







北桥、南桥
早期cpu核心频率不高,和内存的频率一样。因此cpu和内存都是直接连接到了一个总线上。但是一些I/O设备,eg 键盘、磁盘的访问速度相比cpu和内存的速度还是慢了很多。为了协调他们之间的速度,这些外设都会通过一个I/O控制器再连接到总线上。如下图所示:
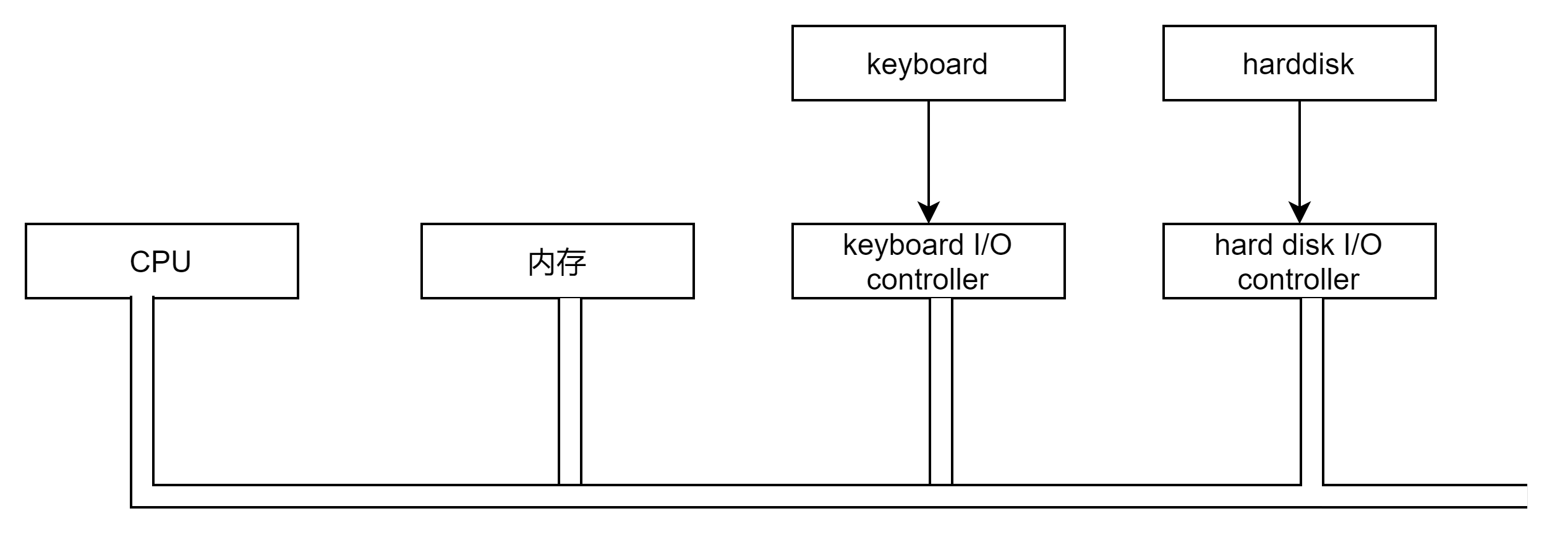
后面由于CPU核心频率提升,导致内存跟不上cpu的速度。因此CPU就不再和内存直接连在一个总线上。产生了后面的北桥、南桥芯片。北桥运行速度高,负责连接cpu等高速部件。南桥负责处理I/O等低速设备,eg键盘、usb、磁盘等。这些低速设备由南桥芯片汇总后连接到北桥上。
SMP与多核
受到制造cpu工艺等限制,cpu频率无法继续提升。因此出现了增加cpu数量的方法来提升计算速度。其中一种形式就是多对称处理器(SMP),它们每个cpu在系统中所处的地方和发挥的作用是对等的。
多核处理器:多处理器成本高,多核处理器是将多个处理器合并打包,这些打包的处理器共享一些昂贵的缓存部件,只保留了多个核心。这就是多处理器。
那感觉多对称处理器里面的各个cpu都是完全独立的咯。多核处理器是SMP的简化版
线程实现的两种方式
内核线程:线程的信息由内核来维护。感觉linux就是这样实现的啊。内核能够感知到一个进程中的多个线程。线程的调度有内核统一调度。可移植性差,需要内核支持、线程调度涉及到上下文切换、如果内核线程数量受限,会导致用户线程数量也受到限制
用户态实现: 用户进程需要专门写个线程调度,由它来调度进程内部的其他线程。但是这种方式内核感知不到进程中的线程。如果进程休眠了,那么该进程里面其他线程都无法被调度。但是内核级线程则不会有这种情况
可重入函数
一个函数被重入表示这个函数没有执行完成,又一次进入了该函数执行。
函数可重入必须有以下几个特点:
1、不使用进程或者全局的非const变量
2、不返回任何静态或者全局的非const变量指针
3、仅依赖调用方提供的参数
4、不依赖任何单个资源锁(mutex等)
5、不调用任何不可重入函数
关于EXPORT_SYMBOL
当模块被载入以后,会被动态的连接到内核里面。该模块内的函数接口,只有被显示的导出之后,才能被外部函数使用。
有些时候,我们从A.ko导出一个符号,让B.ko使用。但是B.ko里面还是无法使用。之前以为是B.ko是加载到A.ko之前。所以B.ko在使用的时候无法使用。其实应该是编译的时候,不应该是加载
如果代码被配置为模块,那么需要保证当该模块被编译时,所有需要的接口都全部被导出,导出,否则就会产生链接错误,无法找到符号,模块编译失败。
还有就是不知道为什么A/B两个模块,无论从哪个方向导出符号。他们都无法访问。按理说AB两个模块肯定是有先后顺序的啊。不知道是为什么导出了还是访问不了。
最后还是通过挂接钩子函数去实现的。大概就是在A和B都能访问的地方,把A需要导出的接口,赋值为B的一个全局变量??
关闭中断进行进程切换
raw_local_irq_disable() //关闭本地中断
schedule() //调用schedule()函数来切换进程
raw_local_irq_enable() //打开本地中断有读者这么认为,假设进程A在关闭本地中断的情况下切换到进程B来运行,进程B会在关闭中断的情况下运行,如果进程B一直占用CPU,那么系统会一直没有办法响应时钟中断,系统就处于瘫痪状态。
显然,上述分析是不正确的。因为进程B切换执行时会打开本地中断,以防止系统瘫痪
显然,上述分析是不正确的。因为进程B切换执行时会打开本地中断,以防止系统瘫痪
感觉说进程B在切换的时候会打开本地中断的原因是schedule里面会调用raw_spin_lock_irq和raw_spin_unlock_irq等打开或者关闭本CPU中断的操作,主要最后将本cpu中断打开了就行
可以看到raw_spin_unlock_irq里面其实也调用了local_irq_enable
static inline void __raw_spin_unlock_irq(raw_spinlock_t *lock)
{
spin_release(&lock->dep_map, 1, _RET_IP_);
do_raw_spin_unlock(lock);
local_irq_enable();
preempt_enable();
}可以看到本CPU中断关闭和开启都是操作寄存器。因此即使你调用local_irq_disable两次,在调用local_irq_enable 1次。本cpu的中断还是本打开了。这个不用保证对称性
static inline void arch_local_irq_enable(void)
{
asm volatile(
" cpsie i @ arch_local_irq_enable"
:
:
: "memory", "cc");
}
static inline void arch_local_irq_disable(void)
{
asm volatile(
" cpsid i @ arch_local_irq_disable"
:
:
: "memory", "cc");
}
另外local_irq_disable从实现上看它就是屏蔽了本cpu的中断,那么感觉也是能够屏蔽时钟中断的。除非硬件设计将时钟中断接到了不可屏蔽中断的引脚给了时钟中断。那么我们将本cpu中断屏蔽了,那是不是该cpu就不会产生时钟中断,也就不会进行进程切换了啊(不清楚进程切换是不是只依赖于时钟中断)。
刷新cache
https://www.codenong.com/cs107064291/
cpu<-->cache<-->内存<-->硬件设备(dma)
cpu往一个地址里面写东西,如果cache hit,则会先写到cache里面。当该地址在cache里面失效时,才会被写入到内存里面(好像也不对,这个和更新策略有关系)。因此在该地址失效之前,cache和内存里面的数据是不一致的。同样cpu读取数据时,如果cache里面有对应的数据,那么cpu也不会从内存里面读取数据。
dma设备去读取数据,只能去内存里面读取。因此当dma设备在读取之前,应该刷新cache,让cache里面的数据更新到内存中。同样,当dma设备将数据拷贝到内存中后,cpu去读取这些数据时,应该让cache无效,这样cpu读取的时候就不会缓存命中,从而到内存中去读取数据。
关于函数栈
void f(void)
{
int a = 0;
int b = 0;
int c = 0;
printf("a %p, b %p, c %p\n", &a, &b, &c);
return;
}
int main()
{
unsigned int carry = 0xffffffff;
printf("carry %p\n", &carry);
f();
return 0;
}在不同的机器上输出:
从这个输出可以看到,1、同一个函数内的局部变量的地址是按照定义的先后顺序递减的;2、主调函数的函数栈地址是高于被调函数的。且两者相差了0x20,中间应该是存放了什么寄存器以及函数返回地址这些,待验证
这个结果是未开启栈保护的
![]()
这个则是根据定义的先后顺序地址,但是调用函数之前的关系不变,主调函数的栈高于被调函数,且相差0x30(这个结果是开启栈保护)
![]()
局部变量入栈顺序与输出关系_AaronLiuwq的博客-CSDN博客_局部变量入栈顺序
该文章说局部变量入栈顺序和是否开启栈保护有关。试了一下,确实是这样。
在未开启栈保护时,按照局部变量的先后顺序入栈。如下图:
gcc test.c -o test -fno-stack-protector
这个结果和上面的刚好相反,看来虚拟机上的gcc默认开启了栈保护
unsigned int a = 0x11223344;
unsigned int b = 0x12345678;
unsigned int c = 0x55667788;
char str[4] = {'0'};
printf("a %p, b %p, c %p, str %p\n", &a, &b, &c, str);
a 0xbfb1b8a4, b 0xbfb1b8a0, c 0xbfb1b89c, str 0xbfb1b898
假设未开启栈保护,那么对于函数f的局部变量在栈中布局为:
#include <stdio.h>
#include <stdlib.h>
void f(void)
{
unsigned int a = 0x11223344;
unsigned int b = 0x12345678;
unsigned int c = 0x55667788;
char str[4] = {0,0,0,0};
printf("a %p, b %p, c %p, str %p\n", &a, &b, &c, str);
char *p = &b;
int i = 0;
printf("add:\n");
for (i = 0; i < 8; ++i)
{
printf("%02x, ", *p);
++p;
}
printf("\ndec:\n");
p = &b;
for (i = 0; i < 5; ++i)
{
printf("%02x, ", *p);
--p;
}
printf("\n");
str[4] = 0x99;
printf("add:\n");
p = &b;
for (i = 0; i < 8; ++i)
{
printf("%02x, ", *p);
++p;
}
printf("\ndec:\n");
p = &b;
for (i = 0; i < 5; ++i)
{
printf("%02x, ", *p);
--p;
}
printf("\n");
printf("str[0] addr is %p\n", &str[0]);
return;
}
int main()
{
unsigned int carry = 0xf1f2f3f4;
printf("carry %p\n", &carry);
f();
return 0;
}上述代码输出如下(我这个环境应该是小端字节序)
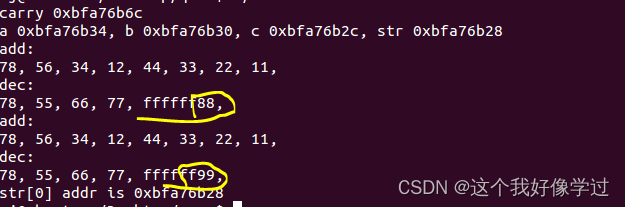

从上图中可以看到.1、栈空间是向下生长的。 被掉函数的栈空间也是在主调函数的栈空间下方。2、在代码中我修改了str[4]=0x99,结果修改到了局部变量c的值,将0x88修改为了0x99(但是不明白为什么打印出来的值是0xffffff88和0xffffff99)。栈被踩坏应该就是说的这种情形,如果str继续往上写,可能就能把保存的信息给写坏
local_irq_enable/local_irq_disable开关中断
cpsie只是修改了寄存器CPSR中的值。因此,关/开中断只是操作了CPSR中的中断标志位而已,并没有去对GIC做操作,即GIC还是会向CPU上报中断,只是简单的不让CPU响应中断。
#define local_irq_enable() \
do { trace_hardirqs_on(); raw_local_irq_enable(); } while (0)
#define raw_local_irq_enable() arch_local_irq_enable()
static inline void arch_local_irq_enable(void)
{
asm volatile(
" cpsie i @ arch_local_irq_enable"
:
:
: "memory", "cc");
}
但是很奇怪的是local_irq_disable和local_irq_enable之前并不是处于原子上下文,可以睡眠或者直接调用schedule。这是为什么啊?这个是硬中断到来时,屏蔽中断,不能休眠有什么区别啊?

只有local_bh_disable/local_bh_enable感觉才是原子上下文呢?
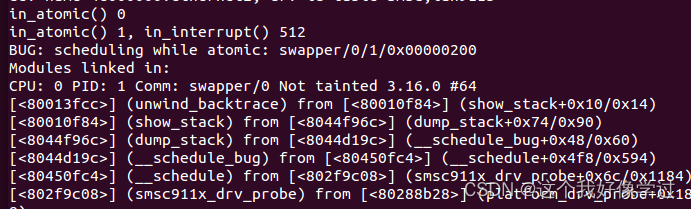
不过仅看in_atomic实现,确实是输出为0。因此local_irq_disable并未修改preempt_count的值。
此外,对于in_atomic()来说,在启用抢占的情况下,它工作的很好,可以告诉内核目前是否持有自旋锁,是否禁用抢占等。但是,在没有启用抢占的情况下,spin_lock根本不修改preempt_count,所以即使内核调用了spin_lock,持有了自旋锁,in_atomic()仍然会返回0,错误的告诉内核目前在非原子上下文中。所以凡是依赖in_atomic()来判断是否在原子上下文的代码,在禁抢占的情况下都是有问题的。
#define in_atomic() ((preempt_count() & ~PREEMPT_ACTIVE) != 0)对了,我自己测试的内核是不支持抢占的。今天去另外的环境测试了一下自旋锁。我自己的环境在自旋锁的临界区里面可以调度。另外的环境就不可以。不知道是不是和preempt_count有关。
感觉local_irq_disable就是没有修改preempt_count的值,而local_bh_disable则是修改了preempt_count,使得其值不为0。导致出现错误
local_bh_disable/local_bh_enable是内核提供的关闭软中断的锁机制。在两者保护的临界区中,禁止本地CPU在中断返回前夕执行软中断
这个两个函数运行在进程上下文(不知道为什么这样说???)
void local_bh_disable(void)
{
__local_bh_disable(_RET_IP_, SOFTIRQ_DISABLE_OFFSET);
}把当前进程的preempt_count成员加上SOFTIRQ_DISABLE_OFFSET。preempt_count的8-15bit用于表示软zh
static inline void __local_bh_disable(unsigned long ip, unsigned int cnt)
{
preempt_count_add(cnt);
barrier();
}下图来自于Linux中的preempt_count - 知乎
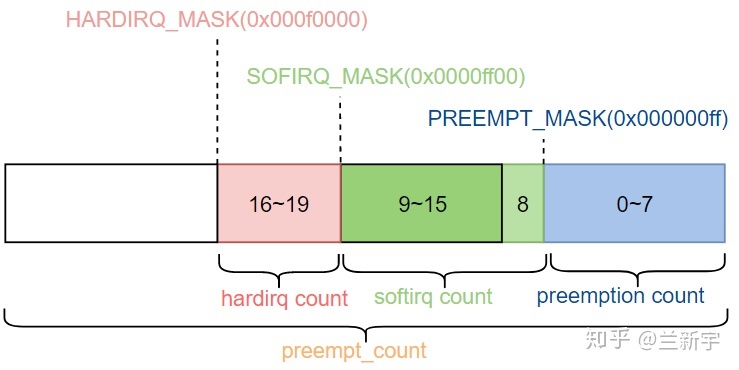
#define PREEMPT_MASK (__IRQ_MASK(PREEMPT_BITS) << PREEMPT_SHIFT)//0x000000ff
#define SOFTIRQ_MASK (__IRQ_MASK(SOFTIRQ_BITS) << SOFTIRQ_SHIFT)//0x0000ff00
#define HARDIRQ_MASK (__IRQ_MASK(HARDIRQ_BITS) << HARDIRQ_SHIFT)//0x000f0000
#define NMI_MASK (__IRQ_MASK(NMI_BITS) << NMI_SHIFT)
#define PREEMPT_OFFSET (1UL << PREEMPT_SHIFT)
#define SOFTIRQ_OFFSET (1UL << SOFTIRQ_SHIFT)
#define HARDIRQ_OFFSET (1UL << HARDIRQ_SHIFT)
#define NMI_OFFSET (1UL << NMI_SHIFT)
#define SOFTIRQ_DISABLE_OFFSET (2 * SOFTIRQ_OFFSET)//0x200SOFTIRQ_DISABLE_OFFSET=0x200,刚刚是将softirq域的第2个bit置1
那为什么local_bh_disable能够在硬中断返回时,禁止软中断的执行呢?
void irq_exit(void)
{
.......................................
/* 不在硬件中断上下文、软中断上下文 同时有软中断待处理 */
/*
因此如果在执行软中断的过程中,被硬件中断打断,然后返回时,
会回到软中断上下文。这些不满足上述条件.不会重新调度新的软中断,
即不会执行invoke_softirq
因此软中断在一个CPU上总是串行执行的
*/
if (!in_interrupt() && local_softirq_pending())
invoke_softirq();
...............................
}硬中断返回, 要软中断执行需要满足:1、有软中断待处理;2不在硬中断上下文或者软中断上下文
#define in_interrupt() (irq_count())
#define irq_count() (preempt_count() & (HARDIRQ_MASK | SOFTIRQ_MASK \
| NMI_MASK))可以看到in_interrupt其实也是去判断preempt_count的值。如果执行了 local_bh_disable,那么SOFTIRQ_MASK域中的值肯定不为0。因此in_interrupt()返回非0值(处于软中断上下文)。则不能执行invoke_softirq,去处理软中断。
void local_bh_enable(void)
{
_local_bh_enable_ip(_RET_IP_);
}_local_bh_enable_ip中为什么先是将preempt_count保留1(关闭抢占),待软中断执行完成之后,在完全减去(开启抢占)
举例:假设进程P运行在CPU0上,在执行判断 if (unlikely(!in_interrupt() && local_softirq_pending()))时发生了中断,且中断返回时被高优先级的任务抢占。如果进程P再次被调度时可能会被换到其他CPU1上。由于"软中断状态寄存器"__softirq_pending是Per-CPU变量。CPU1再去执行该判断时,发现__softirq_pending并没有待处理的软中断。因此之前的软中断会被延迟执行。(软中断不会被丢失,因为CPU0的软中断状态寄存器记录了需要处理的软中断。只有等到CPU0上触发软中断时,才会处理之前进程P"应该"处理的软中断)
static inline void _local_bh_enable_ip(unsigned long ip)
{
WARN_ON_ONCE(in_irq() || irqs_disabled());
#ifdef CONFIG_TRACE_IRQFLAGS
local_irq_disable();
#endif
/*
* Are softirqs going to be turned on now:
*/
if (softirq_count() == SOFTIRQ_DISABLE_OFFSET)
trace_softirqs_on(ip);
/*
* Keep preemption disabled until we are done with
* softirq processing:
*/
/*
这里将preempt_count的值留了1,是为了关闭本地CPU抢占
书上说是为了调用do_softirq时不希望被其他高优先任务抢占
或者是当前任务被迁移到其他CPU上
*/
preempt_count_sub(SOFTIRQ_DISABLE_OFFSET - 1);
if (unlikely(!in_interrupt() && local_softirq_pending())) {
/*
* Run softirq if any pending. And do it in its own stack
* as we may be calling this deep in a task call stack already.
*/
do_softirq();
}
/* 执行完了,才完全将开启抢占功能 */
preempt_count_dec();
#ifdef CONFIG_TRACE_IRQFLAGS
local_irq_enable();
#endif
preempt_check_resched();
}进程上下文和中断上下文
进程上下文:进程在进入内核空间之前,进程会传递一些传输,堆栈内存,以及寄存器的值给内核。需要保存进入内核态之前的运行环境,这些运行环境就是所谓的进程上下文。有了进程上下文信息,才能在该进程被再次调度的时候,恢复之前运行的环境。
中断上下文:硬件通过触发中断,使得内核去调用相应的中断处理程序,在这个过程中,硬件也会传递一些参数给内核。(那当前正在执行的进程的环境,也需要被保存啊。按照这个理解,它不是还包含了进程上下文啊,我看网上说确实会先保存当前进程的上下文)
为什么中断上下文不能访问用户空间?
参考回答:中断上下文为何不可访问用户空间地址_百度知道(我也没有去看发生中断时会去保存哪些信息,后面再去看看,按照这个答案我感觉是并没有保存被打断进程的相关信息?????当时上面不是说发生中断时会先去保存当前进程的上下文吗?)
至于说中断上下文不能访问用户空间地址,并不是因为权限不够(考虑到IDT中中断描述符项中的segment selector的RPL),而是因为中断上下文并不是一个完整的进程空间,所以就虚拟地址空间而言,中断上下文不具备完整的虚拟地址空间的页表项,所以理所当然地,不具有用户空间的虚拟地址页表目录。
但是从理论上讲,让中断上下文环境中做到访问用户空间是完全可行的。在中断发生时,将被中断进程的CR3加入到为中断上下文创立的堆栈中,这样中断上下文将具备完整的进程上下文中完备的虚拟地址空间页表。
后面的数字:代表该线程被绑定到了哪个核上面















 308
308











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









