我们选择在docker容器内搭建,AscendHub上有各种各样已经搭建好相关环境的Docker镜像,只需要宿主机有ascend芯片和驱动即可,免去了我们手动下载配置CANN、mxvision等软件。因此,这种环境配置方式首先需要在服务器上安装好docker,docker的安装较为简单,如果没有安装,apt源设置正确且可用,直接按照下面的步骤即可安装docker。

安装好docker以后就可以下载ascendhub的官方镜像,下面给出AscendHub地址:
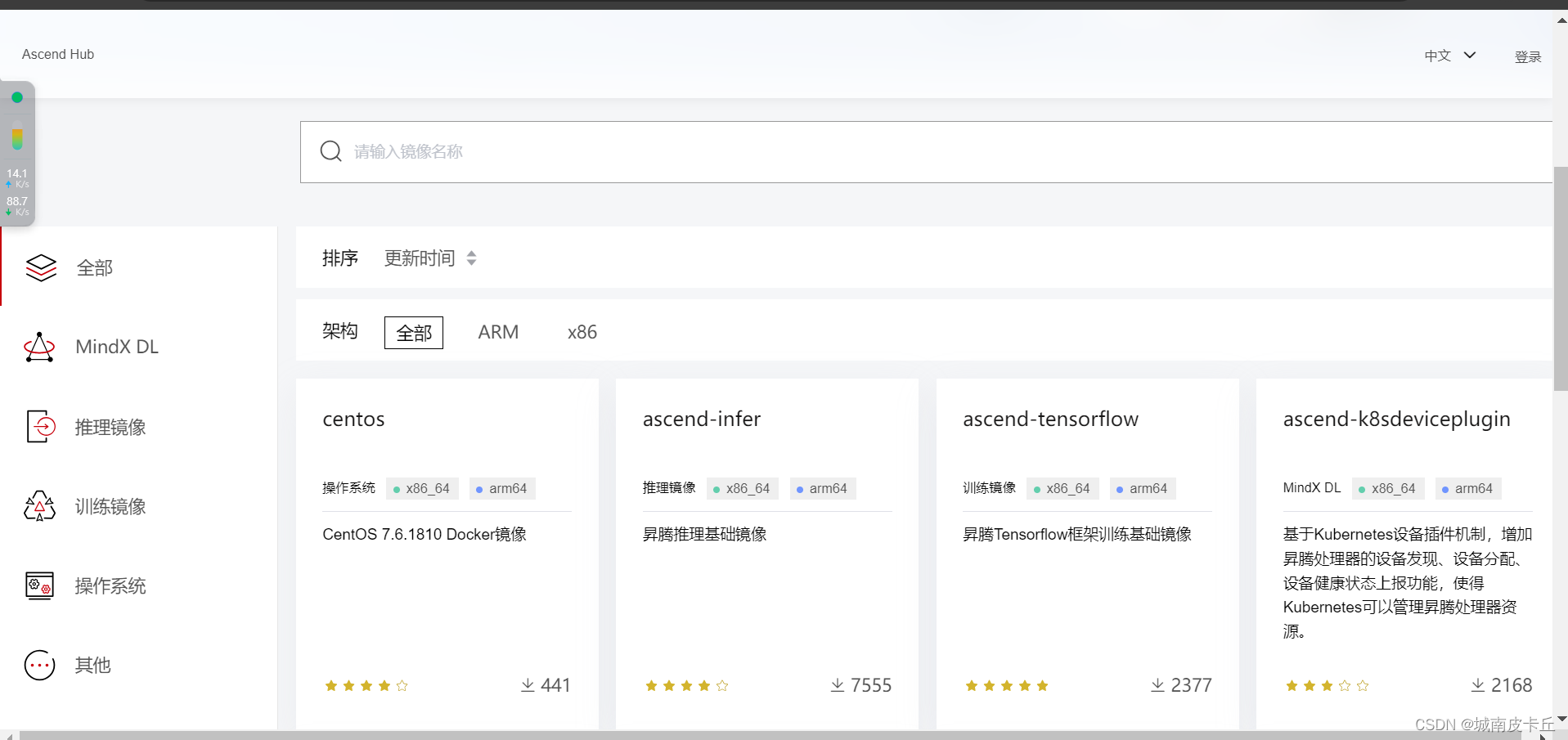
我们直接注册账号然后按照上面给出的步骤把docker images下载到服务器即可。值得注意的是宿主机需要满足下面的调条件:
- 物理机上有Ascend芯片
- 物理机已安装对应CANN版本的驱动和固件(注意跟你要下载的镜像支持的驱动对应,比如在ascendhub下载的镜像往往是最新版本的cann、mxvision,此时宿主机的驱动版本注意对应,如果驱动太老的话是不行的,需要升级或者重装。版本对应关系可以从下面给出的昇腾官网查询到)
- 物理机已安装Docker,且Docker网络可用
我这里以安装 infer-modelzoo 镜像(mxvision版本)为例,该镜像包含模型转换、模型推理等功能。

将镜像下载到本地以后,docker启动命令示例如下
docker run -it \ --device=/dev/davinci0 \ --device=/dev/davinci_manager \ --device=/dev/devmm_svm \ --device=/dev/hisi_hdc \ -v /usr/local/dcmi:/usr/local/dcmi \ -v /var/log/npu:/var/log/npu \ -v /usr/local/Ascend/driver:/usr/local/Ascend/driver \ -v /usr/slog:/usr/slog \ -v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \ -v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \ -v /usr/local/Ascend/driver/tools/:/usr/local/Ascend/driver/tools/ \ -v /usr/local/Ascend/add-ons/:/usr/local/Ascend/add-ons/ \ -v /data:/data \ ascendhub.huawei.com/public-ascendhub/infer-modelzoo:{tag} \ /bin/bash
- tag为镜像版本号,如21.0.3。
- -u 以指定用户进入容器,如不指定用户,默认为HwHiAiUser。
- /usr/local/Ascend/driver为物理机上安装的NPU驱动目录,根据实际安装的驱动目录进行挂载。
- /data为模型转换和推理要用的代码目录,根据实际代码目录进行挂载。
- 命令中默认挂载0卡到容器中,可根据实际需要挂载device。
下面是我自己的docker容器启动命令:
docker run -itd --name ascend-infer --network=host --device=/dev/davinci0 --device=/dev/davinci_manager --device=/
dev/devmm_svm --device=/dev/hisi_hdc -v /usr/local/dcmi:/usr/local/dcmi -v /var/log/npu:/var/log/npu -v /usr/local/Ascend/driver:/usr/local/Ascend/driver -v
/usr/slog:/usr/slog -v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi -v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ -v /usr/local/Ascen
d/driver/tools/:/usr/local/Ascend/driver/tools/ -v /usr/local/Ascend/add-ons/:/usr/local/Ascend/add-ons/ -v /work:/work ascendhub.huawei.com/public-ascendhub/infer-modelzoo:23.0.RC2-mxvision /bin/bash

上图可以看到,我们成功启动了容器并进入到了容器中。
三、模型转化
接下来我们在本地电脑将yolov8s.pt转onnx(我这里直接用的是yolo export命令)
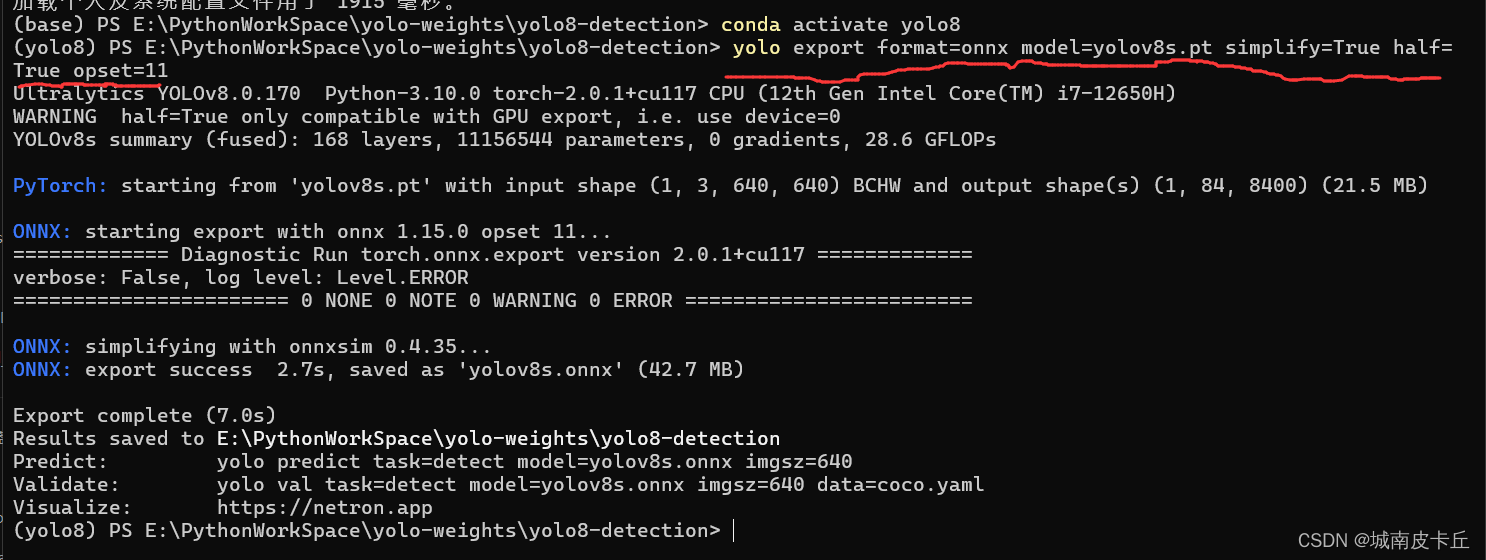
特别需要注意,pt模型转onnx模型的过程中,onnx算子版本必须保持为11,否则后onnx转om会失败!!!
将转化好的ONNX模型上传到服务器的work目录下(由于容器启动的时候/work挂载/work,因此将本地的onnx模型上传到根目录下的/work目录下,在容器内就可以使用该onnx文件)

下面在容器内对onnx模型进行转化,将其转化为适用于Ascend显卡平台的om模型 。这里我们要使用到ATC转化工具(上面运行的容器内有安装好),下面首先简单了解一下ATC命令:
atc --model=./yolov8s.onnx --framework=5 --output=./yolov8s --input_format=NCHW --input_shape="images:1,3,640,640" --soc_version=Ascend310
--model:待转换的ONNX模型。(必须)
--framework:5代表ONNX模型。(必须)
--output:输出的om模型。(必须)
--input_format:输入数据的格式。Caffe、ONNX默认为NCHW;TensorFlow默认为NHWC。
--input_shape:输入数据的shape
--soc_version: 模型转换时指定芯片版本(必须)
上面的转换指令几乎是最简的,更多atc转化参数请参考官方文档,链接如下:
我这里以HwHiAiUser用户登录进docker容器内执行 上述atc模型转换命令出现报错,有大量的Permission Error。(因为我是以root登录进服务器并且以root身份将onnx文件上传到服务器,因此onnx文件所属组和拥有组都是root)

大概是 HwHiAiUser用户无相关权限,退出容器以root身份进入docker内,重新执行上述atc模型转化命令,成功。

此时,在容器内的/work目录下可以看到成功转化的yolov8s.om模型。

接下来修改yolov8s.om所属组和拥有者,使其所属用户和用户组为HwHiAiUser
chown HwHiAiUser:HwHiAiUser yolov8s.om
chown HwHiAiUser:HwHiAiUser fusion_result.json可以直接将yolo8s.om所在的上级目录(work目录)更改为所属用户和用户组为HwHiAiUser
chown -R HwHiAiUser:HwHiAiUser /work
四、使用mxvision sdk进行推理
接下来我们mxvision使用yolov8s.om模型进行加速推理 。官方也有详细的教程:
开发流程-使用API接口方式开发(Python)-mxVision 用户指南-智能视频分析-MindX SDK5.0.1开发文档-昇腾社区 (hiascend.com)
mxvision sdk一般有两种推理方式。一种是pipeline,需要我们写pipeline文件,不得不说ascend自带的视频图片编解码能力(DVPP、AIPP)真的很强大,不仅自持硬件加速功能,而且模块都封装好了,只需要我们调用相关接口即可,比如图片直接输入、视频流直接输入rtsp流地址即可,无需我们自己写编解码程序、写前处理程序、写后处理程序,直接将模型预测结果返回!!! 改变了我们过去需要用opencv numpy等去做相关的工作。第二种是使用api的方式,这种方式不常用,官方给出的案例都是pipeline推理方式,几乎没有一个完整的api推理的案例,唯一可借鉴的是ascend论坛给出的:
https://www.hiascend.com/forum/thread-0281145770724671193-1-1.html
我们这里使用api推理方式,因为这种方式最符合我们过去使用pytorch、paddlepaddle、tensorflow等原生框架推理、ONNX中间态推理的风格习惯,而使用pipeline推理虽然代码量很少很少,但是得要我们比较深入地了解pipeline的流程及芯片内置的模块、接口等。有的项目为了适配不同的平台,可能分为Tensorrt推理版本的代码、onnx推理版本的代码、opencv dnn推理版本的代码 、openvion推理版本.....而使用api推理只需要我们修改之前写过的很少的代码,就拿onnx推理版本来说,基本上修改几行代码即可将onnx推理版本的代码修改为华为Ascend推理版本的代码。
import cv2
import numpy as np
import time
from mindx.sdk import Tensor # mxVision 中的 Tensor 数据结构
from mindx.sdk import base
CLASSES={0: 'person', 1: 'bicycle', 2: 'car', 3: 'motorcycle', 4: 'airplane', 5: 'bus',
6: 'train', 7: 'truck', 8: 'boat', 9: 'traffic light', 10: 'fire hydrant',
11: 'stop sign', 12: 'parking meter', 13: 'bench', 14: 'bird', 15: 'cat',
16: 'dog', 17: 'horse', 18: 'sheep', 19: 'cow', 20: 'elephant', 21: 'bear',
22: 'zebra', 23: 'giraffe', 24: 'backpack', 25: 'umbrella', 26: 'handbag',
27: 'tie', 28: 'suitcase', 29: 'frisbee', 30: 'skis', 31: 'snowboard',
32: 'sports ball', 33: 'kite', 34: 'baseball bat', 35: 'baseball glove',
36: 'skateboard', 37: 'surfboard', 38: 'tennis racket', 39: 'bottle',
40: 'wine glass', 41: 'cup', 42: 'fork', 43: 'knife', 44: 'spoon', 45: 'bowl',
46: 'banana', 47: 'apple', 48: 'sandwich', 49: 'orange', 50: 'broccoli',
51: 'carrot', 52: 'hot dog', 53: 'pizza', 54: 'donut', 55: 'cake', 56: 'chair',
57: 'couch', 58: 'potted plant', 59: 'bed', 60: 'dining table', 61: 'toilet',
62: 'tv', 63: 'laptop', 64: 'mouse', 65: 'remote', 66: 'keyboard', 67: 'cell phone',
68: 'microwave', 69: 'oven', 70: 'toaster', 71: 'sink', 72: 'refrigerator',
73: 'book', 74: 'clock', 75: 'vase', 76: 'scissors', 77: 'teddy bear',
78: 'hair drier', 79: 'toothbrush'}
class YOLO8:
def __init__(self,model_path,conf_thres=0.25, iou_thres=0.45):
self.conf_threshold = conf_thres
self.iou_threshold = iou_thres
self.input_height=640
self.input_width=640
self.class_names=CLASSES
reverse_class_names = {v : k for k, v in self.class_names.items()}
self.reverse_class_names=reverse_class_names
#模型初始化
base.mx_init()
self.model = base.model(modelPath='yolov8s.om', deviceId=0)
#前处理模块
def pre_process(self,img, new_shape):
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img, _, _ = self.letterbox(img, new_shape)
img = img.astype('float32')
img /= 255.0
img = np.transpose(img, [2, 0, 1])
img = np.expand_dims(img, axis=0)
img = np.ascontiguousarray(img)
return img
#推理模块
def inference(self,img):
# print(img)
img_tensor = Tensor(img)
img_tensor.to_device(0)
start = time.perf_counter()
outputs = self.model.infer([img_tensor])
print(f"Inference time: {(time.perf_counter() - start) * 1000:.2f} ms")
nps = [] # 原始numpy结果数组
for i in range(len(outputs)):
outputs[i].to_host()
n = np.array(outputs[i])
nps.append(n) # 使用自定义后处理时直接用此numpy数组即可!!!
#这里的nps 数组维度就是[1,84,8400].后续就可以后处理了
return nps
.......
letterbox nms 后处理等模块与原来保持一致,此处省略
然后执行我们写好的yolo8_om_det.py ,我这里推理了yolo官方给出的bus.jpg(下图),推理尺寸640*640

可以看到程序执行成功,整个推理过程为14ms左右,我这里的服务器是租用的,应该是租用服务器Ascend310算力做了切分之类的,反正这个推理速度不是正常的,不过这个主要以演示为主,正常的应该是3ms以内推理一张图片,下面是图片推理结果

















 207
207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











