







MMCV学习——基础篇4(Hook)
Hook机制在MMCV的各个开源库中应用的十分广泛,它主要用于管理和扩展Runner的整个生命周期。通过Hook机制在Runner的各个生命周期节点调用自定义的函数,可以实现丰富的定制功能。
文章目录
1. 从观察者模式谈起
Hook本身是一种程序设计的机制,并不是某种语言或者框架独有的。在程序设计模式中,有一种模式叫观察者模式就可以通过Hook机制去实现。观察者模式描述的是被观察者(Subject)和观察者(Observer)之间的一对多关系,在观察者不需要知道被观察者是谁的情况下,将被观察者的状态改变推送到观察者这里。
1.1 课程更改,学生如何知道?
下面我们通过一个简单的场景代码来介绍观察者模式:假设一群人订阅了一门课程,如果课程有内容更新,如何比较优雅地让这群人知道这门课程更新了呢?我们天然的方案可能是,每个人定期查询一下课程看看是否更新,但是这样做会导致每隔一段时间大量用户去访问一个课程,显然这样是不合理并且浪费资源的。
所以我们在这里引入观察者模式,仅仅在被观察者(Subject)和观察者(Observer)之间建立一个抽象的耦合关系,就可以做到让观察者及时感知到被观察者的变化。首先,我们先定义一个Subject(课程)类:
class Subject(object):
def __init__(self, state: int) -> None:
self._state = state
self._observers = []
@property
def state(self) -> int:
return self._state
@state.setter
def state(self, state: int):
print('===== start change state! =====')
old_state = self._state
self._state = state
self.notify_observers(old_state)
print('===== end change state! =====')
@property
def observers(self):
# read-only property
return self._observers
def attach(self, observer):
self._observers.append(observer)
def detach(self, observer):
self._observers.remove(observer)
def notify_observers(self, old_state):
for observer in self._observers:
observer.update(old_state)
def __str__(self) -> str:
return f'Subject(state: {self._state})'
Subject类有一个state(状态)和observers(观察者列表)实例属性。- 要实现观察者模式,
Subject就需要实现notify_observers方法,在state发生改变时通知所有观察者。 - attach和detach方法用来管理观察者列表。
然后再定义一个Observer(观察者)类:
class Observer(object):
def __init__(self, name: str, subject: Subject) -> None:
self._name = name
self._subject = subject
self._subject.attach(self)
@property
def name(self):
# read-only
return self._name
@property
def subject(self):
# read-only
return self._subject
def update(self, old_state):
print(f'{self._name}: subject from {old_state} to {self._subject.state}')
def __str__(self) -> str:
return f'Observer(name: {self._name}, subject: {self._subject})'
Observer类有一个name(名字)和subject(课程)只读实例属性。- 要实现观察者模式,
Observer就需要实现update方法以供Subject在notify_observers中调用。
接下来我们来写一段Running script运行一下观察者模式的示例代码:
if __name__ == '__main__':
subject = Subject(1)
observers = [Observer(name, subject) for name in ['Tom', 'Ben', 'Jerry']]
subject.state = 2
print('Now detach Tom and change the state!')
subject.detach(observers[0])
subject.state = 3
'''
Output:
===== start change state! =====
Tom: subject from 1 to 2
Ben: subject from 1 to 2
Jerry: subject from 1 to 2
===== end change state! =====
Now detach Tom and change the state!
===== start change state! =====
Ben: subject from 2 to 3
Jerry: subject from 2 to 3
===== end change state! =====
'''
1.2 观察者模式到底与Hook有什么关系?
上面的观察者设计模式的实现依赖于Subject和Observer两个类,但是如果有些时候我们只是想在Subject状态改变的时候唤起某个自定义的函数,而不想费这么大功夫去专门去写个Observer类的时候该怎么做呢?对于Python来说,函数是里面的一等公民,所以我们可以按照下面的方式去实现观察者设计模式:
from functools import partial
class Subject(object):
def __init__(self, state: int) -> None:
self._state = state
self._hooks = []
@property
def state(self) -> int:
return self._state
@state.setter
def state(self, state: int):
print('===== start change state! =====')
old_state = self._state
self._state = state
self.notify_hooks(old_state)
print('===== end change state! =====')
def attach(self, hook):
self._hooks.append(hook)
def detach(self, hook):
self._hooks.remove(hook)
def notify_hooks(self, old_state):
for hook in self._hooks:
hook(old_state)
def __str__(self) -> str:
return f'Subject(state: {self._state})'
def obs_hook(old_state, name, subject):
print(f'{name}: subject from {old_state} to {subject.state}')
if __name__ == '__main__':
subject = Subject(1)
hook0 = partial(obs_hook, name='Tom', subject=subject)
print(type(hook0))
subject.attach(hook0)
# Now change the state of subject
subject.state = 2
'''
Output:
<class 'functools.partial'>
===== start change state! =====
Tom: subject from 1 to 2
===== end change state! =====
Now detach Tom and change the state!
'''
- 我们将
Observer这个类在这里简化成了一个obs_hook函数,并通过partial工具给obs_hook函数绑定name和subject参数。 - 在
Subject的state的setter方法中去激活所有注册的Hook函数并执行。
2. MMCV中的Hook
MMCV这类第三方框架都会按照工作流程进行一定程度地抽象并归纳出一套通用的执行流程(Runner),但是对于第三方框架的开发者来说,并不知道我们用户在使用这个框架时碰到的具体问题,所以既要保证开发时框架的通用性,又要保证使用时用户可以定制化地修改框架的部分逻辑,就需要用到Hook函数了。
2.1 MMCV Runner的生命周期与Hook
如下图所示,MMCV Runner的生命周期大体上分为这6个阶段,每个阶段都可以插入Hook从而实现扩展功能。当然,Runner中还涉及到了训练(train)和验证(val)模式,可以按照不同的模式划分不同的阶段,具体可以参看MMCV Hook源码。
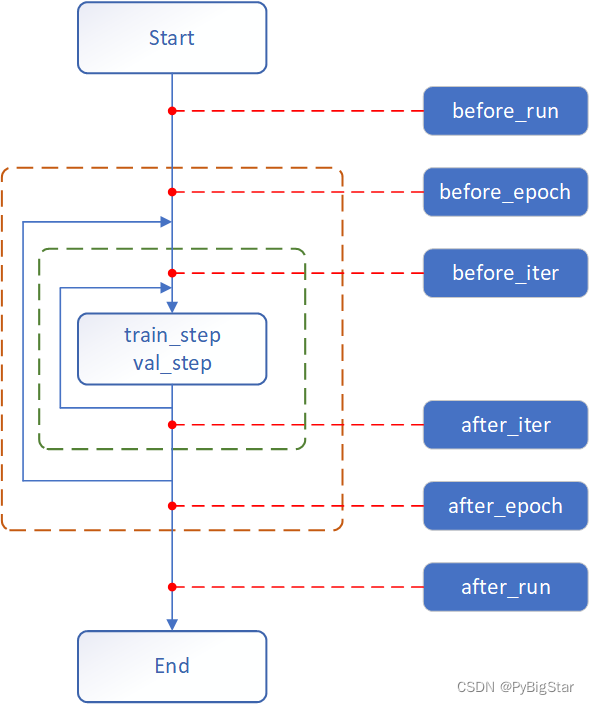
下面的代码以EpochBasedRunner为例展示了Runner调用hook的基本流程,用户要做的只是在各个点位注册好自己写的Hook函数就可以实现自定义的功能:
# 运行前准备工作
before_run()
while self.epoch < self._max_epochs:
# 开始 epoch 迭代前调用
before_train_epoch()
for i, data_batch in enumerate(self.data_loader):
# 开始 iter 迭代前调用
before_train_iter()
self.model.train_step()
# 经过一次迭代后调用
after_train_iter()
# 经过一个 epoch 迭代后调用
after_train_epoch()
# 运行完成后调用
after_run()
2.2 MMCV的Hook分类
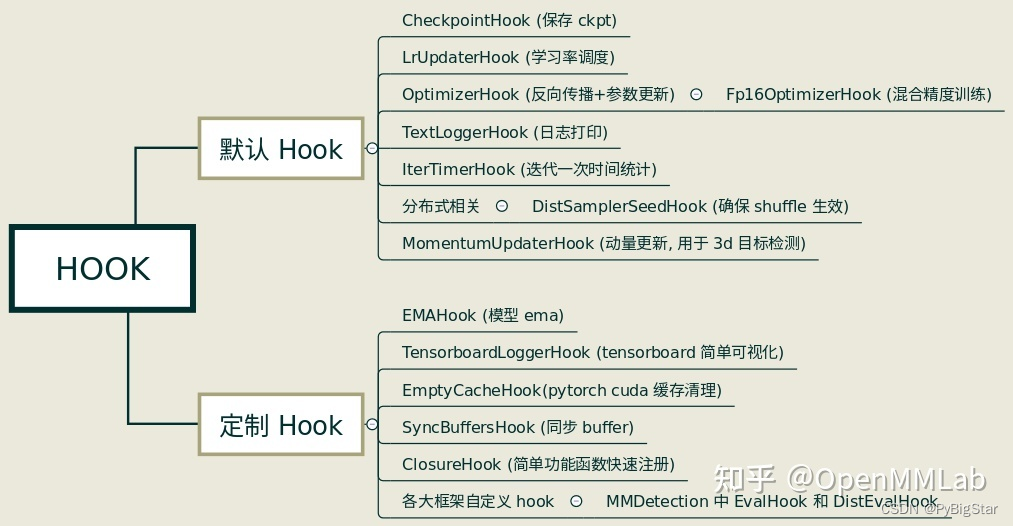
上图是在MMCV官方分享的知乎上拿来的一张Hook分类图,可以看到MMCV中Hook可以分为默认和定制Hook两类。其各自的相关功能图上也写的很清楚了。如果想知道更细节一点的各类Hook的功能实现可以参看MMCV常用 Hook 类简析。
2.3 如何自定义Hook?
用户如果想要自定义一个Hook就可以选择继承基类或者利用ClosureHook快速注册。如果是选择继承的方式自定义Hook,就需要创建子类去重写插入阶段的函数,下面是v1.7.0版本Hook基类的部分源代码:
# Copyright (c) OpenMMLab. All rights reserved.
from mmcv.utils import Registry, is_method_overridden
HOOKS = Registry('hook')
class Hook:
stages = ('before_run', 'before_train_epoch', 'before_train_iter',
'after_train_iter', 'after_train_epoch', 'before_val_epoch',
'before_val_iter', 'after_val_iter', 'after_val_epoch',
'after_run')
def before_run(self, runner):
pass
def after_run(self, runner):
pass
def before_epoch(self, runner):
pass
def after_epoch(self, runner):
pass
def before_iter(self, runner):
pass
def after_iter(self, runner):
pass
def before_train_epoch(self, runner):
self.before_epoch(runner)
def before_val_epoch(self, runner):
self.before_epoch(runner)
def after_train_epoch(self, runner):
self.after_epoch(runner)
def after_val_epoch(self, runner):
self.after_epoch(runner)
def before_train_iter(self, runner):
self.before_iter(runner)
def before_val_iter(self, runner):
self.before_iter(runner)
def after_train_iter(self, runner):
self.after_iter(runner)
def after_val_iter(self, runner):
self.after_iter(runner)
...
- 为了方便模块管理和从config构建自定义Hook,除了需要继承Hook基类,还需要用
@HOOKS.register_module()去注册模块。
写好了自定义的Hook,就可以创建实例并注册到runner实例中使用了,MMCV中BaseRunner提供了register_hook按照priority优先级方法注册自定义的Hook。
def register_hook(self,
hook: Hook,
priority: Union[int, str, Priority] = 'NORMAL') -> None:
"""Register a hook into the hook list.
The hook will be inserted into a priority queue, with the specified
priority (See :class:`Priority` for details of priorities).
For hooks with the same priority, they will be triggered in the same
order as they are registered.
Args:
hook (:obj:`Hook`): The hook to be registered.
priority (int or str or :obj:`Priority`): Hook priority.
Lower value means higher priority.
"""
assert isinstance(hook, Hook)
if hasattr(hook, 'priority'):
raise ValueError('"priority" is a reserved attribute for hooks')
priority = get_priority(priority)
hook.priority = priority # type: ignore
# insert the hook to a sorted list
inserted = False
for i in range(len(self._hooks) - 1, -1, -1):
if priority >= self._hooks[i].priority: # type: ignore
self._hooks.insert(i + 1, hook)
inserted = True
break
if not inserted:
self._hooks.insert(0, hook)
- 对于那几个训练过程中需要用到的默认Hook,
BaseRunner也提供了register_training_hooks去修改它们。


















 686
686

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









