






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
本文转自|3D视觉工坊
1、Arbitrary-Oriented Scene Text Detection via Rotation Proposals
主要思想
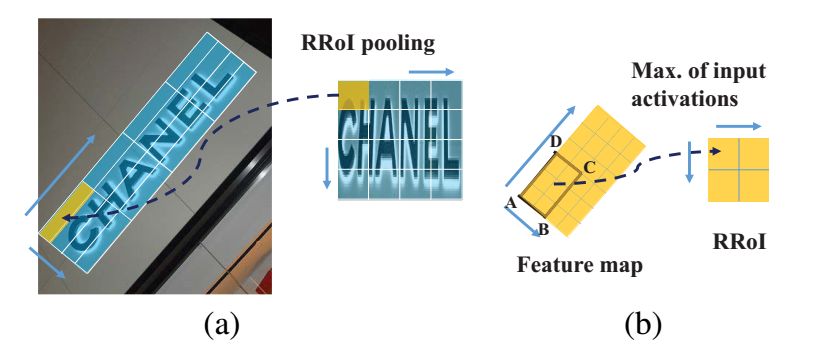
介绍了一种基于旋转的新颖网络框架,用于自然场景图像中面向任意方向的文本检测。论文的主要思想为旋转区域提案网络(RRPN),该网络旨在生成带有文本方向角度信息的倾斜proposal,并将角度信息用于边界框回归,以使proposal在方向方面更准确地适合文本区域。除此之外,还提出了旋转兴趣区域(RRoI)池化层,以将任意方向的proposal投影到feature map上供分类器进行分类。与以前的文本检测系统相比,基于region proposal的体系结构确保了面向任意方向的文本检测的计算效率。
主要创新点
1、与以往的基于分割的框架不同,论文中的框架能够使用基于区域建议的方法来预测文本行的方向,因此,proposals可以更好地适应文本区域,并且文本区域范围可以很容易地被纠正,更便于文本阅读。
2、提出了改进任意方向区域建议的新策略,以提高任意方向文本检测的性能。
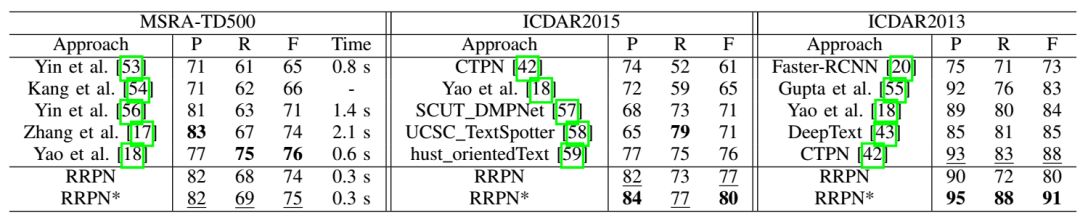
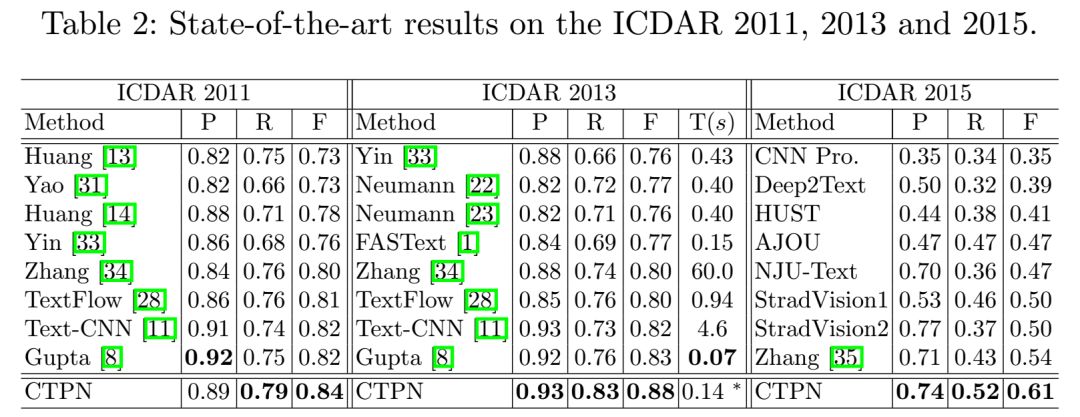
3、在MSRA-TD500、ICDAR2013和ICDAR2015数据集上,与以前的方法相比,本文提出的网络更加准确和高效
网络结构
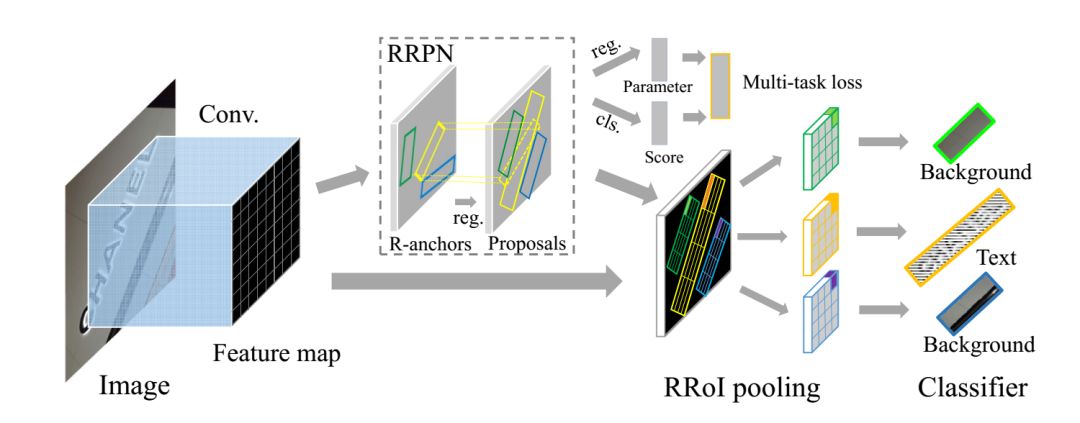
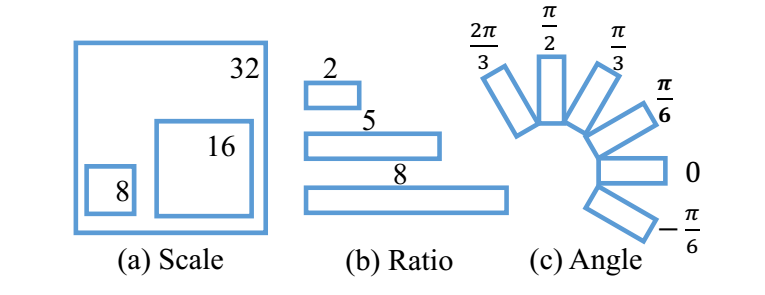
可以看出,思路和Faster RCNN的相似,下图是anchor的设计方式,3个scale和3个Ratio,旋转角度范围在-π/6~2π/3
实验结果

2、Deep Direct Regression for Multi-Oriented Scene Text Detection
主要思想
提出了一种基于深度直接回归的多方向场景文本检测方法。检测框架简单有效,具有全卷积网络和后处理。对全卷积网络进行端到端的优化,实现了文本与非文本像素级分类和直接回归文本边界顶点坐标的双任务输出。
主要贡献
1、直接回归的多方向场景文本检测
2、pipeline只有两个部分,其中一个是卷积神经网络,另一个是一步后处理调用召回非最大抑制。删除了诸如行分组和字分区之类的模块,从而节省了大量调整参数的工作。
3、由于本文的方法可以预测不规则的四边形边界,所以在需要定位每个字级文本的四个顶点的附带文本检测任务中具有很大的优势
网络结构
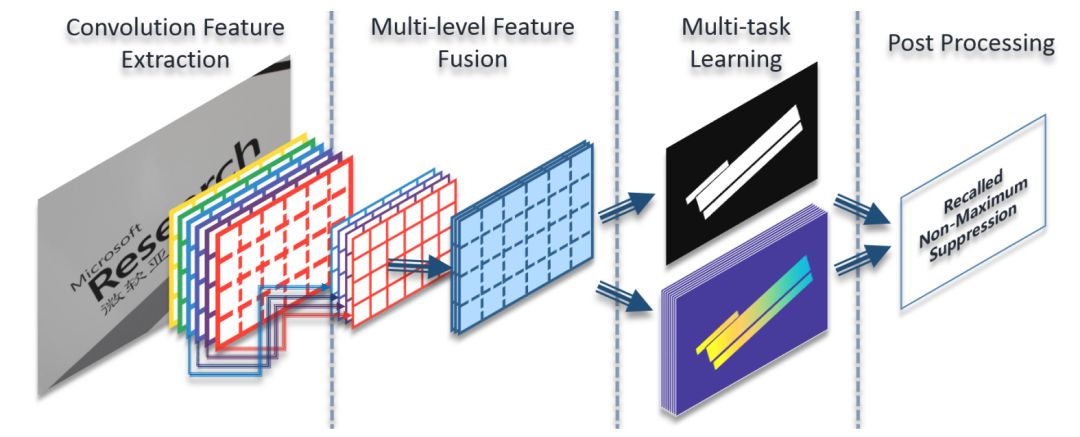
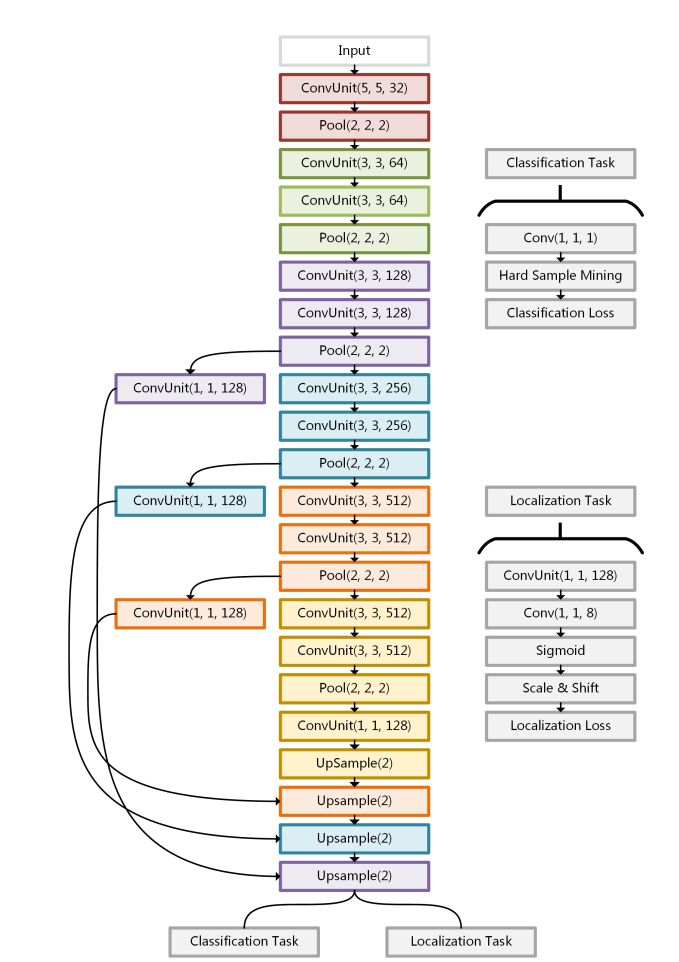
实验结果


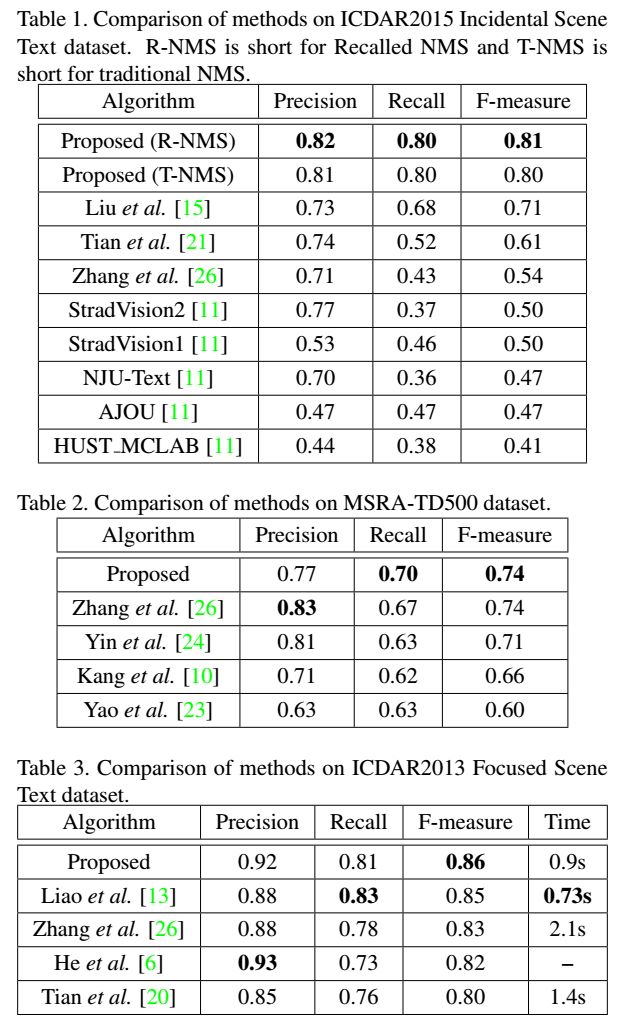
3、Deep Matching Prior Network: Toward Tighter Multi-oriented Text Detection
主要思想
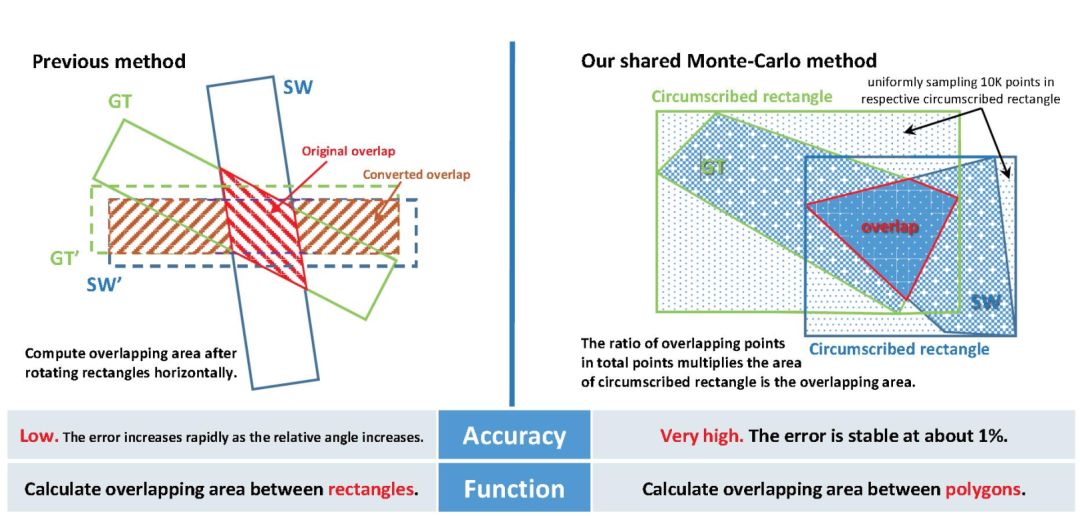
由于文本的多方向性、透视失真以及文本大小、颜色和比例的变化,对incidental scene文本的检测是一项具有挑战性的任务。前期的研究主要集中在使用矩形包围盒或水平滑动窗口进行文本定位,这可能会导致冗余的背景噪声、不必要的重叠甚至信息丢失。针对这些问题,本文提出了一种新的基于卷积神经网络(CNNs)的文本检测方法,称为深度匹配先验网络(DMPNet)。首先在多个特定的中间卷积层中使用四边形滑动窗口对重叠区域较大的文本进行粗略的检测,然后提出一种共享蒙特卡罗方法,用于快速准确地计算多边形区域。在此基础上,设计了一个相对回归的序贯协议,该协议能够精确地预测具有紧凑四边形的文本。此外,还提出了一种辅助平滑LN Loss以进一步恢复文本的位置,在鲁棒性和稳定性方面比L2损失和smooth L1损失具有更好的整体性能。
主要贡献
1、首先提出了先验四边形滑动窗口,显著提高了召回率。
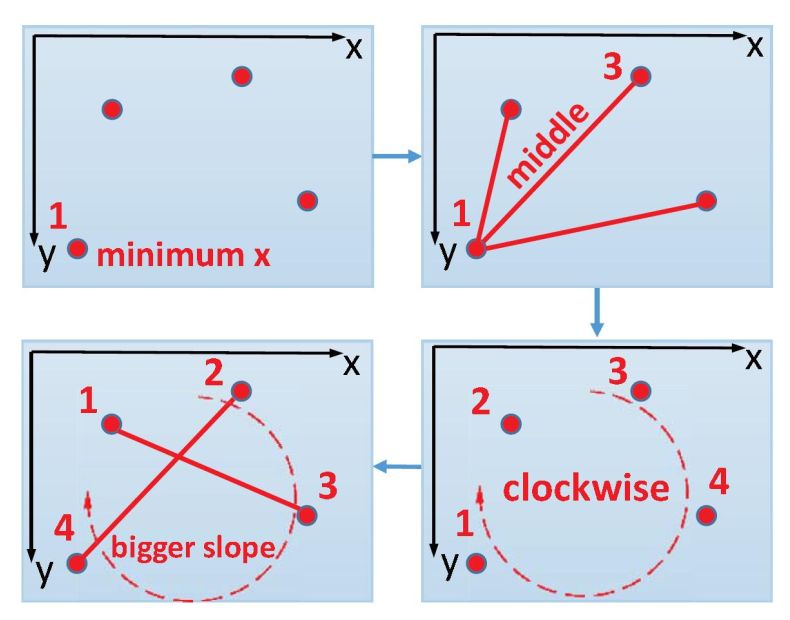
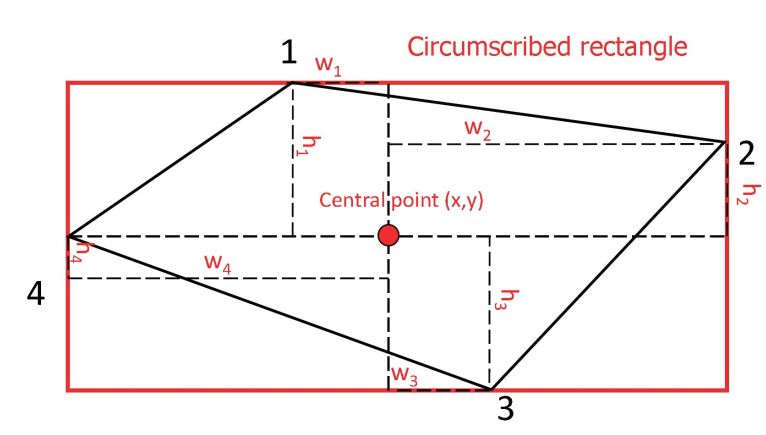
2、提出了唯一确定任意平面凸四边形中4个点顺序的协议,使得该方法能够使用相对回归来预测四边形边界框。
3、提出的共享蒙特卡罗计算方法能够快速准确地计算多边形重叠区域
4、所提出的平滑Ln loss比L2 loss和smooth L1 loss有更好的综合性能。
网络结构
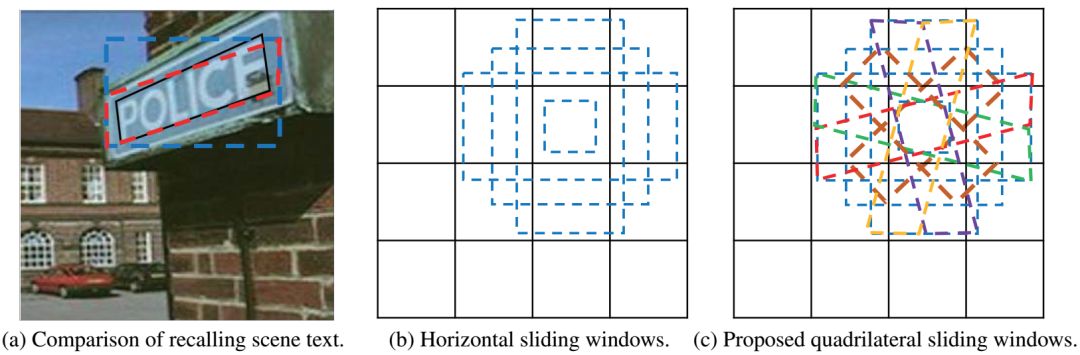
实验结果

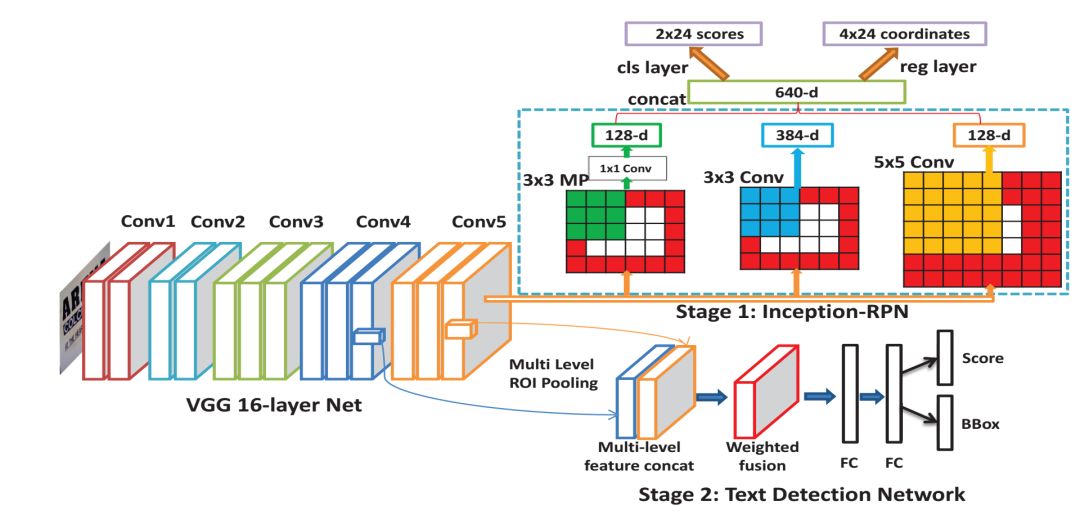
4、DeepText: A Unified Framework for Text Proposal Generation and Text Detection in Natural Images
主要思想
本文提出了一种基于完全卷积神经网络(CNN)的文本区域建议生成和文本检测的统一框架DeepText。首先,提出了初始区域提议网络(Inception RPN),并设计了一组具有文本特征的先验包围盒,以达到只有100个候选提议的高单词召回率。接下来,提出了一个功能强大的文本检测网络,该网络嵌入了模糊文本类别(ATC)信息和多级兴趣区域池(MLRP),用于文本和非文本分类和精确定位。最后,应用一个迭代包围盒投票方案来追求高以互补的方式回忆并引入过滤算法以保留最合适的边界框,同时为每个文本实例移除多余的内部和外部框。
主要贡献
(1) 提出了inception-RPN,它将多尺度滑动窗口应用于卷积特征映射的顶部,并将一组文本特征先验包围盒与每个滑动位置相关联,以生成单词的region proposals。多尺度滑动窗口特征可以在相应的位置保留局部信息和上下文信息,有助于过滤掉非文本的边界框。初始RPN能够实现高召回率,只有数百个词的region proposal。
(2) 将附加的ATC信息和多级ROI池(MLRP)引入到文本检测网络中,帮助它学习更多的区分信息,以区分复杂背景下的文本。
(3) 为了在整个训练过程中更好地利用中间模型,提出了一种迭代包围盒投票方案,以互补的方式获得较高的单词召回率。此外,基于经验观察,多个内盒或外盒可以同时存在一个文本实例。为了解决这个问题,本文使用了一个过滤算法来保留最合适的边界框并移除剩余部分。
(4) 本文的方法在2011年和2013年的ICDAR鲁棒文本检测基准上分别达到了0.83和0.85的F-measure,优于先前的最新结果。
网络结构与实验结果

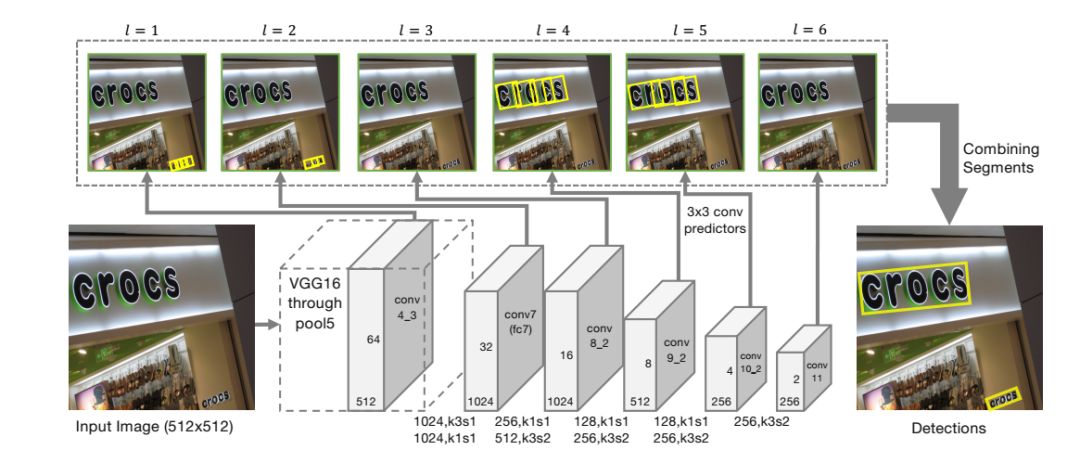
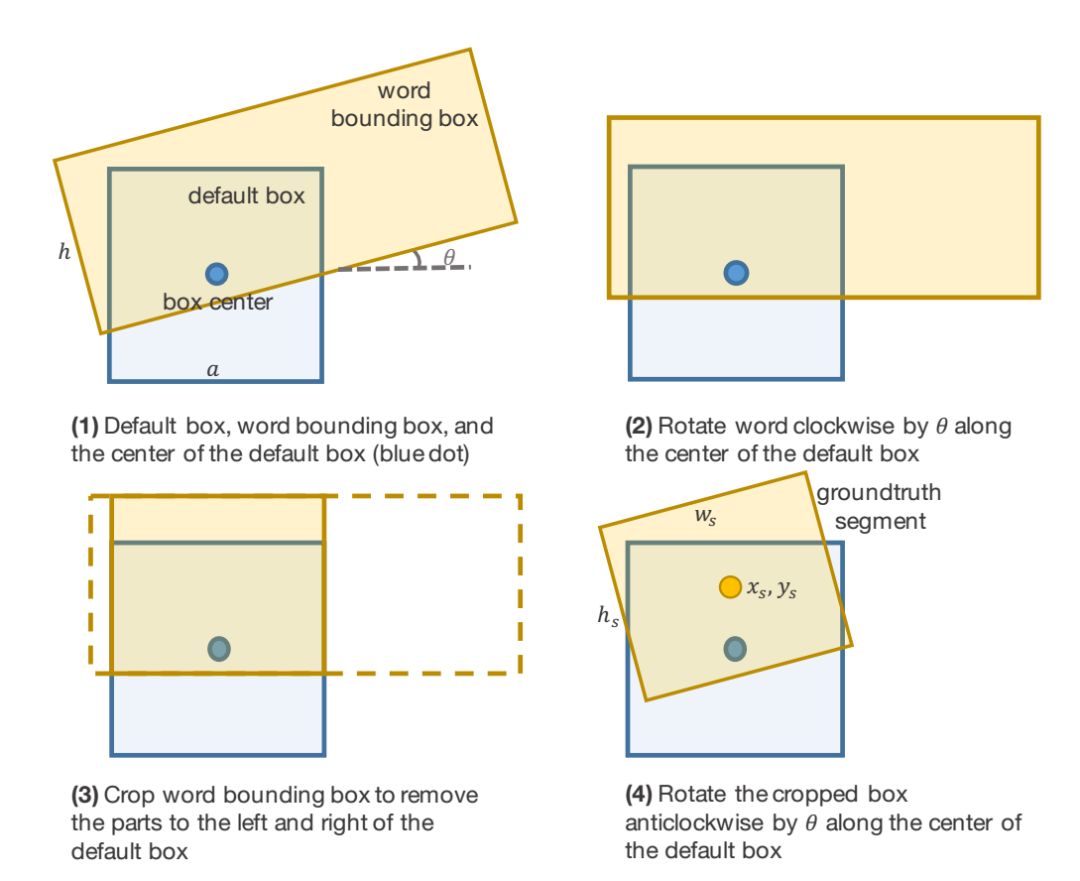
5、Detecting Oriented Text in Natural Images by Linking Segments
主要思想
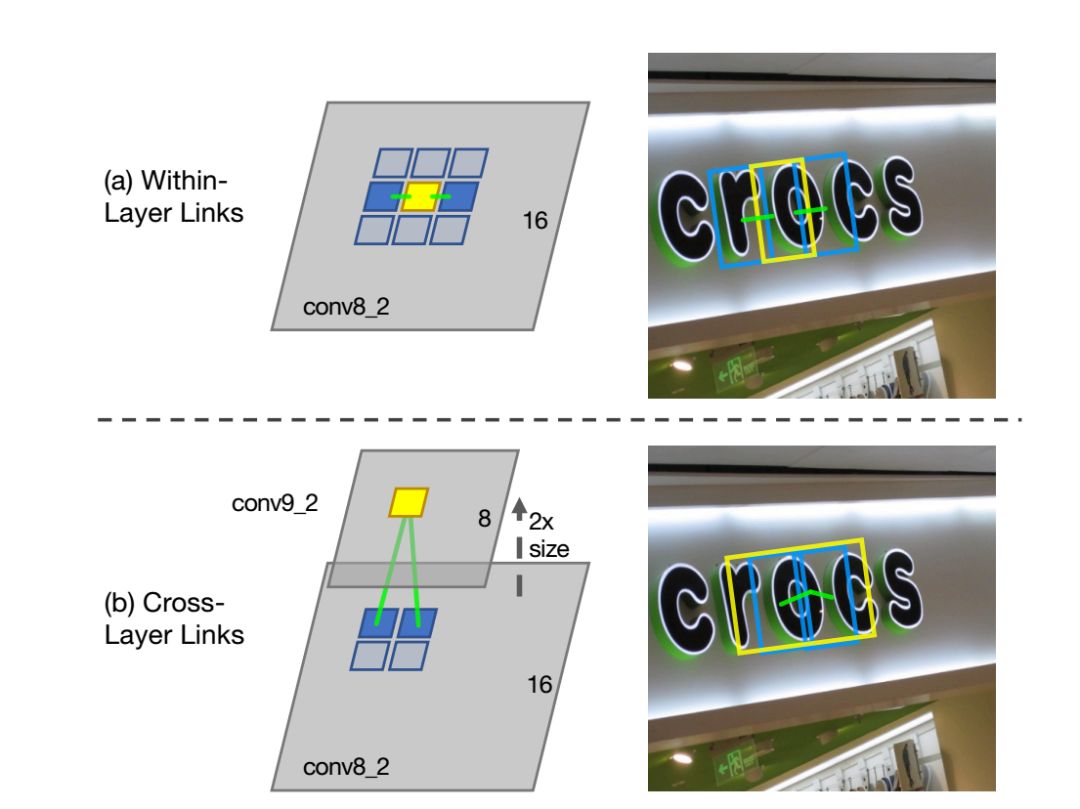
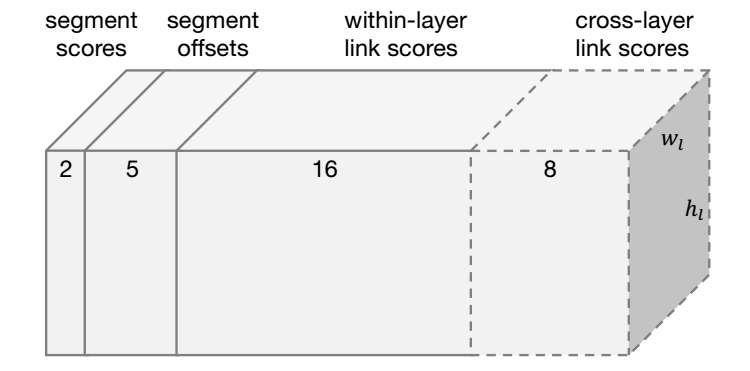
大多数最先进的文本检测方法都是针对水平拉丁语文本的,并且对于实时应用来说速度不够快。介绍了一种面向文本检测的方法——分段链接(SegLink)。其主要思想是将文本分解为两个局部可检测的元素,即片段和链接。段是覆盖单词或文本行一部分的定向框;链接连接两个相邻的段,指示它们属于同一个单词或文本行。通过端到端训练的全卷积神经网络在多个尺度上密集地检测这两个元素。
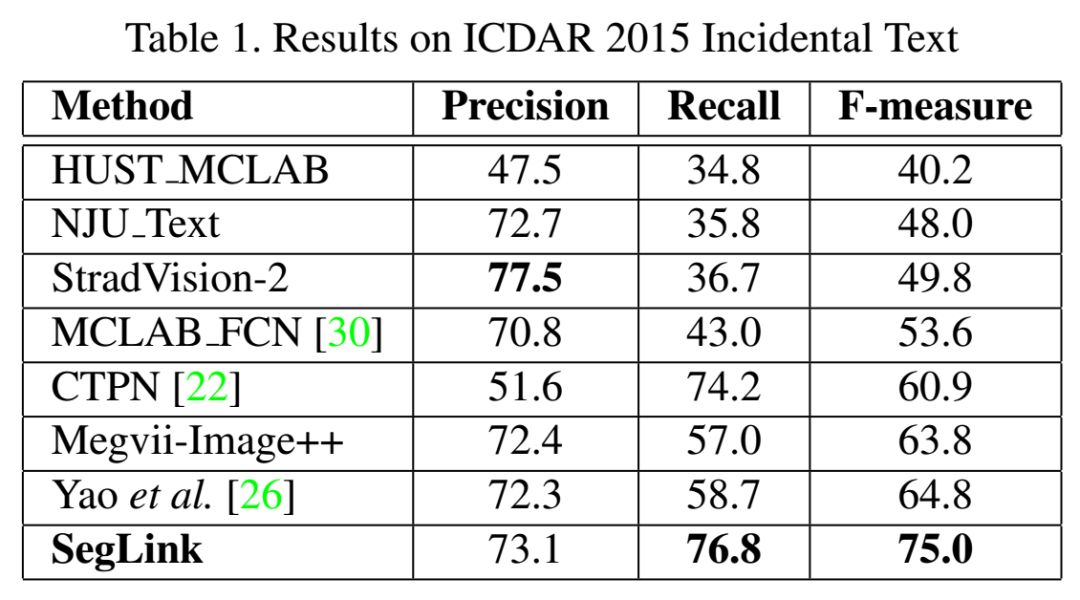
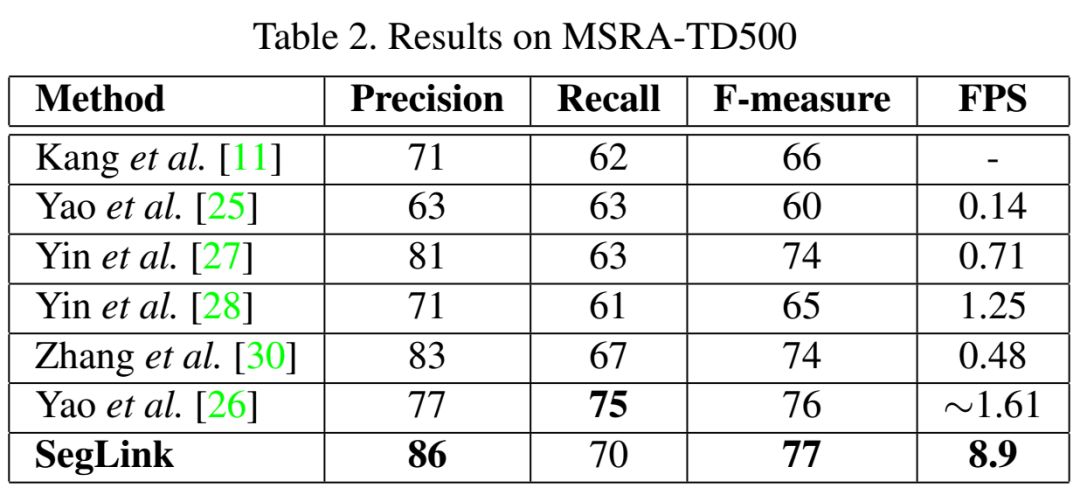
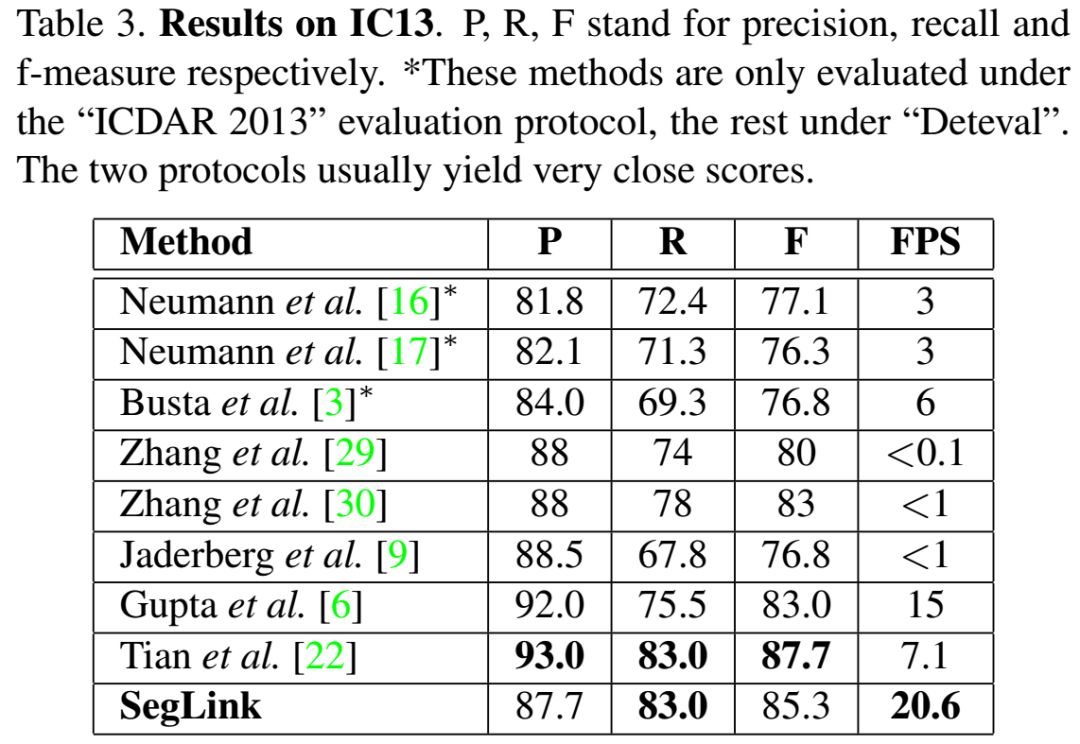
最后的检测是通过组合链接连接的片段来产生的。与以前的方法相比,SegLink在准确性、速度和易训练性方面都有所提高。它在标准ICDAR 2015附带(挑战4)基准上实现了75.0%的f指标,以较大幅度超越了之前的最佳水平。它在512×512个图像上以超过20 FPS的速度运行。而且,SegLink不需要修改就可以检测到非拉丁语文本行,比如中文。
主要贡献
主要贡献是提出了一种新的分段连接检测方法。通过实验,证明与其他最先进的方法相比,所提出的方法具有几个显著的优点:
1) 健壮性:SegLink的结构简单优雅,在复杂的背景下具有鲁棒性。论文的方法在标准数据集上取得了非常有竞争力的结果。特别是,它在2015年ICDAR数据集上的F-meature大大超过了之前的最佳水平;
2) 效率:SegLink由于其单通、全卷积设计而具有很高的效率。它每秒处理超过20幅512x512大小的图像;
3)通用性:无需修改,SegLink能够检测长的非拉丁文字的行,如中文,论文在一个多语言数据集上演示了这种能力。
网络结构
实验结果

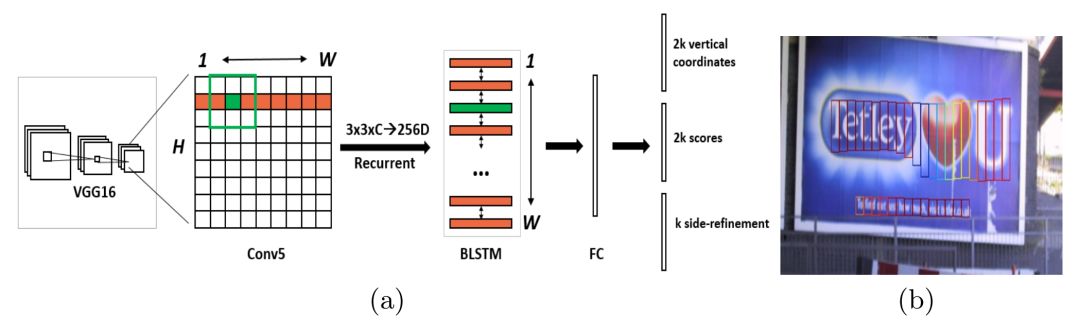
6、Detecting Text in Natural Image with Connectionist Text Proposal Network
主要思想
论文提出了一种新的连接主义文本提议网络(CTPN),该网络能够准确地定位自然图像中的文本行,CTPN直接在卷积特征映射中检测一系列精细尺度文本建议中的文本行。论文开发了一个垂直anchor机制,可以联合预测每个固定宽度方案的位置和文本/非文本分数,大大提高了定位精度。序列方案自然地由递归神经网络连接,递归神经网络与卷积网络无缝结合,形成端到端的可训练模型,这使得CTPN能够探索图像的丰富上下文信息,能够检测到非常模糊的文本。CTPN在多尺度、多语言文本上能够可靠工作,无需进一步的后处理,与以往自下而上的多步后滤波方法不同。
网络结构与实验结果


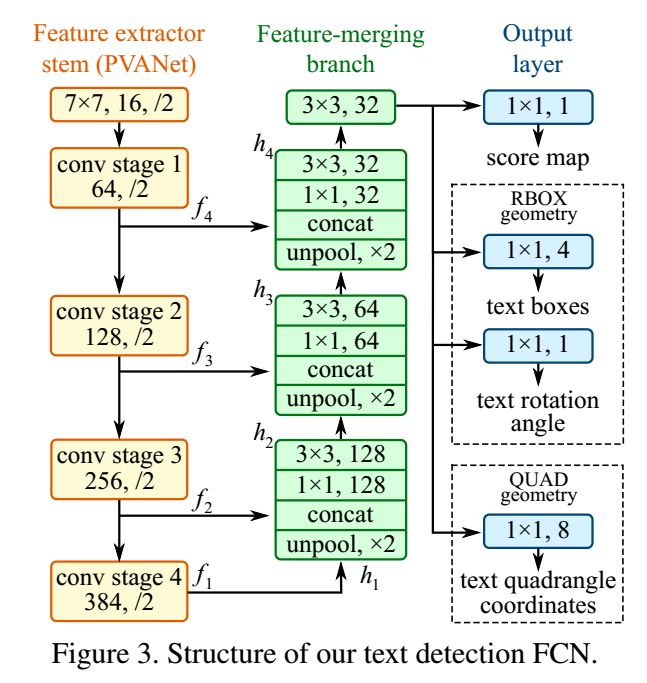
7、EAST: An Efficient and Accurate Scene Text Detector
主要思想
在这项工作中,本文提出了一个简单而强大的pipeline,在自然场景中可以快速而准确的文本检测。pipeline利用单一的神经网络,直接预测整幅图像中任意方向和四边形的单词或文本行,消除了不必要的中间步骤(如候选聚合和单词分割)。pipeline的简单性使得我们可以集中精力设计损失函数和神经网络结构。在ICDAR 2015、COCO Text和MSRA-TD500等标准数据集上的实验表明,该算法在精度和效率上都明显优于最新方法。
主要贡献
这项工作的贡献有三方面:
1、我们提出了一种场景文本检测方法,该方法包括两个阶段:完全卷积网络和NMS合并阶段。FCN直接生成文本区域,不包括冗余和耗时的中间步骤。
2、该管道是灵活的,以产生字级或线级预测,其几何形状可以是旋转框或四边形,这取决于特定的应用。
3、所提出的算法在精度和速度上都明显优于最新的方法。
网络结构
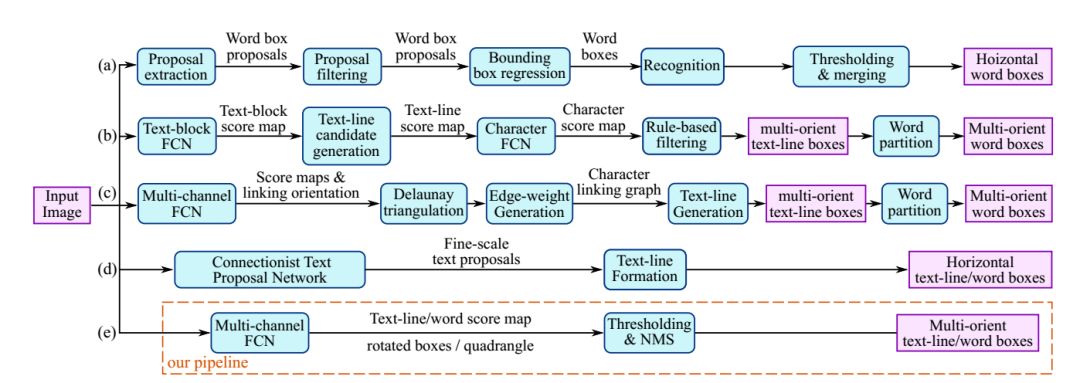
实验结果

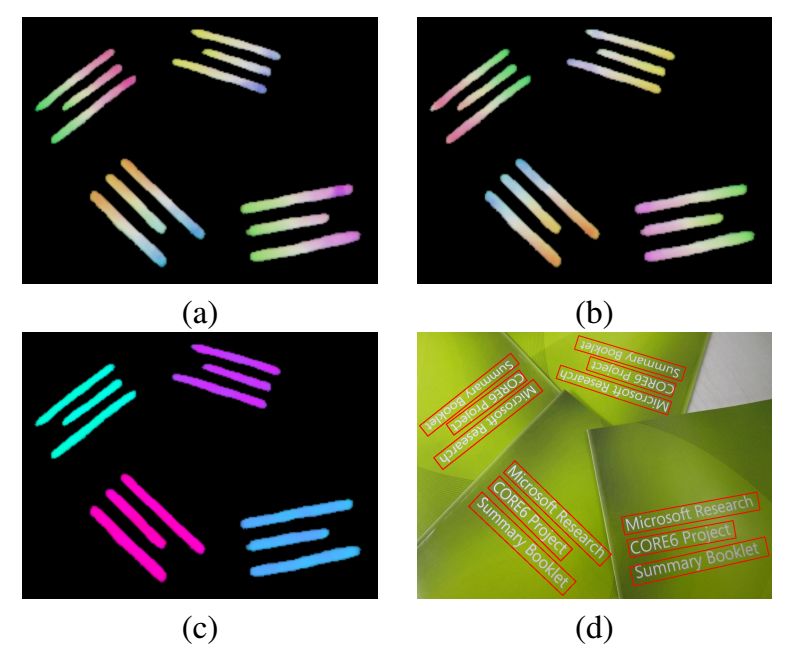
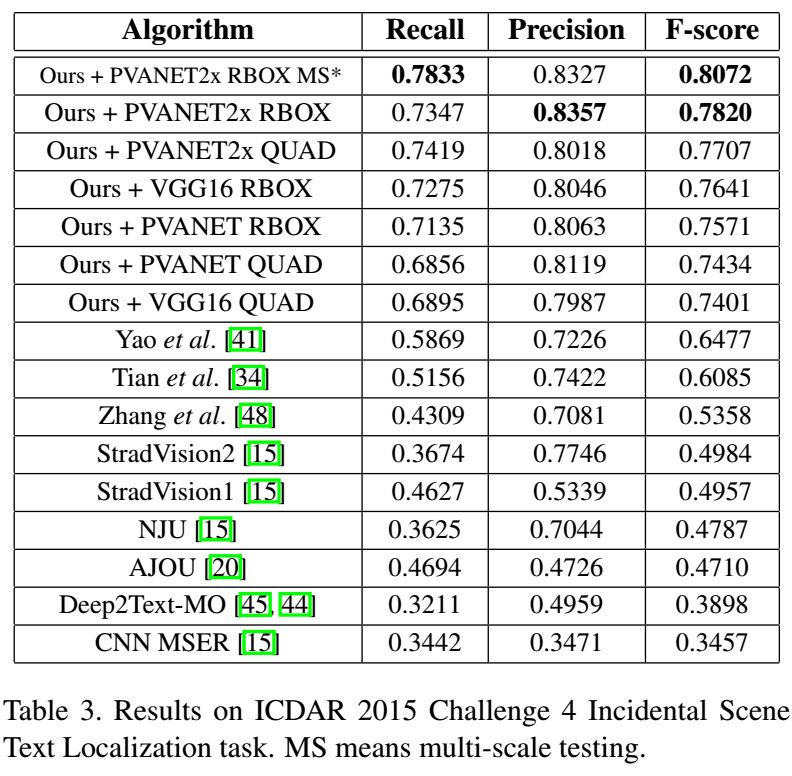
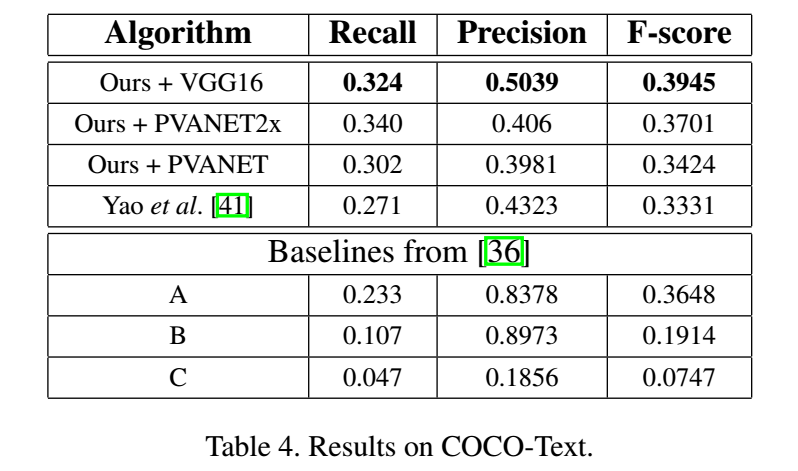
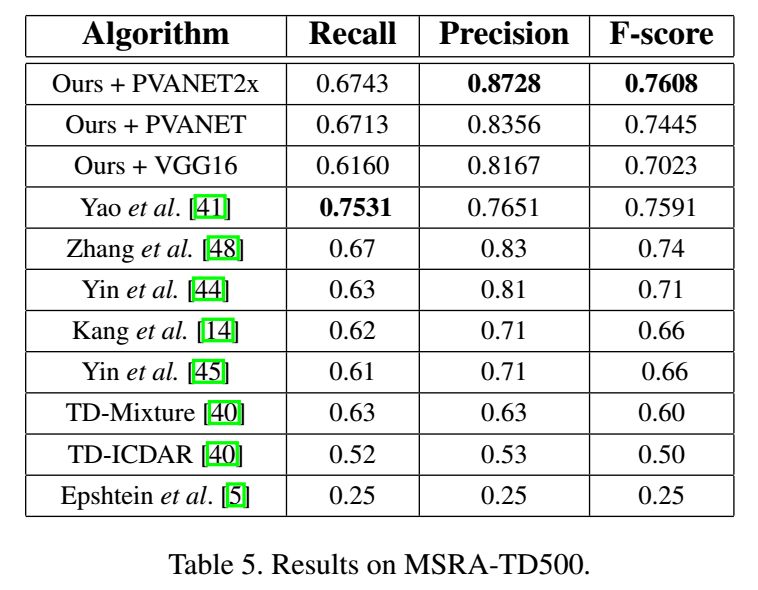
8、Multi-Oriented Text Detection with Fully Convolutional Networks
主要思想
本文提出了一种新的自然图像文本检测方法。在从粗到细的过程中,本地化文本行时同时考虑了本地和全局提示。首先,训练一个全卷积网络(FCN)模型来整体预测文本区域的显著性映射。然后,结合特征映射和字符分量估计文本行假设。最后,使用另一个FCN分类器来预测每个字符的质心,以消除错误的假设。
主要贡献
1、利用FCN学习强文本标注模型,提出了一种计算文本显著性映射的新方法。文本标记模型是以整体的方式进行训练和测试,对场景文本的尺度和方向变化具有很高的稳定性,对文本块的粗定位具有很高的效率。此外,它也适用于多脚本文本。
2、提出了一种有效的多方向文本候选行包围盒提取方法,证明了局部(字符成分)和全局(来自显著地图的文本块)线索既有用又互补。
3、提出了一种新的过滤虚假candidates的方法。我们训练一个有效的模型(另一个FCN)来预测候选文本行内的字符质心。结果表明,预测的字符质心提供了每个字符的准确位置,是去除虚假候选字符的有效特征。
网络结构与实验结果
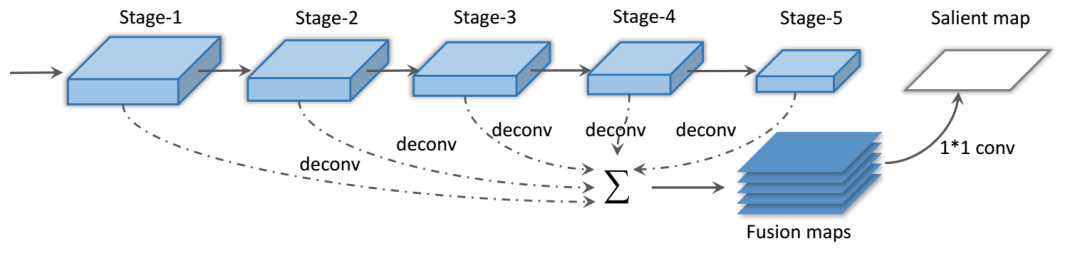



9、Robust Scene Text Recognition with Automatic Rectification
主要思想
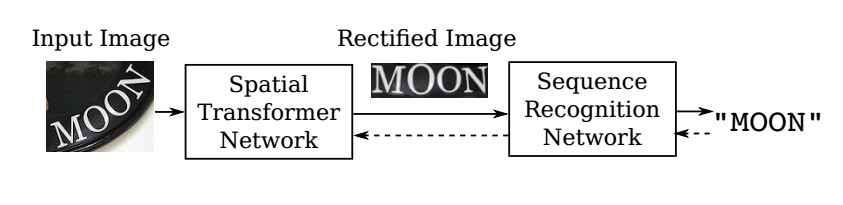
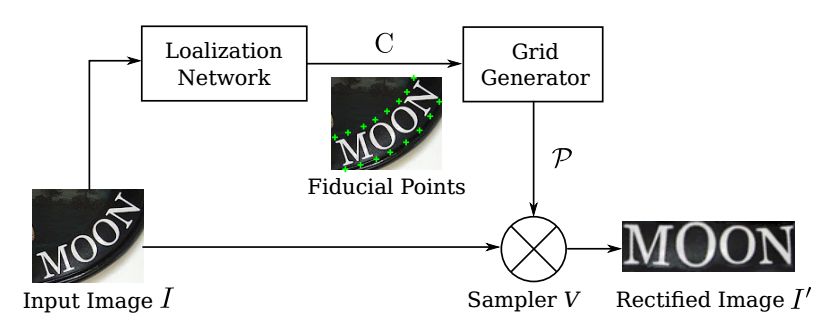
在自然图像中识别文本是一项具有挑战性的任务,许多问题尚未解决。不同于文档中的文字,自然图像中的文字往往具有不规则的形状,这是由透视失真、曲线字符放置等因素造成的。论文提出了一种RARE(自动校正的鲁棒文本识别器)对不规则文本具有鲁棒性的识别模型。RARE是一种特殊设计的深神经网络,它由一个Spatial Transformer Network(STN)和序列识别网络(SRN)。在测试中,首先通过预测的TPS变换将图像校正为更“可读”的图像,用于后续SRN,后者通过序列识别方法识别文本。结果表明,该模型能够识别多种不规则文本,包括透视文本和曲线文本。RARE是端到端可训练的,只需要图像和相关的文本标签,这使得在实际系统中训练和部署模型非常方便。
主要贡献
1、提出了一种对不规则文本具有鲁棒性的场景文本识别方法。
2、使用基于attention的模型并扩展了STN框架,原始STN仅在普通卷积神经网络上进行测试。
3、SRN的编码器采用卷积递归结构,是基于attention模型的一个新变体。
网络结构

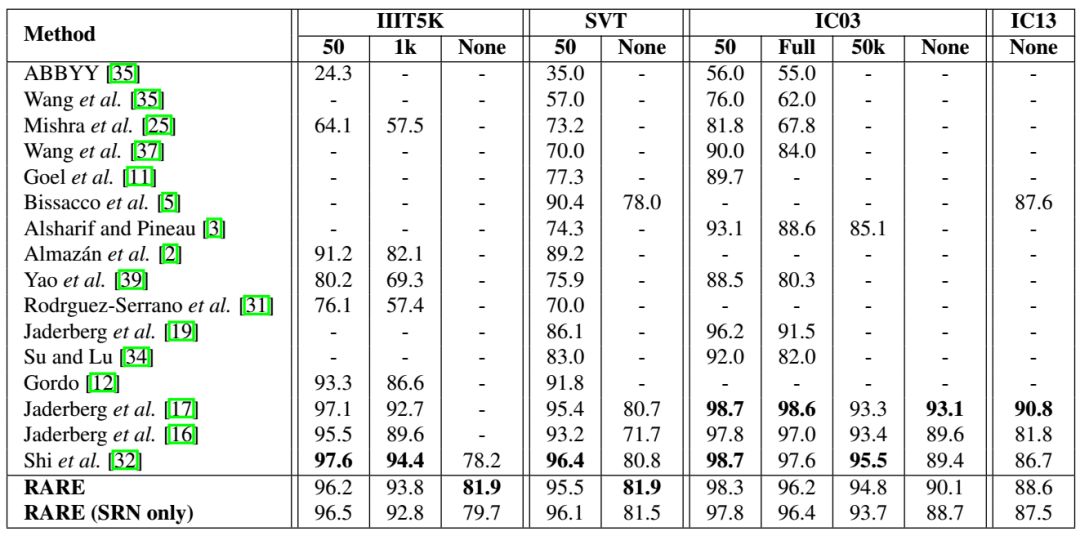
实验结果

上述内容,如有侵犯版权,请联系作者,会自行删文。

下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

















 4778
4778











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









