







sklearn.metrics与分类问题度量指标
常使用 sklearn.metrics 提供的度量指标 API 来评估模型的分类效果,本文梳理了常用的几项指标的使用方法,包括调用接口、参数和输出值。
- 常用指标有准确率(accuracy)、精确率(precision)、召回率(recall)、F1值(fi-score)。
- 可选平均方法为
average:{None, 'micro', 'macro', 'samples', 'weighted', 'binary', default=binary} precision_recall_fscore_supportAPI 可以整合直接输出四个数值,分别是精确率、召回率、F1值和测试集中各类别的数量。
对几种 average 的解释如下:
- None:输出的一个array,里面是每个类单独的 score。
- binary:针对二分类问题,要求输入的 true_y 和 pred_y 都是二值的,即仅包含 0 和 1。
- micro 和 macro:针对多分类问题,一个为微观,一个为宏观。例如,micro-precision 和 macro-precision 计算方式如下:
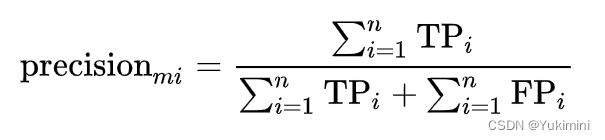
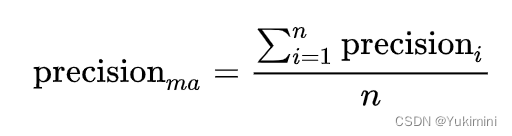
- weighted:‘weighted’ 方法对 ‘micro’ 和 ‘macro’ 进行了改进,每个类别计算出的 score 的权重是每个类别在测试集中所占的比例。
- samples:该方法针对多标签(multi-label)问题。
关于 Micro-F1 和 Macro-F1 的一些解释:
Micro-F1 :
- 计算方式:计算出所有类别总的 Precision 和 Recall ,然后计算出来的F1值即为 micro-F1,种方式被称为 micro-F1 微平均。
- 适用场景:在计算公式中考虑到了每个类别的数量,所以适用于数据分布不平衡的情况;但同时因为考虑到数据的数量,所以在数据极度不平衡的情况下,数量较多数量的类会较大的影响到 F1 的值;
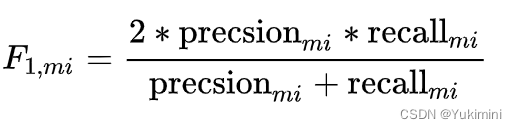
Macro-F1:
- 计算出每一个类的 Precison 和 Recall 后计算F1,这种方式叫做 Macro-F1 宏平均。
- 适用场景:没有考虑到数据的数量,所以会平等的看待每一类(因为每一类的 Precision 和 Recall 都在 0-1 之间),会相对受高 Precision 和高Recall 类的影响较大;
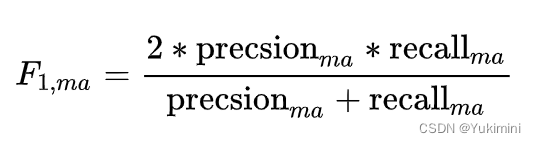
具体的引入包和使用 API 如下所示:
from sklearn.metrics import f1_score, precision_score, recall_score, precision_recall_fscore_support
print("f1_score:", f1_score(true_y, pred_y, average="weighted"))
print("precision_score:", precision_score(true_y, pred_y, average="weighted"))
print("recall_score:", recall_score(true_y, pred_y, average="weighted"))
print(precision_recall_fscore_support(true_y, pred_y, labels=[0,1,2,3,4,5])) # labels列表可以修改,和实际任务相符即可















 512
512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









