







一、基础知识
1 集成学习方法(ensemble method)(一类而非一个算法)
通过组合多个弱基分类器来实现强分类器目的,从而提高分类性能。基分类器一般采用的是弱可学习(weakly lear)分类器,通过集成方法,组合成强可学习(strongly learnable)分类器。所谓弱可学习,是指学习的正确率仅略优于随机猜测的多项式学习算法;强可学习指正确率较高的多项式学习算法。集成学习是一类算法,而不是指一个算法。集成学习策略有非常多种,包括数据层面、模型层面和算法层面三个方面集成。查看博硕论文。常用的两种集成学习方法是:bagging袋装法,典型代表随机森林(Random Forests)和boosting提升法,典型代表GBDT(Gradient Boosting Decision Tree)以及非常火热的XGBoost。
2 bagging集成学习方法(并行)
自举汇聚法(bootstrap aggregating),也称为bagging方法。Bagging对训练数据采用自举采样(boostrap sampling),即有放回地采样数据,主要思想:
- 从原始样本集中抽取训练集。每轮从原始样本集中使用Bootstraping的方法抽取n个训练样本(在训练集中,有些样本可能被多次抽取到,而有些样本可能一次都没有被抽中)。共进行k轮抽取,得到k个训练集。(k个训练集之间是相互独立的)
- 每次使用一个训练集得到一个模型,k个训练集共得到k个模型。(注:这里并没有具体的分类算法或回归方法,我们可以根据具体问题采用不同的分类或回归方法,如决策树、感知器等)
- 对分类问题:将上步得到的k个模型采用投票的方式得到分类结果;对回归问题,计算上述模型的均值作为最后的结果。(所有模型的重要性相同)

3 boosting集成学习方法(串行)
Boosting是一种与Bagging很类似的技术。Boosting的思路则是采用重赋权(re-weighting)法迭代地训练基分类器,主要思想:
- 每一轮的训练数据样本赋予一个权重,并且每一轮样本的权值分布依赖上一轮的分类结果。
- 基分类器之间采用序列式的线性加权方式进行组合。

4 bagging和boosting区别和联系
样本选择上:
- Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
- Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
样例权重:
- Bagging:使用均匀取样,每个样例的权重相等。
- Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
预测函数:
- Bagging:所有预测函数的权重相等。
- Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
并行计算:
- Bagging:各个预测函数可以并行生成。
- Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
下面是将决策树与这些算法框架进行结合所得到的新的算法:
- Bagging + 决策树 = 随机森林
- AdaBoost + 决策树 = 提升树
- Gradient Boosting + 决策树 = GBDT
二、AdaBoost
AdaBoost算法是基于Boosting思想的机器学习算法,AdaBoost是adaptive boosting(自适应boosting)的缩写,其运行过程如下:
1 计算样本权重
训练数据中的每个样本,赋予其权重,即样本权重,用向量D表示,这些权重都初始化成相等值。假设有n个样本的训练集: ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x n , y n ) {(x_1,y_1),(x_2,y_2),...,(x_n,y_n)} (x1,y1),(x2,y2),...,(xn,yn)设定每个样本的权重都是相等的,即1/n。
2 计算错误率
利用第一个弱学习算法h1对其进行学习,学习完成后进行错误率ε的统计: ε = 未 正 确 分 类 的 样 本 数 目 所 有 样 本 数 目 ε={未正确分类的样本数目\over所有样本数目} ε=所有样本数目未正确分类的样本数目
3 计算弱学习算法权重
弱学习算法也有一个权重,用向量α表示,利用错误率计算权重α: α = 1 2 l n ( 1 − ε ε ) α={1\over2}ln({1-ε\overε}) α=21ln(ε1−ε)
4 更新样本权重
在第一次学习完成后,需要重新调整样本的权重,以使得在第一分类中被错分的样本的权重,在接下来的学习中可以重点对其进行学习:
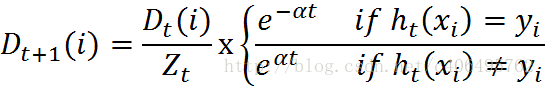 其中,h_t(x_i) = y_i表示对第i个样本训练正确,不等于则表示分类错误。Z_t是一个归一化因子:
其中,h_t(x_i) = y_i表示对第i个样本训练正确,不等于则表示分类错误。Z_t是一个归一化因子:
 这个公式我们可以继续化简,将两个公式进行合并,化简如下:
这个公式我们可以继续化简,将两个公式进行合并,化简如下:
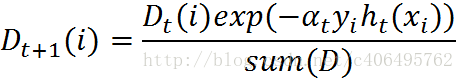
5 AdaBoost算法
重复进行学习,这样经过t轮的学习后,就会得到t个弱学习算法、权重、弱分类器的输出以及最终的AdaBoost算法的输出,分别如下:
 其中,sign(x)是符号函数。具体过程如下所示:
其中,sign(x)是符号函数。具体过程如下所示:


6 AdaBoost算法原理优缺点
优点:泛化错误率低,易编码,可以应用在大部分分类器上,无参数调整
缺点:对离群点敏感
由于AdaBoost是boosting的改进方法,而且性能比较稳定,故而在实践中一般都直接使用AdaBoost而不会使用原始的boosting。















 634
634











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









