







OpenMP基础结构:
例程:
#include <iostream>
#include <omp.h>
#include <cstdio>
#include <bits/stdc++.h>
using namespace std;
int main(int argc, char *argv[]){
int nt, tid;
int np;
const int MAX=256;
char buf[32]={0};
#pragma omp parallel private(nt, tid) num_threads(8)
{
tid=114514;
tid=omp_get_thread_num ();
printf("Hello world from OpenMP thread %d\n",tid);
if(tid==0){
nt=omp_get_num_threads ();
printf("num of threads = %d\n",nt);
}
}
return 0;
}
-
需要在编译的时候添加
-fopenmp参数:
对于Qt, 需要在pro配置文件中添加:
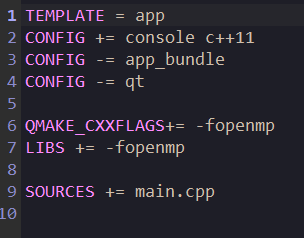
-
在编程时, 需要在并行域处使用
#pragma制导, 并将后头的程序全部放入代码块内clauses用来说明并行域的附加信息

-
在并行域结束后会有一个自动的
barrier隐式同步
常用の附加信息:
并行块:
parallel
表示下头的程序所有线程都会执行
设置数据为公有或私有:
shared(var1, var2, ...)
private(var1, var2, ...)
设置变量为线程私有或是公共变量
前者就和串行执行时相同, 后者所有线程访问此变量时, 使用的都是同一地址, 在编程时需要注意数据竞争问题
default(shared|none)
在fortran中还可以指定为private
设置所有未声明的变量为指定模式, 为none时需指定所有变量的模式, 否则会报错
OpenMP中, 有几个默认情况:
- 所有的循环变量(如for), 临时变量, 写变量 通常为私有
- 数组变量, 只读变量 通常为共有
- 默认情况为公有
拷贝:
copyin
用于将主进程中threadprivate的数据拷贝到每个线程中, 使得每个线程都获得初始值相同的私有变量
#include <iostream>
#include <omp.h>
#include <cstdio>
#include <bits/stdc++.h>
using namespace std;
int a=114514;
#pragma omp threadprivate(a)
int main(int argc, char *argv[]){
int nt, tid;
int np;
const int MAX=256;
char buf[32]={0};
#pragma omp parallel private(nt, tid) shared(np) num_threads(4) copyin(a)
{
tid=114514;
tid=omp_get_thread_num ();
printf("Thread %d: a= %d\n",tid ,a );
}
return 0;
}
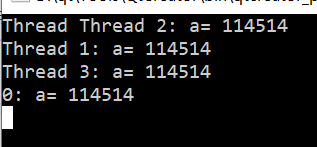
归约:
reduction(+:pi)
与MPI的MPI_Reduce相似, 会在线程join时执行归约操作:
他有俩参数
- 对数据实行的操作, 一定是一个二元运算, 包括min & max
- 指定的变量
reduction中指定的变量无需进行额外的shared() 或 private() 设置
其会被自动分割为private和shared
例程:
使用Reduction计算PI
#include <iostream>
#include <omp.h>
#include <cstdio>
#include <bits/stdc++.h>
using namespace std;
static int n=10000;
const int NUM_THREADS=4;
int main(int argc, char *argv[]){
double pi, startTime=0.0, endTime=0.0;
omp_set_num_threads (NUM_THREADS);
startTime=omp_get_wtime ();
#pragma omp parallel reduction(+:pi)
{
int tid=omp_get_thread_num ();
int rowTime=n/NUM_THREADS;
double temp=0.0;
for(int i=0;i<rowTime;++i){
temp=((i*NUM_THREADS+tid)+0.5)/n;
pi+=4.0/(1+temp*temp);
}
pi/=n;
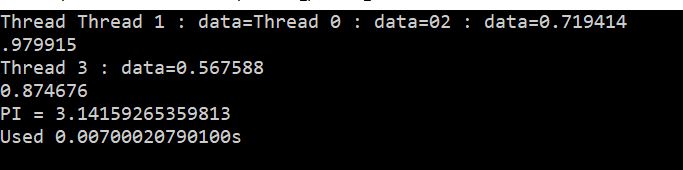
printf("Thread %d : data=%lf\n", tid, pi);
}
printf("PI = %.14lf\n",pi);
endTime=omp_get_wtime ();
printf("Used %.14lfs\n",endTime-startTime);
return 0;
}
任务划分并行制导:
for制导:
相当于OpenMP自动将for划分到各个线程中执行, 无需手动分割任务
#pragma omp for
通常直接放到需要分割的for上头, 嵌套与parallel块中
每次for制导完成后所有线程都会执行一次同步
此时需要注意数据竞争问题
例程:
使用for制导 + reduction归约求PI
#include <iostream>
#include <omp.h>
#include <cstdio>
#include <bits/stdc++.h>
using namespace std;
static int n=100000;
const int NUM_THREADS=4;
int main(int argc, char *argv[]){
double pi, startTime=0.0, endTime=0.0;
omp_set_num_threads (NUM_THREADS);
startTime=omp_get_wtime ();
#pragma omp parallel reduction(+:pi)
{
int tid=omp_get_thread_num ();
double temp=0.0;
#pragma omp for
for(int i=0;i<n;++i){
temp=(i+0.5)/n;
pi+=4.0/(1+temp*temp);
}
pi/=n;
printf("Thread %d : data=%lf\n", tid, pi);
}
printf("PI = %.14lf\n",pi);
endTime=omp_get_wtime ();
printf("Used %.14lfs\n",endTime-startTime);
return 0;
}
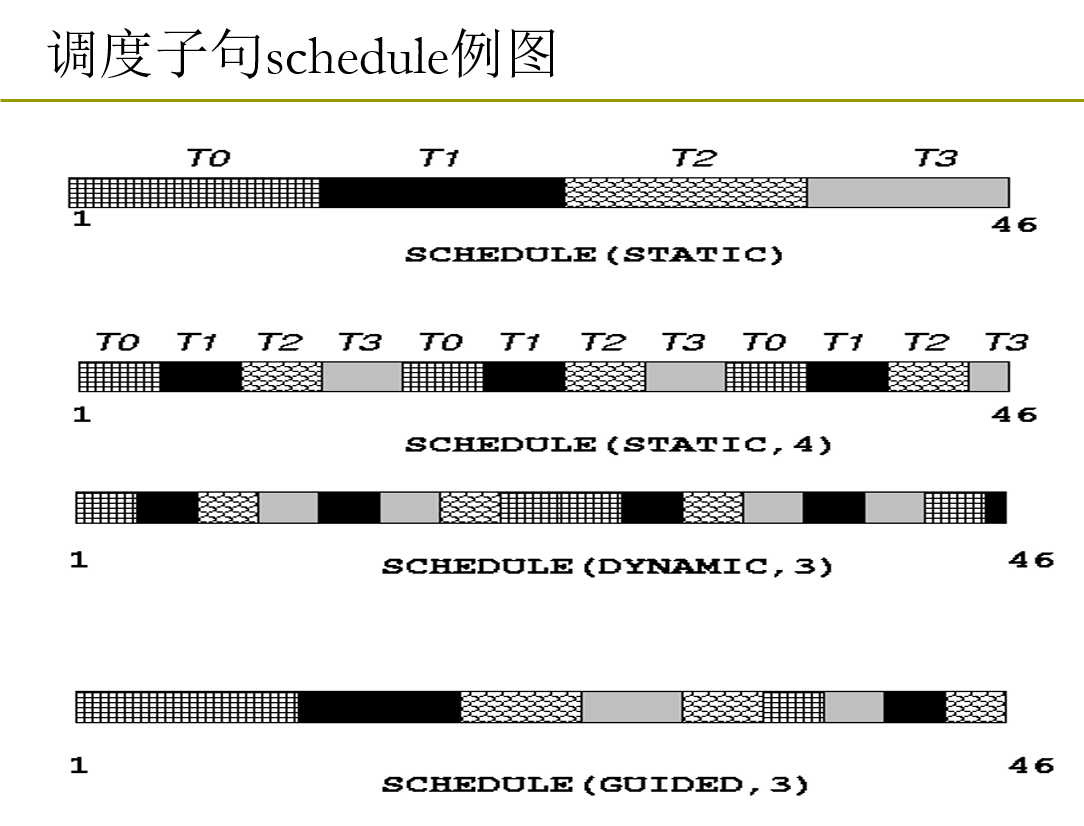
指定for制导的数据分组
默认情况下, OpenMP会将数据分成差不多这个样子:
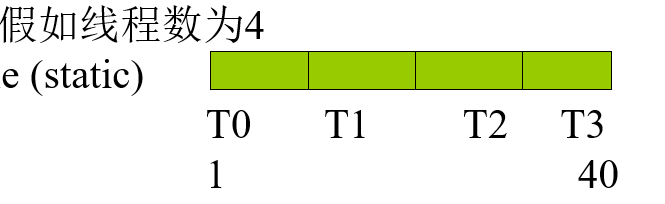
如果要分成这个样子(即每个线程每次拿到固定大小的数据块), 需要使用schedule()操作:
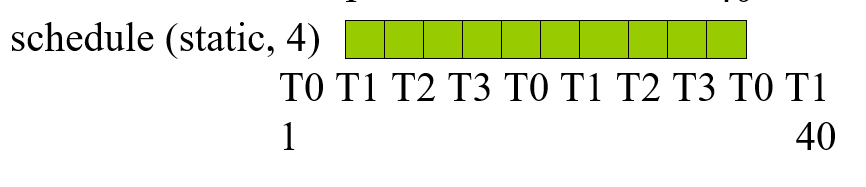
schedule(mode [, chunkSize])
-
第一个为必要参数, 指定schedule的模式:
可选: static, dynamic, duided, runtime
最后一个runtime 不是一个模式, 而是使用环境变量OMP_SCHEDULED来选择三种中的某一个, 并且此时如果指定chunkSize是非法的
-
第二个为数据块的大小, int类型
不同的调度模式:
最标准的静态分配, 与手动分配相同

这玩意相当于各个线程负载均衡, 每次申请的数量仍然是chunkSize, 但执行较快的进程申请的次数也较多, 一定程度上做到了线程负载均衡

进阶的dynamic模式, 如下:

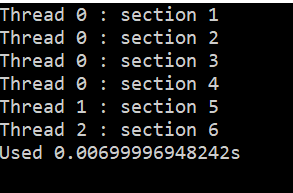
sections制导:
分为两种:
#pragma onp sections
#pragma omp parallel sections
第一种为串行代码, 由主进程进行
第二种为并行代码, 每个进程执行其中不同的代码块, 相当于MPMD
例程:
#include <iostream>
#include <omp.h>
#include <cstdio>
#include <bits/stdc++.h>
using namespace std;
static int n=100000;
const int NUM_THREADS=4;
int main(int argc, char *argv[]){
double startTime=0.0, endTime=0.0;
omp_set_num_threads (NUM_THREADS);
startTime=omp_get_wtime ();
//----------------------------------------
#pragma omp sections
{
#pragma omp section
{
printf("Thread %d : section 1\n",omp_get_thread_num ());
}
#pragma omp section
{
printf("Thread %d : section 2\n",omp_get_thread_num ());
}
#pragma omp section
{
printf("Thread %d : section 3\n",omp_get_thread_num ());
}
}
#pragma omp parallel sections
{
#pragma omp section
{
printf("Thread %d : section 4\n",omp_get_thread_num ());
}
#pragma omp section
{
printf("Thread %d : section 5\n",omp_get_thread_num ());
}
#pragma omp section
{
printf("Thread %d : section 6\n",omp_get_thread_num ());
}
}
//----------------------------------------
endTime=omp_get_wtime ();
printf("Used %.14lfs\n",endTime-startTime);
return 0;
}
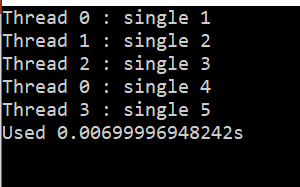
single制导:
single块内的代码仅由最先到达的进程执行(仅被执行一次), 其他进程会在single块结束处等待所有进程同步
例程:
#include <iostream>
#include <omp.h>
#include <cstdio>
#include <bits/stdc++.h>
using namespace std;
const int NUM_THREADS=4;
int main(int argc, char *argv[]){
double startTime=0.0, endTime=0.0;
omp_set_num_threads (NUM_THREADS);
startTime=omp_get_wtime ();
//----------------------------------------
#pragma omp parallel
{
#pragma omp single
{
printf("Thread %d : single 1\n",omp_get_thread_num ());
}
#pragma omp single
{
printf("Thread %d : single 2\n",omp_get_thread_num ());
}
#pragma omp single
{
printf("Thread %d : single 3\n",omp_get_thread_num ());
}
#pragma omp single
{
printf("Thread %d : single 4\n",omp_get_thread_num ());
}
#pragma omp single
{
printf("Thread %d : single 5\n",omp_get_thread_num ());
}
}
//----------------------------------------
endTime=omp_get_wtime ();
printf("Used %.14lfs\n",endTime-startTime);
return 0;
}
使用nowait可以取消进程同步, 这玩意也可以用在所有含有隐式同步的制导中, 用于取消隐式同步
使用nowait后, 就变成了这样:
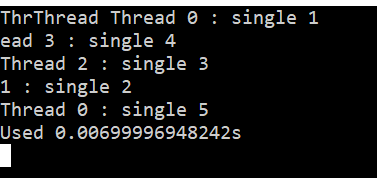
master制导
master块内的代码仅由主进程执行
例程
还是上头的程序
#include <iostream>
#include <omp.h>
#include <cstdio>
#include <bits/stdc++.h>
using namespace std;
const int NUM_THREADS=4;
int main(int argc, char *argv[]){
double startTime=0.0, endTime=0.0;
omp_set_num_threads (NUM_THREADS);
startTime=omp_get_wtime ();
//----------------------------------------
#pragma omp parallel
{
#pragma omp master
{
printf("Thread %d : master 1\n",omp_get_thread_num ());
}
#pragma omp master
{
printf("Thread %d : master 2\n",omp_get_thread_num ());
}
#pragma omp master
{
printf("Thread %d : master 3\n",omp_get_thread_num ());
}
#pragma omp master
{
printf("Thread %d : master 4\n",omp_get_thread_num ());
}
#pragma omp master
{
printf("Thread %d : master 5\n",omp_get_thread_num ());
}
}
//----------------------------------------
endTime=omp_get_wtime ();
printf("Used %.14lfs\n",endTime-startTime);
return 0;
}

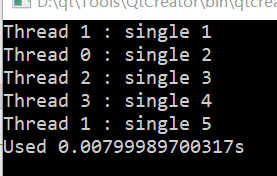
barrier制导
与MPI_Barrier()相似, 此语句强制所有进程在此处同步, 只有所有进程同步完成后才能进行下头的步骤
例程
#include <iostream>
#include <omp.h>
#include <cstdio>
#include <bits/stdc++.h>
using namespace std;
const int NUM_THREADS=4;
int main(int argc, char *argv[]){
double startTime=0.0, endTime=0.0;
omp_set_num_threads (NUM_THREADS);
startTime=omp_get_wtime ();
//----------------------------------------
#pragma omp parallel
{
#pragma omp single nowait
{
printf("Thread %d : single 1\n",omp_get_thread_num ());
}
#pragma omp barrier
#pragma omp single nowait
{
printf("Thread %d : single 2\n",omp_get_thread_num ());
}
#pragma omp barrier
#pragma omp single nowait
{
printf("Thread %d : single 3\n",omp_get_thread_num ());
}
#pragma omp barrier
#pragma omp single nowait
{
printf("Thread %d : single 4\n",omp_get_thread_num ());
}
#pragma omp barrier
#pragma omp single nowait
{
printf("Thread %d : single 5\n",omp_get_thread_num ());
}
#pragma omp barrier
}
//----------------------------------------
endTime=omp_get_wtime ();
printf("Used %.14lfs\n",endTime-startTime);
return 0;
}
flush制导:
#pragma omp flush [(var1, var2, ...)]
flush标记了一个变量同步点, 保证所有进程中的共享变量值相同
强制刷新每个线程的临时视图,使其和内存视图保持一致,即:使线程中缓存的变量值和内存中的变量值保持一致
通常情况下很少使用到flush, 因为其会在大部分#pragma语句中隐式执行
锁:
多线程并发执行必然需要锁来保证安全性
critical锁:
critical译为临界, 其实就是将代码块标记为临界区, 同一时间只能有一个进程在临界区内
#pragma omp critical [(name)]
{
<临界区代码>
}
后头跟的name参数是临界段的名称, 通常还是推荐加个名字
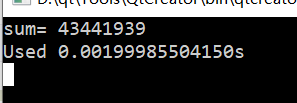
例程:
每次运行这个程序, 结果都是不一样的
#include <iostream>
#include <omp.h>
#include <cstdio>
#include <bits/stdc++.h>
using namespace std;
const int MAX=10000;
const int NUM_THREADS=4;
int main(int argc, char *argv[]){
double startTime=0.0, endTime=0.0;
int sum=0;
omp_set_num_threads (NUM_THREADS);
startTime=omp_get_wtime ();
//----------------------------------------
#pragma omp parallel shared(sum)
{
#pragma omp for
for(int i=0;i<MAX;++i){
sum+=i;
}
}
printf("sum= %d\n",sum);
//----------------------------------------
endTime=omp_get_wtime ();
printf("Used %.14lfs\n",endTime-startTime);
return 0;
}
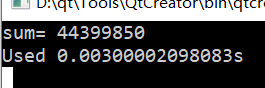
加上critical之后:
#pragma omp parallel shared(sum)
{
#pragma omp for
for(int i=0;i<MAX;++i){
#pragma omp critical
sum+=i;
}
}
printf("sum= %d\n",sum);

atomic锁:
atomic操作与critical操作作用相似, 但是执行的速度快很多
同一个操作, critical & atomic 的比较:

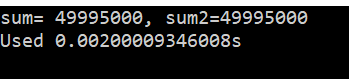
使用上, atomic仅支持部分语句, 且不支持程序块, 但是critical支持程序块:

所以原则上, 对于数据的更新, 优先使用atomic, 而后在考虑critical
互斥锁:
这部分PPT讲的不是很详细
如需详细学习可以参考这里:
https://www.cnblogs.com/xudong-bupt/p/3574818.html
- void omp_init_lock(omp_lock *) 初始化互斥器
- void omp_destroy_lock(omp_lock *) 销毁互斥器
- void omp_set_lock(omp_lock *) 获得互斥器
- void omp_unset_lock(omp_lock *) 释放互斥器
- bool omp_test_lock(omp_lock *) 试图获得互斥器,如果获得成功返回true,否则返回false
这里有点像PV操作
运行库函数:
这里主要介绍常用的OpenMP库函数
其实在之前的例程中都已经用过了
-
获取线程数:
int omp_get_num_threads(); -
获取线程号:
int omp_get_thread_num(); -
设定执行的线程数量:
void omp_set_num_threads(); -
获取墙上时间:
double omp_get_wtime();这个和MPI相似
环境变量:
本部分就这些:
















 1588
1588











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









