






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达无监督光照适应低光视觉
作者:Wenjing Wang; Rundong Luo; Wenhan Yang; Jiaying Liu
摘要
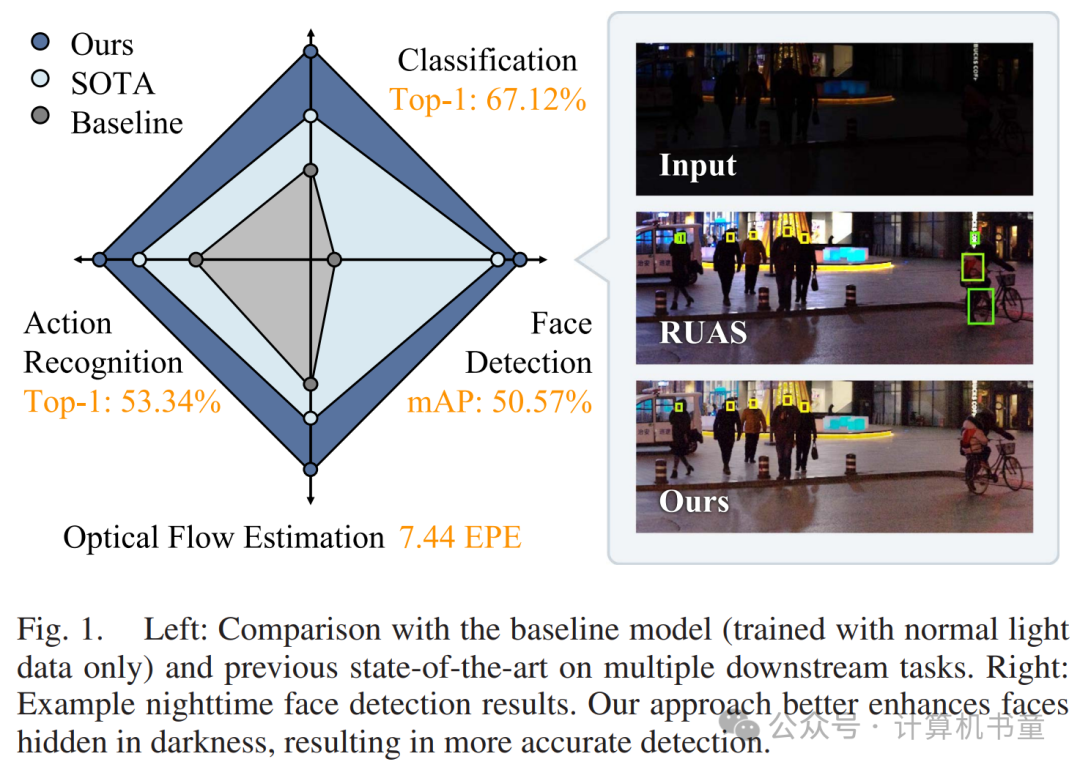
光照不足对人类和机器视觉分析都带来了挑战。现有的低光增强方法主要关注人类视觉感知,往往忽略了机器视觉和高层语义。在本文中,我们首次构建了一个面向高层视觉的光照增强模型。借鉴相机响应函数的灵感,我们的模型可以从机器视觉的角度增强图像,尽管其架构轻量、公式简单。我们还引入了两种方法,利用基础增强曲线的知识和自监督预任务来训练不同的从正常光到低光的适应场景。我们提出的框架克服了现有算法的局限性,无需在低光条件下获取标注数据。它能够更有效地恢复光照和对齐特征,显著提高下游任务的性能,并可以即插即用。该研究推进了低光机器分析领域,广泛适用于分类、面部检测、光流估计和视频动作识别等多种高层视觉任务。
关键词
领域适应
高层视觉
光照增强
低光
自监督学习
I. 引言
光照不足是由恶劣环境、设备故障或不当拍摄设置导致的常见图像退化问题。它会损害图像的视觉质量,导致细节丢失、可见度下降和美感失真。此外,随着深度学习的进步,视觉分析在众多应用中变得越来越重要。低光条件也会对机器分析提出挑战,使高层视觉任务(如夜间监控视频分析和自动驾驶)变得更加困难。
自数字成像诞生以来,低光图像的恢复得到了广泛关注。许多工作有效地提高了低光图像的人类视觉质量,从早期手动设计的算法到最近的基于学习的模型。然而,大多数现有的低光增强方法旨在改善图像的视觉质量,却忽略了机器视觉的需求,从而误导了下游高层视觉模型。一些方法尝试嵌入语义感知进行视觉重建,但仍无法保证下游高层视觉任务的性能。
为了进一步提高机器视觉在黑暗中的表现,一个直观的想法是直接在标注的低光数据上训练模型。尽管在某些任务上表现良好,标注要求却严重限制了它们的应用范围。因此,无监督的正常光到低光领域适应成为一个有前景的研究方向,这种方法消除了标注的需求。在这个领域中,一些方法提出通过图像翻译合成目标领域标注,而另一些则采用自监督学习或手工操作符。然而,现有算法要么依赖多个源域,要么采用繁琐的多阶段和多级过程,或在更暗的情况下失效。此外,大多数适应方法集中于机器分析模型的高维特征,而忽略了输入图像本身的特性。
与上述方法相比,我们充分利用了光照调整的潜力。我们提出了一种基于曲线的增强模型和两种自监督训练策略,以从机器视觉的角度增强图像,从而提升模型在下游高层任务中的表现。首先,受韦伯-费希纳定律和相机统计数据的启发,我们通过“凹性”约束我们的增强函数,该函数通过预测非正二阶导数并应用离散积分来高效实现。此设计使得增强模型能够生成自然逼真的图像,并提高其对多个下游任务的适应性。随后,我们设计了两种自监督策略,将此模型训练为无监督适应。当任务相关信息可用时,我们提出汇集预定义的基础增强曲线的知识。该过程通过汇总这些曲线增强图像上的模型预测结果为伪标签来实现。尽管公式简单,但汇集基础曲线能够为后续的自我训练带来可靠的监督。
III. 架构:深凹曲线
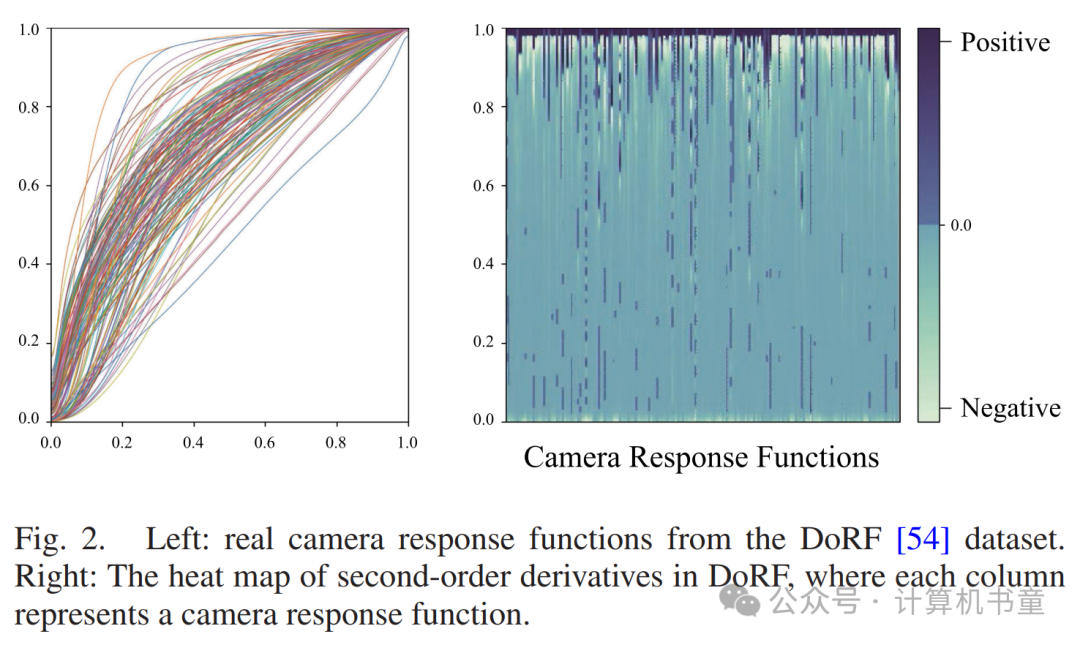
A. 动机:从CRF到凹曲线
相机响应函数(CRF)定义了场景光照强度与相机捕获的像素值(强度)之间的关系。光照与辐照度线性相关,但与强度有着复杂的非线性关系。基于此,一些低光增强工作利用了辐照度的线性关系。他们首先将图像强度转换为辐照度,线性调整辐照度,然后将辐照度映射回强度。
B. 公式和实现
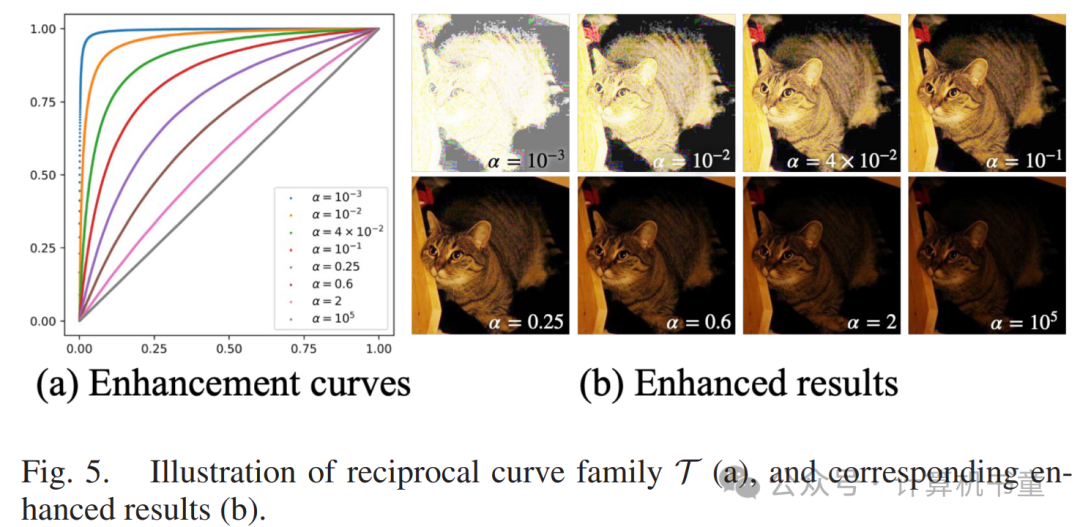
我们的光照增强函数应满足两个基本特征:递增单调性和凹性。因此,我们称我们的增强模型为“深凹曲线”。
给定输入的低光图像,我们使用神经网络预测调整函数。可以表示为颜色空间中个数值的向量(例如,8位图像中)。具体来说,对于输入图像中值为 的像素,其新值将是的第个元素。
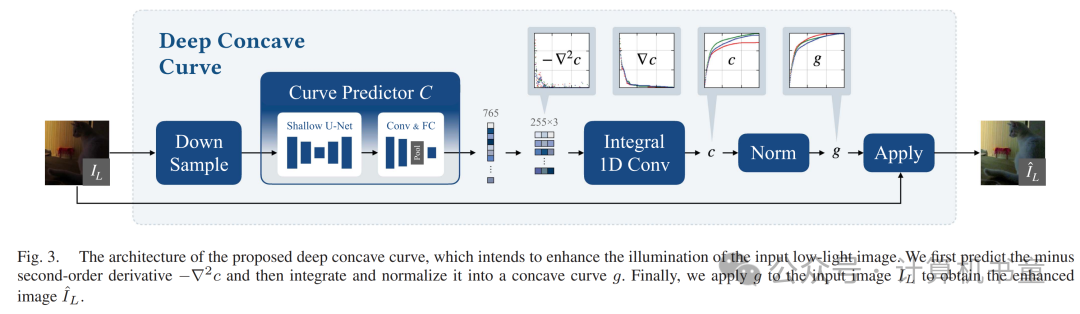
从到的离散积分:
其中是上三角矩阵:
如果如果
最后,我们将归一化为以适应映射到的范围。
C. 网络架构
给定输入的低光图像,我们为每个颜色通道分别预测一个独立的,即RGB图像中的。在实现方面,我们将并排放置,并进行一维卷积积分,输出通道数为256,核大小为1。卷积权重设为,在三个通道间共享。
我们在图3中描绘了整体架构。在训练和推理期间,我们将输入图像下采样至的分辨率,以增强感受野和效率。曲线预测器包含浅U-Net、两层卷积、全局平均池化和一个全连接层。输出维度为8位RGB图像的765。在获得模型预测后,我们将其重塑为,然后通过1D卷积进行积分得到。最后,我们将归一化得到并应用回。
IV. 训练策略:自对齐适应
A. 曲线集成学习
首先,我们讨论任务信息(如任务头)可用的情况。利用任务信息可以直接优化我们的增强模型,避免被与光照无关的特征误导,这些特征对下游任务并不重要。

然而,关键问题在于标签的缺失,最直接的想法是依赖伪标签,即自我训练。自我训练是半监督学习和领域适应的常见方法。具体而言,它利用在源域上预训练的模型为未标注的目标域数据生成伪标签。之后,模型在带有伪标签的目标域数据集上重新训练。
B. 预任务学习
当任务信息可用时,我们可以利用伪标签减少光照无关因素的影响。然而,对于许多下游任务,任务头包含非可微模块,如非极大值抑制。在这种情况下,直接使用模型的预测进行后续的自我训练是不合适的。
训练流程包括两个步骤。我们首先固定特征提取器并在正常光数据集上训练拼图头,该数据集包含正常光图像及其真实旋转拼图排列:
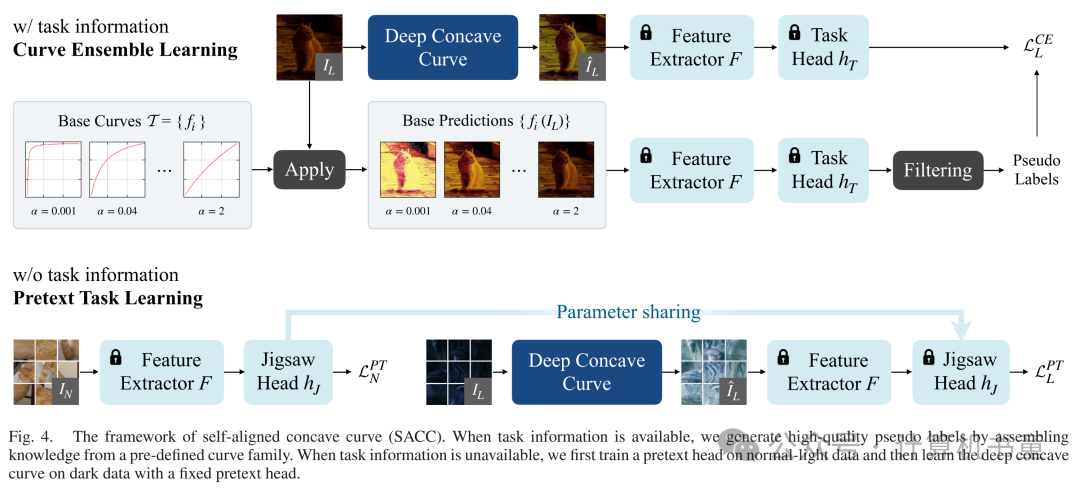
然后,我们固定和,并在低光数据集上训练我们的深凹曲线:
V. 方法设计分析
A. 模型架构的合理性
以下是对所提出的光照增强模型(即深凹曲线)的实证论证。分析基于分类数据集CODaN [8]、面部检测数据集DARK FACE [62]和WIDER FACE [62]。我们的目标是在低光条件下提升正常光预训练模型的性能。正常光预训练模型为用于分类的ResNet-18 [63]和用于检测的DSFD [64]。更多细节见第VI节。对于训练策略,如果没有明确说明,我们分别采用SACC-CE和SACC-PT。为了提高效率,我们在本节评估期间采用DSFD [64]的快速推理模式。
首先,我们将我们的方法与其他低光增强网络架构进行比较。我们探索了两个具有代表性的增强模型:EnlightenGAN [16],其通过U-net [55]直接执行图像到图像翻译;Zero-DCE [18],其通过迭代二次曲线逐像素进行调整。所有增强模型都使用与我们相同的策略进行训练,以便我们可以单独评估网络架构的效果。
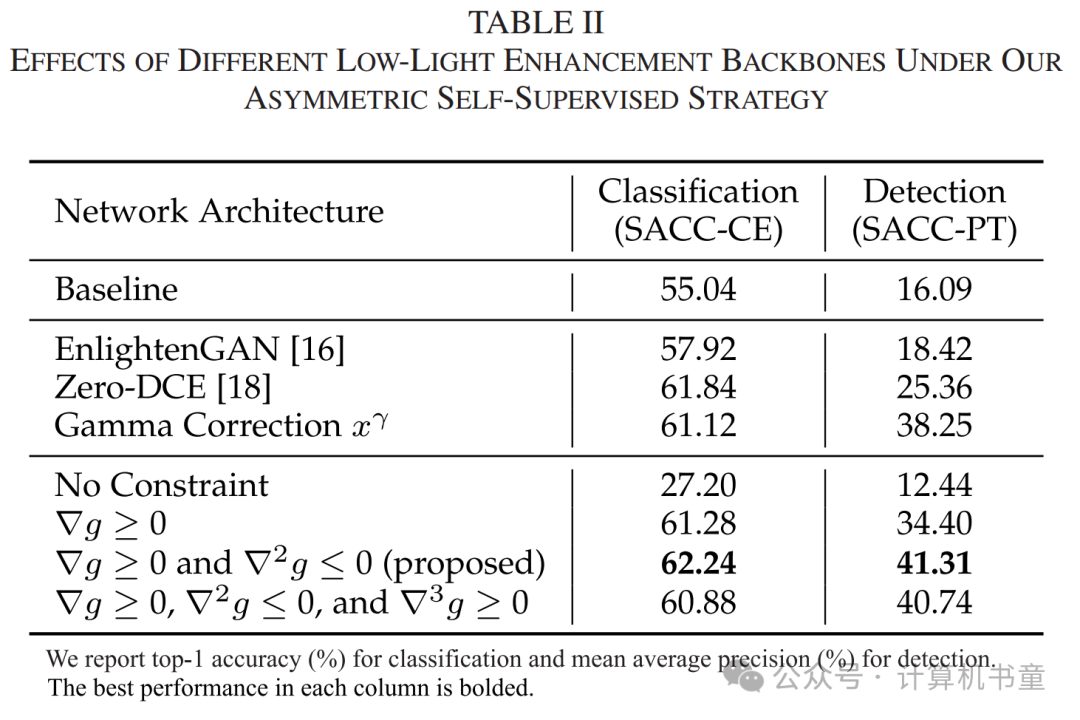
如表II的主观结果所示,EnlightenGAN和Zero-DCE均不如我们提出的深凹曲线。
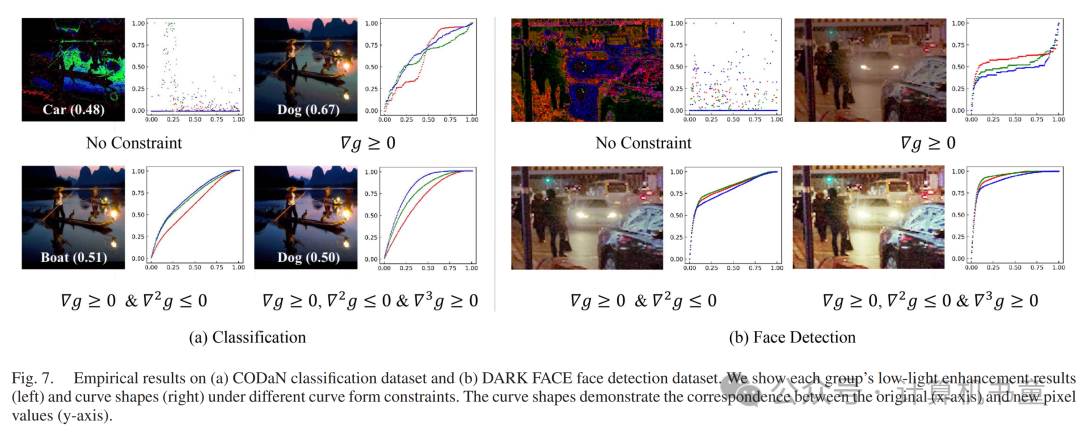
如图6所示,我们在由EnlightenGAN和Zero-DCE生成的增强图像上观察到了奇怪的伪影。在图6(a)中,两种方法都引起了不连续的颜色变化。在图6(b)中,边缘出现了异常纹理。相比之下,我们的深凹曲线在图像分类和面部检测中均表现出更好的视觉效果和下游性能。这些结果表明,我们的空间共享、单调递增和凹性约束可以有效地对模型进行正则化,避免模型在图像上刻画欺骗符号或暗示(即伪影)。
此外,我们测试了伽玛校正 作为替代的基于曲线的增强方法,并使用浅卷积网络预测。如表II所示,其性能有限。我们将其归因于我们的曲线具有高度自由度,因为我们为每个输入像素值预测一个独立的目标值。而伽玛校正仅有全局调整参数。
最后,我们探讨了对曲线预测网络施加约束的适当强度。如图7和表II所示,设置曲线为无约束将导致异常的增强结果。同时,仅有的曲线看似不连续。我们的SACC在我们要求曲线满足和时达到了最佳效果。注意在图7中,红、蓝、绿三条曲线形状各异,表明我们的模型可以根据输入图像进行通道感知的增强,即纠正色偏。我们还尝试了,发现这会降低整体性能,并生成部分过曝的图像。这是因为三次迭代积分会使权重矩阵的值呈指数级增长,从而导致梯度消失并使训练过程复杂化。
B. 训练策略的合理性
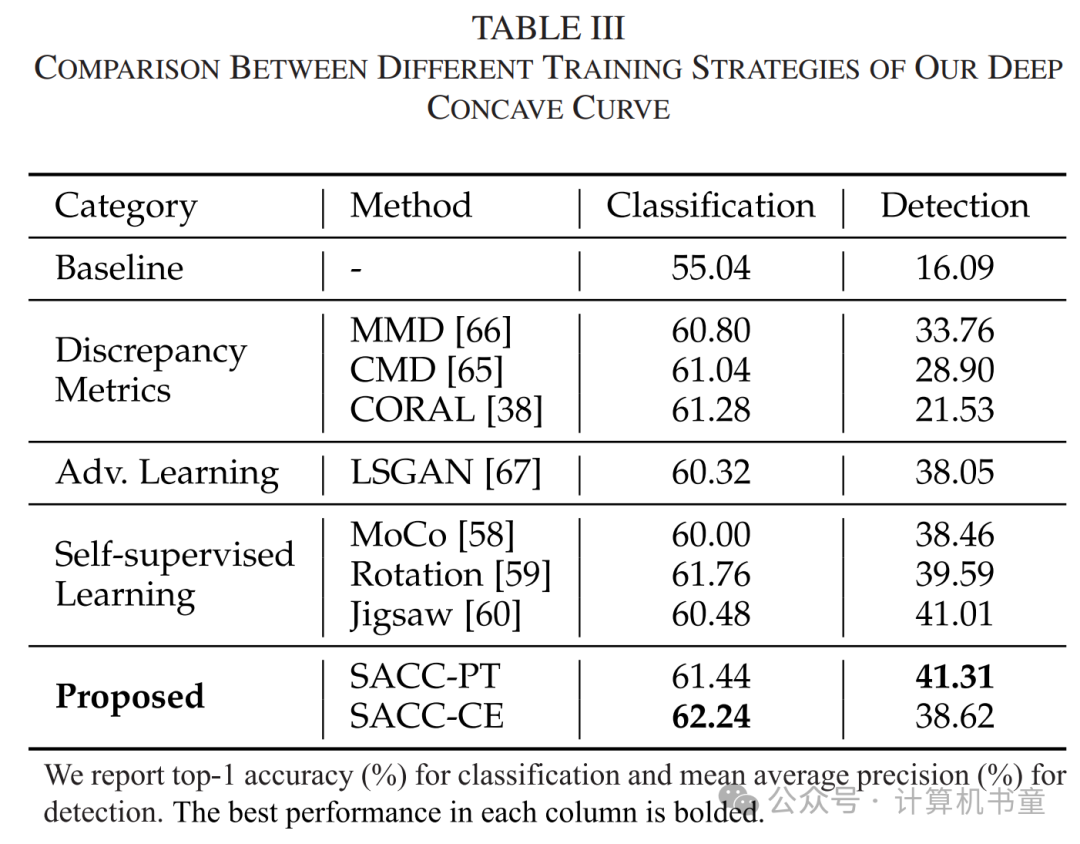
接下来,我们讨论深凹曲线的合适训练策略。我们将提出的训练策略(SACC-CE和SACC-PT)与其他主流范式进行比较,包括差异度量[38]、[65]、[66]、对抗学习[67]和自监督学习[58]、[59]、[60]。定量结果见表III。

差异度量、中央矩差(CMD)[65]、最大均值差异(MMD)[66]和深度CORAL [38]最初是为处理一般领域适应而设计的,在弥合正常/低光域差距方面效果不佳。对抗学习[67]也带来了不满意的结果,因为区分正常/低光模式非常容易,破坏了特征提取器和判别器之间的平衡。此外,对抗学习由于架构复杂性而遭遇不稳定的训练动态。
对于自监督学习,我们考虑了基于对比学习[58]和基于预任务的方法[59]、[60]。尽管对比学习在模型预训练上具有优势,但它考虑的是全局特征,因此不适合训练我们的增强曲线。传统预任务,包括旋转预测和拼图排列,由于表达性有限,表现不佳。
对于提出的SACC-CE和SACC-PT,前者在分类任务上表现较好,而在面部检测上表现较差。我们将这归因于分类输出的离散性和易于比较的性质,这提高了曲线集成的准确性。相反,当应用于面部检测时,集成预测的准确性降低。由于需要专门设计的合并操作来处理边界框预测,直接像分类那样组合会导致伪标签不准确或数量不足,从而导致次优训练结果。设计适当的标签合并策略可能是一个解决方案,但为每个下游任务开发策略是不可行的。因此,我们提出基于特征操作的预任务型SACC-PT。SACC-PT在分类任务上的表现不如SACC-CE,因为它无法利用任务信息,但在面向非分类下游任务时更通用。总的来说,对于需要汇集完整图像信息以进行决策的应用,如图像分类,可使用SACC-CE;对于需要更细粒度局部信息进行推理的应用,可使用SACC-PT。
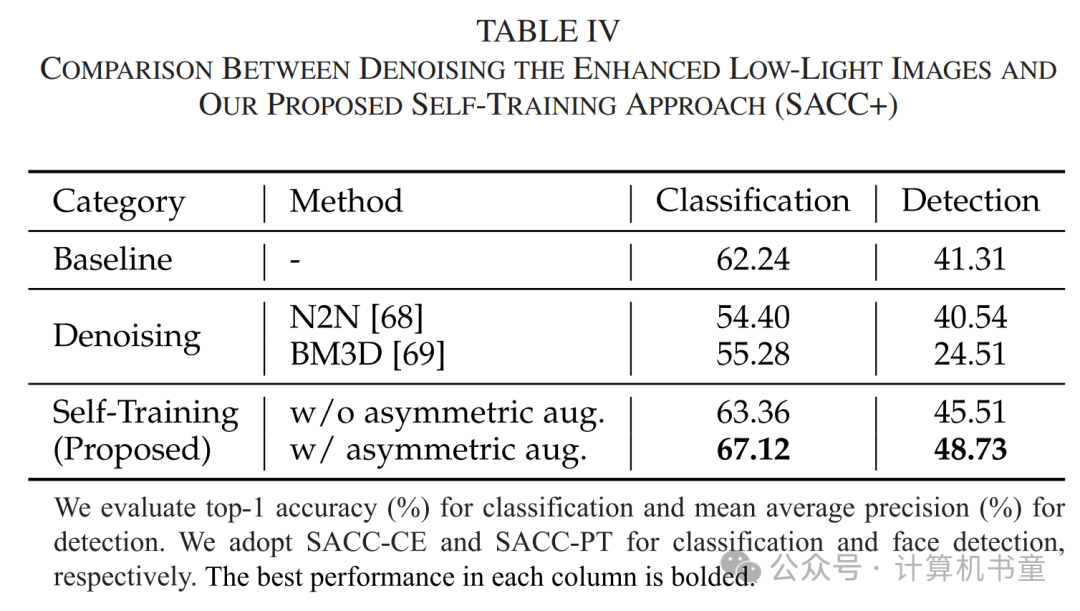
C. SACC+:图像去噪还是模型微调?
最后,我们验证了SACC+的设计。由于深凹曲线是全局操作,它会保留噪声,这是低光图像的主要特征。因此,去噪增强图像可能进一步提高性能。为了测试这一假设,我们考虑了两种方法:非学习方法BM3D [69]和基于学习的Neighbor2Neighbor [68]。
尽管它们在人类视觉体验上取得了成功,但去噪会模糊对高层语义至关重要的细节。结果如表IV所示,模型的分类和面部检测性能显著下降。相比之下,我们的微调方法SACC+通过表示学习本质上解决了噪声问题,同时不损害图像信息。此外,在微调过程中采用非对称增强有助于弥合正常光域和增强低光域之间的差距,有效提升了模型的整体表现。
VI. 实验
A. 实现细节
我们提出的框架适用于多种模型和视觉任务。为了证明其有效性,我们在若干代表性的低光视觉任务上进行了评估,包括分类、面部检测、光流估计和视频动作识别。
我们的框架运行在使用正常光数据预训练的模型上。对于SACC-CE/SACC-PT,我们冻结预训练模型并训练我们的深凹曲线。随后,对于SACC-CE+/SACC-PT+,我们冻结增强模型并微调下游模型。这两个阶段都不需要标注的低光数据。接下来,我们在分类和视频动作识别任务中采用SACC-CE,而在面部检测和光流估计任务中采用SACC-PT。更多实现细节可见补充材料。
B. 低光图像分类
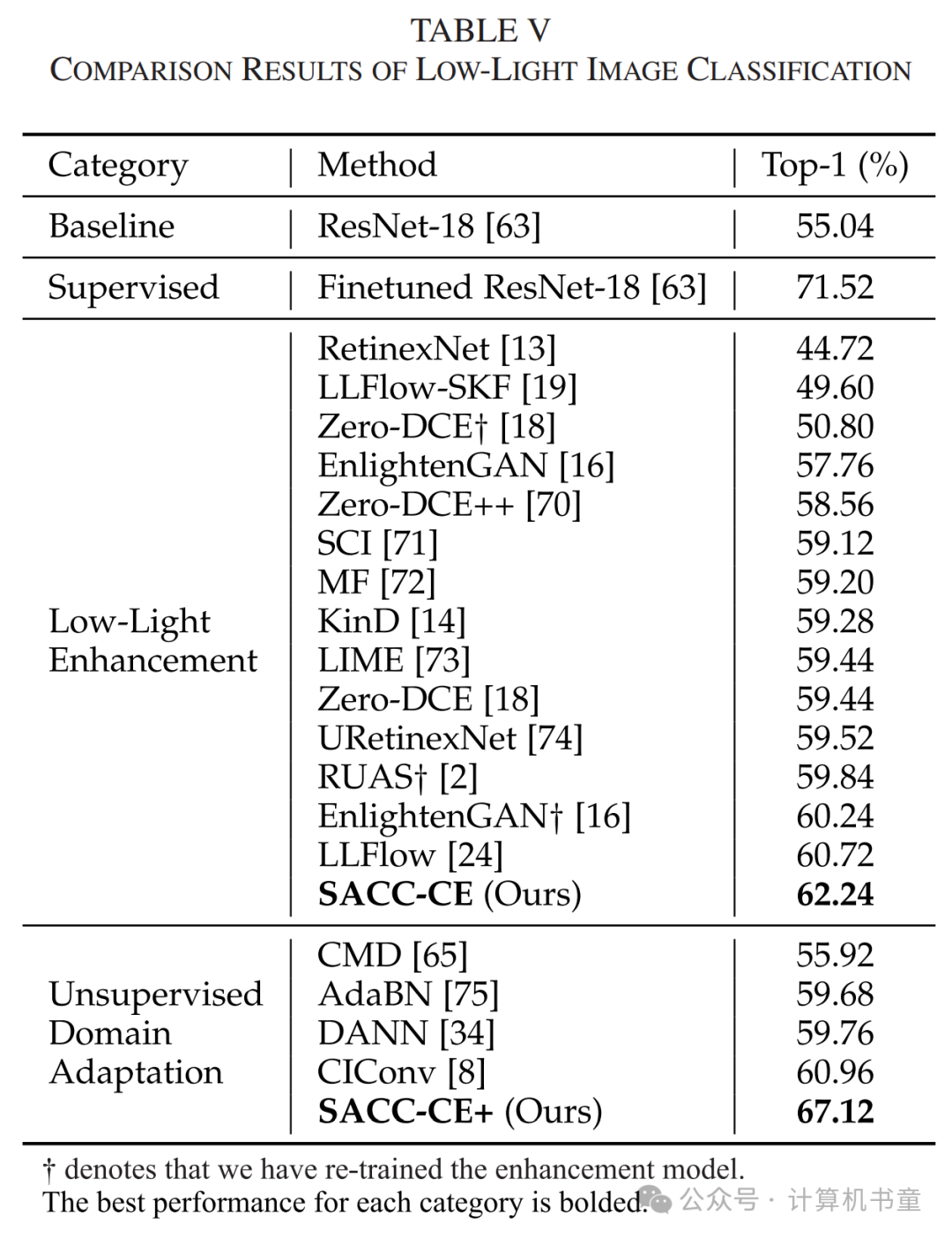
首先,我们通过图像分类任务评估我们的方法。CODaN [8]是一个为低光适应收集的10类数据集,包含12,500张正常光图像和2,500张低光图像。我们使用官方的正常光设置,同时将1,250张低光图像用于训练/验证,剩余的用于测试。我们的目标是将预训练在正常光数据上的ResNet-18适应于低光域。我们将我们的方法与11种低光增强方法和4种无监督领域适应方法进行了比较。需要注意的是,增强方法只修改输入图像,而适应方法则会修改模型。我们还提供了完全监督学习的结果(即使用低光标签进行训练)作为参考。
低光增强方法从人类视觉角度改善了光照,但忽略了机器视觉,导致性能提升有限。无监督领域适应方法,如CMD [65]、AdaBN [75]和DANN [34],设计用于一般领域适应场景,无法有效处理显著的正常/低光域差距。CIConv [8]引入了一个颜色不变卷积层以获取光照不变特征。然而,其手工设计的操作符不足以应对低光环境的多样光照条件。相比之下,我们的SACC-CE根据机器视觉指导调整光照,取得了最佳结果。此外,通过伪标签微调,我们的SACC-CE+实现了更高的结果。
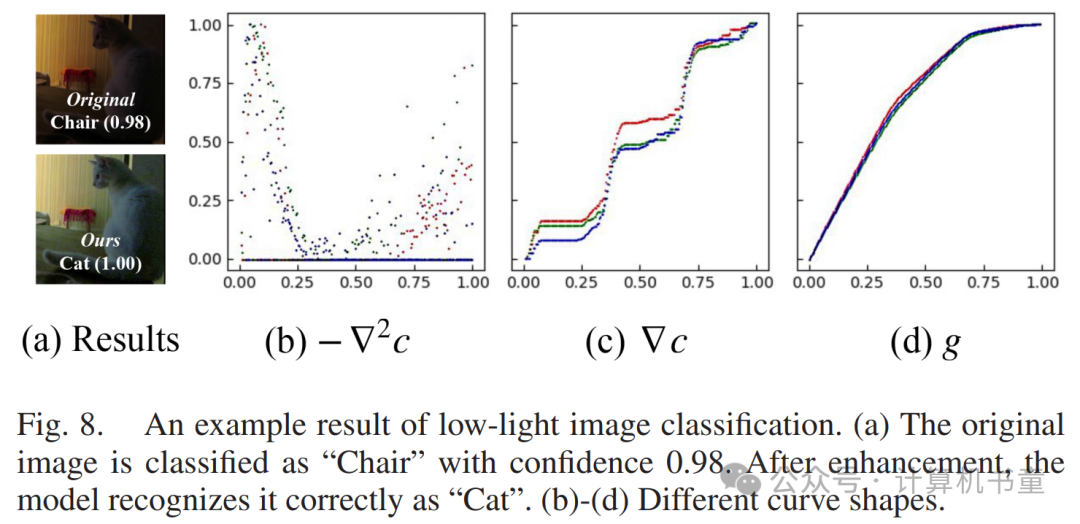
我们在图8中展示了预测增强曲线的示例,以证明它们满足了我们的要求。尽管看似离散,其值仍为正,结果为单调递增的积分和凹的最终增强曲线,与我们在第III-B节中引入的约束一致。
C. 暗光面部检测
我们进一步在暗光面部检测任务中对我们的方法进行了基准测试。WIDER FACE数据集[84]包含了来自各类事件和场景的32,000张图像,而DARK FACE数据集[62]包含了10,000张夜间街景图像。我们采用其官方拆分,并将DSFD [64]用作基线。
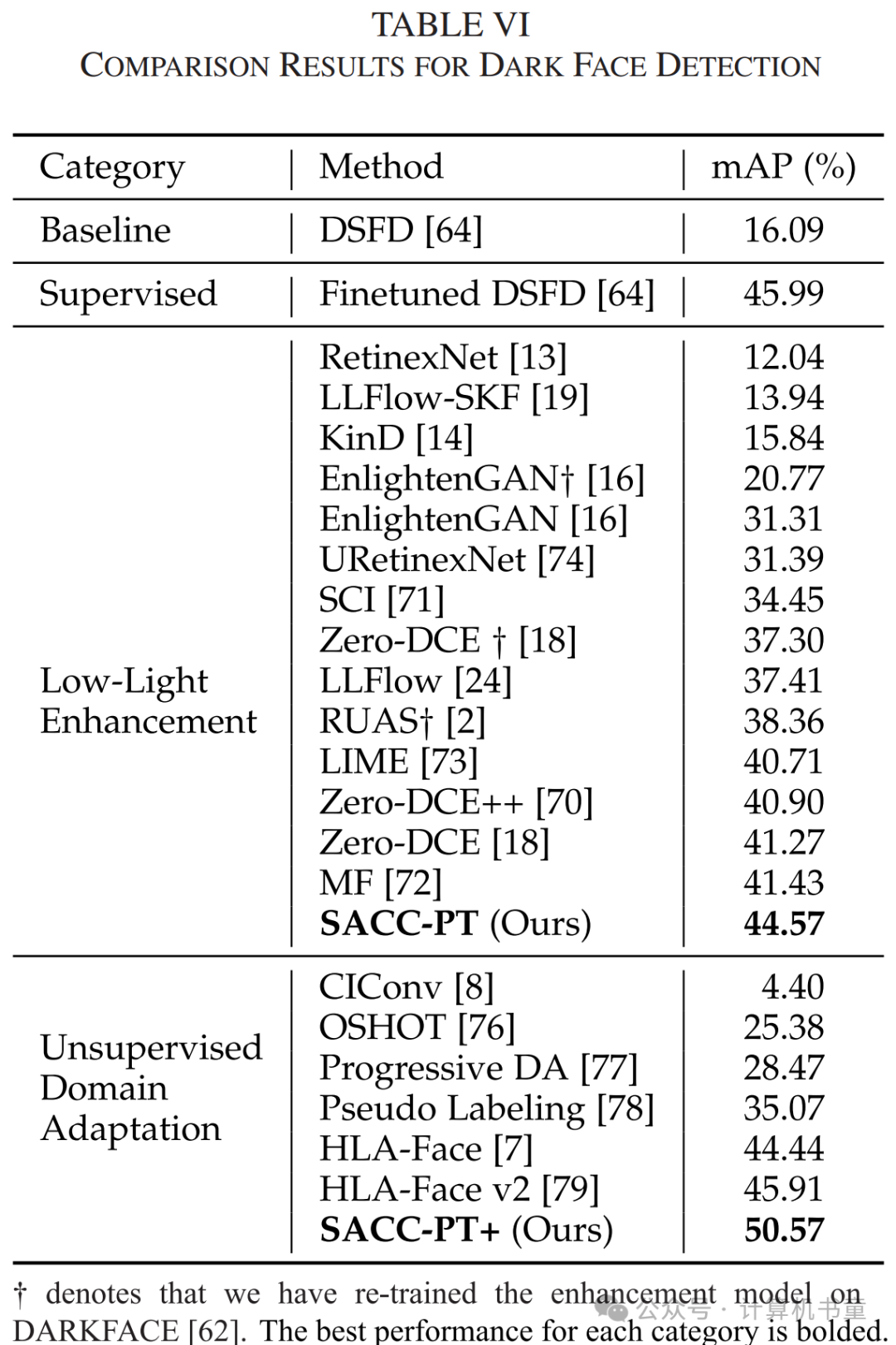
RetinexNet [13]和KinD [14]专注于细节重建和降噪,但引入了额外的伪影,负面影响了机器视觉和面部检测性能。其他低光增强方法也带来了有限的改进。我们将这些结果归因于它们忽视了机器视觉,从而对增强图像引入了不良但人眼不可察觉的噪声。
另一方面,无监督领域适应方法,如 OSHOT [76]、Progressive DA [77]和 Pseudo Labeling [78]仅带来有限的性能提升。尽管 CIConv [8]在 CODaN 上有效,其颜色不变层在 DARK FACE 上因极低的夜间光照而失效。图9(l)中显示,CIConv 的表示受到了严重的噪声影响。HLA-Face [79]和 HLA-Face v2 [79] 采用复杂的高低层联合适应策略。相比之下,我们的 SACC-PT 仅通过光照调整就超越了 HLA-Face。此外,我们的高级版本 SACC-PT+ 甚至可以超越完全监督的结果,展示了我们方法的优越性。
我们接着将使用 DSFD 训练的 SACC-PT 推广到其他面部检测器,包括 PyramidBox [80] 和 MogFace [81]。表VII 显示了我们的方法在未见过的下游框架上表现更好,表明从高层视觉中提炼的知识适用于多种机器模型。
D. 暗光中的光流估计
接下来,我们研究了光流估计任务,以展示我们方法的广泛适用性。VBOF 数据集[87]包含10,000对具有不同亮度级别的图像对。我们选择 Exp-2 到 Exp-5 子集作为目标域进行适应,其中 Exp-2 较亮,Exp-5 较暗。真实的流场通过在正常光条件下拍摄的 Exp-1 子集的先进方法 GMA [88] 估算。我们采用 PWC-Net [89] 作为基线,并通过端点误差(EPE)来测量性能。

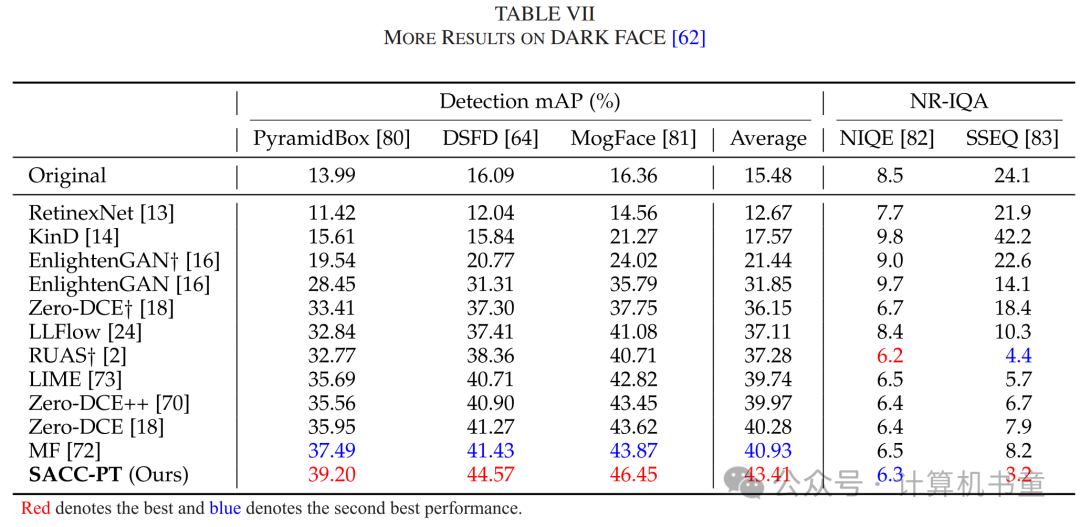

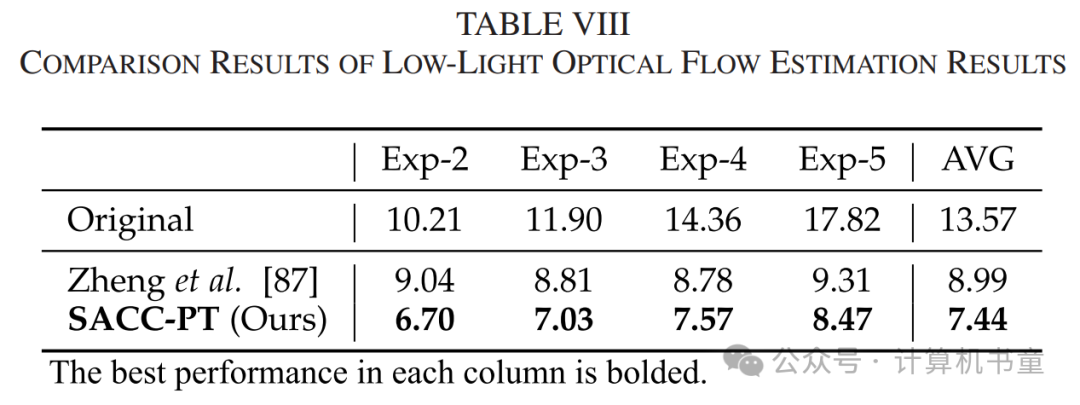
Zheng 等人[87]提出通过模拟暗光噪声并生成低光训练数据集来适应光流模型。然而,该合成过程仅考虑信号分布,而忽略机器视觉,导致其性能增益不如我们的效果,如表 VIII 所示。此外,图10 显示了我们的 SACC 对不同输入亮度级别的鲁棒性。
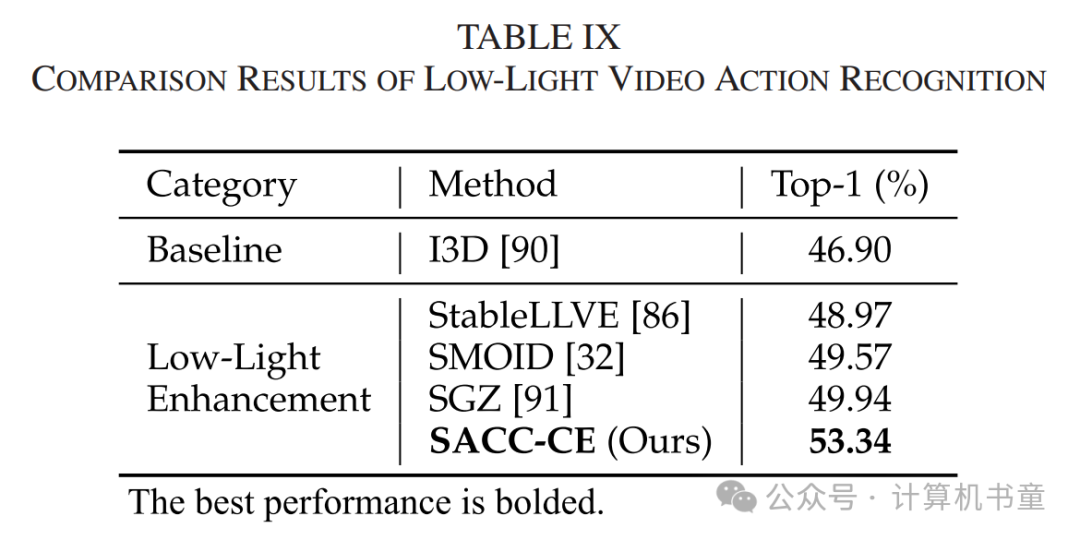
E. 低光动作识别
尽管我们的方法最初是为图像设计的,但也适用于视频。本节进一步评估了我们的框架在低光视频动作识别任务中的表现。我们从ARID数据集[92]中收集了大约800段低光视频片段。正常光训练数据由HMDB51[93]、UCF101[94]、Kinetics-600[90]和Moments in Time[95]的2,600段正常光视频片段组成。我们使用基于3D-ResNet[96]的I3D[85]作为主要分类器。
在预测增强曲线时,我们将一个视频片段中的所有帧合并为一幅大图像,并将预测曲线全局应用于所有帧。的统一性确保了增强视频的时间一致性。我们报告结果为top-1准确率。
如表IX所示,视频增强方法StableLLVE [86]、SMOID [32]和SGZ [91]将基线性能提高了约3%。相比之下,我们的SACC-CE在不增加复杂操作的情况下显著提升了6.44%的性能,显示了我们方法在视频任务中的优越性。主观结果见图11。
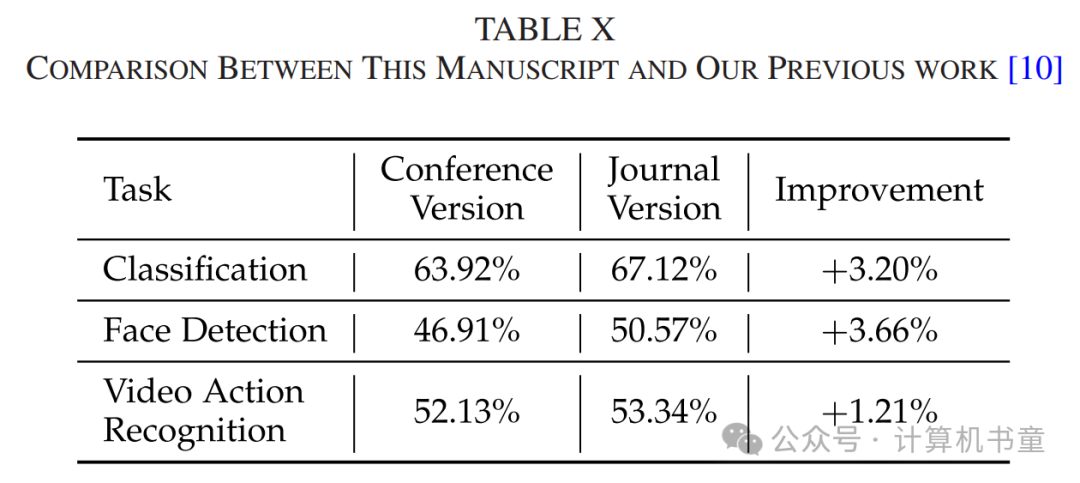
F. 与早期发表的对比
与我们之前的发表[10]相比,我们提出了一种新颖的曲线集成技术,用于训练我们的深凹曲线以进行分类任务,并提出了SACC+的非对称增强策略。这些方法上的进步显著提高了我们模型的性能,如表X所示。
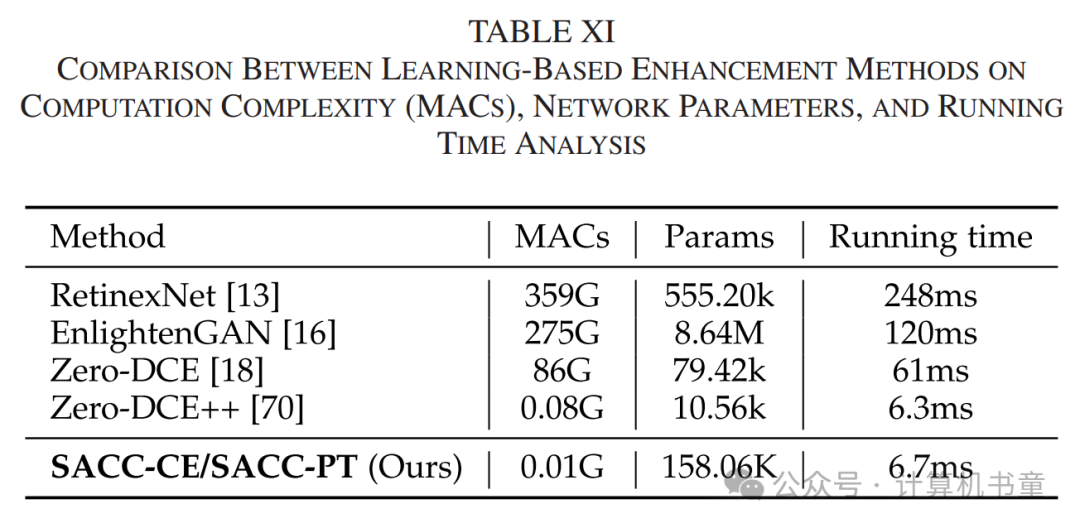
G. 运行时间分析
我们为分辨率为的输入图像提供了计算复杂度(乘加操作,MACs)、网络参数和运行时间的分析,结果如表XI所示。图像在配备Intel i7-9700 K @3.60 GHz CPU的GeForce GTX TITAN X GPU上处理。我们的方法在显著提升性能的同时,所需计算量比之前的方法更低。


H. 更广泛的应用
推广到监督学习场景
尽管主要为领域适应开发,我们的低光增强方法在监督学习情境中也具有优势。特别是,我们利用预训练的深凹曲线(SACC),冻结其参数,并使用低光标注训练数据微调正常光模型。与监督学习基线相比,加入深凹曲线使模型在低光分类上的top-1准确率从71.52%提高到72.64%。
野外评估
我们在DARK FACE [62]之外的样本上对提出的SACC进行暗光面部检测评估,结果见图13。虽然基线检测器[64]对光照条件变化敏感并产生错误预测,我们的方法在各种光照条件下都能稳定输出准确预测。
困难案例
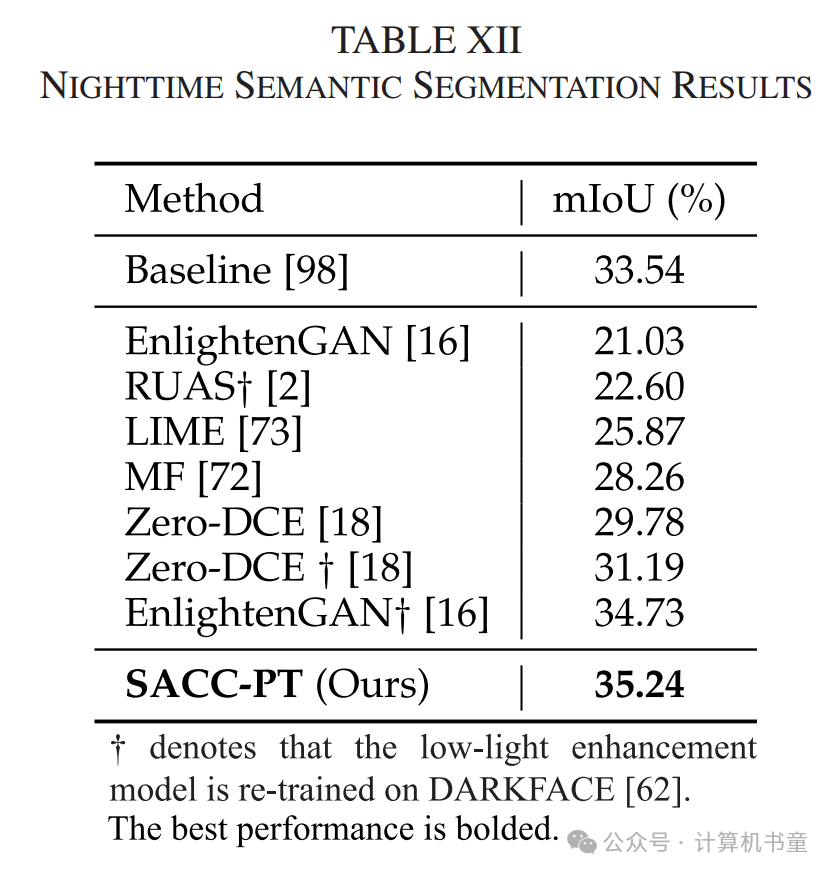
在光照充足的人造光环境中进行低光增强是一个挑战。我们以夜间语义分割为例,目标是将预训练在Cityscapes [99]数据集上的RefineNet [98]适应到Nighttime Driving [97]数据集。尽管夜间街景背景较暗,人造光线充分照亮了前景。然而,现有低光增强方法无法区分目标对象是否已经足够亮。

相比之下,我们的深凹曲线能够自动判断不再需要增强前景,如图12所示。在表XII中,我们的SACC-PT即使在目标数据集上重新训练后,也优于其他低光增强方法,显示出我们框架的卓越适应性。

I. 失败案例研究
我们的模型在极暗且面部非常小的情况下可能产生错误预测,这是所有方法面临的挑战性案例。如图14所示,MF [72]和HLA-Face v2 [79]同样难以准确预测所有面部。这种困难源于检测器在面对小面部时需要根据身体形状进行上下文推理来确定面部位置。因此,该方法不能总是区分面部和后脑勺,导致假阳性。尽管MF和HLA-Face错过了一些面部,但我们的模型成功识别了所有面部,显示了其在应对小面部挑战场景中的增强鲁棒性。
VII. 结论
本文提出了一种新颖的无监督正常光到低光领域适应方法,即自对齐凹曲线(SACC)。与传统主要关注人类视觉体验的增强方法不同,我们提出以高层机器视觉为指导。我们的方法利用深凹曲线进行光照增强,并结合两种自对齐技术来有效训练这种曲线。在多个高层视觉任务上的广泛实验表明了我们框架的优越性。现有和未来的工作可以将我们提出的增强曲线纳入其中,以实现更好的性能。
声明
本文内容为论文学习收获分享,受限于知识能力,本文对原文的理解可能存在偏差,最终内容以原论文为准。本文信息旨在传播和学术交流,其内容由作者负责,不代表本号观点。文中作品文字、图片等如涉及内容、版权和其他问题,请及时与我们联系,我们将在第一时间回复并处理。
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









