






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达来源:ai缝合大王
仅用于学术分享,若侵权请联系删除
论文地址: https://arxiv.org/pdf/2503.00467

创新点
1. 提出“自适应矩形卷积(ARConv)”模块
高度和宽度自适应学习:与传统卷积固定的正方形感受野不同,ARConv能够动态学习卷积核的高度和宽度,生成矩形卷积核,从而根据图像中不同物体的尺寸,灵活调整卷积窗口的形状。
动态采样点数量调整:ARConv不仅能改变卷积核的形状,还能根据学习到的高度和宽度动态调整采样点数量,解决了以往卷积中采样点数量固定、难以适配多尺度目标的问题。
计算复杂度友好:相较于传统可变形卷积需要学习大量偏移参数,ARConv仅需学习两个参数(高度、宽度),在小数据集(如遥感图像融合)任务中具有更好的收敛性。
2. 提出ARNet网络框架
以U-Net为基础,使用ARConv替代U-Net中的标准卷积,设计出更具尺度自适应能力的网络ARNet,在遥感图像的pansharpening任务上实现更优的特征提取和融合效果。
3. 新颖的“仿射变换”机制
在卷积操作完成后,ARConv还引入仿射变换模块,为特征图提供空间变换能力,进一步提升模型对不同形状和位置目标的适应性。
4. 泛化性和可移植性
ARConv设计为即插即用模块,论文通过实验证明将ARConv集成到现有的pansharpening网络(如FusionNet、LAGNet、CANNet)中后,均能有效提升这些网络的性能。
方法
整体架构
ARNet模型整体采用U-Net风格的Encoder-Decoder结构,结合跳跃连接以保留高分辨率特征信息。在编码器和解码器的各个层中,ARNet用自适应矩形卷积(ARConv)替代了标准卷积,形成了自定义的AR-ResBlock模块,使网络具备根据图像中不同目标尺度自适应调整卷积核形状和采样点数量的能力。同时,ARNet在解码阶段通过转置卷积进行逐步上采样,最终输出高分辨率多光谱图像(HRMS)。整体结构实现了高效的空间-光谱信息融合与细节恢复,显著提升遥感图像pansharpening任务中的图像质量。
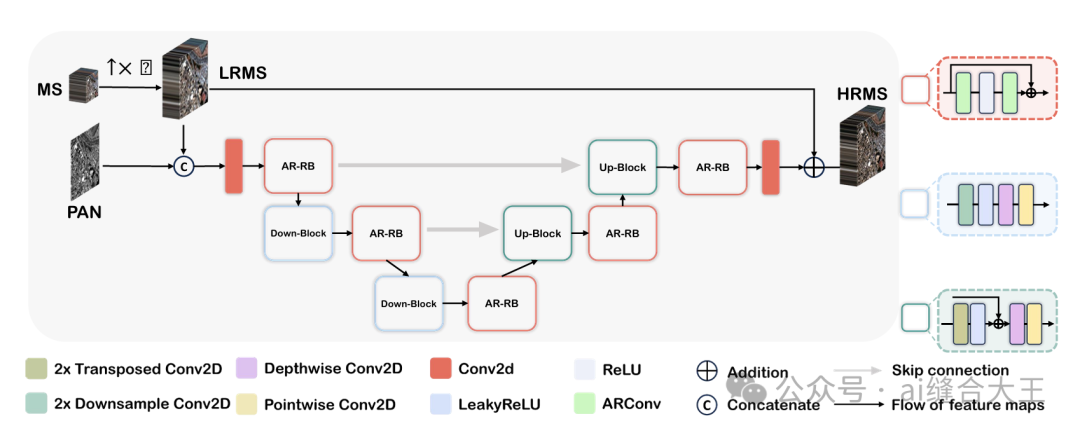
1. 整体架构:Encoder-Decoder结构
Encoder部分(下采样):
类似U-Net,ARNet的下采样部分由多个 Down-Block 组成。
每个Down-Block内包含了带有ARConv的AR-ResBlock模块,即在ResBlock(残差块)中用ARConv替代了普通卷积,能够在下采样过程中自适应捕获不同尺度的特征。
Decoder部分(上采样):
上采样阶段使用 Up-Block,配合转置卷积逐步恢复空间分辨率。
同样,ARConv模块嵌入在解码器的残差块中,持续进行尺度自适应特征提取。
2. 跳跃连接(Skip Connections)
依然保持U-Net的特点,将Encoder中的浅层特征通过跳跃连接传递到Decoder对应层,保证高分辨率的空间信息不丢失,提升细节恢复能力。
3. 输入与输出:
输入:将高分辨率全色图像(PAN)与上采样到相同尺寸的低分辨率多光谱图像(LRMS)进行通道拼接(concat),作为网络输入。
输出:输出高分辨率多光谱图像(HRMS),即融合后的图像。
4. 模块特色
AR-ResBlock:标准ResBlock的替代版,核心为ARConv模块。
ARConv模块:在特征提取层代替普通卷积,实现卷积核尺寸自适应 + 采样点动态选择 + 仿射空间变换,提升多尺度特征的提取能力。
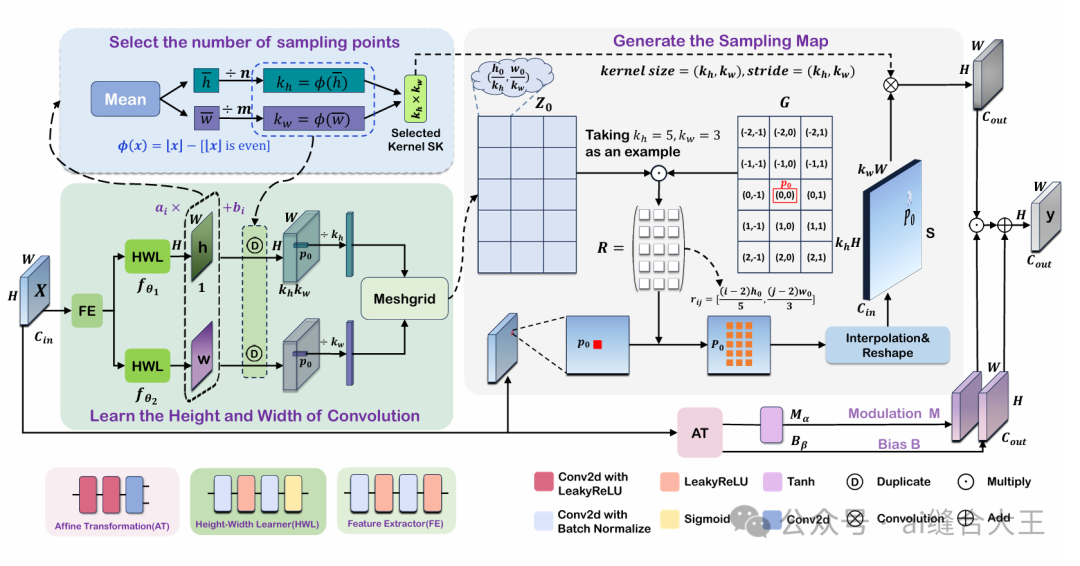
Affine Transformation:在卷积操作之后,针对每个位置输出特征图引入仿射变换,增强空间适配能力。
即插即用模块作用
ARConv 作为一个即插即用模块主要适用于:
遥感图像处理任务(尤其是pansharpening任务)
特点:遥感图像中存在大量尺度差异巨大的目标,比如小尺度的车辆和大尺度的建筑物、森林、道路等。
适用性:ARConv可以自适应调整卷积核的形状(矩形)和采样点数量,灵活适应不同尺度、不同形状的地物特征,特别适合处理遥感图像中的“多尺度、多形状”物体。
多尺度、多形状特征显著的图像处理场景
如医学影像(病灶区域大小不一)、卫星影像超分辨率、目标检测与分割任务等。
适用性:ARConv在这些任务中也能作为卷积替代模块,提升模型对尺度变化显著或目标形状多样化场景的感知和提取能力。
ARConv 作为一个即插即用模块的作用:
🌟 (1)增强多尺度特征提取能力
自动学习每个位置的卷积核“高度”和“宽度”,自适应形成“矩形卷积”,不再局限于固定的正方形窗口。
能根据图像内容动态调整“采样点数量”,在大目标区域密集采样,小目标区域稀疏采样,精细捕捉不同尺度的空间特征。
🌟 (2)减少参数、降低计算量
相较于传统的可变形卷积(Deformable Conv)需要为每个采样点学习偏移量,ARConv只需学习两个参数(h 和 w),在小数据集(如遥感、医疗等)上更容易训练收敛,计算开销更低。
🌟 (3)提升空间适应性与灵活性
结合仿射变换,ARConv不仅可变形、可调整采样密度,还能在输出阶段进一步提升特征图的空间适配能力,更好应对目标位移、扭曲等问题。
消融实验结果
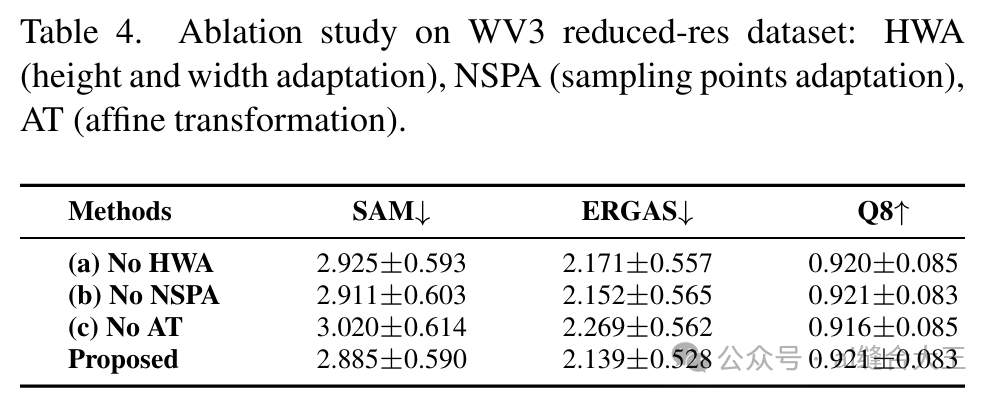
内容:测试了ARConv三个关键组件的作用,具体为:
HWA(Height and Width Adaptation,高度和宽度自适应)
NSPA(Number of Sampling Points Adaptation,采样点数量自适应)
AT(Affine Transformation,仿射变换)
结果:
去掉HWA或NSPA后,模型性能有轻微下降,说明自适应卷积核的形状和采样点数量对特征提取是有效的。
去掉仿射变换(No AT)后,性能下降更明显,说明仿射变换进一步提升了空间适应能力。
结论:这表明三个组件在ARConv中的设计均有助于性能提升,且仿射变换对模型的空间灵活性尤为重要。
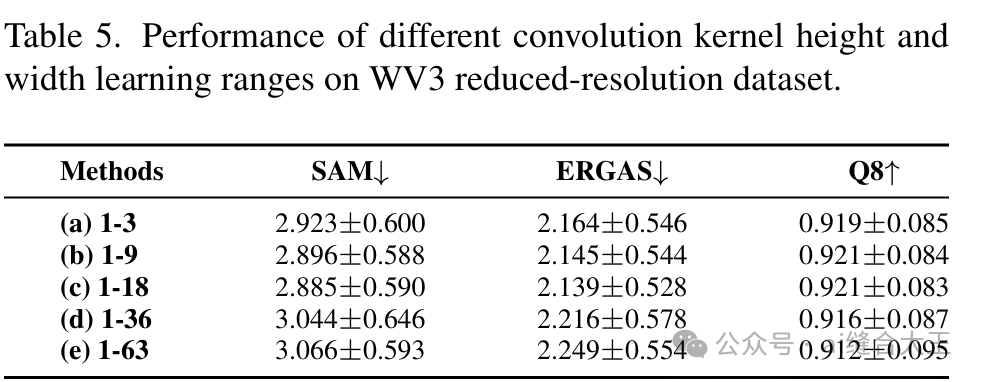
内容:探究ARConv中卷积核高度和宽度学习范围(kernel size range)对性能的影响,测试了以下范围:
1-3
1-9
1-18(最佳)
1-36
1-63
结果:
1-18范围下,模型获得了最优的性能,既能避免采样点过于稠密带来的噪声,也避免采样点过于稀疏造成的信息丢失。
当卷积核范围过大(如1-36或1-63),性能反而下降,说明ARConv需要合理的尺度区间,才能兼顾全局感知和细节捕捉
结论:适度的卷积核自适应范围能够平衡特征提取的“密度”和“尺度”,进一步验证了ARConv中动态控制核大小的必要性。
即插即用模块
import torch import torch.nn as nn class ARConv(nn.Module): def __init__(self, inc, outc, kernel_size=3, padding=1, stride=1, l_max=9, w_max=9, flag=False, modulation=True): super(ARConv, self).__init__() self.lmax = l_max self.wmax = w_max self.inc = inc self.outc = outc self.kernel_size = kernel_size self.padding = padding self.stride = stride self.zero_padding = nn.ZeroPad2d(padding) self.flag = flag self.modulation = modulation self.i_list = [33, 35, 53, 37, 73, 55, 57, 75, 77] self.convs = nn.ModuleList( [ nn.Conv2d(inc, outc, kernel_size=(i // 10, i % 10), stride=(i // 10, i % 10), padding=0) for i inself.i_list ] ) self.m_conv = nn.Sequential( nn.Conv2d(inc, outc, kernel_size=3, padding=1, stride=stride), nn.LeakyReLU(), nn.Dropout2d(0.3), nn.Conv2d(outc, outc, kernel_size=3, padding=1, stride=stride), nn.LeakyReLU(), nn.Dropout2d(0.3), nn.Conv2d(outc, outc, kernel_size=3, padding=1, stride=stride), nn.Tanh() ) self.b_conv = nn.Sequential( nn.Conv2d(inc, outc, kernel_size=3, padding=1, stride=stride), nn.LeakyReLU(), nn.Dropout2d(0.3), nn.Conv2d(outc, outc, kernel_size=3, padding=1, stride=stride), nn.LeakyReLU(), nn.Dropout2d(0.3), nn.Conv2d(outc, outc, kernel_size=3, padding=1, stride=stride) ) self.p_conv = nn.Sequential( nn.Conv2d(inc, inc, kernel_size=3, padding=1, stride=stride), nn.BatchNorm2d(inc), nn.LeakyReLU(), nn.Dropout2d(0), nn.Conv2d(inc, inc, kernel_size=3, padding=1, stride=stride), nn.BatchNorm2d(inc), nn.LeakyReLU(), ) self.l_conv = nn.Sequential( nn.Conv2d(inc, 1, kernel_size=3, padding=1, stride=stride), nn.BatchNorm2d(1), nn.LeakyReLU(), nn.Dropout2d(0), nn.Conv2d(1, 1, 1), nn.BatchNorm2d(1), nn.Sigmoid() ) self.w_conv = nn.Sequential( nn.Conv2d(inc, 1, kernel_size=3, padding=1, stride=stride), nn.BatchNorm2d(1), nn.LeakyReLU(), nn.Dropout2d(0), nn.Conv2d(1, 1, 1), nn.BatchNorm2d(1), nn.Sigmoid() ) self.dropout1 = nn.Dropout(0.3) self.dropout2 = nn.Dropout2d(0.3) self.hook_handles = [] self.hook_handles.append(self.m_conv[0].register_full_backward_hook(self._set_lr)) self.hook_handles.append(self.m_conv[1].register_full_backward_hook(self._set_lr)) self.hook_handles.append(self.b_conv[0].register_full_backward_hook(self._set_lr)) self.hook_handles.append(self.b_conv[1].register_full_backward_hook(self._set_lr)) self.hook_handles.append(self.p_conv[0].register_full_backward_hook(self._set_lr)) self.hook_handles.append(self.p_conv[1].register_full_backward_hook(self._set_lr)) self.hook_handles.append(self.l_conv[0].register_full_backward_hook(self._set_lr)) self.hook_handles.append(self.l_conv[1].register_full_backward_hook(self._set_lr)) self.hook_handles.append(self.w_conv[0].register_full_backward_hook(self._set_lr)) self.hook_handles.append(self.w_conv[1].register_full_backward_hook(self._set_lr)) self.reserved_NXY = nn.Parameter(torch.tensor([3, 3], dtype=torch.int32), requires_grad=False) @staticmethod def _set_lr(module, grad_input, grad_output): grad_input = tuple(g * 0.1if g is not None else None for g in grad_input) grad_output = tuple(g * 0.1if g is not None else None for g in grad_output) return grad_input def remove_hooks(self): for handle inself.hook_handles: handle.remove() # 移除钩子函数 self.hook_handles.clear() # 清空句柄列表 def forward(self, x, epoch, hw_range): assert isinstance(hw_range, list) and len(hw_range) == 2, "hw_range should be a list with 2 elements, represent the range of h w" scale = hw_range[1] // 9 if hw_range[0] == 1 and hw_range[1] == 3: scale = 1 m = self.m_conv(x) bias = self.b_conv(x) offset = self.p_conv(x * 100) l = self.l_conv(offset) * (hw_range[1] - 1) + 1# b, 1, h, w w = self.w_conv(offset) * (hw_range[1] - 1) + 1# b, 1, h, w if epoch <= 100: mean_l = l.mean(dim=0).mean(dim=1).mean(dim=1) mean_w = w.mean(dim=0).mean(dim=1).mean(dim=1) N_X = int(mean_l // scale) N_Y = int(mean_w // scale) def phi(x): if x % 2 == 0: x -= 1 return x N_X, N_Y = phi(N_X), phi(N_Y) N_X, N_Y = max(N_X, 3), max(N_Y, 3) N_X, N_Y = min(N_X, 7), min(N_Y, 7) if epoch == 100: self.reserved_NXY = self.reserved_NXY = nn.Parameter( torch.tensor([N_X, N_Y], dtype=torch.int32, device=x.device), requires_grad=False ) else: N_X = self.reserved_NXY[0] N_Y = self.reserved_NXY[1] N = N_X * N_Y # print(N_X, N_Y) l = l.repeat([1, N, 1, 1]) w = w.repeat([1, N, 1, 1]) offset = torch.cat((l, w), dim=1) dtype = offset.data.type() ifself.padding: x = self.zero_padding(x) p = self._get_p(offset, dtype, N_X, N_Y) # (b, 2*N, h, w) p = p.contiguous().permute(0, 2, 3, 1) # (b, h, w, 2*N) q_lt = p.detach().floor() q_rb = q_lt + 1 q_lt = torch.cat( [ torch.clamp(q_lt[..., :N], 0, x.size(2) - 1), torch.clamp(q_lt[..., N:], 0, x.size(3) - 1), ], dim=-1, ).long() q_rb = torch.cat( [ torch.clamp(q_rb[..., :N], 0, x.size(2) - 1), torch.clamp(q_rb[..., N:], 0, x.size(3) - 1), ], dim=-1, ).long() q_lb = torch.cat([q_lt[..., :N], q_rb[..., N:]], dim=-1) q_rt = torch.cat([q_rb[..., :N], q_lt[..., N:]], dim=-1) # clip p p = torch.cat( [ torch.clamp(p[..., :N], 0, x.size(2) - 1), torch.clamp(p[..., N:], 0, x.size(3) - 1), ], dim=-1, ) # bilinear kernel (b, h, w, N) g_lt = (1 + (q_lt[..., :N].type_as(p) - p[..., :N])) * ( 1 + (q_lt[..., N:].type_as(p) - p[..., N:]) ) g_rb = (1 - (q_rb[..., :N].type_as(p) - p[..., :N])) * ( 1 - (q_rb[..., N:].type_as(p) - p[..., N:]) ) g_lb = (1 + (q_lb[..., :N].type_as(p) - p[..., :N])) * ( 1 - (q_lb[..., N:].type_as(p) - p[..., N:]) ) g_rt = (1 - (q_rt[..., :N].type_as(p) - p[..., :N])) * ( 1 + (q_rt[..., N:].type_as(p) - p[..., N:]) ) # (b, c, h, w, N) x_q_lt = self._get_x_q(x, q_lt, N) x_q_rb = self._get_x_q(x, q_rb, N) x_q_lb = self._get_x_q(x, q_lb, N) x_q_rt = self._get_x_q(x, q_rt, N) # (b, c, h, w, N) x_offset = ( g_lt.unsqueeze(dim=1) * x_q_lt + g_rb.unsqueeze(dim=1) * x_q_rb + g_lb.unsqueeze(dim=1) * x_q_lb + g_rt.unsqueeze(dim=1) * x_q_rt ) x_offset = self._reshape_x_offset(x_offset, N_X, N_Y) x_offset = self.dropout2(x_offset) x_offset = self.convs[self.i_list.index(N_X * 10 + N_Y)](x_offset) out = x_offset * m + bias returnout def _get_p_n(self, N, dtype, n_x, n_y): p_n_x, p_n_y = torch.meshgrid( torch.arange(-(n_x - 1) // 2, (n_x - 1) // 2 + 1), torch.arange(-(n_y - 1) // 2, (n_y - 1) // 2 + 1), ) p_n = torch.cat([torch.flatten(p_n_x), torch.flatten(p_n_y)], 0) p_n = p_n.view(1, 2 * N, 1, 1).type(dtype) return p_n def _get_p_0(self, h, w, N, dtype): p_0_x, p_0_y = torch.meshgrid( torch.arange(1, h * self.stride + 1, self.stride), torch.arange(1, w * self.stride + 1, self.stride), ) p_0_x = torch.flatten(p_0_x).view(1, 1, h, w).repeat(1, N, 1, 1) p_0_y = torch.flatten(p_0_y).view(1, 1, h, w).repeat(1, N, 1, 1) p_0 = torch.cat([p_0_x, p_0_y], 1).type(dtype) return p_0 def _get_p(self, offset, dtype, n_x, n_y): N, h, w = offset.size(1) // 2, offset.size(2), offset.size(3) L, W = offset.split([N, N], dim=1) L = L / n_x W = W / n_y offsett = torch.cat([L, W], dim=1) p_n = self._get_p_n(N, dtype, n_x, n_y) p_n = p_n.repeat([1, 1, h, w]) p_0 = self._get_p_0(h, w, N, dtype) p = p_0 + offsett * p_n return p def _get_x_q(self, x, q, N): b, h, w, _ = q.size() padded_w = x.size(3) c = x.size(1) x = x.contiguous().view(b, c, -1) index = q[..., :N] * padded_w + q[..., N:] index = ( index.contiguous() .unsqueeze(dim=1) .expand(-1, c, -1, -1, -1) .contiguous() .view(b, c, -1) ) x_offset = x.gather(dim=-1, index=index).contiguous().view(b, c, h, w, N) return x_offset @staticmethod def _reshape_x_offset(x_offset, n_x, n_y): b, c, h, w, N = x_offset.size() x_offset = torch.cat([x_offset[..., s:s + n_y].contiguous().view(b, c, h, w * n_y) for s in range(0, N, n_y)], dim=-1) x_offset = x_offset.contiguous().view(b, c, h * n_x, w * n_y) return x_offset
便捷下载方式
浏览打开网址:https://github.com/ai-dawang/PlugNPlay-Modules
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
















 1109
1109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









