






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达阅读本文大概需要 6 min 左右
传统卷积层计算
01
首先我们定义符号F()函数为卷积函数
一维卷积:F(n,m)
n代表输出的维度,m代表滤波器的维度
二维卷积:F(n*m,r*s)
n*m代表输出的维度,r*s代表滤波器的维度
下面我们具体谈谈针对二维的卷积加速
传统的卷积层加速:

对于最简单的F(n*m,r*s)
最传统暴力的卷积运算:
时间成本:
1. 乘法:(n*m*r*s)
2. 加法:(n*m*(r – 1)*(s – 1))
空间成本:
1. 输入层:(n+r-1)*(m + s - 1)
2. 卷积核:(r*s)Imcol+GEMM
02
为了更好的理解,首先给出这幅图:
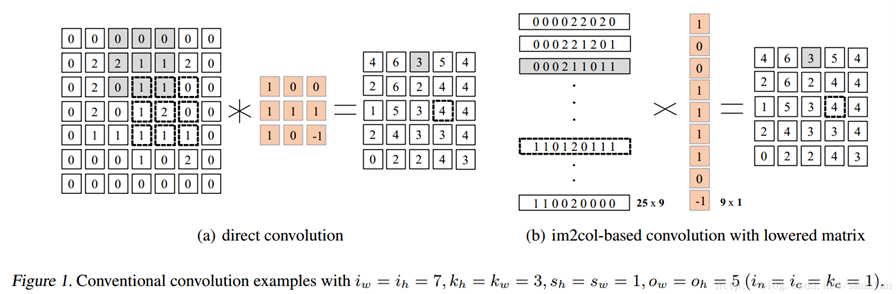
推广到三维,也就是Image:C*H*W


最后一页没画,但是基本上就是Filter Matrix乘以Feature Matrix的转置,得到输出矩阵Cout x (H x W),就可以解释为输出的三维Blob(Cout x H x W)。
相对于传统的暴力的卷积算法而言,此算法将卷积变成了矩阵乘法,为加速提供了便捷条件,能很容易用硬件实现加速。但是内存有冗余。
Imcol+MEC初级版
03
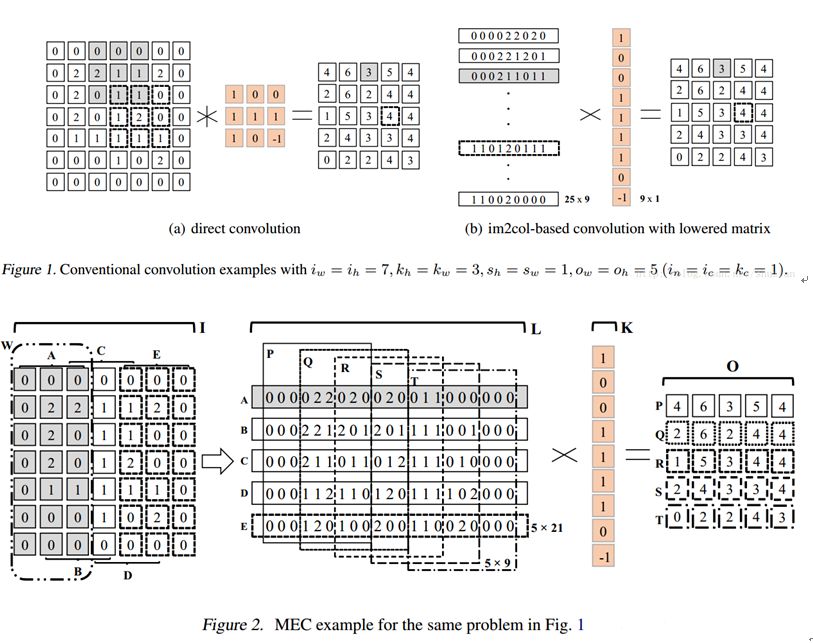
由于是3x3卷积核,且步长为1。因此,循环取出A、B、C、D、E这5个子矩阵,每个矩阵的维度都是: 输入高度x3
将A、B、C、D、E按照行优先展开并拼成一个大的中间矩阵L, L的维度则为:5x21。从L中循环取出P、Q、R、S、T这5个子矩阵,并计算5次矩阵乘法,就得到了最终的结果。从上面的示例中我们不难看出,MEC的解决思路在于将im2col这一过程分成了Height和Width两部分,于是需要存储的中间矩阵也大大减小了。可能带来的问题就是,原来的一次矩阵乘法,现在会变成多次小矩阵乘法。虽然有利于并行计算,但也失去了BLAS库计算大矩阵乘法的优势。
F( n*m,r*s)
原本内存:( n+r – 1) *( m+s – 1)
Imcol+GEMM转换需要内存大小:r * s * n * m
Imcol+MEC初版需要内存大小:m * ( r * ( n + s – 1 ) )Imcol+MEC高级版
04
考虑了batchsize和channel

Winograd方法
05
说完了这些方法,我们来说说Winograd方法吧,加速卷积的不二之选。本文重在于利用Winograd方法加速卷积,顺便选取内存和速度兼顾的方案
公式的推导,这里选用F( 3 *3,2*2)
用多项式的中国剩余定理推导可知:
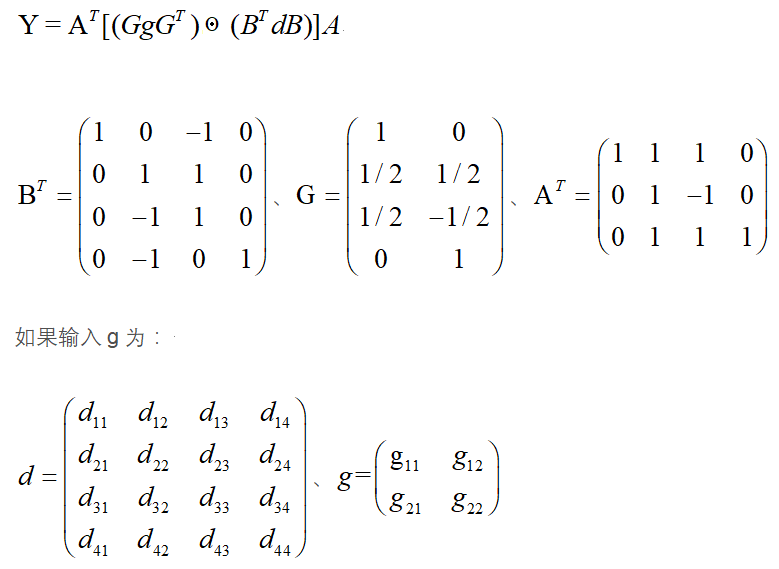



在其中,我用的是F( 4 * 4 , 3 * 3 )
输入的tensor:[N,W,H,C]
卷积核的tensor:[C_out,kernal_W,kernel_H,C_in]
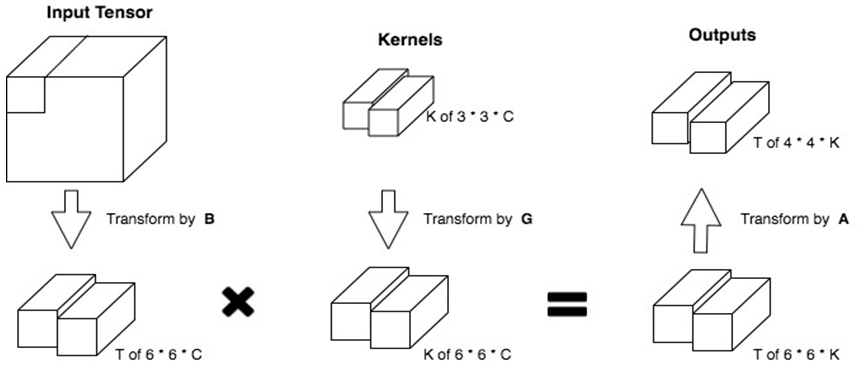
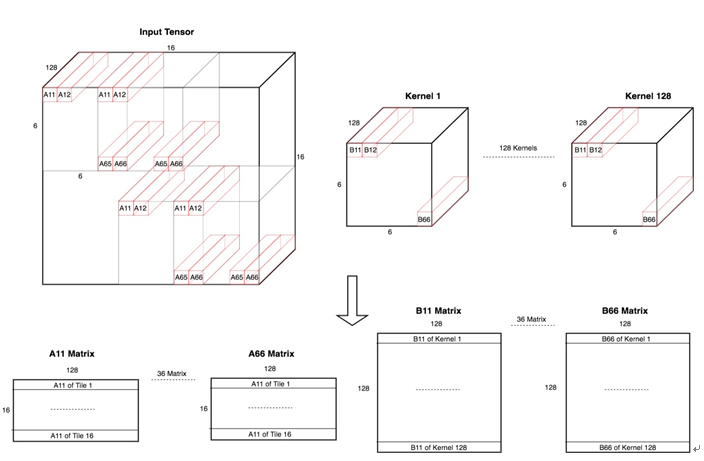
图中K = C_out、T = N
Kernals中的众矩阵通过从[C_out,3,3,C] -> [C_out,6,6,C]
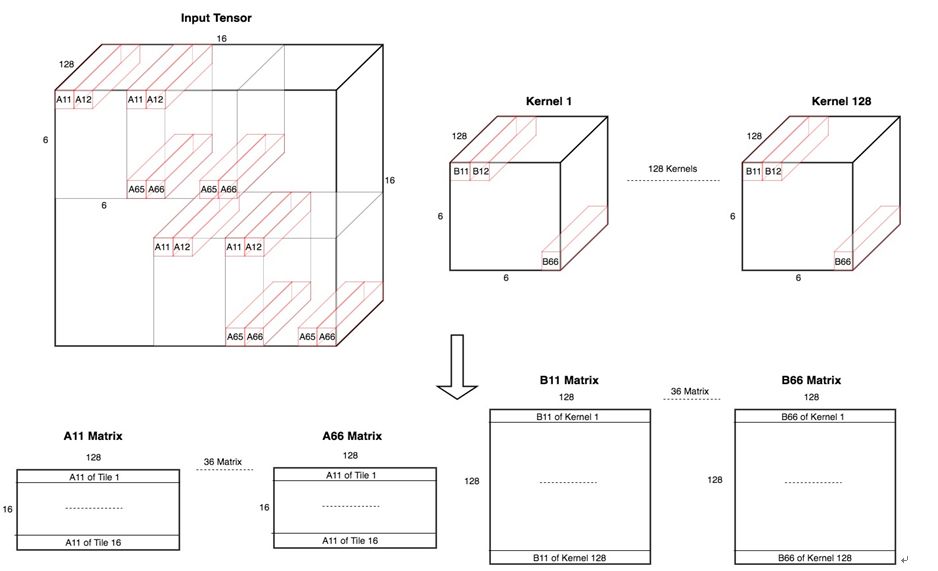

是一个变形后的卷积核,kernal1 = [1,6,6,128],上图中有128个卷积核,因为输出的Tensor:[N,W,H,128],抛开上面具体的实例,为了推导后续公式,这里我们只研究
对于输入矩阵16X16、卷积核 3X3,采用 F( 4 X 4,3X3 ) 的加速方案:
明确输出矩阵14 X 14 首先将卷积核通过GgG(T)变成 6X6的矩阵D


现在的问题变成了如何将点乘的集合变成更简易可表达的形式。再看下面这幅图:


故我们得到的最后的结果是:
所以最后我们统计一下所作的乘法:
传统:3 X 3 X 128 X 14 X 14 = 225792
Winograd:6 X 6 X 128 X 16 = 73728
浮点数运算倍数:225792 / 73728 = 3.0625改进:如若有剩余,考虑用其他矩阵相乘方法
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇

下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~














 285
285











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









