









文章目录
1. Self-supervising Fine-grained Region Similarities for Large-scale Image Localization
ECCV2020
1.1 Thinkings
这篇论文的motivation就在于目前公开的benchmarks 仅能 提供带有噪声的GPS坐标标签,以提供learning image-to-image similarities的弱监督。为了解决这个问题,论文的作者提出了一种自监督、细粒度的image-to-region similarities的学习方式,去充分挖掘difficult positive images和其子区域的潜力。
整篇论文的亮点有二:首先是这篇论文将self-supervision、self-knowledge distillation成功地扩展到了geo-localization的领域,其提出的自监督标签Query-gallery similarities of top ranking gallery images强调了difficult positive images对于网络训练的重要性;其次是这篇论文通过更进一步研究,将自监督标签从image-to-image换成了更细粒度的image-to-region。这样能够很好地缓解仅靠noisy GPS labels划分positive和negative images,而由于视角原因可能GPS很近的图像有区域并没有重合这种弱监督标签的问题。
总体来说论文的contributions如下:
- 将自监督和自我知识蒸馏扩展到geo-localization领域,提出了一种self-supervised similarities可以在不断地迭代中自我蒸馏网络,提高网络性能。
- 更进一步地将这个自监督的标签从image-to-image扩展到了更细粒度的image-to-region。
- 性能达到了sota,并且拥有很强的泛化能力(仅在Pitts30k-train上训练,就能在Tokyo 24/7和 Pitts250k-test上分别达到85.4和90.7R@1)
1.2 Principle Analysis

上图便是整个网络的训练过程,初始的时候考benchmarks提供的GPS label提供弱监督以训练网络,然后再用训练完成的网络输出自监督的image-to-region similarities labels去训练下一代的网络,然后就这样一代一代的自我蒸馏,最终完成训练。
1.2.1 Self-supervising Query-gallery Similarities
有了上面整个网络训练的过程,我们只需要知道作者提出的这个自监督标签如何计算,就能明白整篇论文的原理了,这里博主先介绍论文提出的image-to-image的自监督标签。
S θ 1 ( q , p 1 , ⋯ , p k ; τ 1 ) = s o f t m a x ( [ < f θ 1 q , f θ 1 p 1 > / τ 1 , ⋯ , < f θ 1 q , f θ 1 p k > / τ 1 ) S_{\theta_1}(q,p_1,\cdots,p_k;\tau_1) = softmax([<f^q_{\theta_1}, f^{p1}_{\theta_1}>/\tau_1, \cdots, <f^q_{\theta_1}, f^{pk}_{\theta_1}>/\tau_1) Sθ1(q,p1,⋯,pk;τ1)=softmax([<fθ1q,fθ1p1>/τ1,⋯,<fθ1q,fθ1pk>/τ1)
其中, < , > <,> <,>代表向量点乘, p 1 ⋯ p k p^1 \cdots p^k p1⋯pk代表topk的positive images, τ 1 \tau_1 τ1代表第一代训练的蒸馏温度, θ 1 \theta_1 θ1代表第一代训练的网络参数。
训练下一代的损失函数项如下:
L s o f t ( θ 2 ) = l c e ( S θ 2 ( q , p 1 , ⋯ , p k ; 1 ) , S θ 1 ( q , p 1 , ⋯ , p k ; τ 1 ) ) L_{soft}(\theta_2) = l_{ce}(S_{\theta_2}(q, p1, \cdots, pk;1), S_{\theta_1}(q, p_1, \cdots, p_k;\tau_1)) Lsoft(θ2)=lce(Sθ2(q,p1,⋯,pk;1),Sθ1(q,p1,⋯,pk;τ1))
其中, l c e ( , ) l_{ce}(,) lce(,)代表交叉熵。
1.2.2 Self-supervising Fine-grained Image-to-region Similarities
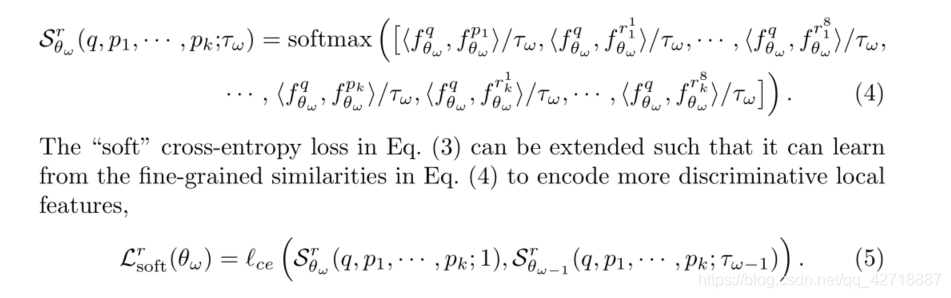
从image-to-image到更细粒度的image-to-region公式都是一样的,就多加入了几个region,从
r
1
⋯
r
8
r_1\cdots r_8
r1⋯r8分别是图像的 4 half regions and 4 quarter regions,所以公式博主就直接截图上去了,不再手敲了。
1.3 Trash Talk
这篇论文成功的将自监督和自我知识蒸馏扩展到geo-localization领域,这个创意是真滴比较可以。但是,后文提出将image-to-image扩展到image-to-region的region划分属实有点随意了,用一张图像的4 half regions and 4 quarter regions很难代表真正有意义的区域,并且有些有意义的区域形状还不一定是矩形。这一点如下图所示,从后面消融实验就能看出来,这样一张Query Image让两种方法都出错了,这就是因为这幅图的有意义区域除了那个墙以外,还有被树遮挡住了一部分的房子,而两者均对房子没啥兴趣。
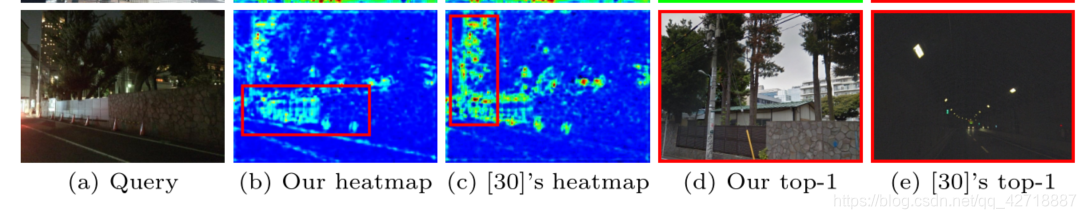
这一点mark一下,我感觉我后续可以把这种自监督和自蒸馏的过程融合到空间attention之中去进行改进。
2. Relation-Aware Global Attention for Persion Re-identification
CVPR2020
2.1 Thinkings
这是一篇Re-id中有关attention的论文,我在这里把它归到Geo-localization的论文阅读之中,主要是想mark一下这篇论文有关attention的思想。
首先,在Re-ID这个领域attention的机制可以加强鉴别特征(discriminate features)并且抑制不相关的特征。这一点和Geo-localization领域是类似的,即关注该关注的而抑制不该关注的,从而可以从图像中提取更加鲁棒的鉴别特征。
这篇文章的motivation就在于大多数的attention机制都是在有限的视角域之下,利用卷积去提取mask,这就导致了这样地attention无法关注到全局的结构信息。
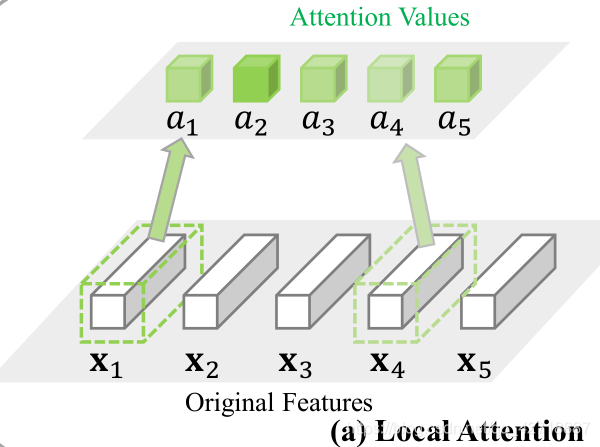
如上图所示,这里的
x
1
⋯
x
5
x_1 \cdots x_5
x1⋯x5就是输入图像经过卷积层之后得到的feature maps。每一个
x
i
x_i
xi就是一个长度为channel的向量,而它也只是由一小部分的视角域(limited receptive fields)经过卷积得到的,最后attention的值
a
i
a_i
ai也只是与
x
i
x_i
xi有关系,所以这种提取attention mask的操作就被叫做Local Attention。
后来为了利用特征的非局部信息去做attention,提出了Non-local block。
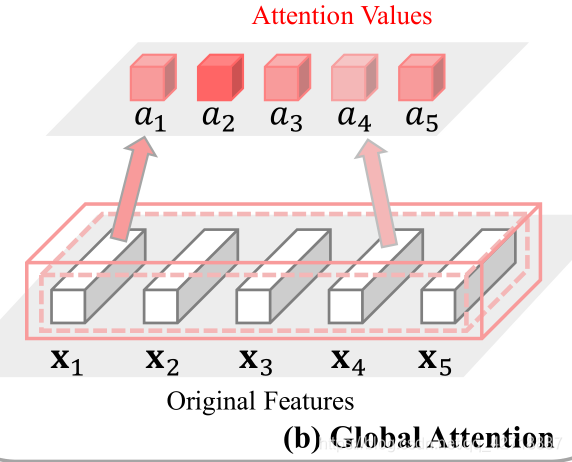
如上图所示,这就是Global Attention,具体原理我这里不做解释,可以移步到这篇博客Non-local neural networks。
本论文的作者认为,虽然上述的Global Attention利用到了全局的信息,但是缺乏显示地特征关系的挖掘(relation exploration)。这也是本论文Relation-Aware(关系感知)的由来。
总体来说,本论文的contributions如下:
- 设计了一个关系感知的全局attention模块(relation-aware global attention, RGA)
2.2 Principle Analysis
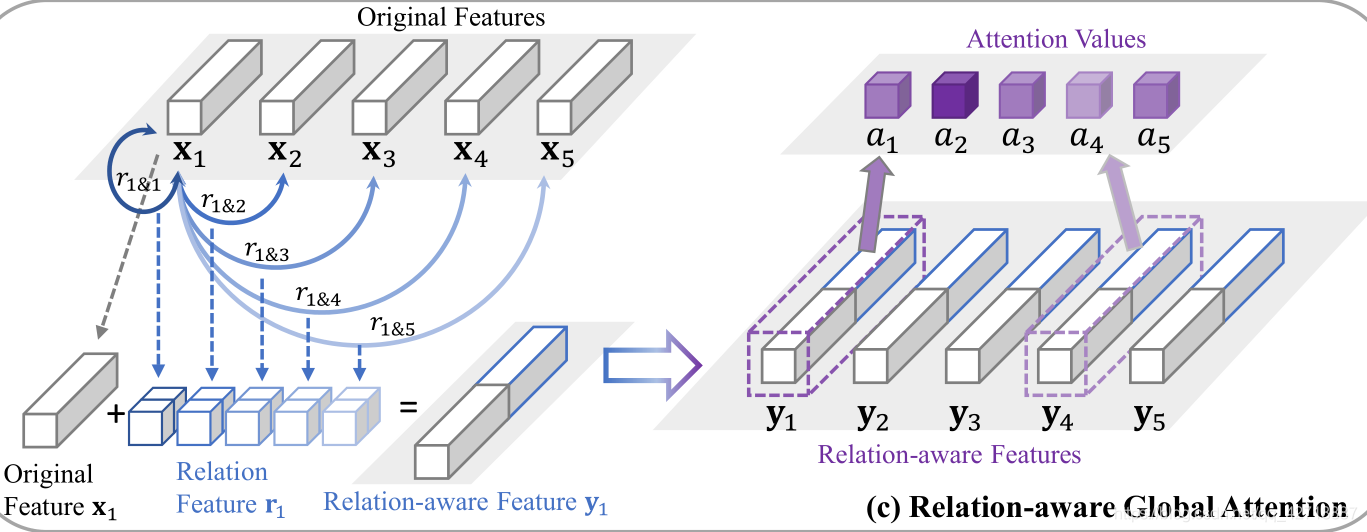
如上图所示,这里是整个模块的概念模型。首先为了得到关系感知特征
y
i
y_i
yi,就需要把原始的
x
i
x_i
xi特征与关系特征
r
i
r_i
ri进行concat操作。关系特征
r
i
r_i
ri则是集合
{
r
i
&
r
j
,
j
∈
{
1
,
2
,
3
⋯
n
}
}
\{r_i \&r_j, j∈\{1, 2, 3 \cdots n \} \}
{ri&rj,j∈{1,2,3⋯n}}。有了关系感知特征
y
i
y_i
yi之后再去学习attention。下面我将介绍具体算法Spatial Relation-Aware Global Attention(RGA-S)和Channel Relation-Aware Global Attention(RGA-C),即空间关系感知和通道关系感知这两种全局attention算法。
2.2.1 Spatial Relation-Aware Global Attention
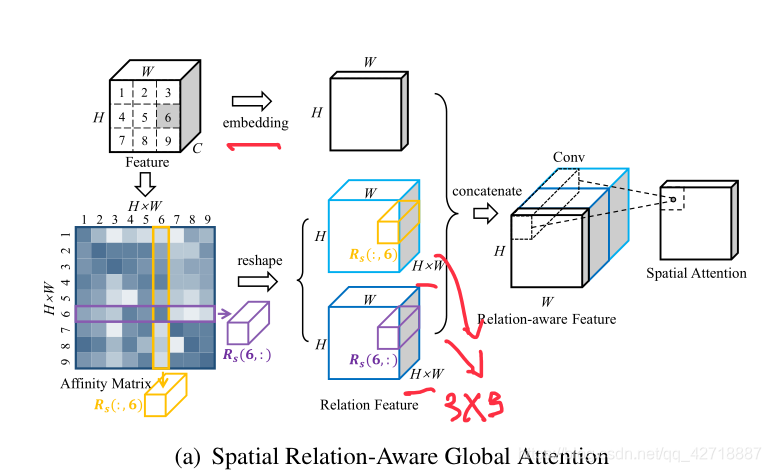
首先把这个
H
×
W
H \times W
H×W的Feature通过embedding(具体实现是一个1 by 1的卷积操作)操作得到一个
H
×
W
H \times W
H×W的中间特征,再利用Feature去提取Affinity Matrix,代表Feature中每一个feature node之间一一对应的关系。比如这里的
R
s
(
6
,
:
)
R_s(6, :)
Rs(6,:)就代表第6个feature node与其他feature node之间的关系大小,
R
s
(
:
,
6
)
R_s(:, 6)
Rs(:,6)就代表其他feature node与第6个feature node之间的关系大小。关系大小的计算公式如下,其实就是用的non-local block那篇论文提出的一种叫Dot Product关系计算公式:
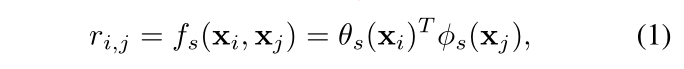
再把得到的三个中间特征(一个原始特征经过embedding变换的特征+两个空间关系感知特征)concat起来,最后把这个concat的特征输入一个1 by 1的卷积就可以提取空间attention了。
2.2.2 Channel Relation-Aware Global Attention
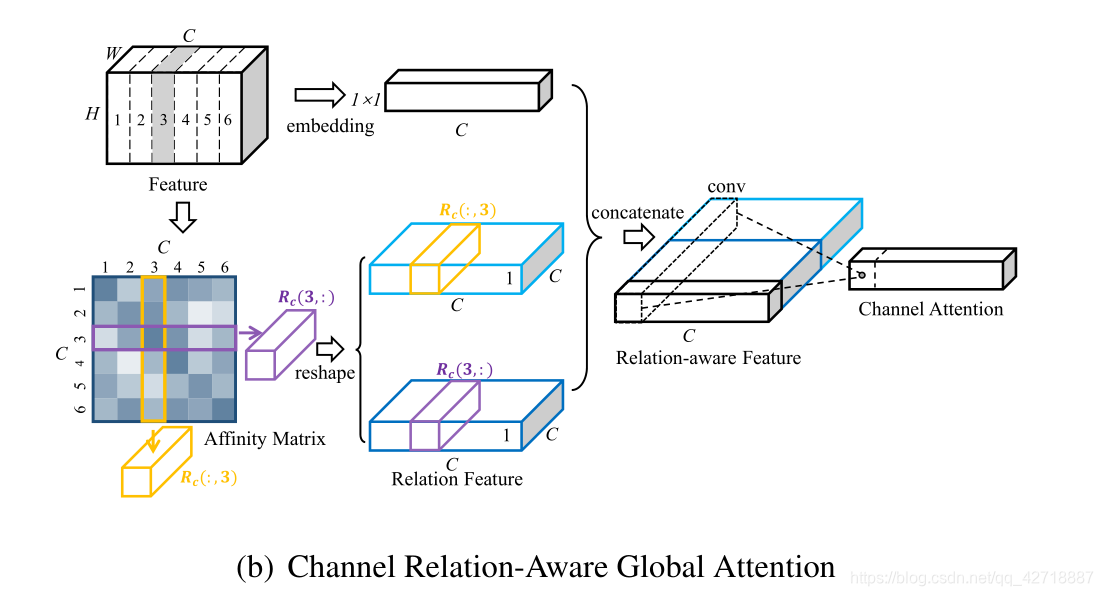
如上图所示,这里的通道关系感知模型和前面的思路一模一样,只是将空间关系改成了通道关系,所以不再进行赘述。
3. Uncertainty-Aware Multi-Shot Knowledge Distillation for Image-Based Object Re-Identification
3.1 Thinkings
这一篇论文也是做基于图像的物体Re-id,提出了利用知识蒸馏(knowledge distillation)的方式,在训练的时候利用teacher network去挖掘多角度图像的信息,再教授给student network,而在inference的时候,仅利用student network输入单角度图像,从而达到提升精度而又不增加inference的复杂度的效果。
除了上述知识蒸馏的引入以外,从本文的标题中的Uncertainty-Aware还可以看出来本文为了能够高效地将知识从老师网络转移到学生网络,还考虑了数据依赖的异方差不确定性(Heteroscedastic uncertainty)。
总体来说,本论文的主要贡献在于以下两点:
-
提出了一个Uncertainty-Aware Multi-shot Teacher-Student Network(UMTS) 去充分挖掘多角度照片的有用信息,而在推理时只利用单角度照片,从而不会增加推理的计算成本。
-
考虑了数据依赖的异方差不确定性,并根据它设计了一个Uncertainty-aware Knowledge Distillation Loss(UA-KDL)。
3.2 Principle Analysis
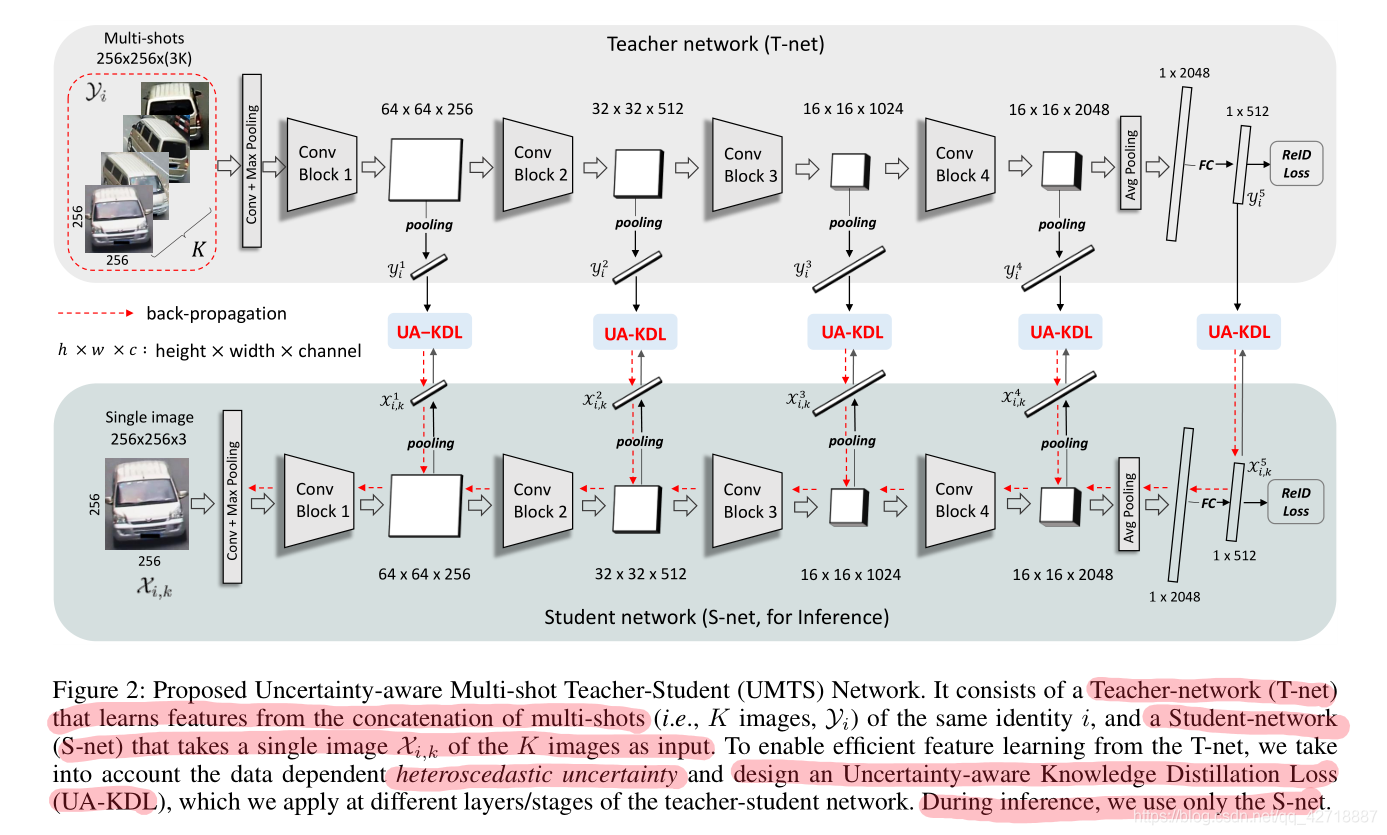
3.2.1 Input
如上图所示,首先我们来说明一下Teacher and Student networks的输入。对于第i个实体,论文选择了这个实体的k个角度图像,即 S i = { X i , 1 , ⋯ , X i , k } S_i = \{X_{i, 1}, \cdots, X_{i, k}\} Si={Xi,1,⋯,Xi,k}, where X i , k ∈ R H × W × 3 X_{i,k}∈R^{H \times W \times 3} Xi,k∈RH×W×3, 然后将 S i S_i Si中的X按照通道concat得到 Y i , Y i ∈ R H × W × 3 K Y_i, Y_i∈R^{H \times W \times 3K} Yi,Yi∈RH×W×3K。 < Y i , X i , k > <Y_i, X_{i,k}> <Yi,Xi,k>就组成了一个teacher-student训练pair,前者是老师网络的输入,后者是学生网络的输入。
3.2.2 Knowledge Transfer with UA-KDL
接下来我们来看论文设计的UA-KDL这个loss。如上图所示,作者在teacher-student network前向传播的时候设置了5个阶段的UA-KDL计算。第b个阶段基础的KDL公式如下:
L
(
i
,
k
)
b
=
∣
∣
θ
t
b
(
y
i
b
)
−
θ
s
b
(
x
i
,
k
b
)
∣
∣
2
(1)
L^b_{(i, k)} = || \theta^b_t(y^b_i) - \theta^b_s(x^b_{i,k}) ||^2 \tag{1}
L(i,k)b=∣∣θtb(yib)−θsb(xi,kb)∣∣2(1)
L
(
i
,
:
)
b
=
∑
k
=
1
K
∣
∣
θ
t
b
(
y
i
b
)
−
θ
s
b
(
x
i
,
k
b
)
∣
∣
2
(2)
L^b_{(i, :)} = \sum^K_{k=1} || \theta^b_t(y^b_i) - \theta^b_s(x^b_{i,k}) ||^2 \tag{2}
L(i,:)b=k=1∑K∣∣θtb(yib)−θsb(xi,kb)∣∣2(2)
其中,
θ
t
b
(
.
)
、
θ
s
b
(
.
)
\theta^b_t(.)、\theta^b_s(.)
θtb(.)、θsb(.)就是将第b阶段teacher和student输出的特征向量投影到同一个空间的embedding function,具体实现就是FC->BN->ReLU。
对于re-id来说,不同的实体图像有着不同的可视物体区域,遮挡,图像质量等等,所以需要网络能从K个角度的图像中稳定地获取知识就需要引入不确定分析(uncertainty analysis)。所以,论文设计的UA-KDL公式如下:
L
U
K
D
(
i
,
:
)
b
=
∑
k
=
1
K
1
2
σ
b
(
y
i
b
,
x
i
,
k
b
)
2
∣
∣
θ
t
b
(
y
i
b
)
−
θ
s
b
(
x
i
,
k
b
)
∣
∣
2
+
l
o
g
σ
b
(
y
i
b
,
x
i
,
k
b
)
(3)
L^b_{UKD(i, :)} = \sum^K_{k=1} \frac{1}{2\sigma_b(y^b_i, x^b_{i,k})^2} || \theta^b_t(y^b_i) - \theta^b_s(x^b_{i,k}) ||^2 + log\sigma_b(y^b_i, x^b_{i,k}) \tag{3}
LUKD(i,:)b=k=1∑K2σb(yib,xi,kb)21∣∣θtb(yib)−θsb(xi,kb)∣∣2+logσb(yib,xi,kb)(3)
其中, σ b ( y i b , x i , k b ) \sigma_b(y^b_i, x^b_{i,k}) σb(yib,xi,kb)就代表了捕捉异方差不确定性的观测噪音。当然,把这个东西引入到深度学习里面肯定就不是直接利用 y i b , x i , k b y^b_i, x^b_{i,k} yib,xi,kb这两个量去计算了。论文采用的方法是利用深度学习的算法对 l o g σ b ( y i b , x i , k b ) 2 log\sigma_b(y^b_i, x^b_{i,k})^2 logσb(yib,xi,kb)2进行建模计算。公式如下:
l o g σ b ( y i b , x i , k b ) 2 = R e L U ( w b [ θ t b ( y i b ) , θ s b ( x i , k b ) ] ) log\sigma_b(y^b_i, x^b_{i,k})^2 = ReLU(w_b[\theta_t^b(y^b_i),\theta^b_s(x^b_{i,k})]) logσb(yib,xi,kb)2=ReLU(wb[θtb(yib),θsb(xi,kb)])
其中,[. , .]代表了concat操作, w b w_b wb代表了一个全连接网络,把concat之后的向量转换为一个标量。至于为什么要对log进行建模,原文解释如下:Predicting the log of uncertainty is more numerically stable than predicting σ b \sigma_b σb , since this avoids a potential division by zero



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









