






进程地址空间
进程所有的地址空间使用mm_struct进行管理,它描述了进程地址空间的所有信息。每个进程地址空间包含了许多使用中的页面对齐的内存区域。它们不会相互重叠。这些区域则使用struct vm_area_struct进行管理。这些区域可能是malloc所申请的堆空间,也可能是一个内存映射文件,又或者是一个mmap分配的匿名内存区域。一个进程只有一个mm_struct,它是对整个用户空间的描述。一个进程可以包含多个vm_area_struct.
struct mm_struct {
.................
unsigned long mmap_base; /* base of mmap area */
..............
unsigned long start_code, end_code, start_data, end_data;
unsigned long start_brk, brk, start_stack;
.......................
};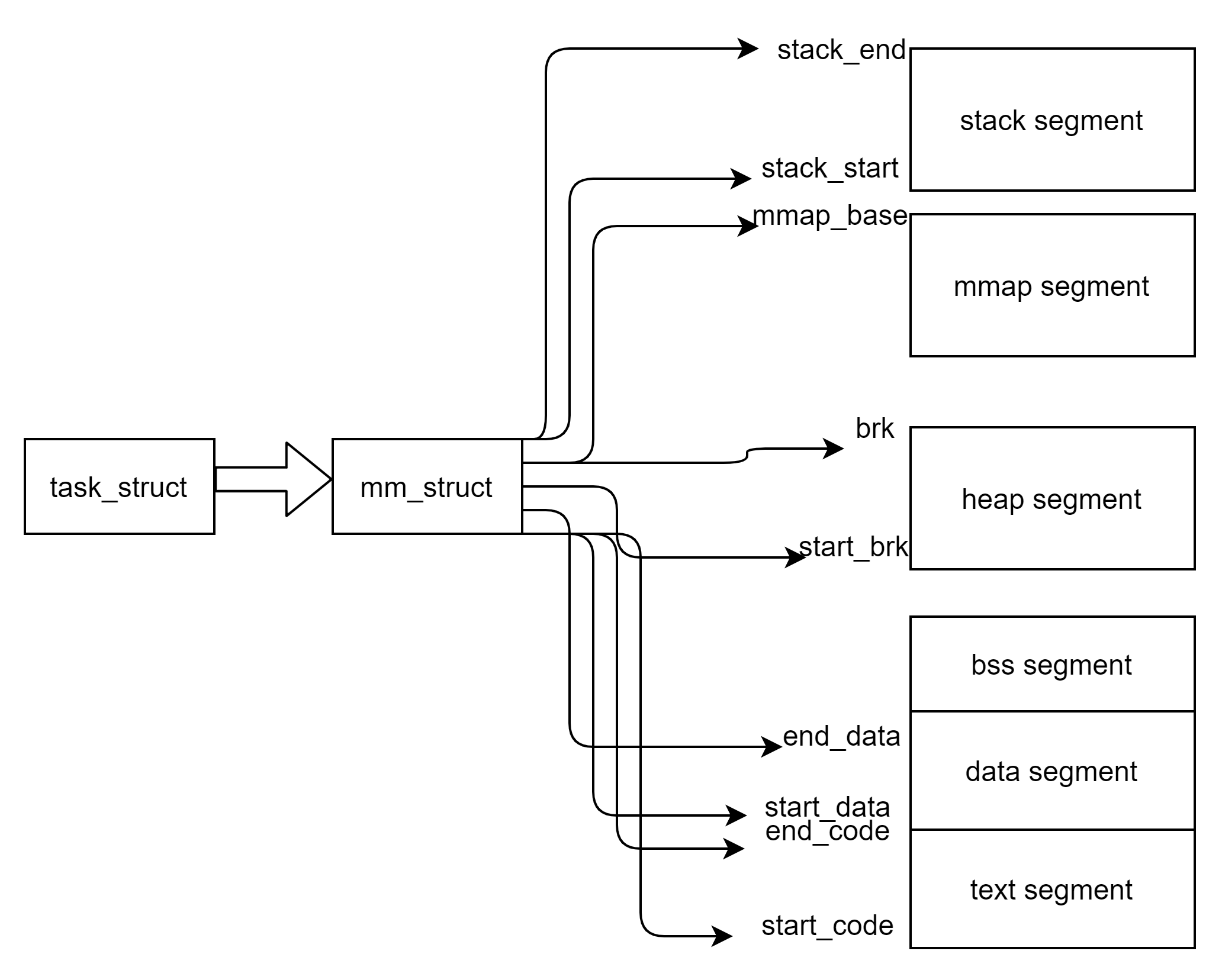
通过上图可以看到,mm_struct里面保存了整个进程空间的代码段,数据段,堆区,栈区的布局信息。
struct mm_struct {
struct vm_area_struct *mmap; /* list of VMAs */
struct rb_root mm_rb;
.........................
};
struct vm_area_struct {
...................
/* linked list of VM areas per task, sorted by address */
struct vm_area_struct *vm_next, *vm_prev;
struct rb_node vm_rb;
.................
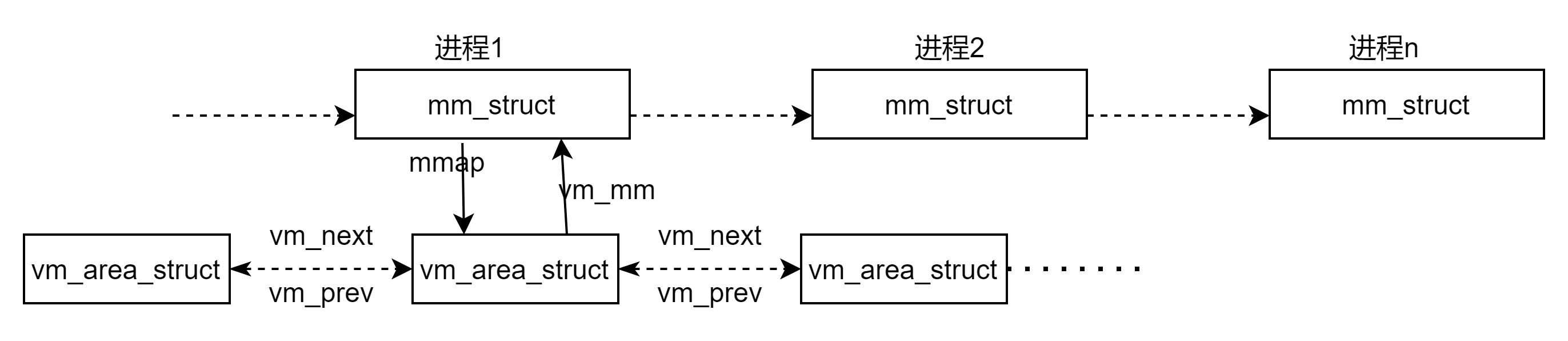
};每个进程只有一个mm_struct,但存在多个vm_area_struct。mm_struct->mmap能够找到链表的头结点vm_area_struct;vm_area_struct->vm_mm能够找到其所属的mm_struct。在地址空间中,mmap为地址空间的内存区域(用vm_area_struct结构来表示)链表,mm_rb用红黑树来存储,它是树的根部。链表表示起来更加方便,红黑树表示起来更加方便查找。区别是,当虚拟区较少的时候,这个时候采用单链表,由mmap指向这个链表,当虚拟区多时此时采用红黑树的结构,由mm_rb指向这棵红黑树。这样就可以在大量数据的时候效率更高。
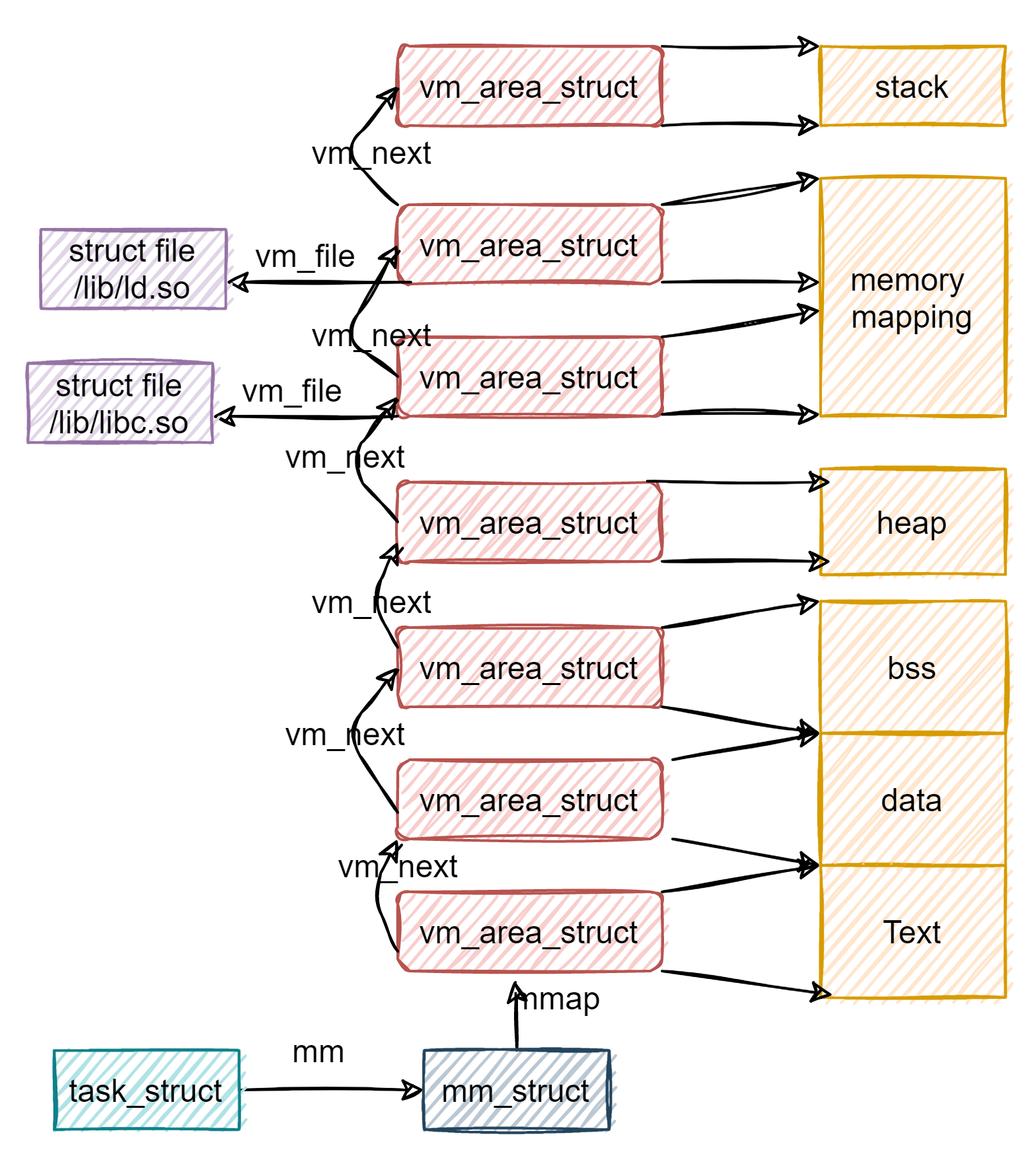
struct mm_struct {
/* VMA链表首部 */
struct vm_area_struct *mmap; /* list of VMAs */
/* VMA会被放到红黑树中,该成员表示根节点 */
struct rb_root mm_rb;
u32 vmacache_seqnum; /* per-thread vmacache */
#ifdef CONFIG_MMU
unsigned long (*get_unmapped_area) (struct file *filp,
unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags);
#endif
unsigned long mmap_base; /* base of mmap area */
unsigned long mmap_legacy_base; /* base of mmap area in bottom-up allocations */
unsigned long task_size; /* size of task vm space */
unsigned long highest_vm_end; /* highest vma end address */
/* 全局目录表的起始地址 */
pgd_t * pgd;
atomic_t mm_users; /* How many users with user space? */
atomic_t mm_count; /* How many references to "struct mm_struct" (users count as 1) */
atomic_long_t nr_ptes; /* Page table pages */
int map_count; /* number of VMAs */
spinlock_t page_table_lock; /* Protects page tables and some counters */
struct rw_semaphore mmap_sem;
struct list_head mmlist; /* List of maybe swapped mm's. These are globally strung
* together off init_mm.mmlist, and are protected
* by mmlist_lock
*/
unsigned long hiwater_rss; /* High-watermark of RSS usage */
unsigned long hiwater_vm; /* High-water virtual memory usage */
unsigned long total_vm; /* Total pages mapped */
unsigned long locked_vm; /* Pages that have PG_mlocked set */
unsigned long pinned_vm; /* Refcount permanently increased */
unsigned long shared_vm; /* Shared pages (files) */
unsigned long exec_vm; /* VM_EXEC & ~VM_WRITE */
unsigned long stack_vm; /* VM_GROWSUP/DOWN */
unsigned long def_flags;
/* 代码段和数据段起始和结束地址 */
unsigned long start_code, end_code, start_data, end_data;
/* 堆栈的起始和结束地址 */
unsigned long start_brk, brk, start_stack;
/* 命令行和环境变量区域的起始和结束地址 */
unsigned long arg_start, arg_end, env_start, env_end;
unsigned long saved_auxv[AT_VECTOR_SIZE]; /* for /proc/PID/auxv */
/*
* Special counters, in some configurations protected by the
* page_table_lock, in other configurations by being atomic.
*/
struct mm_rss_stat rss_stat;
struct linux_binfmt *binfmt;
cpumask_var_t cpu_vm_mask_var;
/* Architecture-specific MM context */
mm_context_t context;
unsigned long flags; /* Must use atomic bitops to access the bits */
struct core_state *core_state; /* coredumping support */
#ifdef CONFIG_AIO
spinlock_t ioctx_lock;
struct kioctx_table __rcu *ioctx_table;
#endif
#ifdef CONFIG_MEMCG
/*
* "owner" points to a task that is regarded as the canonical
* user/owner of this mm. All of the following must be true in
* order for it to be changed:
*
* current == mm->owner
* current->mm != mm
* new_owner->mm == mm
* new_owner->alloc_lock is held
*/
struct task_struct __rcu *owner;
#endif
/* store ref to file /proc/<pid>/exe symlink points to */
struct file *exe_file;
#ifdef CONFIG_MMU_NOTIFIER
struct mmu_notifier_mm *mmu_notifier_mm;
#endif
#if defined(CONFIG_TRANSPARENT_HUGEPAGE) && !USE_SPLIT_PMD_PTLOCKS
pgtable_t pmd_huge_pte; /* protected by page_table_lock */
#endif
#ifdef CONFIG_CPUMASK_OFFSTACK
struct cpumask cpumask_allocation;
#endif
#ifdef CONFIG_NUMA_BALANCING
/*
* numa_next_scan is the next time that the PTEs will be marked
* pte_numa. NUMA hinting faults will gather statistics and migrate
* pages to new nodes if necessary.
*/
unsigned long numa_next_scan;
/* Restart point for scanning and setting pte_numa */
unsigned long numa_scan_offset;
/* numa_scan_seq prevents two threads setting pte_numa */
int numa_scan_seq;
#endif
#if defined(CONFIG_NUMA_BALANCING) || defined(CONFIG_COMPACTION)
/*
* An operation with batched TLB flushing is going on. Anything that
* can move process memory needs to flush the TLB when moving a
* PROT_NONE or PROT_NUMA mapped page.
*/
bool tlb_flush_pending;
#endif
struct uprobes_state uprobes_state;
};一个进程可以包含多个线程,而一个进程只有一个mm_struct。因此这几个线程的task_struct是指向的同一个mm_struct。
内核线程不需要mm_struct,因为它们永远不会发生缺页中断。因此内核线程的task_struct->mm字段为NULL。
如何获取当前进程的task_struct
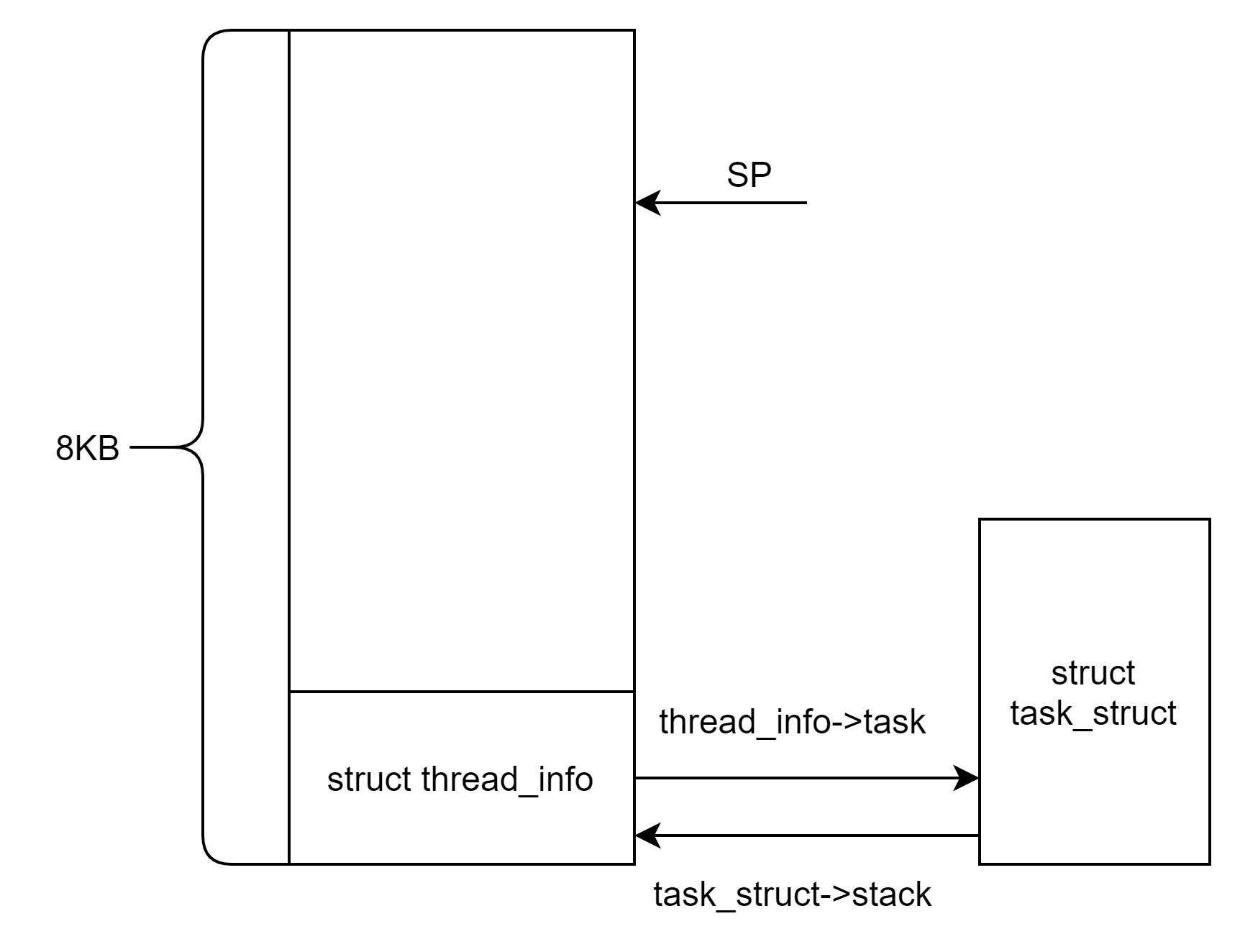
arm32内核栈大小是8k,arm64内核栈大小是16k。内核栈的起始地址都是按照8K或者16k的大小对齐的。因此只要能够获取到sp栈顶指针的地址,那么按照8/16k对齐之后,就能得到内核栈的起始地址。
thread_info被放到了内核栈起始地址处,其成员task指向了当前进程的task_struct。同样当前进程的task_struct的成员stack也指向了其内核栈的起始地址,即thread_info。因此可以知道每个进程都有自己一个单独的内核栈。
struct thread_info {
..........................
struct task_struct *task; /* main task structure */
...................................
};
struct task_struct {
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
void *stack;
...............
};
#define get_current() (current_thread_info()->task)
#define current get_current()
atic inline struct thread_info *current_thread_info(void) __attribute_const__;
static inline struct thread_info *current_thread_info(void)
{
register unsigned long sp asm ("sp");
return (struct thread_info *)(sp & ~(THREAD_SIZE - 1));
}
#define THREAD_SIZE_ORDER 1
#define THREAD_SIZE 8192
#define THREAD_START_SP (THREAD_SIZE - 8)进程、线程创建
进程或者线程的创建通过fork、vfork或者clone等系统调用建立,它们最终都是通过do_fork传入不同的参数实现的。
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)clone_flags:创建进程的标志位集合
stack_start:用户态栈的起始地址
stack_size:用户态栈大小,通常设置为0
parent_tidptr,child_tidptr指向用户空间中地址的两个指针,分别指向父子进程的pid
fork实现:SIGCHLD表示子进程在终止后发送SIGCHLD信号通知父进程。fork为子进程建立了一个基于父进程的完整的副本。但是该副本并不是立即就完成创建,而是采用了写时复制(主要是为了减小创建完整副本的开销)。在最开始是子进程只是复制了进程的页表,并不会去复制页面里面的内存(物理page?)。当子进程需要去修改内容时,才会触发写时复制机制,为子进程创建一个副本(不知道这个创建的副本是父进程所有的东西,还是说就只是需要被改写内容的副本,感觉应该是后者)。
另外fork出来的子进程和父进程,哪个先运行,顺序是不确定的。网上也有说和内核版本有关系。http://chenzhenianqing.com/articles/350.html
SYSCALL_DEFINE0(fork)
{
#ifdef CONFIG_MMU
return do_fork(SIGCHLD, 0, 0, NULL, NULL);
#else
/* can not support in nommu mode */
return -EINVAL;
#endif
}vfork实现
CLONE_VFORK:创建子进程是启用linux内核的完成机制(completion)。wait_for_completion会使父进程进入睡眠等待,直到子进程执行execve或者exit释放虚拟内存资源。
CLONE_VM:父子进程运行在同一个虚拟地址空间,一个进程对全局变量的修改,对另外的进程也可以看到。(正常情况下,不同的进程的虚拟地址空间是不同的)
从传入的标记就可以看到vfork创建的子进程一定运行在父进程前面。
SYSCALL_DEFINE0(vfork)
{
return do_fork(CLONE_VFORK | CLONE_VM | SIGCHLD, 0,
0, NULL, NULL);
}clone实现:clone用于创建线程。
SYSCALL_DEFINE5(clone, unsigned long, clone_flags, unsigned long, newsp,
int __user *, parent_tidptr,
int __user *, child_tidptr,
int, tls_val)
{
return do_fork(clone_flags, newsp, 0, parent_tidptr, child_tidptr);
}long do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
struct task_struct *p;
int trace = 0;
long nr;
/*
* Determine whether and which event to report to ptracer. When
* called from kernel_thread or CLONE_UNTRACED is explicitly
* requested, no event is reported; otherwise, report if the event
* for the type of forking is enabled.
*/
if (!(clone_flags & CLONE_UNTRACED)) {
if (clone_flags & CLONE_VFORK)
trace = PTRACE_EVENT_VFORK;
else if ((clone_flags & CSIGNAL) != SIGCHLD)
trace = PTRACE_EVENT_CLONE;
else
trace = PTRACE_EVENT_FORK;
if (likely(!ptrace_event_enabled(current, trace)))
trace = 0;
}
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace);
/*
* Do this prior waking up the new thread - the thread pointer
* might get invalid after that point, if the thread exits quickly.
*/
if (!IS_ERR(p)) {
struct completion vfork;
struct pid *pid;
trace_sched_process_fork(current, p);
pid = get_task_pid(p, PIDTYPE_PID);
nr = pid_vnr(pid);
if (clone_flags & CLONE_PARENT_SETTID)
put_user(nr, parent_tidptr);
if (clone_flags & CLONE_VFORK) {
p->vfork_done = &vfork;
init_completion(&vfork);
get_task_struct(p);
}
/* 唤醒新创建的进程 */
wake_up_new_task(p);
/* forking complete and child started to run, tell ptracer */
if (unlikely(trace))
ptrace_event_pid(trace, pid);
/*
设置了CLONE_VFORK,父进程就会等待子进程执行exit或者execve
看了一下wait_for_vfork_done最后的实现,感觉父进程只是进入了一个循环,
并不是将父进程从就绪队列里面移除
*/
if (clone_flags & CLONE_VFORK) {
if (!wait_for_vfork_done(p, &vfork))
ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid);
}
put_pid(pid);
} else {
nr = PTR_ERR(p);
}
return nr;
}wait_for_vfork_done->wait_for_completion_killable->wait_for_common->do_wait_for_common
从最后的代码实现看感觉vfork并不是一定会让子进程先运行,只是父进程进入了一个循环出不来而已,并不是将父进程从就绪队列中摘除了??
static inline long __sched
do_wait_for_common(struct completion *x,
long (*action)(long), long timeout, int state)
{
if (!x->done) {
DECLARE_WAITQUEUE(wait, current);
__add_wait_queue_tail_exclusive(&x->wait, &wait);
do {
if (signal_pending_state(state, current)) {
timeout = -ERESTARTSYS;
break;
}
__set_current_state(state);
spin_unlock_irq(&x->wait.lock);
timeout = action(timeout);
spin_lock_irq(&x->wait.lock);
} while (!x->done && timeout);
__remove_wait_queue(&x->wait, &wait);
if (!x->done)
return timeout;
}
x->done--;
return timeout ?: 1;
}copy_process创建一个新的进程
static struct task_struct *copy_process(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *child_tidptr,
struct pid *pid,
int trace)
{
.....................................................
/* 创建一个新的task_struct实例 */
p = dup_task_struct(current);
}static struct task_struct *dup_task_struct(struct task_struct *orig)
{
struct task_struct *tsk;
struct thread_info *ti;
unsigned long *stackend;
int node = tsk_fork_get_node(orig);
int err;
/* 分配一个task_struct实例 */
tsk = alloc_task_struct_node(node);
if (!tsk)
return NULL;
/* 分配一个thread_info实例 */
ti = alloc_thread_info_node(tsk, node);
if (!ti)
goto free_tsk;
/* 把父进程的tsk复制为子进程的tsk */
err = arch_dup_task_struct(tsk, orig);
if (err)
goto free_ti;
tsk->stack = ti;
/* 把父进程的thread_info复制为子进程 */
setup_thread_stack(tsk, orig);
clear_user_return_notifier(tsk);
clear_tsk_need_resched(tsk);
stackend = end_of_stack(tsk);
*stackend = STACK_END_MAGIC; /* for overflow detection */
#ifdef CONFIG_CC_STACKPROTECTOR
tsk->stack_canary = get_random_int();
#endif
/*
* One for us, one for whoever does the "release_task()" (usually
* parent)
*/
atomic_set(&tsk->usage, 2);
#ifdef CONFIG_BLK_DEV_IO_TRACE
tsk->btrace_seq = 0;
#endif
tsk->splice_pipe = NULL;
tsk->task_frag.page = NULL;
account_kernel_stack(ti, 1);
return tsk;
free_ti:
free_thread_info(ti);
free_tsk:
free_task_struct(tsk);
return NULL;
}static struct task_struct *copy_process(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *child_tidptr,
struct pid *pid,
int trace)
{
int retval;
struct task_struct *p;
.....................
/* 创建一个新的task_struct实例 */
p = dup_task_struct(current);
if (!p)
goto fork_out;
ftrace_graph_init_task(p);
get_seccomp_filter(p);
rt_mutex_init_task(p);
#ifdef CONFIG_PROVE_LOCKING
DEBUG_LOCKS_WARN_ON(!p->hardirqs_enabled);
DEBUG_LOCKS_WARN_ON(!p->softirqs_enabled);
#endif
retval = -EAGAIN;
if (atomic_read(&p->real_cred->user->processes) >=
task_rlimit(p, RLIMIT_NPROC)) {
if (p->real_cred->user != INIT_USER &&
!capable(CAP_SYS_RESOURCE) && !capable(CAP_SYS_ADMIN))
goto bad_fork_free;
}
current->flags &= ~PF_NPROC_EXCEEDED;
/* 复制父进程证书,不知道是干啥的 */
retval = copy_creds(p, clone_flags);
if (retval < 0)
goto bad_fork_free;
/*
* If multiple threads are within copy_process(), then this check
* triggers too late. This doesn't hurt, the check is only there
* to stop root fork bombs.
*/
retval = -EAGAIN;
if (nr_threads >= max_threads)
goto bad_fork_cleanup_count;
if (!try_module_get(task_thread_info(p)->exec_domain->module))
goto bad_fork_cleanup_count;
delayacct_tsk_init(p); /* Must remain after dup_task_struct() */
p->flags &= ~(PF_SUPERPRIV | PF_WQ_WORKER);
p->flags |= PF_FORKNOEXEC;//PF_FORKNOEXEC表示该进程还不能执行
INIT_LIST_HEAD(&p->children);//初始化子进程链表为空
INIT_LIST_HEAD(&p->sibling);//初始化兄弟进程链表为空
rcu_copy_process(p);
p->vfork_done = NULL;
spin_lock_init(&p->alloc_lock);
init_sigpending(&p->pending);
p->utime = p->stime = p->gtime = 0;
p->utimescaled = p->stimescaled = 0;
#ifndef CONFIG_VIRT_CPU_ACCOUNTING_NATIVE
p->prev_cputime.utime = p->prev_cputime.stime = 0;
#endif
#ifdef CONFIG_VIRT_CPU_ACCOUNTING_GEN
seqlock_init(&p->vtime_seqlock);
p->vtime_snap = 0;
p->vtime_snap_whence = VTIME_SLEEPING;
#endif
#if defined(SPLIT_RSS_COUNTING)
memset(&p->rss_stat, 0, sizeof(p->rss_stat));
#endif
p->default_timer_slack_ns = current->timer_slack_ns;
task_io_accounting_init(&p->ioac);
acct_clear_integrals(p);
posix_cpu_timers_init(p);
do_posix_clock_monotonic_gettime(&p->start_time);
p->real_start_time = p->start_time;
monotonic_to_bootbased(&p->real_start_time);
p->io_context = NULL;
p->audit_context = NULL;
if (clone_flags & CLONE_THREAD)
threadgroup_change_begin(current);
cgroup_fork(p);
#ifdef CONFIG_NUMA
p->mempolicy = mpol_dup(p->mempolicy);
if (IS_ERR(p->mempolicy)) {
retval = PTR_ERR(p->mempolicy);
p->mempolicy = NULL;
goto bad_fork_cleanup_threadgroup_lock;
}
#endif
#ifdef CONFIG_CPUSETS
p->cpuset_mem_spread_rotor = NUMA_NO_NODE;
p->cpuset_slab_spread_rotor = NUMA_NO_NODE;
seqcount_init(&p->mems_allowed_seq);
#endif
#ifdef CONFIG_TRACE_IRQFLAGS
p->irq_events = 0;
p->hardirqs_enabled = 0;
p->hardirq_enable_ip = 0;
p->hardirq_enable_event = 0;
p->hardirq_disable_ip = _THIS_IP_;
p->hardirq_disable_event = 0;
p->softirqs_enabled = 1;
p->softirq_enable_ip = _THIS_IP_;
p->softirq_enable_event = 0;
p->softirq_disable_ip = 0;
p->softirq_disable_event = 0;
p->hardirq_context = 0;
p->softirq_context = 0;
#endif
#ifdef CONFIG_LOCKDEP
p->lockdep_depth = 0; /* no locks held yet */
p->curr_chain_key = 0;
p->lockdep_recursion = 0;
#endif
#ifdef CONFIG_DEBUG_MUTEXES
p->blocked_on = NULL; /* not blocked yet */
#endif
#ifdef CONFIG_MEMCG
p->memcg_batch.do_batch = 0;
p->memcg_batch.memcg = NULL;
#endif
#ifdef CONFIG_BCACHE
p->sequential_io = 0;
p->sequential_io_avg = 0;
#endif
/* Perform scheduler related setup. Assign this task to a CPU. */
/* 初始化进程调度相关的数据结构 */
retval = sched_fork(clone_flags, p);
if (retval)
goto bad_fork_cleanup_policy;
retval = perf_event_init_task(p);
if (retval)
goto bad_fork_cleanup_policy;
retval = audit_alloc(p);
if (retval)
goto bad_fork_cleanup_policy;
/* copy all the process information */
retval = copy_semundo(clone_flags, p);
if (retval)
goto bad_fork_cleanup_audit;
/* 复制父进程打开的文件信息 */
retval = copy_files(clone_flags, p);
if (retval)
goto bad_fork_cleanup_semundo;
retval = copy_fs(clone_flags, p);
if (retval)
goto bad_fork_cleanup_files;
retval = copy_sighand(clone_flags, p);
if (retval)
goto bad_fork_cleanup_fs;
retval = copy_signal(clone_flags, p);
if (retval)
goto bad_fork_cleanup_sighand;
/* 复制父进程的内存空间 */
retval = copy_mm(clone_flags, p);
if (retval)
goto bad_fork_cleanup_signal;
retval = copy_namespaces(clone_flags, p);
if (retval)
goto bad_fork_cleanup_mm;
retval = copy_io(clone_flags, p);
if (retval)
goto bad_fork_cleanup_namespaces;
retval = copy_thread(clone_flags, stack_start, stack_size, p);
if (retval)
goto bad_fork_cleanup_io;
if (pid != &init_struct_pid) {
retval = -ENOMEM;
pid = alloc_pid(p->nsproxy->pid_ns_for_children);
if (!pid)
goto bad_fork_cleanup_io;
}
p->set_child_tid = (clone_flags & CLONE_CHILD_SETTID) ? child_tidptr : NULL;
/*
* Clear TID on mm_release()?
*/
p->clear_child_tid = (clone_flags & CLONE_CHILD_CLEARTID) ? child_tidptr : NULL;
#ifdef CONFIG_BLOCK
p->plug = NULL;
#endif
#ifdef CONFIG_FUTEX
p->robust_list = NULL;
#ifdef CONFIG_COMPAT
p->compat_robust_list = NULL;
#endif
INIT_LIST_HEAD(&p->pi_state_list);
p->pi_state_cache = NULL;
#endif
/*
* sigaltstack should be cleared when sharing the same VM
*/
if ((clone_flags & (CLONE_VM|CLONE_VFORK)) == CLONE_VM)
p->sas_ss_sp = p->sas_ss_size = 0;
/*
* Syscall tracing and stepping should be turned off in the
* child regardless of CLONE_PTRACE.
*/
user_disable_single_step(p);
clear_tsk_thread_flag(p, TIF_SYSCALL_TRACE);
#ifdef TIF_SYSCALL_EMU
clear_tsk_thread_flag(p, TIF_SYSCALL_EMU);
#endif
clear_all_latency_tracing(p);
/* ok, now we should be set up.. */
p->pid = pid_nr(pid);
if (clone_flags & CLONE_THREAD) {
p->exit_signal = -1;
p->group_leader = current->group_leader;
p->tgid = current->tgid;
} else {
if (clone_flags & CLONE_PARENT)
p->exit_signal = current->group_leader->exit_signal;
else
p->exit_signal = (clone_flags & CSIGNAL);
p->group_leader = p;
p->tgid = p->pid;
}
p->nr_dirtied = 0;
p->nr_dirtied_pause = 128 >> (PAGE_SHIFT - 10);
p->dirty_paused_when = 0;
p->pdeath_signal = 0;
INIT_LIST_HEAD(&p->thread_group);
p->task_works = NULL;
/*
* Make it visible to the rest of the system, but dont wake it up yet.
* Need tasklist lock for parent etc handling!
*/
write_lock_irq(&tasklist_lock);
/* CLONE_PARENT re-uses the old parent */
if (clone_flags & (CLONE_PARENT|CLONE_THREAD)) {
p->real_parent = current->real_parent;
p->parent_exec_id = current->parent_exec_id;
} else {
p->real_parent = current;
p->parent_exec_id = current->self_exec_id;
}
spin_lock(¤t->sighand->siglock);
/*
* Process group and session signals need to be delivered to just the
* parent before the fork or both the parent and the child after the
* fork. Restart if a signal comes in before we add the new process to
* it's process group.
* A fatal signal pending means that current will exit, so the new
* thread can't slip out of an OOM kill (or normal SIGKILL).
*/
recalc_sigpending();
if (signal_pending(current)) {
spin_unlock(¤t->sighand->siglock);
write_unlock_irq(&tasklist_lock);
retval = -ERESTARTNOINTR;
goto bad_fork_free_pid;
}
if (likely(p->pid)) {
ptrace_init_task(p, (clone_flags & CLONE_PTRACE) || trace);
init_task_pid(p, PIDTYPE_PID, pid);
if (thread_group_leader(p)) {
init_task_pid(p, PIDTYPE_PGID, task_pgrp(current));
init_task_pid(p, PIDTYPE_SID, task_session(current));
if (is_child_reaper(pid)) {
ns_of_pid(pid)->child_reaper = p;
p->signal->flags |= SIGNAL_UNKILLABLE;
}
p->signal->leader_pid = pid;
p->signal->tty = tty_kref_get(current->signal->tty);
list_add_tail(&p->sibling, &p->real_parent->children);
list_add_tail_rcu(&p->tasks, &init_task.tasks);
attach_pid(p, PIDTYPE_PGID);
attach_pid(p, PIDTYPE_SID);
__this_cpu_inc(process_counts);
} else {
current->signal->nr_threads++;
atomic_inc(¤t->signal->live);
atomic_inc(¤t->signal->sigcnt);
list_add_tail_rcu(&p->thread_group,
&p->group_leader->thread_group);
list_add_tail_rcu(&p->thread_node,
&p->signal->thread_head);
}
attach_pid(p, PIDTYPE_PID);
nr_threads++;
}
total_forks++;
spin_unlock(¤t->sighand->siglock);
syscall_tracepoint_update(p);
write_unlock_irq(&tasklist_lock);
proc_fork_connector(p);
cgroup_post_fork(p);
if (clone_flags & CLONE_THREAD)
threadgroup_change_end(current);
perf_event_fork(p);
trace_task_newtask(p, clone_flags);
uprobe_copy_process(p, clone_flags);
return p;
bad_fork_free_pid:
if (pid != &init_struct_pid)
free_pid(pid);
bad_fork_cleanup_io:
if (p->io_context)
exit_io_context(p);
bad_fork_cleanup_namespaces:
exit_task_namespaces(p);
bad_fork_cleanup_mm:
if (p->mm)
mmput(p->mm);
bad_fork_cleanup_signal:
if (!(clone_flags & CLONE_THREAD))
free_signal_struct(p->signal);
bad_fork_cleanup_sighand:
__cleanup_sighand(p->sighand);
bad_fork_cleanup_fs:
exit_fs(p); /* blocking */
bad_fork_cleanup_files:
exit_files(p); /* blocking */
bad_fork_cleanup_semundo:
exit_sem(p);
bad_fork_cleanup_audit:
audit_free(p);
bad_fork_cleanup_policy:
perf_event_free_task(p);
#ifdef CONFIG_NUMA
mpol_put(p->mempolicy);
bad_fork_cleanup_threadgroup_lock:
#endif
if (clone_flags & CLONE_THREAD)
threadgroup_change_end(current);
delayacct_tsk_free(p);
module_put(task_thread_info(p)->exec_domain->module);
bad_fork_cleanup_count:
atomic_dec(&p->cred->user->processes);
exit_creds(p);
bad_fork_free:
free_task(p);
fork_out:
return ERR_PTR(retval);
}copy_process->copy_mm:可以看到如果设置了CLONE_VM,确实父子进程指向的是同一个mm_struct,共享了同一个虚拟地址空间
static int copy_mm(unsigned long clone_flags, struct task_struct *tsk)
{
struct mm_struct *mm, *oldmm;
int retval;
tsk->min_flt = tsk->maj_flt = 0;
tsk->nvcsw = tsk->nivcsw = 0;
#ifdef CONFIG_DETECT_HUNG_TASK
tsk->last_switch_count = tsk->nvcsw + tsk->nivcsw;
#endif
tsk->mm = NULL;
tsk->active_mm = NULL;
/*
* Are we cloning a kernel thread?
*
* We need to steal a active VM for that..
*/
oldmm = current->mm;
if (!oldmm)/* mm为空说明是线程或者内核线程 */
return 0;
/* initialize the new vmacache entries */
vmacache_flush(tsk);
/* 从这里可以看到CLONE_VM,确实父子进程共享虚拟地址空间,
父子进程指向同一个mm_struct
*/
if (clone_flags & CLONE_VM) {
atomic_inc(&oldmm->mm_users);
mm = oldmm;
goto good_mm;
}
retval = -ENOMEM;
/* 分配一个mm_struct然后从父进程复制相关内容 */
mm = dup_mm(tsk);
if (!mm)
goto fail_nomem;
good_mm:
tsk->mm = mm;
tsk->active_mm = mm;
return 0;
fail_nomem:
return retval;
}copy_process->copy_mm->dup_mm:为子进程分配一个mm_struct,然后将父进程的相关信息copy过来
/*
* Allocate a new mm structure and copy contents from the
* mm structure of the passed in task structure.
*/
static struct mm_struct *dup_mm(struct task_struct *tsk)
{
struct mm_struct *mm, *oldmm = current->mm;
int err;
/* 为子进程分配一个mm_struct */
mm = allocate_mm();
if (!mm)
goto fail_nomem;
memcpy(mm, oldmm, sizeof(*mm));
mm_init_cpumask(mm);
#if defined(CONFIG_TRANSPARENT_HUGEPAGE) && !USE_SPLIT_PMD_PTLOCKS
mm->pmd_huge_pte = NULL;
#endif
if (!mm_init(mm, tsk))
goto fail_nomem;
if (init_new_context(tsk, mm))
goto fail_nocontext;
dup_mm_exe_file(oldmm, mm);
err = dup_mmap(mm, oldmm);
if (err)
goto free_pt;
mm->hiwater_rss = get_mm_rss(mm);
mm->hiwater_vm = mm->total_vm;
if (mm->binfmt && !try_module_get(mm->binfmt->module))
goto free_pt;
return mm;
free_pt:
/* don't put binfmt in mmput, we haven't got module yet */
mm->binfmt = NULL;
mmput(mm);
fail_nomem:
return NULL;
fail_nocontext:
/*
* If init_new_context() failed, we cannot use mmput() to free the mm
* because it calls destroy_context()
*/
mm_free_pgd(mm);
free_mm(mm);
return NULL;
}copy_process->copy_mm->dup_mm->mm_alloc_pgd->pgd_alloc:为进程分配PGD页表
/*
* need to get a 16k page for level 1
*/
pgd_t *pgd_alloc(struct mm_struct *mm)
{
pgd_t *new_pgd, *init_pgd;
pud_t *new_pud, *init_pud;
pmd_t *new_pmd, *init_pmd;
pte_t *new_pte, *init_pte;
new_pgd = __pgd_alloc();
if (!new_pgd)
goto no_pgd;
memset(new_pgd, 0, USER_PTRS_PER_PGD * sizeof(pgd_t));
/*
* Copy over the kernel and IO PGD entries
*/
init_pgd = pgd_offset_k(0);
memcpy(new_pgd + USER_PTRS_PER_PGD, init_pgd + USER_PTRS_PER_PGD,
(PTRS_PER_PGD - USER_PTRS_PER_PGD) * sizeof(pgd_t));
clean_dcache_area(new_pgd, PTRS_PER_PGD * sizeof(pgd_t));
#ifdef CONFIG_ARM_LPAE
/*
* Allocate PMD table for modules and pkmap mappings.
*/
new_pud = pud_alloc(mm, new_pgd + pgd_index(MODULES_VADDR),
MODULES_VADDR);
if (!new_pud)
goto no_pud;
new_pmd = pmd_alloc(mm, new_pud, 0);
if (!new_pmd)
goto no_pmd;
#endif
if (!vectors_high()) {
/*
* On ARM, first page must always be allocated since it
* contains the machine vectors. The vectors are always high
* with LPAE.
*/
new_pud = pud_alloc(mm, new_pgd, 0);
if (!new_pud)
goto no_pud;
new_pmd = pmd_alloc(mm, new_pud, 0);
if (!new_pmd)
goto no_pmd;
new_pte = pte_alloc_map(mm, NULL, new_pmd, 0);
if (!new_pte)
goto no_pte;
init_pud = pud_offset(init_pgd, 0);
init_pmd = pmd_offset(init_pud, 0);
init_pte = pte_offset_map(init_pmd, 0);
set_pte_ext(new_pte + 0, init_pte[0], 0);
set_pte_ext(new_pte + 1, init_pte[1], 0);
pte_unmap(init_pte);
pte_unmap(new_pte);
}
return new_pgd;
no_pte:
pmd_free(mm, new_pmd);
no_pmd:
pud_free(mm, new_pud);
no_pud:
__pgd_free(new_pgd);
no_pgd:
return NULL;
}copy_process->copy_mm->dup_mm->dup_mmap
遍历父进程所有的VMA(进程的虚拟地址空间由vm_area_struct表示),复制父进程VMA中对应的pte页表项到子进程相应的VMA中(只复制对应的pte页表项,并未复制VMA所对应页面的内容)
文章最开始提到,VMA可以是一个文件,也可以是代码段,数据段。因此父子进程执行同一个代码。应该就是这里复制的
static int dup_mmap(struct mm_struct *mm, struct mm_struct *oldmm)
{
struct vm_area_struct *mpnt, *tmp, *prev, **pprev;
struct rb_node **rb_link, *rb_parent;
int retval;
unsigned long charge;
uprobe_start_dup_mmap();
down_write(&oldmm->mmap_sem);
flush_cache_dup_mm(oldmm);
uprobe_dup_mmap(oldmm, mm);
/*
* Not linked in yet - no deadlock potential:
*/
down_write_nested(&mm->mmap_sem, SINGLE_DEPTH_NESTING);
mm->locked_vm = 0;
mm->mmap = NULL;
mm->vmacache_seqnum = 0;
mm->map_count = 0;
cpumask_clear(mm_cpumask(mm));
mm->mm_rb = RB_ROOT;
rb_link = &mm->mm_rb.rb_node;
rb_parent = NULL;
pprev = &mm->mmap;
retval = ksm_fork(mm, oldmm);
if (retval)
goto out;
retval = khugepaged_fork(mm, oldmm);
if (retval)
goto out;
prev = NULL;
/* 遍历所有的VMA */
for (mpnt = oldmm->mmap; mpnt; mpnt = mpnt->vm_next) {
struct file *file;
if (mpnt->vm_flags & VM_DONTCOPY) {
vm_stat_account(mm, mpnt->vm_flags, mpnt->vm_file,
-vma_pages(mpnt));
continue;
}
charge = 0;
if (mpnt->vm_flags & VM_ACCOUNT) {
unsigned long len = vma_pages(mpnt);
if (security_vm_enough_memory_mm(oldmm, len)) /* sic */
goto fail_nomem;
charge = len;
}
tmp = kmem_cache_alloc(vm_area_cachep, GFP_KERNEL);
if (!tmp)
goto fail_nomem;
*tmp = *mpnt;
INIT_LIST_HEAD(&tmp->anon_vma_chain);
retval = vma_dup_policy(mpnt, tmp);
if (retval)
goto fail_nomem_policy;
tmp->vm_mm = mm;
if (anon_vma_fork(tmp, mpnt))
goto fail_nomem_anon_vma_fork;
tmp->vm_flags &= ~VM_LOCKED;
tmp->vm_next = tmp->vm_prev = NULL;
file = tmp->vm_file;
if (file) {
struct inode *inode = file_inode(file);
struct address_space *mapping = file->f_mapping;
get_file(file);
if (tmp->vm_flags & VM_DENYWRITE)
atomic_dec(&inode->i_writecount);
mutex_lock(&mapping->i_mmap_mutex);
if (tmp->vm_flags & VM_SHARED)
mapping->i_mmap_writable++;
flush_dcache_mmap_lock(mapping);
/* insert tmp into the share list, just after mpnt */
if (unlikely(tmp->vm_flags & VM_NONLINEAR))
vma_nonlinear_insert(tmp,
&mapping->i_mmap_nonlinear);
else
vma_interval_tree_insert_after(tmp, mpnt,
&mapping->i_mmap);
flush_dcache_mmap_unlock(mapping);
mutex_unlock(&mapping->i_mmap_mutex);
}
/*
* Clear hugetlb-related page reserves for children. This only
* affects MAP_PRIVATE mappings. Faults generated by the child
* are not guaranteed to succeed, even if read-only
*/
if (is_vm_hugetlb_page(tmp))
reset_vma_resv_huge_pages(tmp);
/*
* Link in the new vma and copy the page table entries.
*/
*pprev = tmp;
pprev = &tmp->vm_next;
tmp->vm_prev = prev;
prev = tmp;
/* 将新创建的tmp加入到子进程的链表中 */
__vma_link_rb(mm, tmp, rb_link, rb_parent);
rb_link = &tmp->vm_rb.rb_right;
rb_parent = &tmp->vm_rb;
mm->map_count++;
retval = copy_page_range(mm, oldmm, mpnt);
if (tmp->vm_ops && tmp->vm_ops->open)
tmp->vm_ops->open(tmp);
if (retval)
goto out;
}
/* a new mm has just been created */
arch_dup_mmap(oldmm, mm);
retval = 0;
out:
up_write(&mm->mmap_sem);
flush_tlb_mm(oldmm);
up_write(&oldmm->mmap_sem);
uprobe_end_dup_mmap();
return retval;
fail_nomem_anon_vma_fork:
mpol_put(vma_policy(tmp));
fail_nomem_policy:
kmem_cache_free(vm_area_cachep, tmp);
fail_nomem:
retval = -ENOMEM;
vm_unacct_memory(charge);
goto out;
}copy_process->copy_mm->dup_mm->dup_mmap->copy_page_range将父进程的VAM页表复制到子进程页表中
int copy_page_range(struct mm_struct *dst_mm, struct mm_struct *src_mm,
struct vm_area_struct *vma)
{
pgd_t *src_pgd, *dst_pgd;
unsigned long next;
unsigned long addr = vma->vm_start;
unsigned long end = vma->vm_end;
unsigned long mmun_start; /* For mmu_notifiers */
unsigned long mmun_end; /* For mmu_notifiers */
bool is_cow;
int ret;
/*
* Don't copy ptes where a page fault will fill them correctly.
* Fork becomes much lighter when there are big shared or private
* readonly mappings. The tradeoff is that copy_page_range is more
* efficient than faulting.
*/
if (!(vma->vm_flags & (VM_HUGETLB | VM_NONLINEAR |
VM_PFNMAP | VM_MIXEDMAP))) {
if (!vma->anon_vma)
return 0;
}
if (is_vm_hugetlb_page(vma))
return copy_hugetlb_page_range(dst_mm, src_mm, vma);
if (unlikely(vma->vm_flags & VM_PFNMAP)) {
/*
* We do not free on error cases below as remove_vma
* gets called on error from higher level routine
*/
ret = track_pfn_copy(vma);
if (ret)
return ret;
}
/*
* We need to invalidate the secondary MMU mappings only when
* there could be a permission downgrade on the ptes of the
* parent mm. And a permission downgrade will only happen if
* is_cow_mapping() returns true.
*/
is_cow = is_cow_mapping(vma->vm_flags);
mmun_start = addr;
mmun_end = end;
if (is_cow)
mmu_notifier_invalidate_range_start(src_mm, mmun_start,
mmun_end);
ret = 0;
dst_pgd = pgd_offset(dst_mm, addr);
src_pgd = pgd_offset(src_mm, addr);
do {
next = pgd_addr_end(addr, end);
if (pgd_none_or_clear_bad(src_pgd))
continue;
if (unlikely(copy_pud_range(dst_mm, src_mm, dst_pgd, src_pgd,
vma, addr, next))) {
ret = -ENOMEM;
break;
}
} while (dst_pgd++, src_pgd++, addr = next, addr != end);
if (is_cow)
mmu_notifier_invalidate_range_end(src_mm, mmun_start, mmun_end);
return ret;
}fork是怎么返回两次的?感觉就是因为有两个进程,分别都会从fork调用返回。
在copy_thread里面可以看到,给子进程的r0设置为了0。网上说用户态fork调用的返回值就是r0,因此子进程返回的是0。而的do_fork返回值是子进程的pid,这里应该是父进程的返回值。
thread->cpu_context.pc = (unsigned long)ret_from_fork;
thread->cpu_context.sp = (unsigned long)childregs;2、可以看到进程硬件上下文cpu_context的pc被设置为了ret_from_fork。在copy_process返回后,会将子进程唤醒,这样就能够让子进程被调度。在进程切换时,switch_to()函数会完成进程硬件上下文的切换,即把下一个进程(next进程)的cpu_context数据结构保存的内容恢复到处理器的寄存器中,从而完成进程的切换。此时,处理器开始运行next进程了。由于新创建的子进程的PC设置为了ret_from_fork,处理器会从ret_from_fork汇编函数里开始执行。
int
copy_thread(unsigned long clone_flags, unsigned long stack_start,
unsigned long stk_sz, struct task_struct *p)
{
struct thread_info *thread = task_thread_info(p);
struct pt_regs *childregs = task_pt_regs(p);
memset(&thread->cpu_context, 0, sizeof(struct cpu_context_save));
if (likely(!(p->flags & PF_KTHREAD))) {//用户进程
*childregs = *current_pt_regs();//这里的regs保存的是用户态的上下文
childregs->ARM_r0 = 0;
if (stack_start)
childregs->ARM_sp = stack_start;
} else {//创建的是内核线程
/*
内核线程的没有用户态的东西,所以及通过memset全部置为0,
cpu_context表示内核态的上下文,
在这里把要执行函数的地址保存在r5寄存器中,参数保存在r4寄存器中
*/
memset(childregs, 0, sizeof(struct pt_regs));
thread->cpu_context.r4 = stk_sz;//参数
thread->cpu_context.r5 = stack_start;//内核线程执行的函数
childregs->ARM_cpsr = SVC_MODE;
}
thread->cpu_context.pc = (unsigned long)ret_from_fork;
thread->cpu_context.sp = (unsigned long)childregs;
clear_ptrace_hw_breakpoint(p);
if (clone_flags & CLONE_SETTLS)
thread->tp_value[0] = childregs->ARM_r3;
thread->tp_value[1] = get_tpuser();
thread_notify(THREAD_NOTIFY_COPY, thread);
return 0;
}
#define THREAD_SIZE 8192
#define THREAD_START_SP (THREAD_SIZE - 8)
#define task_pt_regs(p) \
((struct pt_regs *)(THREAD_START_SP + task_stack_page(p)) - 1)
#define task_stack_page(task) ((task)->stack)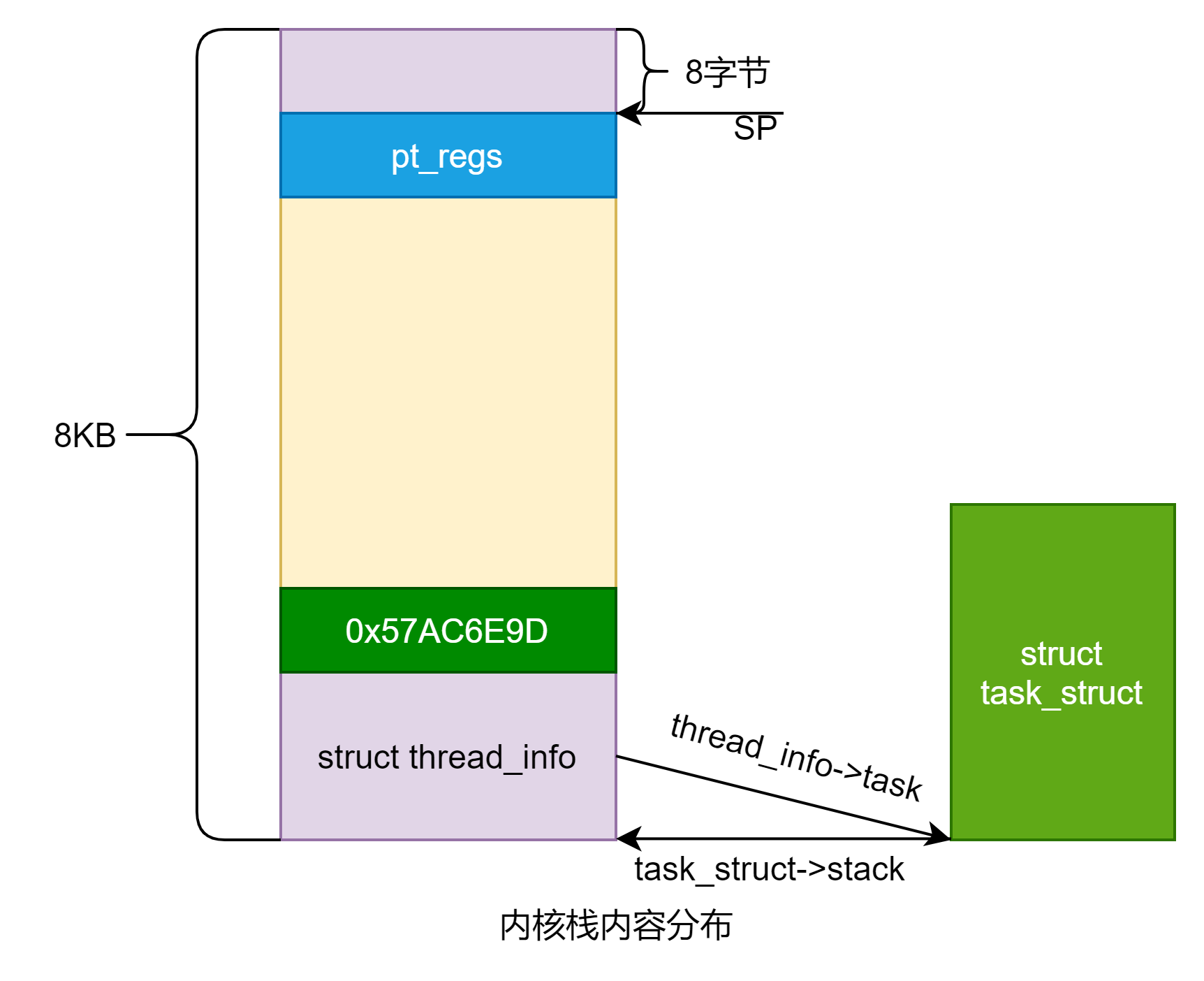
(task)->stack是指向了内核栈最下面,即thread_info起始地址
(struct pt_regs *)(THREAD_START_SP + task_stack_page(p))是指向了上图SP的位置。
然后将其-1,其实等价于(uint8_t*)(struct pt_regs *)(THREAD_START_SP + task_stack_page(p)) - sizeof(struct pt_regs *)
https://blog.csdn.net/rlk8888/article/details/122514176。
(3)CPU打断正在运行的用户进程A,处于异常模式。CPU会跳转到异常向量表中的el0_irq里。在el0_irq汇编函数里,首先把中断现场保存到进程A的pt_regs栈框中。
按照上面说的,pt_regs里面应该是用户进程的现场信息。
#define STACK_END_MAGIC 0x57AC6E9D
static inline unsigned long *end_of_stack(struct task_struct *p)
{
return (unsigned long *)(task_thread_info(p) + 1);
}
static struct task_struct *dup_task_struct(struct task_struct *orig)
{
.........................
ti = alloc_thread_info_node(tsk, node);
.........................
stackend = end_of_stack(tsk);
*stackend = STACK_END_MAGIC; /* for overflow detection */
}可以看到0x57AC6E90,其实就是在创建子进程信息的时候被设置的。表示栈的末尾,用于栈溢出检测
接下来看子进程被调度时如何运行
schedule -> __schedule -> context_switch ->switch_mm & switch_to
static inline void
context_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next)
{
struct mm_struct *mm, *oldmm;
prepare_task_switch(rq, prev, next);
mm = next->mm;
oldmm = prev->active_mm;
.......................
if (!mm) {
next->active_mm = oldmm;
atomic_inc(&oldmm->mm_count);
enter_lazy_tlb(oldmm, next);
} else
switch_mm(oldmm, mm, next);
.........................
switch_to(prev, next, prev);
..............................
}context_switch()调用switch_mm切换进程页表, 然后调用switch_to()加载task的pc, sp等寄存器。
arch\arm\include\asm\switch_to.h(我环境里面是这个)
extern struct task_struct *__switch_to(struct task_struct *, struct thread_info *, struct thread_info *);
#define switch_to(prev,next,last) \
do { \
last = __switch_to(prev,task_thread_info(prev), task_thread_info(next)); \
} while (0)/arch/arm/kernel/asm-offsets.c
DEFINE(TI_CPU_SAVE, offsetof(struct thread_info, cpu_context));
#define DEFINE(sym, val) \
asm volatile("\n->" #sym " %0 " #val : : "i" (val))arm里面寄存器r0,r1,r2,r3用于保存函数传入的形参,超过4个侧保存到栈中
eg:f(a,b,c,d)。a,b,c,d分别对应r0,r1,r2,r3
prev:表示即将被换下的进程(r0和r1里面保存了相关信息);next是即将被换上CPU的进程(r2表示)
/arch/arm/kernel/entry-armv.S
ENTRY(__switch_to)
UNWIND(.fnstart )
UNWIND(.cantunwind )
// ip = r1 + cpu_context偏移 <=> ip = prev->thread_info.cpu_context
add ip, r1, #TI_CPU_SAVE
//将r4 - sl, fp, sp, lr寄存器中的内容保存到IP寄存器所指向的内存地址,即prev->thread_info->cpu_context,这相当于保存了prev进程(即将被换下CPU的进程)运行时的寄存器上下文。从下面可以看到就是保存里面cpu_context_save里面所有的寄存器,lr被保存到了pc里面。
ARM( stmia ip!, {r4 - sl, fp, sp, lr} ) @ Store most regs on stack
//下面这个也是将值保存到ip所执行的内存地址。对了ip!,!表示最新的内存地址会被更新到寄存器ip中。
//此时ip指向了extra
//不知道为什么这个会保存两次
THUMB( stmia ip!, {r4 - sl, fp} ) @ Store most regs on stack
THUMB( str sp, [ip], #4 )
THUMB( str lr, [ip], #4 )
//将next->thread_info->tp_value[0]和tp_value[1]分别复制为r4和r5
ldr r4, [r2, #TI_TP_VALUE]
ldr r5, [r2, #TI_TP_VALUE + 4]
#ifdef CONFIG_CPU_USE_DOMAINS
ldr r6, [r2, #TI_CPU_DOMAIN]
#endif
switch_tls r1, r4, r5, r3, r7
#if defined(CONFIG_CC_STACKPROTECTOR) && !defined(CONFIG_SMP)
ldr r7, [r2, #TI_TASK]
ldr r8, =__stack_chk_guard
ldr r7, [r7, #TSK_STACK_CANARY]
#endif
#ifdef CONFIG_CPU_USE_DOMAINS
mcr p15, 0, r6, c3, c0, 0 @ Set domain register
#endif
mov r5, r0
add r4, r2, #TI_CPU_SAVE
ldr r0, =thread_notify_head
mov r1, #THREAD_NOTIFY_SWITCH
bl atomic_notifier_call_chain
#if defined(CONFIG_CC_STACKPROTECTOR) && !defined(CONFIG_SMP)
str r7, [r8]
#endif
THUMB( mov ip, r4 )
mov r0, r5
//“ARM( ldmia r4, {r4 - sl, fp, sp, pc} )” 将next->thread_info->cpu_context的数据加载到r4 - sl, fp, sp, lr,pc寄存器中,next->thread_info->cpu_context->sp存入寄存器SP相当于内核栈切换完成,next->thread_info->cpu_context->pc存入寄存器PC相当于跳转到next进程运行。即切换到next进程运行时的寄存器上下文。
ARM( ldmia r4, {r4 - sl, fp, sp, pc} ) @ Load all regs saved previously
THUMB( ldmia ip!, {r4 - sl, fp} ) @ Load all regs saved previously
THUMB( ldr sp, [ip], #4 )
THUMB( ldr pc, [ip] )
UNWIND(.fnend )
ENDPROC(__switch_to)struct cpu_context_save {
__u32 r4;
__u32 r5;
__u32 r6;
__u32 r7;
__u32 r8;
__u32 r9;
__u32 sl;
__u32 fp;
__u32 sp;
__u32 pc;
__u32 extra[2]; /* Xscale 'acc' register, etc */
};“ARM( ldmia r4, {r4 - sl, fp, sp, pc} )” 将next->thread_info->cpu_context的数据加载到r4 - sl, fp, sp, lr,pc寄存器中,next->thread_info->cpu_context->sp存入寄存器SP相当于内核栈切换完成,next->thread_info->cpu_context->pc存入寄存器PC相当于跳转到next进程运行。即切换到next进程运行时的寄存器上下文。这里的pc就是前面设置的reet_from_fork
./arch/arm/kernel/entry-header.S
下面这些都是寄存器的别名。tsk是r9的别名
scno .req r7 @ syscall number
tbl .req r8 @ syscall table pointer
why .req r8 @ Linux syscall (!= 0)
tsk .req r9 @ current thread_info
/*
* Get current thread_info.
*/
.macro get_thread_info, rd
ARM( mov \rd, sp, lsr #13 )
THUMB( mov \rd, sp )
THUMB( lsr \rd, \rd, #13 )
mov \rd, \rd, lsl #13
.endm
ENTRY(ret_from_fork)
bl schedule_tail
cmp r5, #0 /*copy_thread里面说了r5如果是0,则表示创建的是用户进程,反之是内核线程执行函数的地址 */
movne r0, r4/* 不为0,则将参数r4给r0 */
adrne lr, BSYM(1f)
movne pc, r5
/*
因此如果创建的是用户进程,上面的ne都不满足,直接到这里
get_thread_info tsk将r9设置为thread__info的起始地址
*/
1: get_thread_info tsk
b ret_slow_syscall
ENDPROC(ret_from_fork)ret_to_user返回到用户空间
ENTRY(ret_to_user)
ret_slow_syscall:
disable_irq @ disable interrupts
ENTRY(ret_to_user_from_irq)
ldr r1, [tsk, #TI_FLAGS]
tst r1, #_TIF_WORK_MASK
bne work_pending
no_work_pending:
asm_trace_hardirqs_on
/* perform architecture specific actions before user return */
arch_ret_to_user r1, lr
ct_user_enter save = 0
restore_user_regs fast = 0, offset = 0
ENDPROC(ret_to_user_from_irq)
ENDPROC(ret_to_user)“ARM( ldmia r4, {r4 - sl, fp, sp, pc} )” 将next->thread_info->cpu_context的数据加载到r4 - sl, fp, sp, lr,pc寄存器中,next->thread_info->cpu_context->sp存入寄存器SP相当于内核栈切换完成,next->thread_info->cpu_context->pc存入寄存器PC相当于跳转到next进程运行。即切换到next进程运行时的寄存器上下文。这里的pc就是前面设置的reet_from_fork
上面说__switch_to会切换当前进程和即将运行进程里的cpu_context里面保存的寄存器内容。那子进程是何时开始运行的呢?进行如下验证:
int printTwice = 10;
asmlinkage __visible void schedule_tail(struct task_struct *prev)
__releases(rq->lock)
{
struct rq *rq = this_rq();
finish_task_switch(rq, prev);
if (printTwice != 0)
{
printk(KERN_EMERG "\r\nfunc %s, line %d, new process, CPU: %d PID: %d Comm: %.20s \n", __FUNCTION__, __LINE__, raw_smp_processor_id(), current->pid, current->comm);
--printTwice;
}
}
static inline void
context_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next)
{
if (printTwice != 0)
{
printk(KERN_EMERG "\r\nfunc %s, line %d, before switch CPU: %d PID: %d Comm: %.20s \n", __FUNCTION__, __LINE__, raw_smp_processor_id(), current->pid, current->comm);
}
context_tracking_task_switch(prev, next);
/* Here we just switch the register state and the stack. */
switch_to(prev, next, prev);
if (printTwice != 0)
{
printk(KERN_EMERG "\r\nfunc %s, line %d, after switch, CPU: %d PID: %d Comm: %.20s\n", __FUNCTION__, __LINE__, raw_smp_processor_id(), current->pid, current->comm);
--printTwice;
}
}在switch_to(prev, next, prev);前后增加打印。另外即将会换上CPU的进程会去调用schedule_tail,这个函数里面也增加打印,看打印顺序。打印结果如下:
可以看到在switch_to返回之前,新的进程已经开始运行。switch_to返回之后,是调度器有重新调度到该进程了
“ARM( ldmia r4, {r4 - sl, fp, sp, pc} )” 将next->thread_info->cpu_context的数据加载到r4 - sl, fp, sp, lr,pc寄存器中,next->thread_info->cpu_context->sp存入寄存器SP相当于内核栈切换完成,next->thread_info->cpu_context->pc存入寄存器PC相当于跳转到next进程运行。即切换到next进程运行时的寄存器上下文。这里的pc就是前面设置的reet_from_fork
所以我感觉应该是在执行这句汇编指令后:ARM( ldmia r4, {r4 - sl, fp, sp, pc} ),新的进程就立马投入了运行。
THUMB( ldmia ip!, {r4 - sl, fp} ) @ Load all regs saved previously
THUMB( ldr sp, [ip], #4 )
THUMB( ldr pc, [ip] )在执行这几条指令的时候,多半是当前进程被重新调度的时候了。
func context_switch, line 2338, before switch CPU: 0 PID: 0 Comm: swapper/0
func schedule_tail, line 2278, new process, CPU: 0 PID: 2 Comm: swapper/0
func context_switch, line 2338, before switch CPU: 0 PID: 2 Comm: kthreadd
func schedule_tail, line 2278, new process, CPU: 0 PID: 1 Comm: swapper/0
func context_switch, line 2338, before switch CPU: 0 PID: 1 Comm: swapper/0
func context_switch, line 2345, after switch, CPU: 0 PID: 2 Comm: kthreadd
func context_switch, line 2338, before switch CPU: 0 PID: 2 Comm: kthreadd
func schedule_tail, line 2278, new process, CPU: 0 PID: 3 Comm: kthreadd
func context_switch, line 2338, before switch CPU: 0 PID: 3 Comm: kthreadd
func context_switch, line 2345, after switch, CPU: 0 PID: 1 Comm: swapper/0
func context_switch, line 2338, before switch CPU: 0 PID: 1 Comm: swapper/0
func context_switch, line 2345, after switch, CPU: 0 PID: 3 Comm: ksoftirqd/0
func context_switch, line 2338, before switch CPU: 0 PID: 3 Comm: ksoftirqd/0
func context_switch, line 2345, after switch, CPU: 0 PID: 1 Comm: swapper/0
func context_switch, line 2338, before switch CPU: 0 PID: 1 Comm: swapper/0
func context_switch, line 2345, after switch, CPU: 0 PID: 2 Comm: kthreadd
func context_switch, line 2338, before switch CPU: 0 PID: 2 Comm: kthreadd
func context_switch, line 2345, after switch, CPU: 0 PID: 3 Comm: ksoftirqd/0
func context_switch, line 2338, before switch CPU: 0 PID: 3 Comm: ksoftirqd/0
func schedule_tail, line 2278, new process, CPU: 0 PID: 4 Comm: kthreadd














 1383
1383











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









