






内核采用区块zone的方式管理内存。
通常情况下内核的zone分为ZONE_DMA,ZONE_DMA32,ZONE_NORMAL,ZONE_HIGHMEM
vexpress,linux3.16上面我验了一下,其实就只有zone_type:ZONE_NORMAL,ZONE_MOVABLE
因此__MAX_NR_ZONES=2
enum zone_type {
#ifdef CONFIG_ZONE_DMA
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
ZONE_DMA32,
#endif
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,
__MAX_NR_ZONES
};zone初始化函数在bootmem_init中完成,因此需要确定每个zone的范围。在find_limits函数中会计算出min_low_pfn,max_low_pfn和max_pfn3个值。
同样也是通过memblock子系统(这个时候是通过memblock管理内存)获得起始地址、结束地址的page number
static void __init find_limits(unsigned long *min, unsigned long *max_low,
unsigned long *max_high)
{
*max_low = PFN_DOWN(memblock_get_current_limit());
*min = PFN_UP(memblock_start_of_DRAM());
*max_high = PFN_DOWN(memblock_end_of_DRAM());
}
phys_addr_t __init_memblock memblock_get_current_limit(void)
{
return memblock.current_limit;
}其中min_low_pfn是内存块的开始地址页帧号(0x60000000/0x1000,即物理内存起始地址为0x60000000,4k为1页,则对应的物理页帧号为0x60000);
max_low_pfn表示ZONE_NORMAL区域的结束页帧号(我这里是0xa0000),书上说这个值是根据arm_lowmem_limit而来的。那ZONE_NORMAL是对应了低端内存嘛?
;max_pfn是内存块的的结束地址页帧号(0xa0000)
(min_low_pfn,max_low_pfn)这个范围的物理内存是zone_normal(属于低端内存,低端内存包含了zone_dma和zone_normal)
(max_low_pfn,max_pfn)是属于高端内存,zone_highmem。只不过在本例中高端内存的长度为0

min_low_pfn = min;//系统中可用的最小页帧号
max_low_pfn = max_low;//低端内存标识的最大页帧号
max_pfn = max_high;//系统中可以的最大页帧号paging_init-->bootmem_init
在setup_arch中通过paging_init函数初始化内核分页机制之后, 内核通过bootmem_init()开始完成内存结点和内存区域的初始化工作
void __init bootmem_init(void)
{
unsigned long min, max_low, max_high;
memblock_allow_resize();
max_low = max_high = 0;
/* 通过memblock拿到limit,DRAM的起始地址的页面号 */
find_limits(&min, &max_low, &max_high);
printk(KERN_EMERG "\r\nmin %lx, max_low %lx, max_high %lx\n", \
min, max_low, max_high);
arm_memory_present();
sparse_init();
/* zone_sizes_init()来初始化节点和管理区的一些数据项 */
zone_sizes_init(min, max_low, max_high);
min_low_pfn = min;//系统中可用的最小页帧号
max_low_pfn = max_low;//低端内存标识的最大页帧号
max_pfn = max_high;//系统中可以的最大页帧号
}低端内存,高端内存和zone_type的关系
低端内存包含了zone_dma和zone_normal;高端内存则对应zone_highmem。参考链接https://www.jianshu.com/p/f964da9036a0
- ZONE_DMA:范围是0 ~ 16M,该区域的物理页面专门供I/O设备的DMA使用。之所以需要单独管理DMA的物理页面,是因为DMA使用物理地址访问内存,不经过MMU,并且需要连续的缓冲区,所以为了能够提供物理上连续的缓冲区,必须从物理地址空间专门划分一段区域用于DMA。
- ZONE_NORMAL:范围是16M ~ 896M,该区域的物理页面是内核能够直接使用的。这部分的物理内存是启动的时候经过线性映射,映射完成的
- ZONE_HIGHMEM:范围是896M ~ 结束,该区域即为高端内存,内核不能直接使用。在使用的时候进行动态映射。
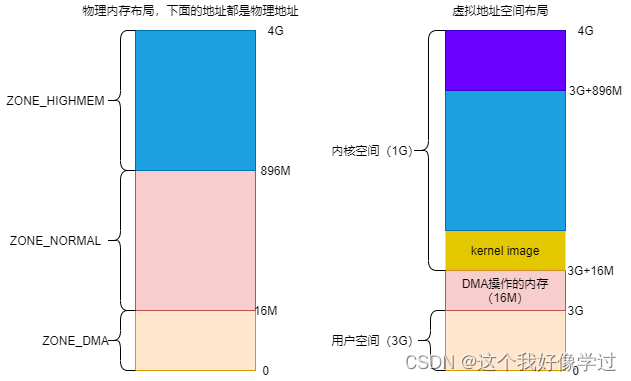
由于我这边版本只包含了ZONE_NORMAL,ZONE_MOVABLE。因此上图的DMA和zone_higmem是没有的。
ZONE_NORMAL在虚拟地址空间的范围是从0x80000000-0xc0000000
PAGE_OFFSET:0X80000000(内核虚拟地址空间起始地址??)
PHY_OFFSET:0x60000000(未进行验证。是因为物理内存起始地址不是从0开始嘛?)
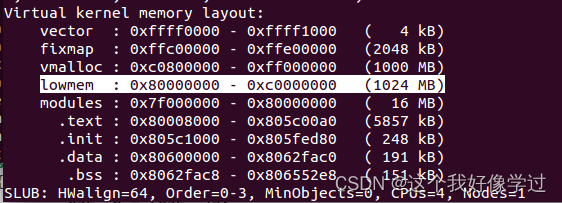
由于未定义 CONFIG_ZONE_DMA,CONFIG_ZONE_DMA32等。最后函数zone_sizes_init简化如下:
paging_init-->bootmem_init-->zone_sizes_init
传入参数min=0x60000,max_low=0xa0000, max_high=0xa0000
static void __init zone_sizes_init(unsigned long min, unsigned long max_low,
unsigned long max_high)
{
unsigned long zone_size[MAX_NR_ZONES], zhole_size[MAX_NR_ZONES];
struct memblock_region *reg;
printk(KERN_EMERG "\r\n MAX_NR_ZONES is %u\n", MAX_NR_ZONES);
memset(zone_size, 0, sizeof(zone_size));
/*
看来zone_size是保存各个zone的page数量
从传入参数看zone_size[0] = 0xa0000 - 0x60000 = 0x40000
*/
zone_size[0] = max_low - min;
memcpy(zhole_size, zone_size, sizeof(zhole_size));
for_each_memblock(memory, reg) {
unsigned long start = memblock_region_memory_base_pfn(reg);
unsigned long end = memblock_region_memory_end_pfn(reg);
printk(KERN_EMERG "\r\n %s: start is %lx, end is %lx\n", \
__FUNCTION__, start, end);
if (start < max_low) {
unsigned long low_end = min(end, max_low);
/* 从这里可以看到起始zhole_size[0] = 0 */
zhole_size[0] -= low_end - start;
}
}
/*
用来针对特定的节点进行初始化
0:UMA是有一个节点
min:zone_normal的起始页帧号pfn
*/
free_area_init_node(0, zone_size, min, zhole_size);
}可以看到MAX_NR_ZONES其实就对应了__MAX_NR_ZONES(应该是哪里赋值了)

那么对于数组zone_size[MAX_NR_ZONES], zone_size[0]就对应了zone_normal.
memblock子系统里面的动态内存只有一个,即dts内的memory节点,因此只循环一次。该节点的起始页帧号为0x60000,结束页帧号为0xa0000.
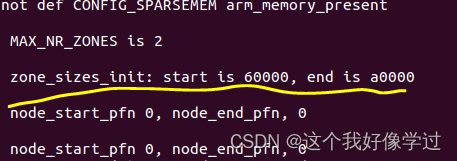
free_area_init_node传入参数nid = 0(因为对于UMA只存在一个节点) zones_size[2] = {0x40000,0}
node_start_pfn = 0x60000, zholes_size[2] = {0,0}
void __paginginit free_area_init_node(int nid, unsigned long *zones_size,
unsigned long node_start_pfn, unsigned long *zholes_size)
{
/*
对于NUMA系统包含了多个节点。对同一节点内存的访问,时间是相同的
不同节点的内存访问,则所需时间是不同的
对于UMA系统,也会存在一个节点,其node id = 0
其中节点使用pg_data_t
*/
pg_data_t *pgdat = NODE_DATA(nid);
unsigned long start_pfn = 0;
unsigned long end_pfn = 0;
/* pg_data_t should be reset to zero when it's allocated */
WARN_ON(pgdat->nr_zones || pgdat->classzone_idx);
pgdat->node_id = nid;
/* 初始化时node_start_pfn=0x60000 */
pgdat->node_start_pfn = node_start_pfn;
/* 对节点长度和可用page数进行初始化 */
calculate_node_totalpages(pgdat, start_pfn, end_pfn,
zones_size, zholes_size);
alloc_node_mem_map(pgdat);
#ifdef CONFIG_FLAT_NODE_MEM_MAP
printk(KERN_DEBUG "free_area_init_node: node %d, pgdat %08lx, node_mem_map %08lx\n",
nid, (unsigned long)pgdat,
(unsigned long)pgdat->node_mem_map);
#endif
/* 真正初始化zone,填充节点pgdat的Zone */
free_area_init_core(pgdat, start_pfn, end_pfn,
zones_size, zholes_size);
}计算每一个zone的总页数和实际页数(不包含空洞),以及内存节点的总页数和实际页数(不包含空洞),因此每个节点都是有各自的Zone
/* 用来计算每一个zone的总页数和实际页数(不包含空洞),以及内存节点的总页数和实际页数(不包含空洞) */
static void __meminit calculate_node_totalpages(struct pglist_data *pgdat,
unsigned long node_start_pfn,
unsigned long node_end_pfn,
unsigned long *zones_size,
unsigned long *zholes_size)
{
unsigned long realtotalpages, totalpages = 0;
enum zone_type i;
for (i = 0; i < MAX_NR_ZONES; i++)
{
totalpages += zone_spanned_pages_in_node(pgdat->node_id, i,
node_start_pfn,
node_end_pfn,
zones_size);
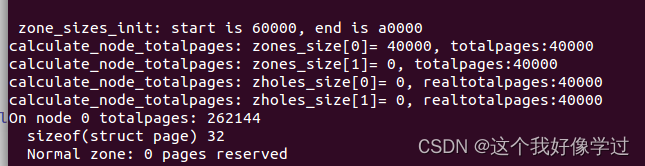
printk(KERN_EMERG "calculate_node_totalpages: zones_size[%u]= %lx, totalpages:%lx \n", i,zones_size[i], totalpages);
}
/* 网上说这个是node里面不连续的page数量 */
pgdat->node_spanned_pages = totalpages;
realtotalpages = totalpages;
for (i = 0; i < MAX_NR_ZONES; i++)
{
realtotalpages -=
zone_absent_pages_in_node(pgdat->node_id, i,
node_start_pfn, node_end_pfn,
zholes_size);
printk(KERN_EMERG "calculate_node_totalpages: zholes_size[%u]= %lx, realtotalpages:%lx \n", i,zholes_size[i], realtotalpages);
}
/* 这个是真实可用的page数量 */
pgdat->node_present_pages = realtotalpages;
printk(KERN_EMERG "On node %d totalpages: %lu\n", pgdat->node_id,
realtotalpages);
}
可以看到该节点没有空洞区域,总共包含了0x40000=262144个page。
在linux内核中,所有的物理内存都用struct page结构来描述,这些对象以数组形式存放,而这个数组的地址就是mem_map。内核以节点node为单位,每个node下的物理内存统一管理,也就是说在表示内存node的描述类型struct pglist_data中,有node_mem_map这个成员,其针对平坦型内存进行描述(CONFIG_FLAT_NODE_MEM_MAP)。如果系统只有一个pglist_data对象,那么此对象下的node_mem_map即为全局对象mem_map。(详见alloc_node_mem_map)
我理解的是mem_map包含了所有的物理内存,自然每个node所包含的内存也在里面。因此每个node的成员node_mem_map指向了数组的一部分(我以为直接是数组下标或者对应下标的地址之类的)。但是看函数实现,感觉不是这样的。。。但是我也不知道怎么和全局变量mem_map联系上去的。。。
另外这个node_mem_map是如何和4k的物理内存建立关系的内?明天继续看看
还是说这根本就是两个不同的东西管理内存的不同方式啊?内核有一个全局变量struct page * mem_map管理所有的物理内存。而node有一个struct page* node_mem_map管理该node对应的物理内存。
alloc_node_mem_map只是把管理page的数组分配了出来,但是还没有为他们建立对应的映射关系
static void __init_refok alloc_node_mem_map(struct pglist_data *pgdat)
{
/* Skip empty nodes */
if (!pgdat->node_spanned_pages)
return;
#ifdef CONFIG_FLAT_NODE_MEM_MAP
/* ia64 gets its own node_mem_map, before this, without bootmem */
if (!pgdat->node_mem_map) {
unsigned long size, start, end;
struct page *map;
/*
* The zone's endpoints aren't required to be MAX_ORDER
* aligned but the node_mem_map endpoints must be in order
* for the buddy allocator to function correctly.
*/
/* 向下取整 MAX_ORDER_NR_PAGES 打印出来是1024*/
printk(KERN_EMERG "MAX_ORDER_NR_PAGES %lu, ", MAX_ORDER_NR_PAGES);
start = pgdat->node_start_pfn & ~(MAX_ORDER_NR_PAGES - 1);
end = pgdat_end_pfn(pgdat);
end = ALIGN(end, MAX_ORDER_NR_PAGES);
/* 数组map是用来存放struct page的结构,数组大小就是page个数*page结构体大小 */
size = (end - start) * sizeof(struct page);
map = alloc_remap(pgdat->node_id, size);
if (!map)
map = memblock_virt_alloc_node_nopanic(size,
pgdat->node_id);
/* 对齐之后可能map最开始的部分可能是无效的 */
pgdat->node_mem_map = map + (pgdat->node_start_pfn - start);
}
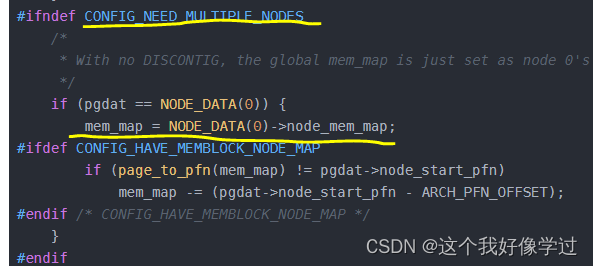
#ifndef CONFIG_NEED_MULTIPLE_NODES
/*
* With no DISCONTIG, the global mem_map is just set as node 0's
*/
if (pgdat == NODE_DATA(0)) {
mem_map = NODE_DATA(0)->node_mem_map;
#ifdef CONFIG_HAVE_MEMBLOCK_NODE_MAP
if (page_to_pfn(mem_map) != pgdat->node_start_pfn)
mem_map -= (pgdat->node_start_pfn - ARCH_PFN_OFFSET);
#endif /* CONFIG_HAVE_MEMBLOCK_NODE_MAP */
}
#endif
#endif /* CONFIG_FLAT_NODE_MEM_MAP */
}感觉是当前节点在对齐之后,包含了size个page,因此需要分配size*sizeof(struct page)的内存来管理这么多的page。

当前环境是UMA,没有CONFIG_NEED_MULTIPLE_NODES,只有一个node 0。可以看到对应UMA,全局变量mem_map就是node 0的node_mem_map。原来这句话(如果系统只有一个pglist_data对象,那么此对象下的node_mem_map即为全局对象mem_map。)是这个意思。
free_area_init_core:对当前节点的node(pgdat->node_zones + j)遍历各个zone进行初始化:
1、计算zone的总共的page数量size, realsize,管理该zone所有page,所需要的struct page的page数memmap_pages,空闲page数freesize
freesize = 总的page数-memmap_pages-dma_reserve区域
2、初始化zone的其他变量和锁等等
static void __paginginit free_area_init_core(struct pglist_data *pgdat,
unsigned long node_start_pfn, unsigned long node_end_pfn,
unsigned long *zones_size, unsigned long *zholes_size)
{
enum zone_type j;
int nid = pgdat->node_id;
unsigned long zone_start_pfn = pgdat->node_start_pfn;
int ret;
pgdat_resize_init(pgdat);
#ifdef CONFIG_NUMA_BALANCING
spin_lock_init(&pgdat->numabalancing_migrate_lock);
pgdat->numabalancing_migrate_nr_pages = 0;
pgdat->numabalancing_migrate_next_window = jiffies;
#endif
init_waitqueue_head(&pgdat->kswapd_wait);
init_waitqueue_head(&pgdat->pfmemalloc_wait);
pgdat_page_cgroup_init(pgdat);
for (j = 0; j < MAX_NR_ZONES; j++) {
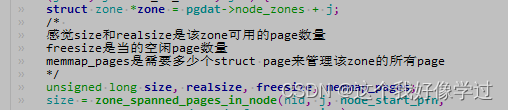
struct zone *zone = pgdat->node_zones + j;
/*
感觉size和realsize是该zone可用的page数量
freesize是当的空闲page数量
memmap_pages是需要多少个struct page来管理该zone的所有page
*/
unsigned long size, realsize, freesize, memmap_pages;
size = zone_spanned_pages_in_node(nid, j, node_start_pfn,
node_end_pfn, zones_size);
realsize = freesize = size - zone_absent_pages_in_node(nid, j,
node_start_pfn,
node_end_pfn,
zholes_size);
/*
* Adjust freesize so that it accounts for how much memory
* is used by this zone for memmap. This affects the watermark
* and per-cpu initialisations
*/
memmap_pages = calc_memmap_size(size, realsize);
if (freesize >= memmap_pages) {
freesize -= memmap_pages;
if (memmap_pages)
printk(KERN_DEBUG
" %s zone: %lu pages used for memmap\n",
zone_names[j], memmap_pages);
} else
printk(KERN_WARNING
" %s zone: %lu pages exceeds freesize %lu\n",
zone_names[j], memmap_pages, freesize);
/* Account for reserved pages */
if (j == 0 && freesize > dma_reserve) {
freesize -= dma_reserve;
printk(KERN_EMERG " %s zone: %lu pages reserved\n",
zone_names[0], dma_reserve);
}
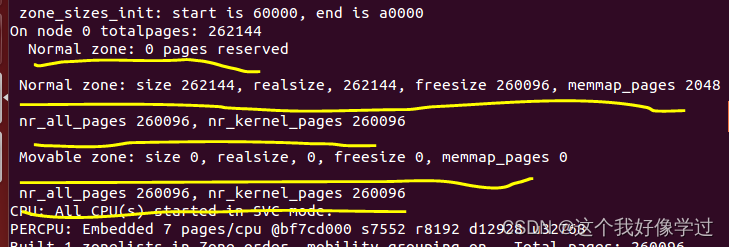
printk(KERN_EMERG "\r\n %s zone: size %lu, realsize, %lu, freesize %lu, memmap_pages %lu\n", \
zone_names[j], size, realsize, freesize, memmap_pages);
if (!is_highmem_idx(j))
nr_kernel_pages += freesize;
/* Charge for highmem memmap if there are enough kernel pages */
else if (nr_kernel_pages > memmap_pages * 2)
nr_kernel_pages -= memmap_pages;
nr_all_pages += freesize;
printk(KERN_EMERG "\r\n nr_all_pages %lu, nr_kernel_pages %lu\n", \
nr_all_pages, nr_kernel_pages);
zone->spanned_pages = size;
zone->present_pages = realsize;
/*
* Set an approximate value for lowmem here, it will be adjusted
* when the bootmem allocator frees pages into the buddy system.
* And all highmem pages will be managed by the buddy system.
*/
zone->managed_pages = is_highmem_idx(j) ? realsize : freesize;
#ifdef CONFIG_NUMA
zone->node = nid;
zone->min_unmapped_pages = (freesize*sysctl_min_unmapped_ratio)
/ 100;
zone->min_slab_pages = (freesize * sysctl_min_slab_ratio) / 100;
#endif
zone->name = zone_names[j];
spin_lock_init(&zone->lock);
spin_lock_init(&zone->lru_lock);
zone_seqlock_init(zone);
zone->zone_pgdat = pgdat;
zone_pcp_init(zone);
/* For bootup, initialized properly in watermark setup */
mod_zone_page_state(zone, NR_ALLOC_BATCH, zone->managed_pages);
lruvec_init(&zone->lruvec);
if (!size)
continue;
set_pageblock_order();
setup_usemap(pgdat, zone, zone_start_pfn, size);
ret = init_currently_empty_zone(zone, zone_start_pfn,
size, MEMMAP_EARLY);
BUG_ON(ret);
memmap_init(size, nid, j, zone_start_pfn);
zone_start_pfn += size;
}
}和之前一样,node里面包含了两个区域分布是zone_normal,zone_movable
对于zone_normal总共包含了262144个page(262144*4096=1G,dts里面也是1G),1G的物理内存需要2048个page来管理。
在当前环境中sizeof(struct page) = 32,总共有262144个page, 那么也需要262144个struct page来管理这么多物理页。因此所需要的字节数是262144 * 32 = 8388608 = 2048个物理页(2048*4096)
setup_usemap:计算和分配pageblock_flags所需大小
static void __init setup_usemap(struct pglist_data *pgdat,
struct zone *zone,
unsigned long zone_start_pfn,
unsigned long zonesize)
{
printk(KERN_EMERG "func %s, line %d: start_pfn %lx, zonesize %lx\n", __FUNCTION__, __LINE__,
zone_start_pfn, zonesize);
unsigned long usemapsize = usemap_size(zone_start_pfn, zonesize);
printk(KERN_EMERG "func %s, line %d: usemapsize %lx\n", __FUNCTION__, __LINE__,
usemapsize);
zone->pageblock_flags = NULL;
if (usemapsize)
zone->pageblock_flags =
memblock_virt_alloc_node_nopanic(usemapsize,
pgdat->node_id);
}
zone_start_pfn=0x60000,zone_size=0x40000
static unsigned long __init usemap_size(unsigned long zone_start_pfn, unsigned long zonesize)
{
unsigned long usemapsize;
printk(KERN_EMERG "func %s, line %d: pageblock_nr_pages %lu, pageblock_order %lu, NR_PAGEBLOCK_BITS %lu\n",\
__FUNCTION__, __LINE__,pageblock_nr_pages, pageblock_order, NR_PAGEBLOCK_BITS);
zonesize += zone_start_pfn & (pageblock_nr_pages-1);
usemapsize = roundup(zonesize, pageblock_nr_pages);
usemapsize = usemapsize >> pageblock_order;
usemapsize *= NR_PAGEBLOCK_BITS;
usemapsize = roundup(usemapsize, 8 * sizeof(unsigned long));
return usemapsize / 8;
}

因此pageblock_flags所需大小为0x80=128字节。当前环境里面没有高端内存,全部都是低端内存,总共1024M。128字节=128*8bit。一个pageblock用4bit表示,一个pageblock大小4M(pageblock_nr_pages= 1024 * 4K = 4M)。那么总共有128*8/4=256个pageblock。256个pageblock所表示的内存为256*4=1024M
free_area_init_core->memmap_init->memmap_init_zone
void __meminit memmap_init_zone(unsigned long size, int nid, unsigned long zone,
unsigned long start_pfn, enum memmap_context context)
{
struct page *page;
unsigned long end_pfn = start_pfn + size;
unsigned long pfn;
struct zone *z;
if (highest_memmap_pfn < end_pfn - 1)
highest_memmap_pfn = end_pfn - 1;
z = &NODE_DATA(nid)->node_zones[zone];
for (pfn = start_pfn; pfn < end_pfn; pfn++) {
if (context == MEMMAP_EARLY) {
if (!early_pfn_valid(pfn))
continue;
if (!early_pfn_in_nid(pfn, nid))
continue;
}
page = pfn_to_page(pfn);
set_page_links(page, zone, nid, pfn);
mminit_verify_page_links(page, zone, nid, pfn);
init_page_count(page);
page_mapcount_reset(page);
page_cpupid_reset_last(page);
SetPageReserved(page);
if ((z->zone_start_pfn <= pfn)
&& (pfn < zone_end_pfn(z))
&& !(pfn & (pageblock_nr_pages - 1)))
set_pageblock_migratetype(page, MIGRATE_MOVABLE);
INIT_LIST_HEAD(&page->lru);
#ifdef WANT_PAGE_VIRTUAL
/* The shift won't overflow because ZONE_NORMAL is below 4G. */
if (!is_highmem_idx(zone))
set_page_address(page, __va(pfn << PAGE_SHIFT));
#endif
}
}
目前上述的过程,可以看到在该过程中free_area链表都被初始化空,里面并没有page被加入到链表中。
page被加入到free_area的过程可以参考伙伴系统杂记_这个我好像学过的博客-CSDN博客















 356
356











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









